SpringCloud Gateway加载断言predicates与过滤器filters的源码分析
我们今天的主角是Gateway网关,一听名字就知道它基本的任务就是去分发路由。根据不同的指定名称去请求各个服务,下面是Gateway官方的解释:
https://spring.io/projects/spring-cloud-gateway,其他的博主就不多说了,大家多去官网看看,只有官方的才是最正确的,回归主题,我们的过滤器与断言如何加载进来的,并且是如何进行对请求进行过滤的。
大家如果对SpringBoot自动加载的熟悉的话,一定知道要看一个代码的源码,要找到META-INF下的spring.factories,具体为啥的博主就不多说了,网上也有很多讲解自动加载的源码分析,今天就讲解Gateway,所有项目三板斧:加依赖、写注解、弄配置
依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
注解:启动类上需要添加@EnableDiscoveryClient,启动服务发现
配置:
spring:
cloud:
gateway:
routes:
- id: after-route #id必须要唯一
uri: lb://product-center
predicates:
- After=2030-12-16T15:53:22.999+08:00[Asia/Shanghai]
filters:
- PrefixPath=/product-api
大家看到这个配置的时候,为什么我们写After断言与PrefixPath过滤器,gateway就会自动识别呢,那我们有没有那一个地方可以看到所有的自带的属性呢?当然有,而且我们本篇就主要讲解为什么gateway会自动识别,并且我们要自己实现并且添加自定义属性。开始源码解析第一步,找到自动加载的类一探究竟;
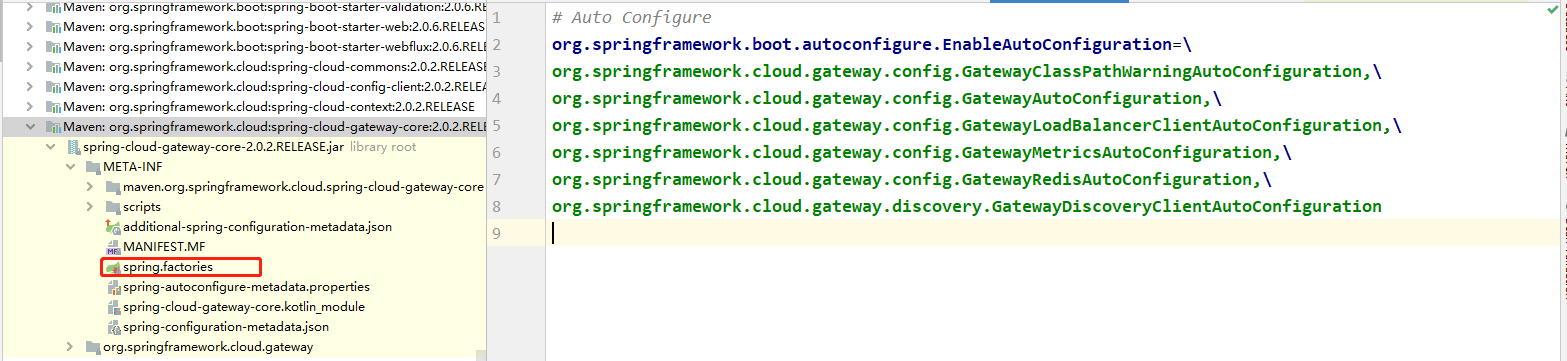
看到这里的时候,第一步就成功了,剩下的就是找到org.springframework.cloud.gateway.config.GatewayAutoConfiguration这个关键类,我们主要看看里面的两个类
@Bean
public RouteLocator routeDefinitionRouteLocator(GatewayProperties properties,
List<GatewayFilterFactory> GatewayFilters,
List<RoutePredicateFactory> predicates,
RouteDefinitionLocator routeDefinitionLocator) {
return new RouteDefinitionRouteLocator(routeDefinitionLocator, predicates, GatewayFilters, properties);
}
@Bean
@Primary
//TODO: property to disable composite?
public RouteLocator cachedCompositeRouteLocator(List<RouteLocator> routeLocators) {
return new CachingRouteLocator(new CompositeRouteLocator(Flux.fromIterable(routeLocators)));
}
这俩个类配置,大家可能非常熟悉,大家上手一个新知识点的时候,肯定会找一些快速入门的文章看看,博主还是习惯直接找官方的quick start来看,大家可以看看这些快速上手项目:https://spring.io/guides/gs/gateway/
所以博主直接就找到了RouteLocator这个类配置,果不其然,我们找到了断言与过滤器的注入,虽然实在方法体内作为参数传入,但是会被spring解析到,直接去工厂里拿到,具体怎么拿呢?我们再来看看:
public BeanWrapper instantiateUsingFactoryMethod(
String beanName, RootBeanDefinition mbd, @Nullable Object[] explicitArgs) {
.....
for (Method candidate : candidates) {
Class<?>[] paramTypes = candidate.getParameterTypes();
if (paramTypes.length >= minNrOfArgs) {
ArgumentsHolder argsHolder;
if (explicitArgs != null) {
// Explicit arguments given -> arguments length must match exactly.
if (paramTypes.length != explicitArgs.length) {
continue;
}
argsHolder = new ArgumentsHolder(explicitArgs);
}
else {
// Resolved constructor arguments: type conversion and/or autowiring necessary.
try {
String[] paramNames = null;
ParameterNameDiscoverer pnd = this.beanFactory.getParameterNameDiscoverer();
if (pnd != null) {
paramNames = pnd.getParameterNames(candidate);
}
//主要就是会进入到这里去解析每一个参数类型
argsHolder = createArgumentArray(beanName, mbd, resolvedValues, bw,
paramTypes, paramNames, candidate, autowiring, candidates.length == 1);
}
catch (UnsatisfiedDependencyException ex) {
if (logger.isTraceEnabled()) {
logger.trace("Ignoring factory method [" + candidate + "] of bean '" + beanName + "': " + ex);
}
// Swallow and try next overloaded factory method.
if (causes == null) {
causes = new LinkedList<>();
}
causes.add(ex);
continue;
}
}
int typeDiffWeight = (mbd.isLenientConstructorResolution() ?
argsHolder.getTypeDifferenceWeight(paramTypes) : argsHolder.getAssignabilityWeight(paramTypes));
// Choose this factory method if it represents the closest match.
if (typeDiffWeight < minTypeDiffWeight) {
factoryMethodToUse = candidate;
argsHolderToUse = argsHolder;
argsToUse = argsHolder.arguments;
minTypeDiffWeight = typeDiffWeight;
ambiguousFactoryMethods = null;
}
// Find out about ambiguity: In case of the same type difference weight
// for methods with the same number of parameters, collect such candidates
// and eventually raise an ambiguity exception.
// However, only perform that check in non-lenient constructor resolution mode,
// and explicitly ignore overridden methods (with the same parameter signature).
else if (factoryMethodToUse != null && typeDiffWeight == minTypeDiffWeight &&
!mbd.isLenientConstructorResolution() &&
paramTypes.length == factoryMethodToUse.getParameterCount() &&
!Arrays.equals(paramTypes, factoryMethodToUse.getParameterTypes())) {
if (ambiguousFactoryMethods == null) {
ambiguousFactoryMethods = new LinkedHashSet<>();
ambiguousFactoryMethods.add(factoryMethodToUse);
}
ambiguousFactoryMethods.add(candidate);
}
}
}
.....
return bw;
}
每一个参数都需要解析,但是看这里不像没关系,继续往下走:就会看到
private ArgumentsHolder createArgumentArray(
String beanName, RootBeanDefinition mbd, @Nullable ConstructorArgumentValues resolvedValues,
BeanWrapper bw, Class<?>[] paramTypes, @Nullable String[] paramNames, Executable executable,
boolean autowiring, boolean fallback) throws UnsatisfiedDependencyException {
....
//这下就是了,每个参数都被进行解析
for (int paramIndex = 0; paramIndex < paramTypes.length; paramIndex++) {
....
try {
//我们的参数就是在这里被进行解析的--resolveAutowiredArgument
Object autowiredArgument = resolveAutowiredArgument(
methodParam, beanName, autowiredBeanNames, converter, fallback);
args.rawArguments[paramIndex] = autowiredArgument;
args.arguments[paramIndex] = autowiredArgument;
args.preparedArguments[paramIndex] = new AutowiredArgumentMarker();
args.resolveNecessary = true;
}
catch (BeansException ex) {
throw new UnsatisfiedDependencyException(
mbd.getResourceDescription(), beanName, new InjectionPoint(methodParam), ex);
}
}
}
//其他不重要的,直接忽略掉
...
return args;
}
开始解析的时看到了,我们需要把断言和过滤器列表都加在进来,那spring是如何加载的呢?是根据方法体内传入的类型找到所有实现了断言和过滤器工厂接口的类并且进行获取实例,我们仔细这些工厂的实现类,就会找到我们的使用的一些属性,比如我们例子中的PrefixPath过滤器和Path断言;
protected Map<String, Object> findAutowireCandidates(
@Nullable String beanName, Class<?> requiredType, DependencyDescriptor descriptor) {
//主要的就是这个,beanNamesForTypeIncludingAncestors方法,该方法就是从bean工厂中获取所有当前类的实现实例名称,
String[] candidateNames = BeanFactoryUtils.beanNamesForTypeIncludingAncestors(
this, requiredType, true, descriptor.isEager());
Map<String, Object> result = new LinkedHashMap<>(candidateNames.length);
...
//遍历名称,进行实例化
for (String candidate : candidateNames) {
if (!isSelfReference(beanName, candidate) && isAutowireCandidate(candidate, descriptor)) {
addCandidateEntry(result, candidate, descriptor, requiredType);
}
}
.....
return result;
}
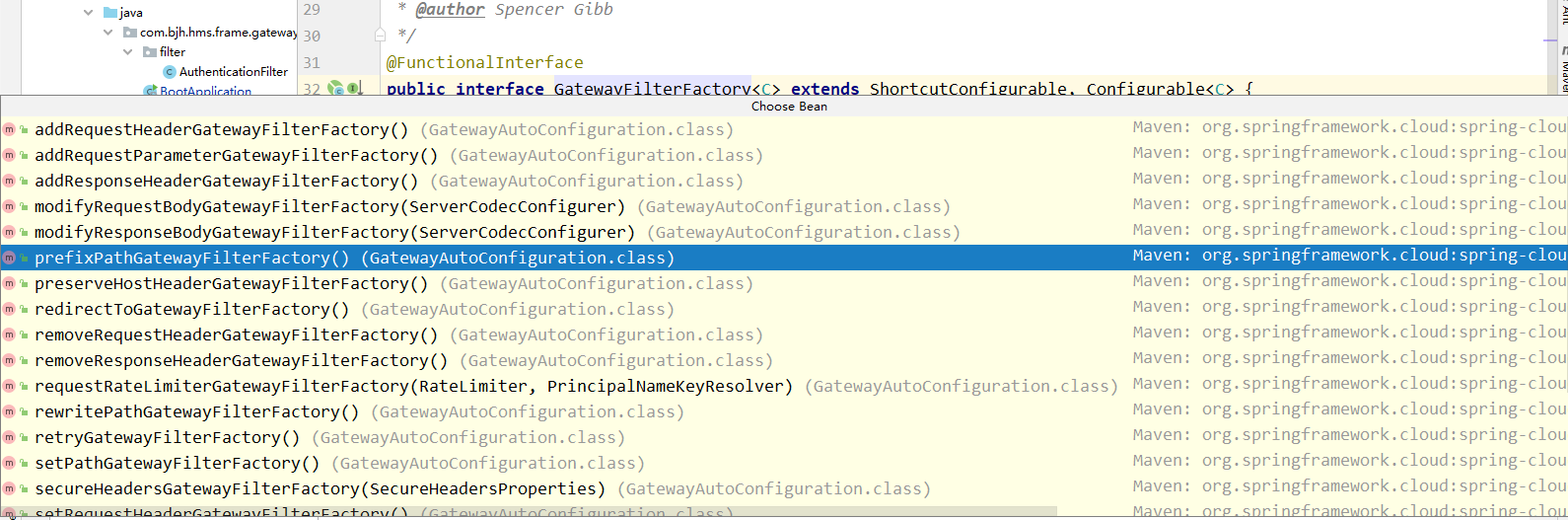
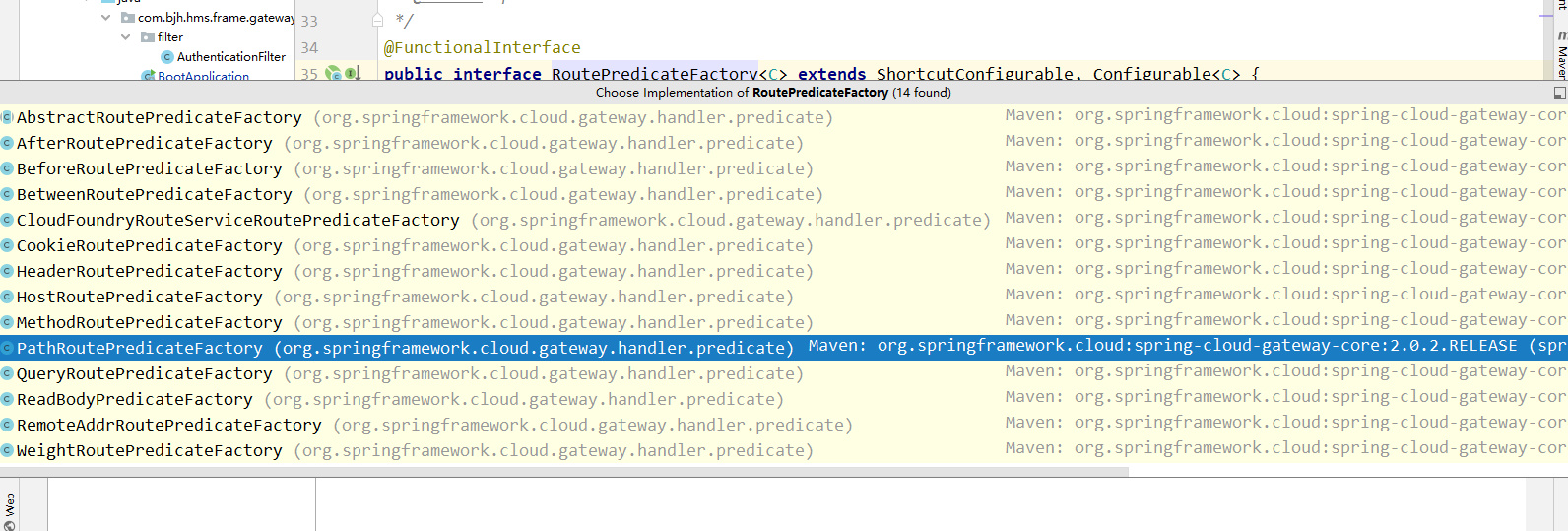
这下我们知道了,系统配置的断言和过滤器是如何被加载 的了,那我们还有一个问题,如果我自定义一个,如何被系统识别呢?并且怎么进行配置呢?不难发现我们之前看源码时,他是被spring通过找工厂实现类找到并且加载进来的,那我们自己实现工厂接口并且使用@Component注解,让spring加载进来不就的了吗?但是你会发现系统自定义的属性断言或者过滤器都有工厂名字的后缀,这是为什么呢?影响我们自定义 的类被加载到gateway中且生效吗?事实是会影响,那为什么影响呢?我们还是看源码。因为我们之前的类加载还没有看完,我们最开始的时候就找到了两个@bean 的自动加载,那这两个类实例化的时候都做了哪些工作,我们还没有细看;
public RouteDefinitionRouteLocator(RouteDefinitionLocator routeDefinitionLocator,
List<RoutePredicateFactory> predicates,
List<GatewayFilterFactory> gatewayFilterFactories,
GatewayProperties gatewayProperties) {
this.routeDefinitionLocator = routeDefinitionLocator;
initFactories(predicates);
gatewayFilterFactories.forEach(factory -> this.gatewayFilterFactories.put(factory.name(), factory));
this.gatewayProperties = gatewayProperties;
}
initFactories(predicates):这段代码主要是进行解析断言工厂实现类;并且放入一个Map中,
gatewayFilterFactories.forEach(factory -> this.gatewayFilterFactories.put(factory.name(), factory)):跟断言的代码几乎一样,因为没有其他多余的逻辑,所以没有封装到方法中,直接使用java8 的流特性,写完了遍历的过程。大家要注意一段代码就是factory.name(),这里使用了一个方法;
default String name() {
return NameUtils.normalizeRoutePredicateName(getClass());
}
主要就是把当前类包含工厂名字的部分去掉了,然后用剩下的字符串当key值,所以我们可以使用工厂名字做后坠,也可以不用,但是剩下的字符则是你要写进配置的关键字,不过博主基本都是按照系统自带属性一样,用的是工厂接口的名字做的后缀。
好了,今天就讲解这么多,下次在讲解gateway接到请求后,是如何进行一步一步过滤的,何时进行断言校验的。一次不讲这么多,消化了就好。
到此这篇关于SpringCloud Gateway加载断言predicates与过滤器filters的源码分析的文章就介绍到这了,更多相关SpringCloud Gateway断言内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
详解SpringCloudGateway内存泄漏问题
SpringCloudGateway内存泄漏问题 项目完善差不多,在进入压力测试阶段期间,发现了gateway有内存泄漏问题,问题发现的起因是,当时启动一台gateway,一台对应的下游应用服务,在压力测试期间,发现特别不稳定,并发量时高时低,而且会有施压机卡住的现象,然后找到容器对应的宿主机,并使用container stats命令观察内存,经过观察发现,压力测试时内存会暴涨,并由于超过限制最大内存导致容器挂掉(这里由于用的swarm所以会自动选择节点重启)最终发现由于之前测试服务器配置低,所
-
springboot2.0和springcloud Finchley版项目搭建(包含eureka,gateWay,Freign,Hystrix)
前段时间spring boot 2.0发布了,与之对应的spring cloud Finchley版本也随之而来了,两者之间的关系和版本对应详见我这边文章:spring boot和spring cloud对应的版本关系 项目地址:spring-cloud-demo spring boot 1.x和spring cloud Dalston和Edgware版本搭建的微服务项目现在已经很流行了,现在很多企业都已经在用了,这里就不多说了. 使用版本说明: spring boot 2.0.x spring
-
详解SpringCloud Finchley Gateway 统一异常处理
SpringCloud Finchley Gateway 统一异常处理 全文搜索[@@]搜索重点内容标记 1 . 问题:使用SpringCloud Gateway时,会出现各种系统级异常,默认返回HTML. 2 . Finchley版本的Gateway,使用WebFlux形式作为底层框架,而不是Servlet容器,所以常规的异常处理无法使用 翻阅源码,默认是使用DefaultErrorWebExceptionHandler这个类实现结构如下: 可以实现参考DefaultErrorWebExcep
-

Springcloud GateWay网关配置过程图解
一般为了不暴露自己的端口信息等,会选择架构一个网关在前面进行阻挡,起到保护的作用.附上一张工作示列图. 1.配置网关9527 gateway作为网关需要和其他的应用一样需要注册进eureka中进行管理,先创建应用gateway9527 pom文件,关键是gateway依赖 <dependencies> <dependency> <groupId>com.bai</groupId> <artifactId>cloud-api-common</
-
详解SpringCloud Gateway之过滤器GatewayFilter
在Spring-Cloud-Gateway之请求处理流程文中我们了解最终网关是将请求交给过滤器链表进行处理,接下来我们阅读Spring-Cloud-Gateway的整个过滤器类结构以及主要功能 通过源码可以看到Spring-Cloud-Gateway的filter包中吉接口有如下三个,GatewayFilter,GlobalFilter,GatewayFilterChain,下来我依次阅读接口的主要实现功能. GatewayFilterChain 类图 代码 /** * 网关过滤链表接口 * 用
-
springcloud gateway聚合swagger2的方法示例
问题描述 在搭建分布式应用时,每个应用通过nacos在网关出装配了路由,我们希望网关也可以将所有的应用的swagger界面聚合起来.这样前端开发的时候只需要访问网关的swagger就可以,而不用访问每个应用的swagger. 框架 springcloud+gateway+nacos+swagger 问题分析 swagger页面是一个单页面应用,所有的显示的数据都是通过和springfox.documentation.swagger.web.ApiResponseController进行数据交互,
-
SpringCloud Gateway加载断言predicates与过滤器filters的源码分析
我们今天的主角是Gateway网关,一听名字就知道它基本的任务就是去分发路由.根据不同的指定名称去请求各个服务,下面是Gateway官方的解释: https://spring.io/projects/spring-cloud-gateway,其他的博主就不多说了,大家多去官网看看,只有官方的才是最正确的,回归主题,我们的过滤器与断言如何加载进来的,并且是如何进行对请求进行过滤的. 大家如果对SpringBoot自动加载的熟悉的话,一定知道要看一个代码的源码,要找到META-INF下的spring
-
Android Activity View加载与绘制流程深入刨析源码
1.App的启动流程,从startActivity到Activity被创建. 这个流程主要是ActivityThread和ActivityManagerService之间通过binder进行通信来完成. ActivityThread可以拿到AMS 的BinderProxy.AMS可以拿到ActivityThread的BinderProxy ApplicationThread.这样双方就可以互相通讯了. 当ApplicationThread 接收到AMS的Binder调用后,会通过handler机
-
SpringBoot源码分析之bootstrap.properties文件加载的原理
目录 1.bootstrap的使用 2.bootstrap加载原理分析 2.1 BootstrapApplicationListener 2.2 启动流程梳理 2.3 bootstrap.properties的加载原理 对于SpringBoot中的属性文件相信大家在工作中用的是比较多的,对于application.properties和application.yml文件应该非常熟悉,但是对于bootstrap.properties文件和bootstrap.yml这个两个文件用的估计就比较少了
-
lazy init控制加载在Spring中如何实现源码分析
目录 一.lazy-init说明 二.lazy-init 属性被设置的地方 三.lazy-init发挥作用的地方 四.问答 一.lazy-init说明 ApplicationContext实现的默认行为就是在启动时将所有singleton bean提前进行实例化(也就是依赖注入). 提前实例化意味着作为初始化过程的一部分,ApplicationContext实例会创建并配置所有的singleton bean. 通常情况下这是件好事,因为这样在配置中的任何错误就会即刻被发现(否则的话可能要花几个小
-
SpringCloud微服务续约实现源码分析详解
目录 一.前言 二.客户端续约 1.入口 构造初始化 initScheduledTasks()调度执行心跳任务 2.TimedSupervisorTask组件 构造初始化 TimedSupervisorTask#run()任务逻辑 3.心跳任务 HeartbeatThread私有内部类 发送心跳 4.发送心跳到注册中心 构建请求数据发送心跳 三.服务端处理客户端续约 1.InstanceRegistry#renew()逻辑 2.PeerAwareInstanceRegistryImpl#rene
-
详解springMVC容器加载源码分析
springmvc是一个基于servlet容器的轻量灵活的mvc框架,在它整个请求过程中,为了能够灵活定制各种需求,所以提供了一系列的组件完成整个请求的映射,响应等等处理.这里我们来分析下springMVC的源码. 首先,spring提供了一个处理所有请求的servlet,这个servlet实现了servlet的接口,就是DispatcherServlet.把它配置在web.xml中,并且处理我们在整个mvc中需要处理的请求,一般如下配置: <servlet> <servlet-name
-
从源码分析Android的Glide库的图片加载流程及特点
0.基础知识 Glide中有一部分单词,我不知道用什么中文可以确切的表达出含义,用英文单词可能在行文中更加合适,还有一些词在Glide中有特别的含义,我理解的可能也不深入,这里先记录一下. (1)View: 一般情况下,指Android中的View及其子类控件(包括自定义的),尤其指ImageView.这些控件可在上面绘制Drawable (2)Target: Glide中重要的概念,目标.它即可以指封装了一个View的Target(ViewTarget),也可以不包含View(SimpleTa
-
关于Spring启动时Context加载源码分析
前言 本文主要给大家介绍了关于Spring启动时Context加载的相关内容,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧. 测试源码下载test-annotation.zip 有如下的代码 @Component public class HelloWorldService { @Value("${name:World}") private String name; public String getHelloMessage() { return "Hell
-
SpringCloud Tencent 全套解决方案源码分析
目录 Spring Cloud Tencent 是什么? 项目源码地址 一.安装北极星 二.服务注册与发现 三.配置管理 四.服务限流 五.服务路由 六.限流熔断 Spring Cloud Tencent 是什么? Spring Cloud Tencent 是腾讯开源的一站式微服务解决方案.Spring Cloud Tencent 实现了 Spring Cloud 标准微服务 SPI,开发者可以基于 Spring Cloud Tencent 快速开发 Spring Cloud 微服务架构应用.S
-
详解Spring简单容器中的Bean基本加载过程
本篇将对定义在 XMl 文件中的 bean,从静态的的定义到变成可以使用的对象的过程,即 bean 的加载和获取的过程进行一个整体的了解,不去深究,点到为止,只求对 Spring IOC 的实现过程有一个整体的感知,具体实现细节留到后面用针对性的篇章进行讲解. 首先我们来引入一个 Spring 入门使用示例,假设我们现在定义了一个类 org.zhenchao.framework.MyBean ,我们希望利用 Spring 来管理类对象,这里我们利用 Spring 经典的 XMl 配置文件形式进行