python实战教程之OCR文字识别方法汇总
目录
- 方法一: 使用easyocr模块
- 方法二:通过pytesseract调用tesseract
- Tesseract的安装与使用
- pytesseract
- cnocr 第二种 Python 开源识别工具的效果
- 安装 cnocr:
- cnocr 识别图片的中文
- 方法三:调用百度API
- 总结
将图片翻译成文字一般被称为光学文字识别(Optical Character Recognition,OCR)。可以实现OCR 的底层库并不多,目前很多库都是使用共同的几个底层OCR 库,或者是在上面进行定制。
方法一: 使用easyocr模块
easyocr是基于torch的深度学习模块
easyocr安装后调用过程中出现opencv版本不兼容问题,所以放弃此方案。
方法二:通过pytesseract调用tesseract
优点:部署快,轻量级,离线可用,免费
缺点:自带的中文库识别率较低,需要自己建数据进行训练
Tesseract 是一个OCR 库,目前由Google 赞助(Google 也是一家以OCR 和机器学习技术闻名于世的公司)。Tesseract 是目前公认最优秀、最精确的开源OCR 系统。
除了极高的精确度,Tesseract 也具有很高的灵活性。它可以通过训练识别出任何字体(只要这些字体的风格保持不变就可以),也可以识别出任何Unicode 字符。
Tesseract的安装与使用
python 识别图片上的数字,使用pytesseract库从图像中提取文本,而识别引擎采用 tesseract-ocr。
pytesseract是python包装器,它为可执行文件提供了pythonic API。
1、安装必要的包:
pip install pillow pip install pytesseract
2、安装tesseract-ocr的识别引擎
最新版本下载地址: https://github.com/UB-Mannheim/tesseract/wiki
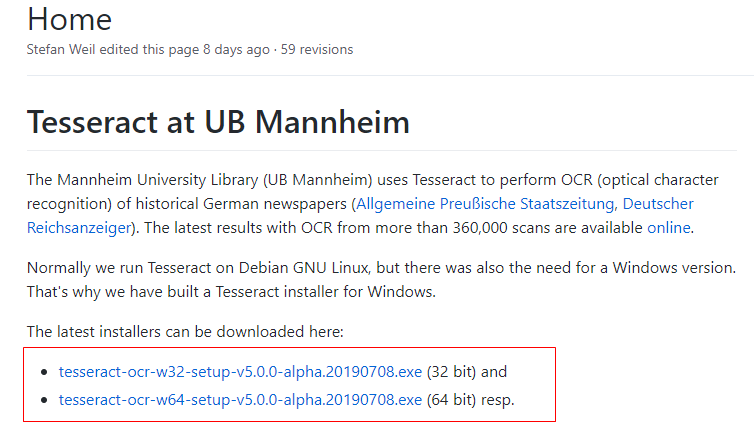
或者更多版本的tesseract下载地址:https://digi.bib.uni-mannheim.de/tesseract/
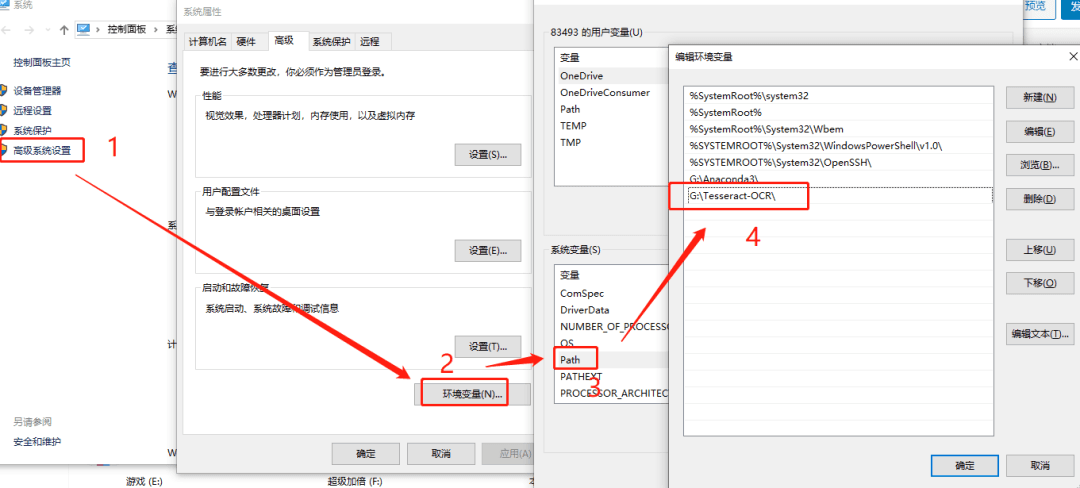
安装完后,需要将Tesseract添加到系统变量中。
环境变量: 我的电脑 ->属性 -> 高级系统设置 ->环境变量 ->系统变量 ,在 path 中添加 安装路径。
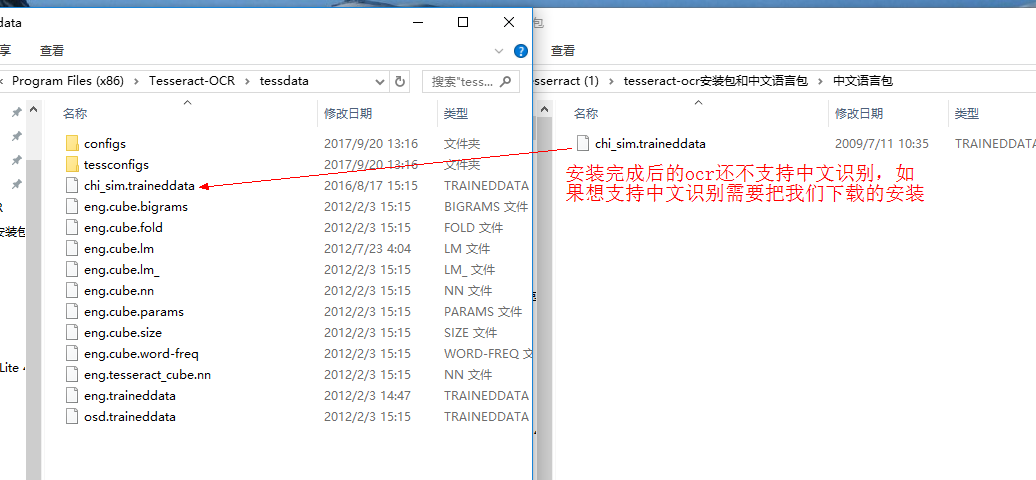
并将训练好的模型文件 chi_sim.traineddata 放入该目录中,这样安装就完成了。
在命令行 WIN+R 输入cmd :输入 tesseract -v ,出现版本信息,则配置成功。

tesseract-ocr默认不支持中文识别。支持中文识别.png
3、解决pytesseract 找不到路径的问题。
在自己安装的pytesseract包中,找到pytesseract.py文件
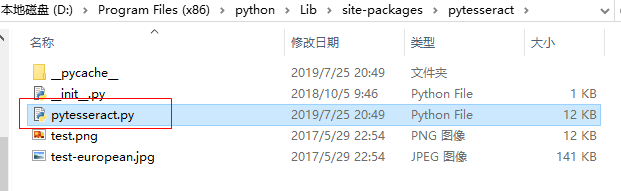
打开pytesseract.py文件,修改 tesseract_cmd 的值:tesseract.exe 的安装路径 。
为了避免其他的错误,使用双反斜杠,或者斜杠
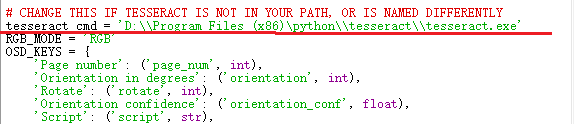
4、简单使用
import pytesseract
from PIL import Image
if __name__ == '__main__':
text = pytesseract.image_to_string(Image.open("D:\\test.png"),lang="eng")
# 如果你想试试Tesseract识别中文,只需要将代码中的eng改为chi_sim即可
print(text)
测试图片:
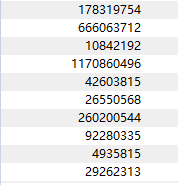
输出结果:
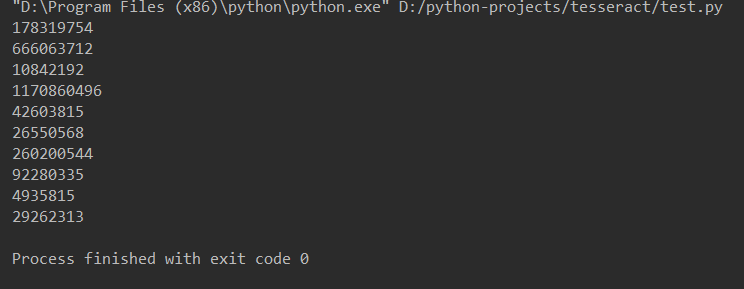
用Tesseract可以识别格式规范的文字,主要具有以下特点:
- 使用一个标准字体(不包含手写体、草书,或者十分“花哨的”字体)
- 虽然被复印或拍照,字体还是很清晰,没有多余的痕迹或污点
- 排列整齐,没有歪歪斜斜的字
- 没有超出图片范围,也没有残缺不全,或紧紧贴在图片的边缘
下面将给出几个tesseract识别图片中文字的例子。
首先是E://figures/other/poems.jpg, 输入命令 tesseract E://figures/other/poems.jpg E://figures/other/poems.txt, 则会将poems.jpg中的识别文字写入到poems.txt中,如下图:



接着是稍微有点倾斜的文字图片th.jpg,识别情况如下:

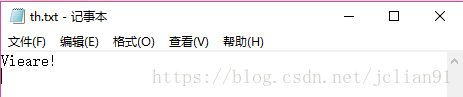
可以看到识别的情况不如刚才规范字体的好,但是也能识别图片中的大部分字母。
最后是识别简体中文,需要事先安装简体中文语言包,下载地址为:https://github.com/tesseract-ocr/tessdata/find/master/chi_sim.traineddata ,再讲chi_sim.traineddata放在C:\Program Files (x86)\Tesseract-OCR\tessdata目录下。我们以图片timg.jpg为例:

输入命令:
tesseract E://figures/other/timg.jpg E://figures/other/timg.txt -l chi_sim
识别结果如下:

只识别错了一个字,识别率还是不错的。
最后加一句,Tesseract对于彩色图片的识别效果没有黑白图片的效果好。
pytesseract
pytesseract是Tesseract关于Python的接口,可以使用pip install pytesseract安装。安装完后,就可以使用Python调用Tesseract了,不过,你还需要一个Python的图片处理模块,可以安装pillow.
输入以下代码,可以实现同上述Tesseract命令一样的效果:
import pytesseract
from PIL import Image
pytesseract.pytesseract.tesseract_cmd = 'C://Program Files (x86)/Tesseract-OCR/tesseract.exe'
text = pytesseract.image_to_string(Image.open('E://figures/other/poems.jpg'))
print(text)
运行结果如下:

cnocr 第二种 Python 开源识别工具的效果
两个工具的使用方法和对比效果。
安装 cnocr:
pip install cnocr
看到 Successfully installed xxx 则说明安装成功。
如果你只想对图片中的中文进行识别,那么 cnocr 是一个不错的选择,你只需要安装 cnocr 包即可。
但如果你想试试其他语言的OCR识别,Tesseract 是更好的选择。
cnocr 识别图片的中文
cnocr 主要针对的是排版简单的印刷体文字图片,如截图图片,扫描件等。目前内置的文字检测和分行模块无法处理复杂的文字排版定位。
尽管它分别提供了单行识别函数和多行识别函数,但在本人实测下,单行识别函数的效果非常糟糕,或者说要求的条件十分苛刻,基本上连截图的文字都识别不出来。
不过多行识别函数还不错,使用该函数识别的代码如下:
from cnocr import CnOcr
ocr = CnOcr()
res = ocr.ocr('test.png')
print("Predicted Chars:", res)
用于识别这个图片里的文字:
效果如下:

如果不是很吹毛求疵,这样的效果已经很不错了。
方法三:调用百度API
优点:使用方便,功能强大
缺点:大量使用需要收费
我自己采用的是调用百度API的方式,下面是我的步骤:
注册百度账号,创建OCR应用可以参考其他教程。
购买后使用python调用方法
方式一: 通过urllib直接调用,替换自己的api_key和secret_key即可
# coding=utf-8
import sys
import json
import base64
# 保证兼容python2以及python3
IS_PY3 = sys.version_info.major == 3
if IS_PY3:
from urllib.request import urlopen
from urllib.request import Request
from urllib.error import URLError
from urllib.parse import urlencode
from urllib.parse import quote_plus
else:
import urllib2
from urllib import quote_plus
from urllib2 import urlopen
from urllib2 import Request
from urllib2 import URLError
from urllib import urlencode
# 防止https证书校验不正确
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
API_KEY = 'YsZKG1wha34PlDOPYaIrIIKO'
SECRET_KEY = 'HPRZtdOHrdnnETVsZM2Nx7vbDkMfxrkD'
OCR_URL = "https://aip.baidubce.com/rest/2.0/ocr/v1/accurate_basic"
""" TOKEN start """
TOKEN_URL = 'https://aip.baidubce.com/oauth/2.0/token'
"""
获取token
"""
def fetch_token():
params = {'grant_type': 'client_credentials',
'client_id': API_KEY,
'client_secret': SECRET_KEY}
post_data = urlencode(params)
if (IS_PY3):
post_data = post_data.encode('utf-8')
req = Request(TOKEN_URL, post_data)
try:
f = urlopen(req, timeout=5)
result_str = f.read()
except URLError as err:
print(err)
if (IS_PY3):
result_str = result_str.decode()
result = json.loads(result_str)
if ('access_token' in result.keys() and 'scope' in result.keys()):
if not 'brain_all_scope' in result['scope'].split(' '):
print ('please ensure has check the ability')
exit()
return result['access_token']
else:
print ('please overwrite the correct API_KEY and SECRET_KEY')
exit()
"""
读取文件
"""
def read_file(image_path):
f = None
try:
f = open(image_path, 'rb')
return f.read()
except:
print('read image file fail')
return None
finally:
if f:
f.close()
"""
调用远程服务
"""
def request(url, data):
req = Request(url, data.encode('utf-8'))
has_error = False
try:
f = urlopen(req)
result_str = f.read()
if (IS_PY3):
result_str = result_str.decode()
return result_str
except URLError as err:
print(err)
if __name__ == '__main__':
# 获取access token
token = fetch_token()
# 拼接通用文字识别高精度url
image_url = OCR_URL + "?access_token=" + token
text = ""
# 读取测试图片
file_content = read_file('test.jpg')
# 调用文字识别服务
result = request(image_url, urlencode({'image': base64.b64encode(file_content)}))
# 解析返回结果
result_json = json.loads(result)
print(result_json)
for words_result in result_json["words_result"]:
text = text + words_result["words"]
# 打印文字
print(text)
方式二:通过HTTP-SDK模块进行调用
from aip import AipOcr
APP_ID = '25**9878'
API_KEY = 'VGT8y***EBf2O8xNRxyHrPNr'
SECRET_KEY = 'ckDyzG*****N3t0MTgvyYaKUnSl6fSw'
client = AipOcr(APP_ID,API_KEY,SECRET_KEY)
def get_file_content(filePath):
with open(filePath, 'rb') as fp:
return fp.read()
image = get_file_content('test.jpg')
res = client.basicGeneral(image)
print(res)
#res = client.basicAccurate(image)
#print(res)
直接识别屏幕指定区域上的文字
from aip import AipOcr APP_ID = '25**9878' API_KEY = 'VGT8y***EBf2O8xNRxyHrPNr' SECRET_KEY = 'ckDyzG*****N3t0MTgvyYaKUnSl6fSw' client = AipOcr(APP_ID,API_KEY,SECRET_KEY) from io import BytesIO from PIL import ImageGrab out_buffer = BytesIO() img = ImageGrab.grab((100,200,300,400)) img.save(out_buffer,format='PNG') res = client.basicGeneral(out_buffer.getvalue()) print(res)
总结
到此这篇关于python实战教程之OCR文字识别方法的文章就介绍到这了,更多相关python OCR文字识别内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python 3调用百度OCR API实现剪贴板文字识别
本程序调用百度OCR API对剪贴板的图片文字识别,配合CaptureScreen软件,可快速识别文字. #!python3 import urllib.request, urllib.parse import os, io, sys, json, socket import base64 from PIL import ImageGrab socket.setdefaulttimeout(30) def get_auth(): apikey = 'your apikey' secret_key
-

Python 实现任意区域文字识别(OCR)操作
本文的OCR当然不是自己从头开发的,是基于百度智能云提供的API(我感觉是百度在中国的人工智能领域值得称赞的一大贡献),其提供的API完全可以满足个人使用,相对来说简洁准确率高. 安装OCR Python SDK OCR Python SDK目录结构 ├── README.md ├── aip //SDK目录 │ ├── __init__.py //导出类 │ ├── base.py //aip基类 │ ├── http.py //http请求 │ └── ocr.py //OCR └── se
-
Python图像处理之图片文字识别功能(OCR)
OCR与Tesseract介绍 将图片翻译成文字一般被称为光学文字识别(Optical Character Recognition,OCR).可以实现OCR 的底层库并不多,目前很多库都是使用共同的几个底层OCR 库,或者是在上面进行定制. Tesseract 是一个OCR 库,目前由Google 赞助(Google 也是一家以OCR 和机器学习技术闻名于世的公司).Tesseract 是目前公认最优秀.最精确的开源OCR 系统. 除 了极高的精确度,Tesseract 也具有很高的灵活性.它可
-
python调用文字识别OCR轻松搞定验证码
今天带你们去研究一个有趣的东西,文字识别OCR.不知道你们有没有想要识别图片,然后读出文字的功能.例如验证码,如果需要自动填写的话就需要这功能.还有很多种情况需要这功能的. 我们可以登录百度云,然后看看里面的接口文档.接口功能还是有比较丰富的应用场景的. # encoding:utf-8 import requests import base64 ''' 通用文字识别 ''' request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/gene
-
Python调用百度OCR实现图片文字识别的示例代码
百度AI提供了一天50000次的免费文字识别额度,可以愉快的免费使用!下面直接上方法: 首先在百度AI创建一个应用,按照下图创建即可,创建后会获得如下: 创建后会获得如下信息: APP_ID = '******' API_KEY = '************' SECRET_KEY = '**************' 下面就是百度API包的安装,在终端cmd输入如下语句直接pip方式安装,注意是 baidu-api 哦! pip install --user baidu-aip 接下来上py
-
Python 图片文字识别的实现之PaddleOCR
目录 项目使用 项目结构 环境部署 1.安装Anaconda,构造虚拟环境 2.依赖包下载 测试代码 参数补充 总结 前言 什么是OCR? 光学字符识别(Optical Character Recognition, OCR),是指对文本资料的图像文件进行分析识别处理,获取文字及版面信息的过程.简而言之,检测图像中的文本资料,并且识别出文本的内容. 那么有哪些应用场景呢? 其实我们日常生活中处处都有ocr的影子,比如在疫情期间身份证识别录入信息.车辆车牌号识别.自动驾驶等.我们的生活中,机器学习已
-
Python基于百度AI实现OCR文字识别
百度AI功能还是很强大的,百度AI开放平台真的是测试接口的天堂,免费接口很多,当然有量的限制,但个人使用是完全够用的,什么人脸识别.MQTT服务器.语音识别等等,应有尽有. 看看OCR识别免费的量 快速安装:执行pip install baidu-aip即可 新建一个AipOcr: from aip import AipOcr """ 你的 APPID AK SK """ APP_ID = '你的 App ID' API_KEY = '你的 Ap
-
Python3使用腾讯云文字识别(腾讯OCR)提取图片中的文字内容实例详解
百度OCR体验地址: https://ai.baidu.com/tech/imagerecognition/general 腾讯OCR体验地址: https://cloud.tencent.com/act/event/ocrdemo 测试结果是:腾讯的效果要比百度的好 腾讯云目前额度是: 每个接口 1,000次/月免费,有6个文字识别的接口,一共是6,000次/月 百度接口调用之前写过文章 python实现百度OCR图片识别过程解析 使用步骤 1.注册账号: https://cloud.tenc
-
基于Python实现图像文字识别OCR工具
目录 引言 功能列表 OCR部分 界面部分 软件代码 参考链接 引言 最近在技术交流群里聊到一个关于图像文字识别的需求,在工作.生活中常常会用到,比如票据.漫画.扫描件.照片的文本提取. 博主基于 PyQt + PaddleOCR 写了一个桌面端的OCR工具,用于快速实现图片中文本区域自动检测+文本自动识别. 识别效果如下图所示: 所有框选区域为OCR算法自动检测,右侧列表有每个框对应的文字内容: 点击右侧"识别结果"中的文本记录,然后点击"复制到剪贴板"即可复制该
-
python基础教程之lambda表达式使用方法
Python中,如果函数体是一个单独的return expression语句,开发者可以选择使用特殊的lambda表达式形式替换该函数: 复制代码 代码如下: lambda parameters: expression lambda表达式相当于函数体为单个return语句的普通函数的匿名函数.请注意,lambda语法并没有使用return关键字.开发者可以在任何可以使用函数引用的位置使用lambda表达式.在开发者想要使用一个简单函数作为参数或者返回值时,使用lambda表达式是很方便的.下面是
-
Python GUI教程之在PyQt5中使用数据库的方法
目录 PyQt5的SQL数据库支持 在PyQt5中简单使用数据库 创建一个UI界面 连接一个数据库 在UI界面查看和修改数据 添加和删除数据 在桌面图像化界面编程中,我们通常需要将一些数据或配置信息存储在本地.在本地进行数据的存储,我们可以直接使用文本文件,比如ini文件.csv文件.json文件等,或者是使用文件型的数据库(比如sqlit3)进行存储. PyQt5的SQL数据库支持 Qt平台对SQL编程有着良好的支持,PyQt5也一并继承了过来.在PyQt5中,QtSql子模块提供对SQL数据
-
Python Pandas教程之series 上的转换操作
前言: 在转换操作中,我们执行各种操作,例如更改系列的数据类型,将系列更改为列表等.为了执行转换操作,我们有各种有助于转换的功能,例如.astype()等.tolist(). 代码#1: # 使用 astype 转换 series 数据类型的 Python 程序 # importing pandas module import pandas as pd # 从 url 读取 csv 文件 data = pd.read_csv("nba.csv") # 删除空值列以避免错误 data.d
-
java实现百度云OCR文字识别 高精度OCR识别身份证信息
本文为大家分享了java实现百度云OCR识别的具体代码,高精度OCR识别身份证信息,供大家参考,具体内容如下 1.通用OCR文字识别 这种OCR只能按照识别图片中的文字,且是按照行识别返回结果,精度较低. 首先引入依赖包: <dependency> <groupId>com.baidu.aip</groupId> <artifactId>java-sdk</artifactId> <version>4.6.0</version&
-
不到十行实现javaCV图片OCR文字识别
spring boot项目pom文件中添加以下依赖 <!-- https://mvnrepository.com/artifact/org.bytedeco/javacv-platform --> <dependency> <groupId>org.bytedeco</groupId> <artifactId>javacv-platform</artifactId> <version>1.5.5</version&g
-
Python基础教程之pytest参数化详解
目录 前言 源代码分析 装饰测试类 装饰测试函数 单个数据 一组数据 组合数据 标记用例 嵌套字典 增加测试结果可读性 总结 前言 上篇博文介绍过,pytest是目前比较成熟功能齐全的测试框架,使用率肯定也不断攀升.在实际 工作中,许多测试用例都是类似的重复,一个个写最后代码会显得很冗余.这里,我们来了解一下 @pytest.mark.parametrize装饰器,可以很好的解决上述问题. 源代码分析 def parametrize(self,argnames, argvalues, indir
-
vue3实战教程之axios的封装和环境变量
目录 axios 基本使用 配置 封装 请求时添加loading 环境变量 总结 axios axios: ajax i/o system. 一个可以同时在浏览器和node环境进行网络请求的第三方库 功能特点: 在浏览器中发送 XMLHttpRequests 请求 在 node.js 中发送 http请求 支持 Promise API 拦截请求和响应 转换请求和响应数据 等等 基本使用 get请求 // 导入的axios是一个实例对象 import axios from 'axios' // a
-
python爬虫教程之bs4解析和xpath解析详解
目录 bs4解析 原理: 如何实例化BeautifulSoup对象: 用于数据解析的方法和属性: xpath解析 xpath解析原理: 实例化一个etree对象: xpath(‘xpath表达式’) 总结 bs4解析 原理: 1.实例化一个BeautifulSoup对象,并且将页面源码数据加载到该对象中 2.通过调用BeautifulSoup对象中相关的属性或者方法进行标签定位和数据提取 如何实例化BeautifulSoup对象: from bs4 import BeautifulSoup Be
-
python基础教程之csv格式文件的写入与读取
目录 csv的简单介绍 csv的写入 第一种写入方法(通过创建writer对象) 第二种写入方法(使用DictWriter可以使用字典的方式将数据写入) csv的读取 通过reader()读取 通过dictreader()读取 总结 csv的简单介绍 CSV (Comma Separated Values),即逗号分隔值(也称字符分隔值,因为分隔符可以不是逗号),是一种常用的文本格式,用以存储表格数据,包括数字或者字符.很多程序在处理数据时都会碰到csv这种格式的文件.python自带了csv模
-
Python基础教程之pip的安装和卸载
目录 一.pip的安装: 二.pip的卸载: 三.列出已安装的版本 1.pip list 2.pip freeze 四.换源安装 总结 一.pip的安装: win+R出现一下界面 然后输入cmd点击确定,出现以下界面,就可进行下载 以下是两种下载方法 1.普通安装:pip install 模板名 2.指定版本安装:pip install 模板名==版本 二.pip的卸载: pip uninstall 模板名 出现此界面,输入y确定卸载,输入n取消卸载 出现Successfully即卸载成功 三.