python+selenium实现自动化百度搜索关键词
通过python配合爬虫接口利用selenium实现自动化打开chrome浏览器,进行百度关键词搜索。
1、安装python3,访问官网选择对应的版本安装即可,最新版为3.7。

2、安装selenium库。
使用 pip install selenium 安装即可。
同时需要安装chromedriver,并放在python安装文件夹下,如下图所示。
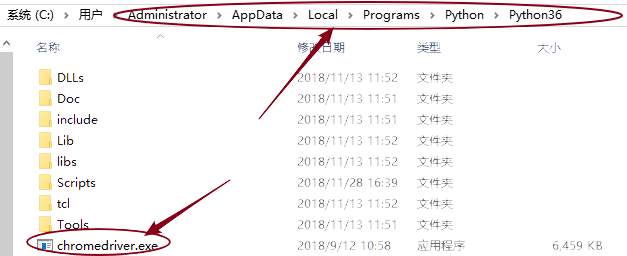
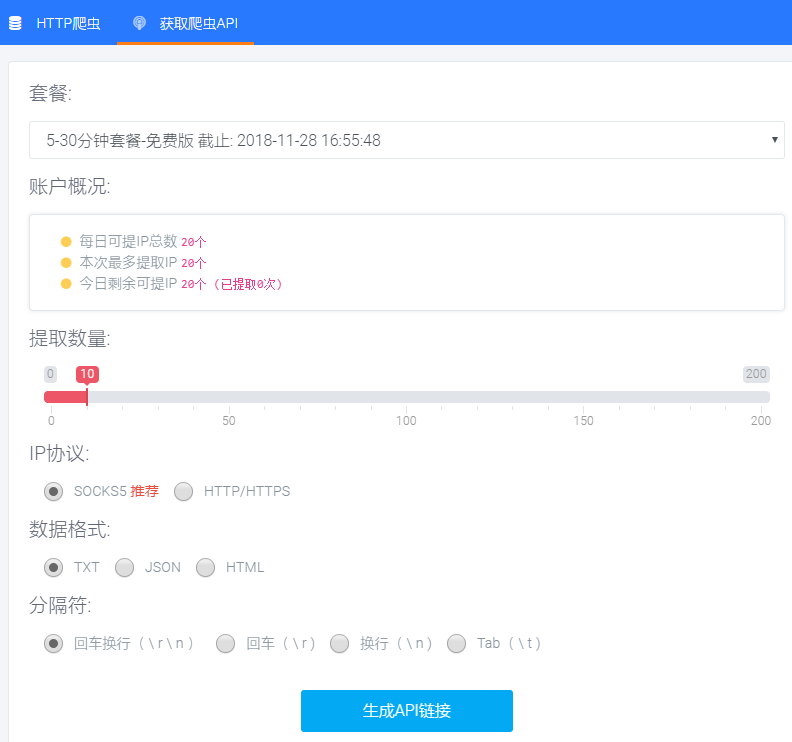
3、获取爬虫接口链接。
注册账号,点击爬虫代理,领取每日试用。
from selenium import webdriver
import requests,time
#自建IP池
def get_proxy():
r = requests.get('http://127.0.0.1:5555/random')
return r.text
import random
FILE = './tuziip.txt'
# 读取的txt文件路径
# 获取代理IP
def proxy_ip():
ip_list = []
with open(FILE, 'r') as f:
while True:
line = f.readline()
if not line:
break
ip_list.append(line.strip())
ip_port = random.choice(ip_list)
return ip_port
def bd():
chromeOptions = webdriver.ChromeOptions()
# 设置代理
chromeOptions.add_argument("--proxy-server=http://"+proxy_ip())
# 一定要注意,=两边不能有空格,不能是这样--proxy-server = http://202.20.16.82:10152
browser = webdriver.Chrome(chrome_options = chromeOptions)
# 查看本机ip,查看代理是否起作用
browser.get("https://www.baidu.com/")
browser.find_element_by_id("kw").send_keys("ip")
browser.find_element_by_id("su").click()
time.sleep(2)
browser.find_element_by_id("kw").clear()
time.sleep(1)
browser.find_element_by_id("kw").send_keys("百度")
browser.find_element_by_id("su").click()
time.sleep(2)
browser.find_element_by_id("kw").clear()
time.sleep(1)
browser.find_element_by_id("kw").send_keys("百度")
browser.find_element_by_id("su").click()
time.sleep(2)
browser.find_element_by_id("kw").clear()
time.sleep(1)
browser.close()
# 退出,清除浏览器缓存
browser.quit()
if __name__ == "__main__":
while True:
bd()
5、运行程序,如下图所示,可自动化搜索。

相关推荐
-
Python使用Selenium+BeautifulSoup爬取淘宝搜索页
使用Selenium驱动chrome页面,获得淘宝信息并用BeautifulSoup分析得到结果. 使用Selenium时注意页面的加载判断,以及加载超时的异常处理. import json import re from bs4 import BeautifulSoup from selenium import webdriver from selenium.common.exceptions import TimeoutException from selenium.webdriver.com
-
python+selenium实现自动化百度搜索关键词
通过python配合爬虫接口利用selenium实现自动化打开chrome浏览器,进行百度关键词搜索. 1.安装python3,访问官网选择对应的版本安装即可,最新版为3.7. 2.安装selenium库. 使用 pip install selenium 安装即可. 同时需要安装chromedriver,并放在python安装文件夹下,如下图所示. 3.获取爬虫接口链接. 注册账号,点击爬虫代理,领取每日试用. from selenium import webdriver import requ
-

Python使用Selenium自动进行百度搜索的实现
目录 安装 Selenium 写代码 点位网页元素 我们今天介绍一个非常适合新手的python自动化小项目,项目虽小,但是五脏俱全.它是一个自动化操作网页浏览器的小应用:打开浏览器,进入百度网页,搜索关键词,最后把搜索结果保存到一个文件里.这个例子非常适合新手学习Python网络自动化,不仅能够了解如何使用Selenium,而且还能知道一些超级好用的小工具. 当然有人把操作网页,然后把网页的关键内容保存下来的应用一律称作网络爬虫,好吧,如果你想这么爬取内容,随你.但是,我更愿意称它为网络机器人.
-
Python+Selenium实现自动化的环境搭建的步骤(图文)
1.在浏览器下载与浏览器相对于的驱动并放到python的安装根目录下 驱动的两个下载地址: http://chromedriver.storage.googleapis.com/index.html http://npm.taobao.org/mirrors/chromedriver/ a.先找到浏览器的版本 b.找到与浏览器对应的驱动 c.把下载好的驱动放到python安装目录的根目录下 2.点击设置 3.添加selenium 4.搜索selenium并添加 5.输入以下代码并运行,如果能打开
-
Python通过tkinter实现百度搜索的示例代码
本文主要介绍了Python通过tkinter实现百度搜索的示例代码,分享给大家,具体如下: """ 百度搜索可视化 """ import tkinter import win32api from selenium.webdriver import Chrome entry = None def callback(): global entry keywords = entry.get() if not keywords: win32api.Mes
-
python selenium UI自动化解决验证码的4种方法
本文介绍了python selenium UI自动化解决验证码的4种方法,分享给大家,具体如下: 测试环境 windows7+ firefox50+ geckodriver # firefox浏览器驱动 python3 selenium3 selenium UI自动化解决验证码的4种方法:去掉验证码.设置万能码.验证码识别技术-tesseract.添加cookie登录,本次主要讲解验证码识别技术-tesseract和添加cookie登录. 1. 去掉验证码 去掉验证码,直接通过用户名和密码登陆网
-
Python爬虫爬取百度搜索内容代码实例
这篇文章主要介绍了Python爬虫爬取百度搜索内容代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 搜索引擎用的很频繁,现在利用Python爬虫提取百度搜索内容,同时再进一步提取内容分析就可以简便搜索过程.详细案例如下: 代码如下 # coding=utf8 import urllib2 import string import urllib import re import random #设置多个user_agents,防止百度限制I
-
学习Python selenium自动化网页抓取器
直接入正题---Python selenium自动控制浏览器对网页的数据进行抓取,其中包含按钮点击.跳转页面.搜索框的输入.页面的价值数据存储.mongodb自动id标识等等等. 1.首先介绍一下 Python selenium ---自动化测试工具,用来控制浏览器来对网页的操作,在爬虫中与BeautifulSoup结合那就是天衣无缝,除去国外的一些变态的验证网页,对于图片验证码我有自己写的破解图片验证码的源代码,成功率在85%. 详情请咨询QQ群--607021567(这不算广告,群里有好多P
-
使用Python+selenium实现第一个自动化测试脚本
最近在学web自动化,记录一下学习过程. 此处我选用python3.6+selenium3.0,均用最新版本,以适应未来需求. 环境:windows10,64位 一.安装python python官方下载地址:https://www.python.org/downloads/ 进入页面就有两个版本的下载选择,2.x版本和3.x版本,或者根据系统选择对应版本. 点击Windows,跳转到Windows版本页面: 点选Python3.6.0版本,进入3.6版本页面,拉到页面下方,找到files 选择
-
Python selenium模拟手动操作实现无人值守刷积分功能
经常为学校的各种刷分而发愁,得知开学无望,日后还要刷课,索性自动化一次,学而不用乃愚昧 聪慧 四大模块 初始化 from selenium import webdriver if __name__ == '__main__': driver = webdriver.Chrome() url = 'https://pc.xuexi.cn/points/login.html?ref=https://pc.xuexi.cn/points/my-points.html' driver.get(url =
-
Python+selenium实现截图图片并保存截取的图片
这篇文章介绍如何利用Selenium的方法进行截图,在测试过程中,是有必要截图,特别是遇到错误的时候进行截图.在selenium for Python中主要有三个截图方法,我们挑选其中最常用的一种. 截图技能对于测试人员来说应该是较为重要的一个技能. 在自动化测试中,截图可以帮助我们直观的定位错误.记录测试步骤. 记得以前在给某跨国银行做自动化项目的时候,某银的PM要求我们自动化测试的每一步至少需要1个截图,以证明每个功能都被自动化测试给覆盖过,在这种情况下截图就成了证明自动化测试有效性的重要手