Python dataframe如何设置index
目录
- dataframe设置index
- 重命名dataframe的index
- 方法1:直接赋值法
- 方法2:map
- 方法3:rename
- 自定义map函数处理dataframe
dataframe设置index
DataFrame.set_index(keys, drop=True, append=False, inplace=False, verify_integrity=False)
其中:keys是列标签或数组列表
drop:删除要用作新索引的列,布尔值默认为Trueappend:boolean是否将列附加到现有索引默认为False,inplace修改DataFrame(不要创建新对象)默认为Falseverify_integrity:检查新索引是否有重复项默认为False。
示例:
In [ ]: df = pd.DataFrame({'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']},
index=[0, 1, 2, 3])
Out[ ]:
A B C D
0 A0 B0 C0 D0
1 A1 B1 C1 D1
2 A2 B2 C2 D2
3 A3 B3 C3 D3
>>> df1= df.set_index(['A', 'B']) >>> df2 = df.set_index([[1, 2, 3,4]])
DataFrame.reset_index(level=None, drop=False, inplace=False, col_level=0, col_fill='')
level指仅从索引中删除给定的级别,默认情况下删除所有级别int,str,tuple或list,默认为None。drop确定索引列会是否还原为普通列
示例:
>>> df.reset_index()
重命名dataframe的index
方法1:直接赋值法
因为dataframe的index也是series格式的数据,所以直接指定index为一个新的series即可修改dataframe的index:

方法2:map
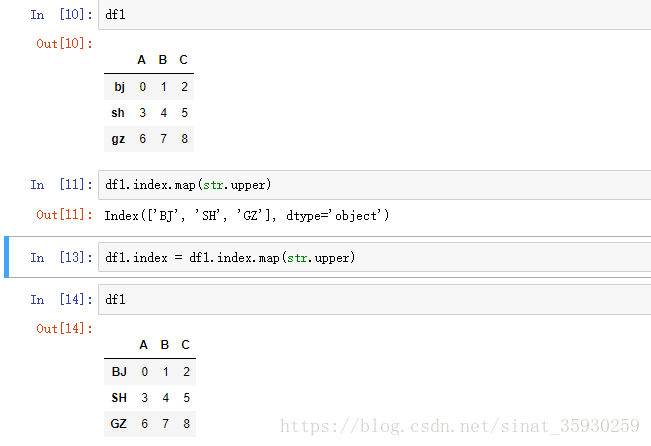
方法3:rename
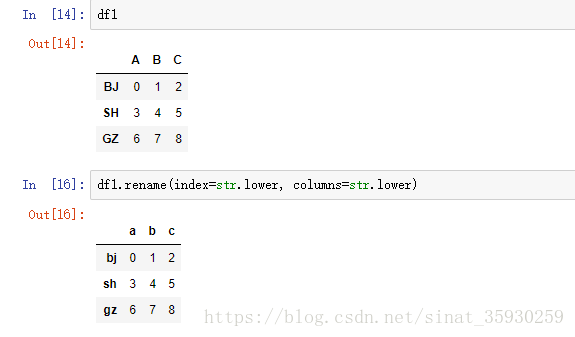
通过rename传入一个函数可以批量替换index或rename:
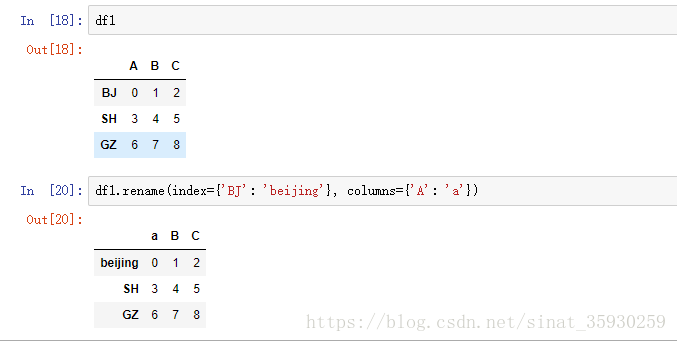
也可以通过传入一个字典,指定修改index或column:
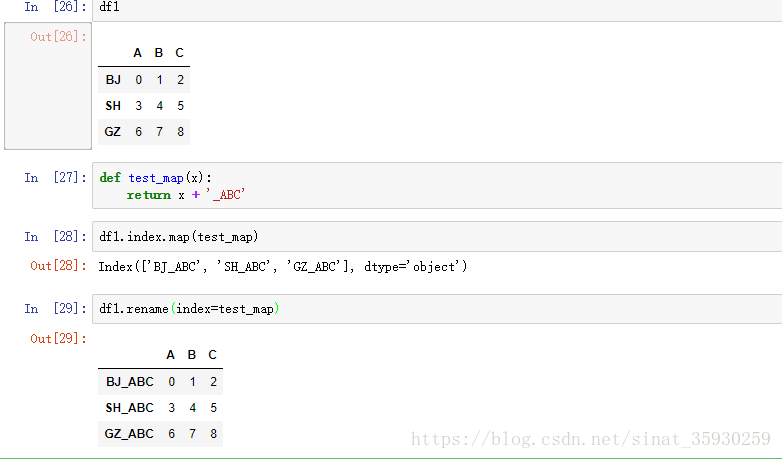
自定义map函数处理dataframe
map函数通过传入一个函数来对对象进行批量处理:
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Python pandas.DataFrame调整列顺序及修改index名的方法
1. 从字典创建DataFrame >>> import pandas >>> dict_a = {'user_id':['webbang','webbang','webbang'],'book_id':['3713327','4074636','26873486'],'rating':['4','4','4'],'mark_date':['2017-03-07','2017-03-07','2017-03-07']} >>> df = pandas.
-
python 给DataFrame增加index行名和columns列名的实现方法
在工作中遇到需要对DataFrame加上列名和行名,不然会报错 开始的数据是这样的 需要的格式是这样的: 其实,需要做的就是添加行名和列名,下面开始操作下. # a是DataFrame格式的数据集 a.index.name = 'date' a.columns.name = 'code' 这样就可以修改过来. 以上这篇python 给DataFrame增加index行名和columns列名的实现方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
python pandas 对series和dataframe的重置索引reindex方法
reindex更多的不是修改pandas对象的索引,而只是修改索引的顺序,如果修改的索引不存在就会使用默认的None代替此行.且不会修改原数组,要修改需要使用赋值语句. series.reindex() import pandas as pd import numpy as np obj = pd.Series(range(4), index=['d', 'b', 'a', 'c']) print obj d 0 b 1 a 2 c 3 dtype: int64 print obj.reinde
-
删除python pandas.DataFrame 的多重index实例
如下dataframe想要删除多层index top1000[:10] name sex births year prop year sex 1880 F 0 Mary F 7065 1880 0.077643 1 Anna F 2604 1880 0.028618 2 Emma F 2003 1880 0.022013 3 Elizabeth F 1939 1880 0.021309 4 Minnie F 1746 1880 0.019188 5 Margaret F 1578 1880 0.
-
Python DataFrame 设置输出不显示index(索引)值的方法
在输出代码行中,加入"index=False"如下: m_pred_survived.to_csv("clasified.csv",index=False) 以上这篇Python DataFrame 设置输出不显示index(索引)值的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
Python将DataFrame的某一列作为index的方法
下面代码实现了将df中的column列作为index df.set_index(["Column"], inplace=True) 以上这篇Python将DataFrame的某一列作为index的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们. 您可能感兴趣的文章: 对Python中DataFrame按照行遍历的方法 使用DataFrame删除行和列的实例讲解 Python中的index()方法使用教程 Python中List.index()方法的使用
-

Python dataframe如何设置index
目录 dataframe设置index 重命名dataframe的index 方法1:直接赋值法 方法2:map 方法3:rename 自定义map函数处理dataframe dataframe设置index DataFrame.set_index(keys, drop=True, append=False, inplace=False, verify_integrity=False) 其中:keys是列标签或数组列表 drop:删除要用作新索引的列,布尔值默认为True append:boo
-
Python DataFrame设置/更改列表字段/元素类型的方法
Python DataFrame 如何设置列表字段/元素类型? 比如笔者想将列表的两个字段由float64设置为int64,那么就要用到DataFrame的astype属性,举例如图: 该例列表为"m_pred_survived"字段为"PassengerId"及"Survived",设置为int64类型,最后可以输出检验下是否正确. m_pred_survived = pd.DataFrame(columns=['PassengerId', '
-
python DataFrame数据格式化(设置小数位数,百分比,千分位分隔符)
目录 1.设置小数位数 1.1数据框设置统一小数位数 1.2数据框分别设置不同小数位数 1.3通过Series设置DataFrame小数位数 1.4applymap(自定义函数) 2.设置百分比 3.设置千分位分隔符 1.设置小数位数 1.1 数据框设置统一小数位数 以保留小数点后两位小数为例: import pandas as pd import numpy as np df = pd.DataFrame(np.random.random([5, 5]), columns=['A1', 'A2
-
python DataFrame中stack()方法、unstack()方法和pivot()方法浅析
目录 1.stack() 2. unstack() 3. pivot() 总结 1.stack() stack()用于将列索引转换为最内层的行索引,这样叙述比较抽象,看示例就容易理解啦: 准备一组数据,给其设置双索引. import pandas as pd data = [['A类', 'a1', 123, 224, 254], ['A类', 'a2', 234, 135, 444], ['A类', 'a3', 345, 241, 324], ['B类', 'b1', 112, 412, 46
-
python DataFrame获取行数、列数、索引及第几行第几列的值方法
1.df=DataFrame([{'A':'11','B':'12'},{'A':'111','B':'121'},{'A':'1111','B':'1211'}]) print df.columns.size#列数 2 print df.iloc[:,0].size#行数 3 print df.ix[[0]].index.values[0]#索引值 0 print df.ix[[0]].values[0][0]#第一行第一列的值 11 print df.ix[[1]].values[0][1]
-
Python Dataframe 指定多列去重、求差集的方法
1)去重 指定多列去重,这是在dataframe没有独一无二的字段作为PK(主键)时,需要指定多个字段一起作为该行的PK,在这种情况下对整体数据进行去重. Attention:主要用到了drop_duplicates方法,并设置参数subset为多个字段名构成的数组. 具体代码如下: >>>import pandas as pd >>>data={'state':[1,1,2,2,1,2,2],'pop':['a','b','c','d','b','c','d']} &
-
python dataframe常见操作方法:实现取行、列、切片、统计特征值
实例如下所示: # -*- coding: utf-8 -*- import numpy as np import pandas as pd from pandas import * from numpy import * data = DataFrame(np.arange(16).reshape(4,4),index = list("ABCD"),columns=list('wxyz')) print data print data[0:2] #取前两行数据 print'+++++
-
python dataframe向下向上填充,fillna和ffill的方法
首先新建一个dataframe: In[8]: df = pd.DataFrame({'name':list('ABCDA'),'house':[1,1,2,3,3],'date':['2010-01-01','2010-06-09','2011-12-03','2011-04-05','2012-03-23']}) In[9]: df Out[9]: date house name 0 2010-01-01 1 A 1 2010-06-09 1 B 2 2011-12-03 2 C 3 201