Redis有序集合类型的操作_动力节点Java学院整理
今天我们说一下Redis中最后一个数据类型 “有序集合类型”,回首之前学过的几个数据结构,不知道你会不会由衷感叹,开源的世界真好,写这些代码的好心人真的要一生平安哈,不管我们想没想的到的东西,在这个世界上都已经存在着,曾几何时,我们想把所有数据按照数据结构模式组成后灌输到内存中,然而为了达到内存共享的方式,不得不将这块内存单独部署,同时还要考虑怎么序列化,何时序列互的问题,烦心事太多太多。。。后来才知道有redis这么个玩意,能把高级的,低级的数据结构单独包装到一个共享内存中(Redis),高级的数据结构,就是本篇所说的 “有序集合”。
一: 有序集合(SortedSet)
可能有些初次接触SortedSet集合的人可能会说,这个集合的使用场景都有哪些??? 我可以明确的告诉你:“范围查找“的天敌就是”有序集合“,任何大数据量下,查找一个范围的时间复杂度永远都是 O[(LogN)+M],其中M:返回的元素个数。
为了从易到难,我们还是先看一下redis手册,挑选几个我们常用的方法观摩观摩效果。。。
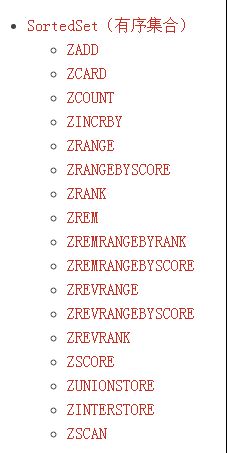
从上面17个命令中,毫无疑问,常用的命令为ZADD,ZREM,ZRANGEBYSCORE,ZRANGE。
1. ZADD
ZADD key score member [[score member] [score member] ...]
将一个或多个 member 元素及其 score 值加入到有序集 key 当中。
这个是官方的解释,赋值方式和hashtable差不多,只不过这里的key是有序的而已。下面我举个例子:我有一个fruits集合,其中记录了每个水果的price,然后我根据price的各种操作来获取对应的水果信息。

有了上面的基本信息,接下来我逐一送他们到SortedSet中,如下图:
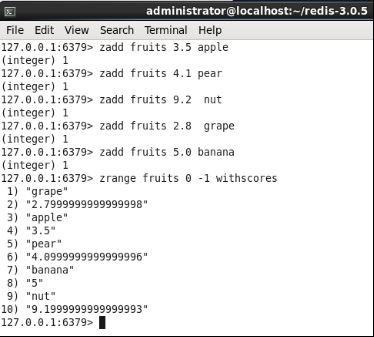
从上面的图中,不知道你有没有发现到什么异常???至少有两种。
<1> 浮点数近似值的问题,比如grape,我在add的时候,写明的是2.8,在redis中却给我显示近似值2.79999....,这个没关系,本来就是这样。
<2> 默认情况下,SortedSet是以key的升序排序的方式进行存放。
2. ZRANGE,ZREVRANGE
ZRANGE key start stop [WITHSCORES]
返回有序集 key 中,指定区间内的成员。
其中成员的位置按 score 值递增(从小到大)来排序。
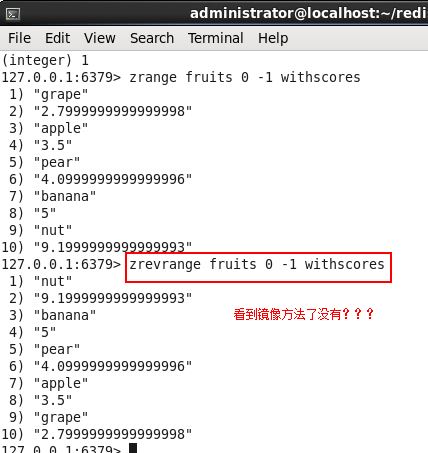
上面就是ZRange的格式模版,前面我在说ZAdd的时候其实我也已经说了,但是这个不是重点,在说ZAdd的时候留下了一个问题就是ZRange默认是按照key升序排序的,对吧,那如果你想倒序显示的话,怎么办呢???其实你可以使用ZRange的镜像方法ZREVRANGE 即可,如下图:
3. ZRANGEBYSCORE
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]
返回有序集 key 中,所有 score 值介于 min 和 max 之间(包括等于 min 或 max )的成员。有序集成员按 score 值递增(从小到大)次序排列。
这个算是对SortedSet来说最最重要的方法了,文章开头我也说了,有序集合最利于范围查找,既然是查找,你得有条件对吧,下面我举个例子:
<1> 我要找到1-4块钱的水果种类,理所当然,我会找到【葡萄,苹果】,如下图:
127.0.0.1:6379> zrangebyscore fruits 1 4 withscores 1) "grape" 2) "2.7999999999999998" 3) "apple" 4) "3.5" 127.0.0.1:6379>
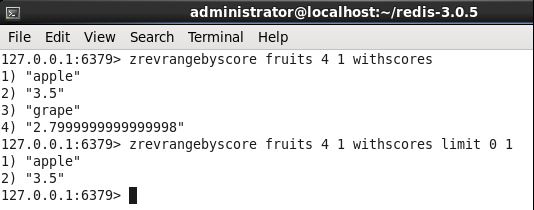
<2> 我要找到1-4区间中最接近4块的水果是哪个??? 这个问题就是要找到apple这个选项,那如果找到呢??? 仔细想想我可以这么做,
将1-4区间中的所有数倒序再取第一条数据即可,对吧,如下图:
127.0.0.1:6379> zrevrangebyscore fruits 4 1 withscores 1) "apple" 2) "3.5" 3) "grape" 4) "2.7999999999999998" 127.0.0.1:6379> zrevrangebyscore fruits 4 1 withscores limit 0 1 1) "apple" 2) "3.5" 127.0.0.1:6379>
4. ZREM
ZREM key member [member ...]
移除有序集 key 中的一个或多个成员,不存在的成员将被忽略。
当 key 存在但不是有序集类型时,返回一个错误。
跟其他方法一样,zrem的目的就是删除指定的value成员,比如这里我要删除scores=3.5 的 apple记录。
127.0.0.1:6379> zrem fruits apple (integer) 1 127.0.0.1:6379> zrange fruits 0 -1 withscores 1) "grape" 2) "2.7999999999999998" 3) "pear" 4) "4.0999999999999996" 5) "banana" 6) "5" 7) "nut" 8) "9.1999999999999993" 127.0.0.1:6379>
你会发现,已经没有apple的相关记录了,因为已经被我删除啦。。。
二:探索原理
简单的操作都已经演示完毕了,接下来探讨下sortedset到底是由什么数据结构支撑的,大家应该早有耳闻,sortedset在CURD的摊还分析上都是Log(N)的复杂度,可以与平衡二叉树媲美,它就是1987年才出来的新型高效数据结构“跳跃表(SkipList)”,SkipList牛的地方在于跳出了树模型的思维,用多层链表的模式构造了Log(N)的时间复杂度,层的高度增加与否,采用随机数的模式,这个和 ”Treap树“ 的思想一样,用它来保持”树“或者”链表”的平衡。
详细的我就不说了哈,不然的话又是一篇文章啦,如果非要了解的话,大家可以参见一下百度百科,我大概看了下百科里面画的这张图,就像下面这样:

这幅图中有三条链,在SkipList中是必须要保证每条链中的数据必须有序才可以,这是必须的。
1. 如果要在level1层中找到节点6,那么你需要逐一遍历,需要6次查找才能正确的找到数据。
2. 如果你在level2层中找到节点6的话,那么你需要4次才能找到。
3. 如果你在level3层中找到节点6的话,那么你需要3次就可以找到。。。。
现在宏观理解上,是不是有一种感觉,如果level的层数越高,相对找到数据需要遍历的次数就越少,这就是跳跃表的思想,不然怎么跳哈,接下来我们来看看redis中是怎么定义这个skiplist的,它的源码在redis.h 中:
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode {
robj *obj;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward;
unsigned int span;
} level[];
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
} zskiplist;
从源码中可以看出如下几点:
<1> zskiplistnode就是skiplist中的node节点,节点中有一个level[]数组,如果你够聪明的话,你应该知道这个level[]就是存放着上图中
的 level1,level2,level3 这三条链。
<2> level[]里面是zskiplistLevel实体,这个实体中有一个 *forward指针,这个指针就是指向同层中的后续节点。
<3> 在zskiplistLevel中还有一个 robj类型的*obj指针,这个就是RedisObject对象哈,里面存放的就是我们的value值,接下来还有一个 score属性,这个就是key值啦。。。skiplist就是根据它来进行排序的哈。
<4> 接下来就是第二个枚举zskiplist,这个没什么意思,纯粹的包装层,比如里面的length是记录skiplist中的节点个数,level记录skiplist 当前的层数,用*header,*tail记录skiplist中的首节点和尾节点。。。仅此而已。。。
相关推荐
-

Java中的collection集合类型总结
Java集合是java提供的工具包,包含了常用的数据结构:集合.链表.队列.栈.数组.映射等.Java集合工具包位置是java.util.* Java集合主要可以划分为4个部分:List列表.Set集合.Map映射.工具类(Iterator迭代器.Enumeration枚举类.Arrays和Collections). Java集合工具包框架如下图. 说明:看上面的框架图,先抓住它的主干,即Collection和Map. Collection是一个接口,是高度抽象出来的集合,它包含了集合的基本操作
-
java集合类arraylist循环中删除特定元素的方法
在项目开发中,我们可能往往需要动态的删除ArrayList中的一些元素. 一种错误的方式: <pre name="code" class="java">for(int i = 0 , len= list.size();i<len;++i){ if(list.get(i)==XXX){ list.remove(i); } } 上面这种方式会抛出如下异常: Exception in thread "main" java.lang.I
-
浅析Java中的set集合类型及其接口的用法
概念 首先,我们看看Set集合. (01) Set 是继承于Collection的接口.它是一个不允许有重复元素的集合. (02) AbstractSet 是一个抽象类,它继承于AbstractCollection,AbstractCollection实现了Set中的绝大部分函数,为Set的实现类提供了便利. (03) HastSet 和 TreeSet 是Set的两个实现类. HashSet依赖于HashMap,它实际上是通过HashMap实现的.HashSet中的元素是无序的.
-
Java集合类的组织结构和继承、实现关系详解
Collection继承.实现关系如下(说明(I)表示接口, (C)表示Java类,<--表示继承,<<--表示实现): (I)Iterable |<-- (I)Collection |<-- (I)List |<<-- (C)ArrayList |<<-- (C)LinkedList |<<-- (C)Vector |<-- (I)Set |<<-- (C)HashSet |<-- (I)Queue [kju] M
-
redis集合类型_动力节点Java学院整理
我们来看看Redis五大类型中的第四大类型:"集合类型",集合类型还是蛮有意思的,先看redis手册,如下: 上面就是redis中的set类型使用到的所有方法,还是老话,常用的方法也就那么四个(CURD)... 一: 常用方法 1. SAdd 这个方法毫无疑问,就是向集合里面添加数据,比如下面这样,我往fruits集合里面添加喜爱的水果. 127.0.0.1:6379> sadd fruits apple (integer) 1 127.0.0.1:6379> sadd f
-
Java集合类中文介绍
Java集合是java提供的工具包,包含了常用的数据结构:集合.链表.队列.栈.数组.映射等.Java集合工具包位置是java.util.*Java集合主要可以划分为4个部分:List列表.Set集合.Map映射.工具类(Iterator迭代器.Enumeration枚举类.Arrays和Collections)..Java集合工具包框架图(如下):大致说明:看上面的框架图,先抓住它的主干,即Collection和Map.1 Collection是一个接口,是高度抽象出来的集合,它包含了集合的基
-
总结Java集合类操作优化经验
在实际的项目开发中会有很多的对象,如何高效.方便地管理对象,成为影响程序性能与可维护性的重要环节.Java 提供了集合框架来解决此类问题,线性表.链表.哈希表等是常用的数据结构,在进行 Java 开发时,JDK 已经为我们提供了一系列相应的类来实现基本的数据结构,所有类都在 java.util 这个包里,清单1 描述了集合类的关系. 清单 1.集合类之间关系 Collection ├List │├LinkedList │├ArrayList │└Vector │ └Stack └Set Map
-
java集合类源码分析之Set详解
Set集合与List一样,都是继承自Collection接口,常用的实现类有HashSet和TreeSet.值得注意的是,HashSet是通过HashMap来实现的而TreeSet是通过TreeMap来实现的,所以HashSet和TreeSet都没有自己的数据结构,具体可以归纳如下: •Set集合中的元素不能重复,即元素唯一 •HashSet按元素的哈希值存储,所以是无序的,并且最多允许一个null对象 •TreeSet按元素的大小存储,所以是有序的,并且不允许null对象 •Set集合没有ge
-
Java的Hibernate框架中集合类数据结构的映射编写教程
一.集合映射 1.集合小介 集合映射也是基本的映射,但在开发过程中不会经常用到,所以不需要深刻了解,只需要理解基本的使用方法即可,等在开发过程中遇到了这种问题时能够查询到解决方法就可以了.对应集合映射它其实是指将java中的集合映射到对应的表中,是一种集合对象的映射,在java中有四种类型的集合,分别是Set.Map.List还有普通的数组,它们之间有很大的区别: (1)Set,不可以有重复的对象,对象是无序的: (2)List,可以与重复的对象,对象之间有顺序: (3)Map,它是键值成对出现
-
Redis有序集合类型的操作_动力节点Java学院整理
今天我们说一下Redis中最后一个数据类型 "有序集合类型",回首之前学过的几个数据结构,不知道你会不会由衷感叹,开源的世界真好,写这些代码的好心人真的要一生平安哈,不管我们想没想的到的东西,在这个世界上都已经存在着,曾几何时,我们想把所有数据按照数据结构模式组成后灌输到内存中,然而为了达到内存共享的方式,不得不将这块内存单独部署,同时还要考虑怎么序列化,何时序列互的问题,烦心事太多太多...后来才知道有redis这么个玩意,能把高级的,低级的数据结构单独包装到一个共享内存中(Redi
-
Java Collections集合继承结构图_动力节点Java学院整理
面向对象语言对事物的体现都是以对象的形式,所以为了方便对多个对象的操作,就对对象进行存储,集合就是存储对象最常用的一种方式. 数组虽然也可以存储对象,但长度是固定的:集合长度是可变的,数组中可以存储基本数据类型,集合只能存储对象. 集合类的特点:集合只用于存储对象,集合长度是可变的,集合可以存储不同类型的对象. 集合框架图 Collection (集合的最大接口)继承关系 --List 可以存放重复的内容 --Set 不能存放重复的内容,所以的重复内容靠hashCode()和equals()两个
-
Java中List Set和Map之间的区别_动力节点Java学院整理
Java集合的主要分为三种类型: • Set(集) • List(列表) • Map(映射) 要深入理解集合首先要了解下我们熟悉的数组: 数组是大小固定的,并且同一个数组只能存放类型一样的数据(基本类型/引用类型),而JAVA集合可以存储和操作数目不固定的一组数据. 所有的JAVA集合都位于 java.util包中! JAVA集合只能存放引用类型的的数据,不能存放基本数据类型. 世间上本来没有集合,(只有数组参考C语言)但有人想要,所以有了集合 有人想有可以自动扩展的数组,所以有了List 有的
-
Java Iterator迭代器_动力节点Java学院整理
迭代器是一种模式,它可以使得对于序列类型的数据结构的遍历行为与被遍历的对象分离,即我们无需关心该序列的底层结构是什么样子的.只要拿到这个对象,使用迭代器就可以遍历这个对象的内部. 1.Iterator Java提供一个专门的迭代器<<interface>>Iterator,我们可以对某个序列实现该interface,来提供标准的Java迭代器.Iterator接口实现后的功能是"使用"一个迭代器. 文档定义: Package java.util; publici
-
Java 中的HashMap详解和使用示例_动力节点Java学院整理
第1部分 HashMap介绍 HashMap简介 HashMap 是一个散列表,它存储的内容是键值对(key-value)映射. HashMap 继承于AbstractMap,实现了Map.Cloneable.java.io.Serializable接口. HashMap 的实现不是同步的,这意味着它不是线程安全的.它的key.value都可以为null.此外,HashMap中的映射不是有序的. HashMap 的实例有两个参数影响其性能:"初始容量" 和 "加载因子&quo
-
Java 中HashCode作用_动力节点Java学院整理
第1 部分 hashCode的作用 Java集合中有两类,一类是List,一类是Set他们之间的区别就在于List集合中的元素师有序的,且可以重复,而Set集合中元素是无序不可重复的.对于List好处理,但是对于Set而言我们要如何来保证元素不重复呢?通过迭代来equals()是否相等.数据量小还可以接受,当我们的数据量大的时候效率可想而知(当然我们可以利用算法进行优化).比如我们向HashSet插入1000数据,难道我们真的要迭代1000次,调用1000次equals()方法吗?hashCod
-
Java中List Set和Map之间的区别_动力节点Java学院整理
Java集合的主要分为三种类型: • Set(集) • List(列表) • Map(映射) 要深入理解集合首先要了解下我们熟悉的数组: 数组是大小固定的,并且同一个数组只能存放类型一样的数据(基本类型/引用类型),而JAVA集合可以存储和操作数目不固定的一组数据. 所有的JAVA集合都位于 java.util包中! JAVA集合只能存放引用类型的的数据,不能存放基本数据类型. 世间上本来没有集合,(只有数组参考C语言)但有人想要,所以有了集合 有人想有可以自动扩展的数组,所以有了List 有的
-
Java JVM原理与调优_动力节点Java学院整理
JVM是一种用于计算设备的规范,它是一个虚构出来的计算机,是通过在实际的计算机上仿真模拟各种计算机功能来实现的.Java虚拟机包括一套字节码指令集.一组寄存器.一个栈.一个垃圾回收堆和一个存储方法域. JVM屏蔽了与具体操作系统平台相关的信息,使Java程序只需生成在Java虚拟机上运行的目标代码(字节码),就可以在多种平台上不加修改地运行.是运行Java应用最底层部分. JDK(Java Development kit) 整个Java的核心,包括了Java运行环境(Java Runtime E
-
Java中的HashSet详解和使用示例_动力节点Java学院整理
第1部分 HashSet介绍 HashSet 简介 HashSet 是一个没有重复元素的集合. 它是由HashMap实现的,不保证元素的顺序,而且HashSet允许使用 null 元素. HashSet是非同步的.如果多个线程同时访问一个哈希 set,而其中至少一个线程修改了该 set,那么它必须 保持外部同步.这通常是通过对自然封装该 set 的对象执行同步操作来完成的.如果不存在这样的对象,则应该使用 Collections.synchronizedSet 方法来"包装" set.
-
Java设计模式之迭代器模式_动力节点Java学院整理
定义:提供一种方法访问一个容器对象中各个元素,而又不暴露该对象的内部细节. 类型:行为类模式 类图: 如果要问Java中使用最多的一种模式,答案不是单例模式,也不是工厂模式,更不是策略模式,而是迭代器模式,先来看一段代码吧: public static void print(Collection coll){ Iterator it = coll.iterator(); while(it.hasNext()){ String str = (String)it.next(); System.out