redis中hash数据结构及说明
目录
- hash的数据结构
- ziplist底层实现
- 字典
- 底层实现
- 扩容
- 缩容
- 总结
hash的数据结构
- hash底层数据结构的实现包括两种:ziplist和字典当
- 保存的所有键值对字符串长度小于 64 字节并且键值对数量小于 512 时使用ziplist ,否则使用字典的方式
ziplist底层实现
ziplist是为了提高存储效率而设计的一种特殊编码的双向链表。它可以存储字符串或者整数,存储整数时是采用整数的二进制而不是字符串形式存储。
他能在O(1)的时间复杂度下完成list两端的push和pop操作。
但是因为每次修改操作都需要重新分配ziplist的内存,所以实际复杂度和ziplist的内存使用量相关
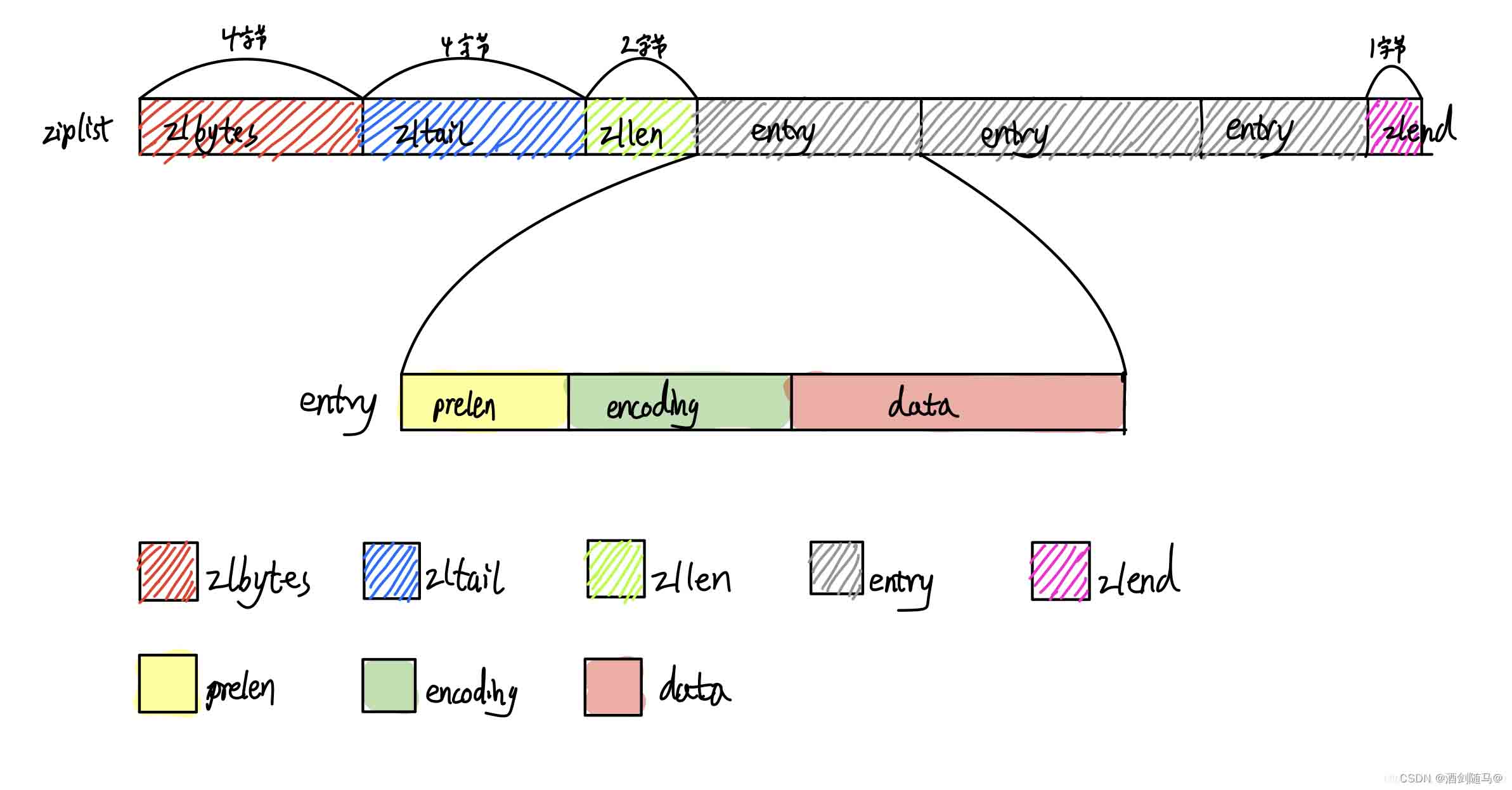
ziplist 中包含有zlbytes、zltail、zllen、entry、zlend等属性
zlbytes:表示整个ziplist所占的空间大小,占4个字节zltail:压缩列表尾元素相对于压缩列表起始地址的偏移量,占4个字节zllen:压缩列表的元素数目,占两个字节;那么当压缩列表的元素数目超过(2^16)-1怎么处理呢?此时通过zllen字段无法获得压缩列表的元素数目,必须遍历整个压缩列表才能获取到元素数目zlend:压缩列表的结尾,占一个字节,恒为0xFF(255)entry:压缩列表存储的元素,可以为字节数组或者整数
entry 中包含有previous_entry_length、encoding、content等属性
previous_entry_length:记录前一个节点的长度
该属性根据前一个节点的大小不同可以是1个字节或者5个字节;如果数值小于254,那就只用一个字节来表示长度,如果长度大于等于254就用5个字节,第一个字节是固定值254(FE)来标识这是个特殊的数据,剩下的4个字节来表示实际的长度
为什么要这么设计?
压缩列表目的是为了尽可能的节省存储空间,数据进行紧邻存储在一块连续的内存区域中;压缩表中元素的长度的是不同的,且为了减少存储空间,并没有保存前后节点的指针,无法通过后退指针来找到上一个元素,而通过保存上一个节点的长度,用当前的地址减去这个长度,就可以很容易的获取到了上一个节点的位置,通过一个一个节点向前回溯,来达到从表尾往表头遍历的操作
encoding:数据的编码形式(字符串还是数字,长度是多少)content:实际存储的数据
修改操作耗费性能:ziplist在内存中是高度紧凑的连续存储,这意味着它对修改并不友好,如果要对ziplist做修改类的操作,那就需重新分配新的内存来存储新的ziplist,代价很大
ziplist其实是一个逻辑上的双向链表,可以快速找到头节点和尾节点,然后每个节点(entry)中也包含指向前/后节点的"指针",但作者为了将内存节省到极致,摒弃了传统的链表设计(前后指针需要16字节的空间,而且会导致内存碎片化严重),设计出了内存非常紧凑的存储格式。
内存是省下来了,但操作复杂性也更新的复杂度上来了
字典
底层实现
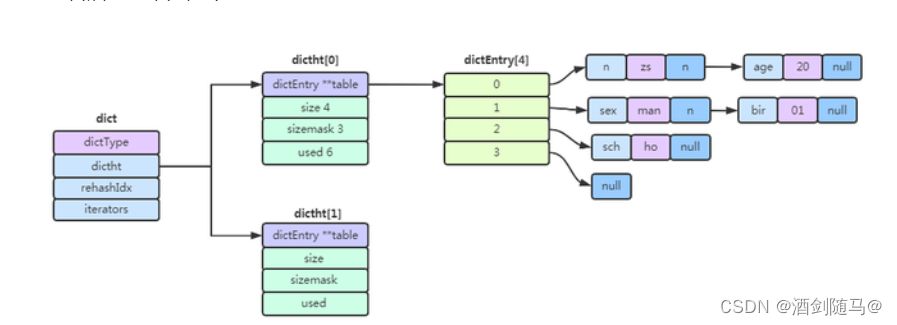
字典(dict):其中包含长度为2的哈希表数组dictht,rehashIdx(默认-1)如果为-1说明当前没有扩容,如果不为 -1 则表示正在进行扩容,记录了原hash表需rehash的数组下标
hash表数组中,ht[0] 在第一次往字典中添加键值时分配内存空间,而另一个 ht[1] 将会在hash表中数组扩容/缩容才会进行空间分配
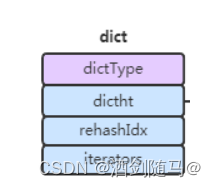
hash表(dictht):字典dictht数组元素,其中包括了
1 数据 dictEntry 类型的数组,每个数组的 item 可能都指向一个链表
2 数组长度 size
3 sizemask 等于 size - 1
4 当前 dictEntry 数组中包含总共多少节点

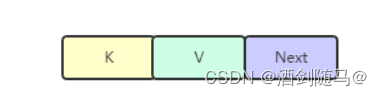
hash表数组中元素(dictEntry):真正的数据节点,包括 key、value 和 next 节点
整体结构如下所示:
扩容
扩容时机:在dict->rehashidx == -1 , 也就是字典没有正在进行扩容/缩容的前提下,以下三种情况下对哈希表进行扩容并标记 dict->rehashidx 字段为0,且扩展的哈希表的数组大小是第一个hash表长度的 2倍
- 字典已使用节点数和数组大小之间的比率至少为 1:1,并且 dict_can_resize 为true
- 已使用节点数和字典大小之间的比率超过 dict_force_resize_ratio,该值默认为5
- 哈希表刚初始化完,是个空表,给哈希数组设置默认大小 DICT_HT_INITIAL_SIZE (4)
扩容方式:为ht[1]分配长度为ht[0]2倍长度,rehashIdx设置为0表示正在进行扩容rehash,采取渐进式rehash
redis对一个字典的rehash操作,不是一次性把该字典 dict->ht[0] 哈希表上所有哈希数组里的哈希数组元素全部重新哈希到 dict->ht[1]
而是将全部的rehash操作分散到对该字典操作的各个命令上了,每次进行"一步"哈希操作(增加k/v,删除k/v,查找key,随机返回key)
- 下标从dict->rehashidx开始,在 dict->ht[0].table 数组中找到第一个不为NULL的项
- 将该项链表上的所有元素全部hash映射到 ditct->ht[1] 上
- 每重新映射一个元素, dict->ht[0].used --, dict->ht[1].used ++
- 该项链表处理完后,将 dict->rehashidx ++
如果 dict->ht[0].used == 0,说明 dict->ht[0]中的元素已全部rehash到dict->ht[1],释放dict->ht[0].table 数组,设置 dict->ht[0] = dict->ht[1],重置 dict->ht[1]的字段,设置 dict->rehashidx = -1,rehash操作结束
缩容
字典有扩容也有缩容,从字典中删除key后,若字典中的元素个数与字典数组大小满足一定关系,会触发缩容操作,缩绒条件是:
哈希数组长度大于默认值DICT_HT_INITIAL_SIZE (4),且节点数量 与 字典哈希表数字大小的比例 小于10%
缩容后新数组长度为hash表中元素个数
总结
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

浅谈redis五大数据结构和使用场景
老规矩,先抛结论后验证 string:有点像java的hashMap,存的时候什么key,取的时候也什么key,常用于做缓存,保存用户信息.查询列表等: hash:这个有点像hashMap的value又套了个hashMap,下文有举例,一看就明白了: list:有序列表,类似Java的linkedList,可以在左边右边插入数据: set:去重集合,类似Java的hashset,可用于求交集,比如共同好友: zset:带权重的set集合,可用于做排行榜: 为了方便理解,我们基于这个dog类来做测
-
redis中的数据结构和编码详解
redis中的数据结构和编码: 背景: 1>redis在内部使用redisObject结构体来定义存储的值对象. 2>每种类型都有至少两种内部编码,Redis会根据当前值的类型和长度来决定使用哪种编码实现. 3>编码类型转换在Redis写入数据时自动完成,这个转换过程是不可逆的,转换规则只能从小内存编码向大内存编码转换. 源码: 值对象redisObject: typedef struct redisObject { unsigned ty
-
Redis中5种数据结构的使用场景介绍
一.redis 数据结构使用场景 原来看过 redisbook 这本书,对 redis 的基本功能都已经熟悉了,从上周开始看 redis 的源码.目前目标是吃透 redis 的数据结构.我们都知道,在 redis 中一共有5种数据结构,那每种数据结构的使用场景都是什么呢? String--字符串 Hash--字典 List--列表 Set--集合 Sorted Set--有序集合 下面我们就来简单说明一下它们各自的使用场景: 1. String--字符串 String 数据结构是简单的 key-
-
redis中hash数据结构及说明
目录 hash的数据结构 ziplist底层实现 字典 底层实现 扩容 缩容 总结 hash的数据结构 hash底层数据结构的实现包括两种:ziplist和字典当 保存的所有键值对字符串长度小于 64 字节并且键值对数量小于 512 时使用ziplist ,否则使用字典的方式 ziplist底层实现 ziplist是为了提高存储效率而设计的一种特殊编码的双向链表.它可以存储字符串或者整数,存储整数时是采用整数的二进制而不是字符串形式存储. 他能在O(1)的时间复杂度下完成list两端的push和
-
redis中Hash字典操作的方法
目录 1.Redis操作之Hash操作 redis hash字典操作 1.Redis操作之Hash操作 redis支持五大数据类型,只支持第一层,也就说字典的value值,必须是字符串 如果value值想存字典,必须用json转换一下,转成字符串 redis hash字典操作 reids:{ k1:'dafdadfasf', m1:{ 'key2':value2, 'key1':value1, } } 1.hset(name, key, value),插入值 # name对应的hash中设置一个
-
redis中hash表内容删除的方法代码
hash: Redis hash是一个string类型的field和value的映射表,hash特别适合用于存储对象. Redis 中每个hash可以存储 232 - 1键值对(40多亿). 实例: 127.0.0.1:6379> HMSET runoobkey name "redis tutorial" description "redis basic commands for caching" likes 20 visitors 23000 OK 127.
-
redis中如何使用lua脚本让你的灵活性提高5个逼格详解
前言 在实际工作过程中,可以使用lua脚本来解决一些需要保证原子性的问题,而且lua脚本可以缓存在redis服务器上,势必会增加性能. 然而在redis的官网上洋洋洒洒的大概提供了200多个命令,貌似看起来很多,但是这些都是别人预先给你定义好的,但你却不能按照自己的意图进行定制, 所以是不是感觉自己还是有一种被束缚的感觉,有这个感觉就对了... 一:Lua脚本 说来也巧,redis的大老板给了你解决这种问题的方法,那就是Lua脚本,而且redis的最新版本也支持Lua Script debug,
-
Redis五种数据结构在JAVA中如何封装使用
目录 数据结构 string字符串 string字符串简介 string字符串在Java中的封装 list列表 list列表简介 队列 栈 list列表在Java中的封装 hash(字典) hash字典简介 hash字典在Java中的封装 set(集合) set集合简介 set集合在Java中的封装 zset(有序列表) zset有序列表 zset有序列表在Java中的封装 数据结构 Redis有五种基础数据结构,分别为: 1.string(字符串) 2.list(列表) 3.hash(字典)
-
控制Redis的hash的field中的过期时间
目录 需求场景 方案一使用redis的Zset配置定时任务 方案二使用mq延时队列 综上 总结 需求场景 在业务中有些数据因为历史原因用的hash结构存储数据,但是后期需求要求其中某个field需要按照一些规则去过期,这个时候原来的逻辑懒得改,可以利用redis的Zset或者mq的延时队列去做过期设置. 方案一使用redis的Zset配置定时任务 捞个图 demo需要清缓存的redis的hash结构如下 然后我们再每次往Agent这个hash结构存储数据的时候,同时向AgentExpire为ke
-
Redis中3种特殊的数据类型(BitMap、Geo和HyperLogLog)
前言 Reids 在 Web 应用的开发中使用非常广泛,几乎所有的后端技术都会有涉及到 Redis 的使用.Redis 种除了常见的字符串 String.字典 Hash.列表 List.集合 Set.有序集合 SortedSet 等等之外,还有一些不常用的数据类型,这里着重介绍三个.下面话不多说了,来一起看看详细的介绍吧. BitMap BitMap 就是通过一个 bit 位来表示某个元素对应的值或者状态, 其中的 key 就是对应元素本身,实际上底层也是通过对字符串的操作来实现.Redis 从
-
Redis中一些最常见的面试问题总结
前言 经过长达一周的奔波和面试,电话面试,回首今天终于成功的入职了,总共面试了大概10家公司,包括阿里,京东,IBM等等,京东技术过了,学历因为非统招就被pass了,阿里面了2次电话面试就没下文了,估计是我当时最后提问题的时候减分了吧,其他的也有一些offer,不是不想去,就是了无音讯了,眼看年关将近,也由不得我挑挑拣拣了,就直接进了我现在这家公司,主要是感觉公司人不错,薪水这方面也就没有计较太多.好了,书归正文,今天小编就大家送上我精心准备的关于Redis方面的面试题,希望可以帮到还在求职路上