ShardingSphere数据库读写分离算法及测试示例详解
目录
- 码农在囧途
- 背景
- 一主多从
- 多主多从
- ShardingSphere整合SpringBoot项目进行主从分离
- maven引入ShardingSphere starter
- yml文件配置
- 测试写操作。
- 测试读操作
- ShardingSphere负载均衡算法
- ROUND_ROBIN 轮询算法
- RANDOM 随机算法
- WEIGHT 基于权重的算法
- 在ShardingSphere中自定义负载均衡算法
- 定义SPI
- 编写负载均衡算法核心代码
- 在yml中使用自己实现的负载均衡算法
- 发起大量的查询操作
码农在囧途
最近这段时间来经历了太多东西,无论是个人的压力还是个人和团队失误所带来的损失,都太多,被骂了很多,也被检讨,甚至一些不方便说的东西都经历了,不过还好,一切都得到了解决,无论好坏,这对于个人来说也是一种成长吧,事后自己也做了一些深刻的检讨,总结为一句话“挫败使你难受,使你睡不着觉,使你痛苦,不过最后一定会使你变得成熟,变得认真,变得负责”,每次面临挫败,我都会告诉自己,这不算什么,十年之后,你回过头来看待这件事的时候,你一定会觉得,这算什么屁事。
背景
在现在这个数据量与日俱增的时代,传统的单表,单库已经无法满足我们的需求,可能早期数据量不是很大,CRUD都集中在一个库中,但是当数据量 到达一定的规模的时候,使用单库可能就无法满足需求了,在实际场景中,读的频率是远远大于写的,所以我们一般会做读写分离,主库一般用于写,而从库 用于读,而主从分离有好几种模式。
一主多从
一主多从是只有一台主机用于写操作,多台从机用于读操作,一主多从是存在风险的,当主机宕机后,那么写服务就会瘫痪,本文我们主要说的是ShardingSphere读写分离, 而目前ShardingSphere只支持单主库,所以如果要保证业务的高可用,那么目前ShardingSphere不是很好的选择,不过希望ShardingSphere后面支持多主机模式。
多主多从
从上面的一主多从我们看出了它的弊端,所以为了保证高可用,我们可能需要多个主机用于写操作,这样当某个主机宕机,其他主机还能继续工作,ShardingSphere只支持 单主机。
ShardingSphere只需要简单的配置就能实现数据库的读写的分离,我们甚至感知不到是在操作多个数据库,极大的简化了我们的开发,但是ShardingSphere 不支持多主库,也无法进行主从数据库的同步。
ShardingSphere整合SpringBoot项目进行主从分离
ShardingSphere和SpringBoot能够很简单的进行组合,只需要简单的配置,ShardingSphere能够和主流的ORM框架进行整合,ShardingSphere会 从ORM框架中解析出SQL语句,判断是读操作还是写操作,如果是读操作,则会落到主库上,如果是读操作,那么ShardingSphere会使用对应的负载均衡算法负载到 对应的从库上面。
maven引入ShardingSphere starter
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>shardingsphere-jdbc-core-spring-boot-starter</artifactId>
<version>5.1.2</version>
</dependency>
yml文件配置
names为数据库名称字符串,然后需要一个一个的进行配置JDBC连接,对于读写分离,我们需要关注rules下面的readwrite-splitting 通过load-balancers配置负载均衡策略,data-sources配置对应的读写库,目前ShardingSphere只支持单主库,多从库,如下我们写 库使用write-data-source-name,库为db1,读库使用read-data-source-names,库db2,db3,db4。
spring:
shardingsphere:
datasource:
names: db1,db2,db3,db4
db1:
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3306/db1?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai
username: root
password: qwer123@
type: com.zaxxer.hikari.HikariDataSource
maximumPoolSize: 10
db2:
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3306/db2?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai
username: root
password: qwer123@
type: com.zaxxer.hikari.HikariDataSource
maximumPoolSize: 10
db3:
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3306/db3?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai
username: root
password: qwer123@
type: com.zaxxer.hikari.HikariDataSource
maximumPoolSize: 10
db4:
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://localhost:3306/db4?useUnicode=true&characterEncoding=utf-8&useSSL=false&serverTimezone=Asia/Shanghai
username: root
password: qwer123@
type: com.zaxxer.hikari.HikariDataSource
maximumPoolSize: 10
rules:
sharding:
readwrite-splitting:
load-balancers:
round_robin:
type: ROUND_ROBIN
data-sources:
read_write_db:
type: Static
props:
write-data-source-name: db1
read-data-source-names: db2,db3,db4
load-balancer-name: round_robin
props:
sql-show: true
测试写操作。
因为写操作配置的数据库是db1,所以所有写操作都应该进入db1,如下图所示,解析出来的ShardingSphere-SQL中显示的都是db1。

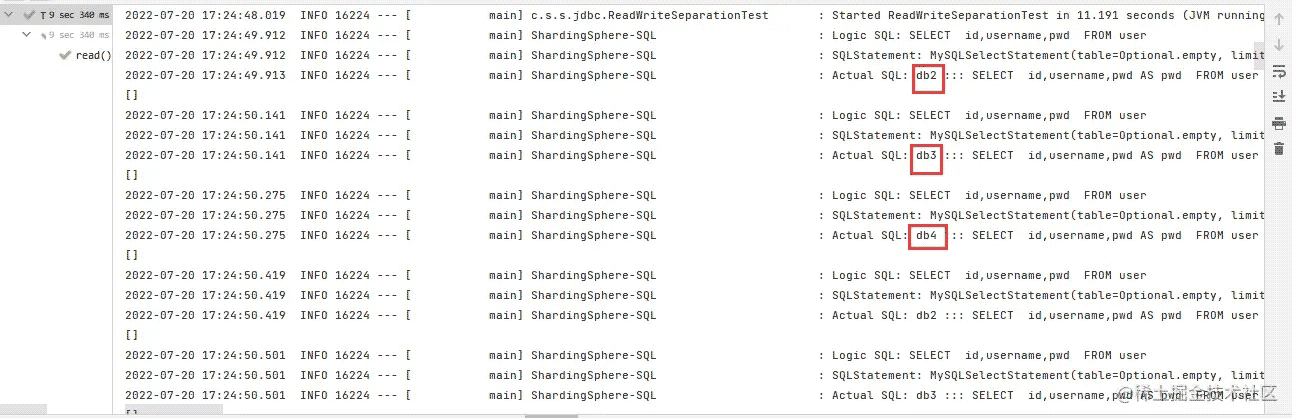
测试读操作
读操作配置的数据库是db2,db3,db4,配置的负载均衡算法是ROUND_ROBIN(轮询算法),所以查询请求会在三个库顺序查询。
ShardingSphere负载均衡算法
因为从库有多个,所以我们需要根据一定的策略将请求分发到不同的数据库上,防止单节点的压力过大或者空闲,ShardingSphere内置了多种负载均衡算法,如果我们想实现自己的 算法,那么可以实现ReadQueryLoadBalanceAlgorithm接口,下面我们列举几种来看下。
ROUND_ROBIN 轮询算法
配置负载均衡算法为轮询算法,那么所有请求都会均匀的分发到对应的数据库,这样,每台数据库所承受的压力都是一样的,轮询算法对应的实现类是RoundRobinReplicaLoadBalanceAlgorithm。
public final class RoundRobinReplicaLoadBalanceAlgorithm implements ReadQueryLoadBalanceAlgorithm {
private final AtomicInteger count = new AtomicInteger(0);
@Getter
private Properties props;
@Override
public void init(final Properties props) {
this.props = props;
}
@Override
public String getDataSource(final String name, final String writeDataSourceName, final List<String> readDataSourceNames) {
if (TransactionHolder.isTransaction()) {
return writeDataSourceName;
}
return readDataSourceNames.get(Math.abs(count.getAndIncrement()) % readDataSourceNames.size());
}
@Override
public String getType() {
return "ROUND_ROBIN";
}
@Override
public boolean isDefault() {
return true;
}
}
RANDOM 随机算法
如果使用随机算法,那么请求过来以后就会随机的分发到其中的一个数据库上面,使用随机算法可能会导致请求的分发不均匀,可能某一台 接受到了大量的请求,某一台接受到的请求相对来说较少。
WEIGHT 基于权重的算法
基于权重的算法需要做相应的配置,我们可以将某一台数据库的权重加大,某一台数据库的权重减小,这样,权重大的数据库 就会接收到更多的请求,权重小的接收到的请求就会比较少。
在ShardingSphere中自定义负载均衡算法
ShardingSphere中使用了大量的SPI,所以我们开发者可以自由的实现自己的规则,然后无缝的切换到自己的规则,我们可以实现自己的一套负载均衡算法,其实ShardingSphere内置的集中负载均衡算法完全能满足数据库负载均衡,只不过为了更加深入的学习ShardingSphere,所以我们很有必要自己简单的实现一下。
下面我们简单的实现一下,我们就不去实现一些复杂的了,为了演示,我们将所有请求全部都负载到db2。
定义SPI
我们从ShardingSphere的读写分离模块shardingspere-readwrite-spliltting-core中的META-INF/services下面看到了负载均衡的SPI。
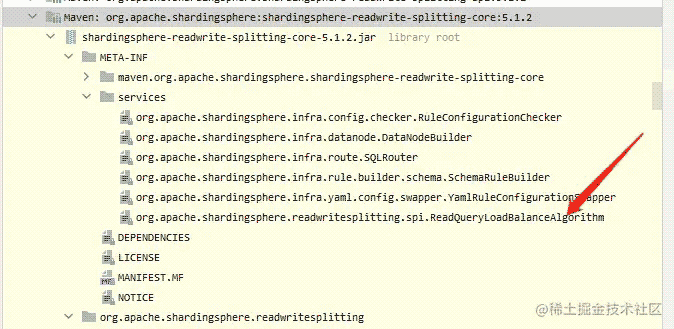
org.apache.shardingsphere.readwritesplitting.algorithm.loadbalance.RoundRobinReplicaLoadBalanceAlgorithm org.apache.shardingsphere.readwritesplitting.algorithm.loadbalance.RandomReplicaLoadBalanceAlgorithm org.apache.shardingsphere.readwritesplitting.algorithm.loadbalance.WeightReplicaLoadBalanceAlgorithm org.apache.shardingsphere.readwritesplitting.algorithm.loadbalance.FixedPrimaryLoadBalanceAlgorithm org.apache.shardingsphere.readwritesplitting.algorithm.loadbalance.FixedReplicaRandomLoadBalanceAlgorithm org.apache.shardingsphere.readwritesplitting.algorithm.loadbalance.FixedReplicaRoundRobinLoadBalanceAlgorithm org.apache.shardingsphere.readwritesplitting.algorithm.loadbalance.FixedReplicaWeightLoadBalanceAlgorithm org.apache.shardingsphere.readwritesplitting.algorithm.loadbalance.TransactionRandomReplicaLoadBalanceAlgorithm org.apache.shardingsphere.readwritesplitting.algorithm.loadbalance.TransactionRoundRobinReplicaLoadBalanceAlgorithm org.apache.shardingsphere.readwritesplitting.algorithm.loadbalance.TransactionWeightReplicaLoadBalanceAlgorithm
为了实现自己的负载均衡算法,我们需要在自己的模块中定义SPI,如下,在自己项目的META-INF/services目录下编写负载均衡SPI接口,里面内容为我们自定义的负载均衡算法的类文件的位置。
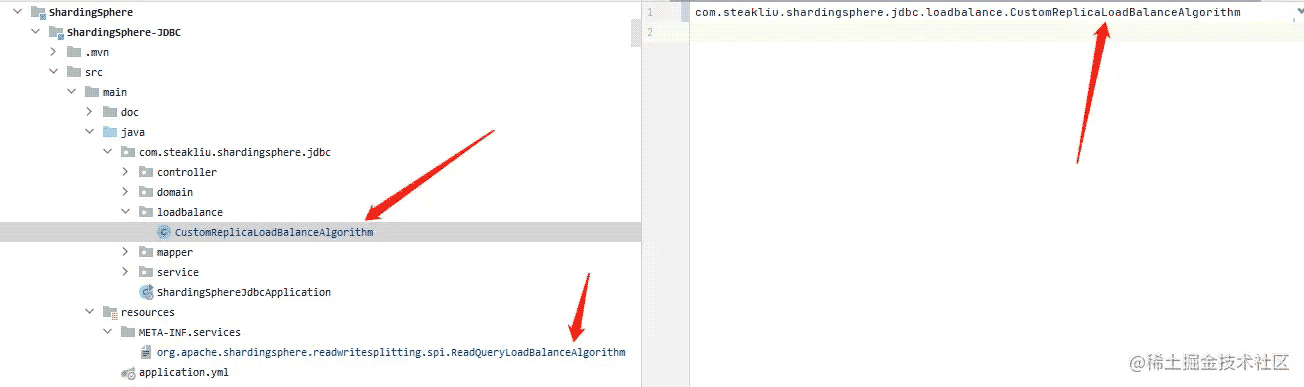
编写负载均衡算法核心代码
自定义负载均衡算法需要实现ReadQueryLoadBalanceAlgorithm接口,里面核心的两个方法是getDataSource和getType,getDataSource是算法的逻辑实现部分,其目的是选出一个目标数据库,此方法会传入readDataSourceNames,它是读库的集合,我们此处直接返回db2,那么会一直读db2,getType是返回负载均衡算法的名称。
/**
* 功能说明: 自定义负载均衡算法
* <p>
* Original @Author: steakliu-刘牌, 2022-07-20 18:05
* <p>
* Copyright (C)2020-2022 steakliu All rights reserved.
*/
public class CustomReplicaLoadBalanceAlgorithm implements ReadQueryLoadBalanceAlgorithm {
@Getter
private Properties props;
@Override
public String getDataSource(final String name, final String writeDataSourceName, final List<String> readDataSourceNames) {
return "db2";
}
@Override
public String getType() {
return "CUSTOM";
}
@Override
public void init(Properties props) {
this.props = props;
}
@Override
public boolean isDefault() {
return false;
}
}
在yml中使用自己实现的负载均衡算法
rules:
sharding:
readwrite-splitting:
load-balancers:
custom:
type: CUSTOM
data-sources:
read_write_db:
type: Static
props:
write-data-source-name: db1
read-data-source-names: db2,db3,db4
load-balancer-name: custom
发起大量的查询操作
从日志输出来看,所有的请求全部落在了db2上面,于是证明我们自定义的负载均衡算法成功了。

读写分离的中间件其实有很多,ShardingSphere旨在构建异构数据库上层的标准和生态,使用它我们基本上能解决数据库中的大部分问题,但是ShardingSphere也并不是万能的,还有一些东西没有实现,我们期待ShardingSphere能够实现更多强大,好用的功能。
关于ShardingSphere读写分离的分享,我们今天就先说到这里,后面我们会继续探索ShardingSphere的更多强大的功能,比如数据分片,高可用,数据加密,影子库等,今天的分享就到这里,更多关于ShardingSphere读写分离的资料请关注我们其它相关文章!
相关推荐
-

使用shardingsphere对SQLServer坑的解决
背景:最近一个使用SQLServer的项目,业务量太大,开始对业务有影响了,因此用户要求升级改造,技术上采用shardingsphere进行分库分表. 经过一系列调研,设计...哐哐一顿操作之后开始动刀改造.pom依赖如下: <!--sharding--> <dependency> <groupId>org.apache.shardingsphere</groupId> <artifactId>sharding-jdbc-spring-boot-
-
ShardingSphere解析SQL示例详解
目录 引言 解析Sql的入口 解析Sql 1. 将 SQL 解析为抽象语法树 2. 提取Sql片段 3. 填充Sql片段,生成解析结果 总结 引言 ShardingSphere的SQL解析,本篇文章源码基于4.0.1版本 ShardingSphere的分片引擎从解析引擎到路由引擎到改写引擎到执行引擎再到归并引擎,一步一步对分片操作进行处理,我们这篇文章先从解析引擎开始,深入分析一下Sql的解析引擎处理流程. 解析Sql的入口 SQLParseEngine这个类是sql解析引擎对应的类,通过看它的
-
ShardingSphere jdbc实现分库分表核心概念详解
目录 ShardingSphere Sharding-JDBC Sharding-JDBC包含的一些核心概念 分片策略算法 分片算法 分片策略 分片策略配置类 ShardingSphere ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC.Sharding-Proxy和Sharding-Sidecar(计划中)这3款相互独立的产品组成.他们均提供标准化的数据分片.分布式事务和数据库治理功能. Sharding-JDBC 定位为轻量级J
-
java开发ShardingSphere的路由引擎类型示例详解
目录 ShardingSphere的路由引擎类型 路由引擎类型 标准路由 路由逻辑 总结 ShardingSphere的路由引擎类型 本篇文章源码基于4.0.1版本 上篇文章我们了解到了ShardingSphere在路由流程过程中,根据不同类型的SQL会现在不同的路由引擎,而ShardingSphere支持的路由规则也很多了,包括广播(broadcast)路由.混合(complex)路由.默认数据库(defaultdb)路由.无效(ignore)路由.标准(standard)路由以及单播(uni
-
TypeScript实现十大排序算法之冒泡排序示例详解
目录 一. 冒泡排序的定义 二. 冒泡排序的流程 三. 冒泡排序的图解 四. 冒泡排序的代码 五. 冒泡排序的时间复杂度 六. 冒泡排序的总结 一. 冒泡排序的定义 冒泡排序是一种简单的排序方法. 基本思路是通过两两比较相邻的元素并交换它们的位置,从而使整个序列按照顺序排列. 该算法一趟排序后,最大值总是会移到数组最后面,那么接下来就不用再考虑这个最大值. 一直重复这样的操作,最终就可以得到排序完成的数组. 这种算法是稳定的,即相等元素的相对位置不会发生变化. 而且在最坏情况下,时间复杂度为O(
-
C语言编程题杨氏矩阵算法快速上手示例详解
目录 题目概要 一.解题思路 二.具体代码 题目概要 有一个数字矩阵,矩阵的每行从左到右都是递增的,矩阵从上到下都是递增的,请编写程序在这样的矩阵中查找某个数字是否存在? 一.解题思路 对于查找一个数组中元素是否存在,很多同学第一想法就是从头到尾遍历一遍.这样的想法优点是代码简单且无脑容易上手,但是这样的缺点也很明显,比如是m *n的数组,你从头到尾遍历,最坏情况要找m *n次.题目给的相关条件比如从左向右递增,从上向下递增你也完全没有使用,这样的暴力求解显然不是我们想看到的 我们来介绍一种方法
-
java数据结构算法稀疏数组示例详解
目录 一.什么是稀疏数组 二.场景用法 1.二维数组转稀疏数组思路 2.稀疏数组转二维数组思路 3.代码实现 一.什么是稀疏数组 当一个数组a中大部分元素为0,或者为同一个值,那么可以用稀疏数组b来保存数组a. 首先,稀疏数组是一个数组,然后以一种特定的方式来保存上述的数组a,具体处理方法: 记录数组a一共有几行几列 记录a中有多少个不同的值 最后记录不同值的元素所在行列,以及具体的值,放在一个小规模的数组里,以缩小程序的规模. 这个小规模的数组,就是稀疏数组. 举个栗子,左侧是一个二维数组,一
-
Go&java算法之最大数示例详解
目录 最大数 方法一:排序(java) 方法一:排序(go) 最大数 给定一组非负整数 nums,重新排列每个数的顺序(每个数不可拆分)使之组成一个最大的整数. 注意:输出结果可能非常大,所以你需要返回一个字符串而不是整数. 示例 1: 输入:nums = [10,2] 输出:"210" 示例 2: 输入:nums = [3,30,34,5,9] 输出:"9534330" 提示: 1 <= nums.length <= 100 0 <= nums[
-
Oracle统计信息的导出导入测试示例详解
背景: 有时我们会希望可以对Oracle的统计信息整体进行导出导入.比如在数据库迁移前后,希望统计信息保持不变;又比如想对统计信息重新进行收集,但是担心重新收集的结果反而引发性能问题,想先保存当前的统计信息,这样即使重新收集后效果不好还可以导入之前的统计信息. Oracle提供给我们一些方法,比较常用的粒度有两种: schema级别统计信息的导出导入 通过调用DBMS_STATS.EXPORT_SCHEMA_STATS和DBMS_STATS.IMPORT_SCHEMA_STATS来进行. dat
-
python3+telnetlib实现简单自动测试示例详解
目录 1 telnetlib介绍 1.1 简介 1.2 库常用函数及使用 1.2.1 建立连接 1.2.2 发送命令 1.2.3 读取返回数据 1.2.4 关闭连接 1.3 使用示例 2 自动测试 1 telnetlib介绍 1.1 简介 官方介绍文档:telnetlib – Telnet 客户端 - Python 3.9.6 文档 telnetlib 模块提供一个实现Telnet协议的类 Telnet. 1.2 库常用函数及使用 1.2.1 建立连接 建立连接有两种方式:1.实例化函数的时候,
-
Python web框架(django,flask)实现mysql数据库读写分离的示例
读写分离,顾名思义,我们可以把读和写两个操作分开,减轻数据的访问压力,解决高并发的问题. 那么我们今天就Python两大框架来做这个读写分离的操作. 1.Django框架实现读写分离 Django做读写分离非常的简单,直接在settings.py中把从机加入到数据库的配置文件中就可以了. DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'HOST': '127.0.0.1', # 主服务器的运行ip 'PORT':
-
spring集成mybatis实现mysql数据库读写分离
前言 在网站的用户达到一定规模后,数据库因为负载压力过高而成为网站的瓶颈.幸运的是目前大部分的主流数据库都提供主从热备功能,通过配置两台数据库主从关系,可以将一台数据库的数据更新同步到另一台服务器上.网站利用数据库的这一功能,实现数据库读写分离,从而改善数据库负载压力.如下图所示: 应用服务器在写数据的时候,访问主数据库,主数据库通过主从复制机制将数据更新同步到从数据库,这样当应用服务器读数据的时候,就可以通过从数据库获得数据.为了便于应用程序访问读写分离后的数据库,通常在应用服务器使用专门的数
-
详解如何利用amoeba(变形虫)实现mysql数据库读写分离
关于mysql的读写分离架构有很多,百度的话几乎都是用mysql_proxy实现的.由于proxy是基于lua脚本语言实现的,所以网上不少网友表示proxy效率不高,也不稳定,不建议在生产环境使用: amoeba是阿里开发的一款数据库读写分离的项目(读写分离只是它的一个小功能),由于是基于java编写的,所以运行环境需要安装jdk: 前期准备工作: 1.两个数据库,一主一从,主从同步: master: 172.22.10.237:3306 :主库负责写入操作: slave: 10.4.66.58
-
Spring AOP切面解决数据库读写分离实例详解
Spring AOP切面解决数据库读写分离实例详解 为了减轻数据库的压力,一般会使用数据库主从(master/slave)的方式,但是这种方式会给应用程序带来一定的麻烦,比如说,应用程序如何做到把数据写到master库,而读取数据的时候,从slave库读取.如果应用程序判断失误,把数据写入到slave库,会给系统造成致命的打击. 解决读写分离的方案很多,常用的有SQL解析.动态设置数据源.SQL解析主要是通过分析sql语句是insert/select/update/delete中的哪一种,从而对