Python爬虫实现自动登录、签到功能的代码
更新 2016/8/9:最近发现目标网站已经屏蔽了这个登录签到的接口(PS:不过我还是用这个方式赚到了将近一万点积分·····)
前几天女朋友跟我说,她在一个素材网站上下载东西,积分总是不够用,积分是怎么来的呢,是每天登录网站签到获得的,当然也能购买,她不想去买,因为偶尔才会用一次,但是每到用的时候就发现积分不够,又记不得每天去签到,所以就有了这个纠结的事情。怎么办呢,想办法呗,于是我就用python写了个小爬虫,每天去自动帮她签到挣积分。废话不多说,下面就讲讲代码。
我这里用的是python3.4,使用python2.x的朋友如果有需要请绕道查看别的文章。
工具:Fiddler
首先下载安装Fiddler,这个工具是用来监听网络请求,有助于你分析请求链接和参数。
打开目标网站:http://www.17sucai.com/,然后点击登录
好了,先别急着登录,打开你的Fiddler,此时Fiddler里面是没有监听到网络请求的,然后回到页面,输入邮箱和密码,点击登录,下面再到fiddler里面去看
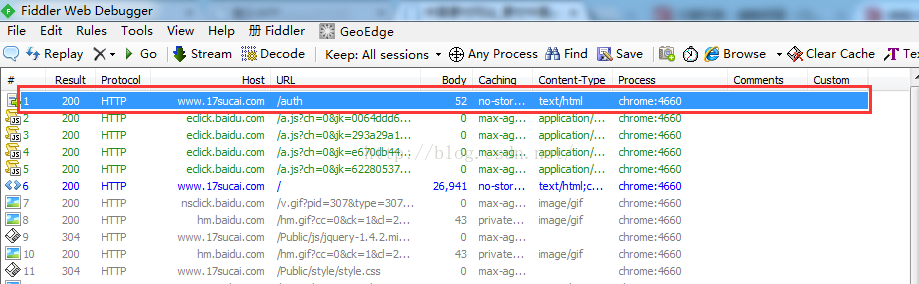
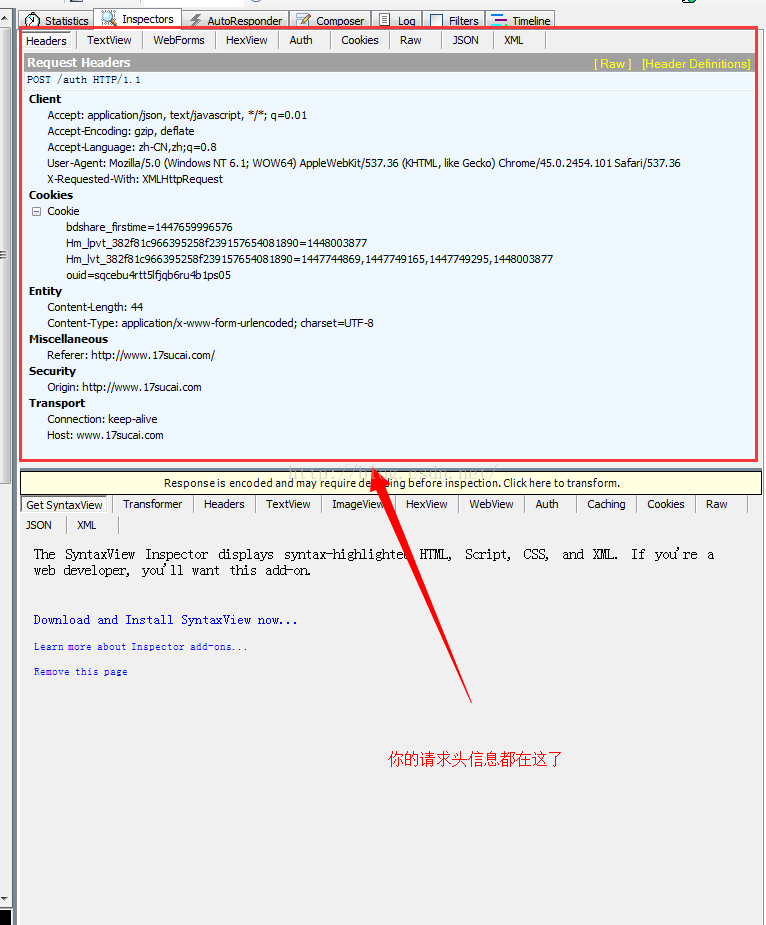
这里面的第一个请求就是你点击登录的网络请求,点击这个链接可以在右边看到你的一些请求信息
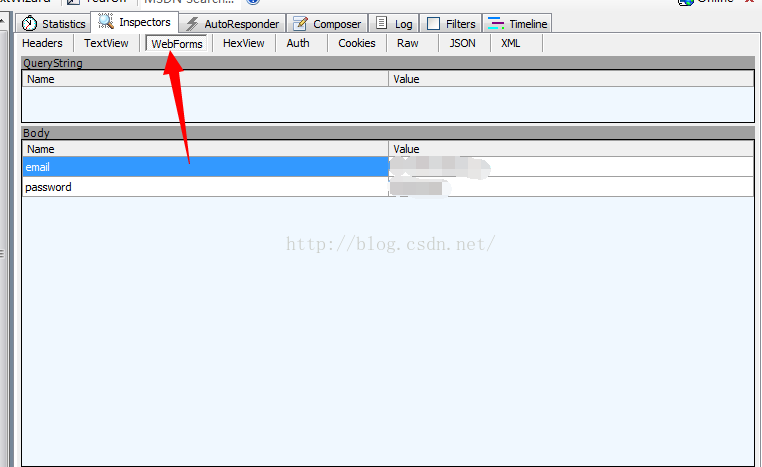
然后点击WebForms可以看到你的请求参数,也就是用户名和密码
下面我们有代码来实现登录功能
import urllib.request
import urllib
import gzip
import http.cookiejar
#定义一个方法用于生成请求头信息,处理cookie
def getOpener(head):
# deal with the Cookies
<pre name="code" class="python"> cj = http.cookiejar.CookieJar()
pro = urllib.request.HTTPCookieProcessor(cj)
opener = urllib.request.build_opener(pro)
header = []
for key, value in head.items():
elem = (key, value)
header.append(elem)
opener.addheaders = header
return opener
#定义一个方法来解压返回信息
def ungzip(data):
try: # 尝试解压
print('正在解压.....')
data = gzip.decompress(data)
print('解压完毕!')
except:
print('未经压缩, 无需解压')
return data
#封装头信息,伪装成浏览器
header = {
'Connection': 'Keep-Alive',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Accept': 'application/json, text/javascript, */*; q=0.01',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36',
'Accept-Encoding': 'gzip, deflate',
'X-Requested-With': 'XMLHttpRequest',
'Host': 'www.17sucai.com',
}
url = 'http://www.17sucai.com/auth'
opener = getOpener(header)
id = 'xxxxxxxxxxxxx'#你的用户名
password = 'xxxxxxx'#你的密码
postDict = {
'email': id,
'password': password,
}
postData = urllib.parse.urlencode(postDict).encode()
op = opener.open(url, postData)
data = op.read()
data = ungzip(data)
print(data)
好了,接下来清空一下你的Fiddler,然后运行这个程序,看一下你的Fiddler
你可以点击这个链接,看看右边的请求信息和你用浏览器请求的是不是一样
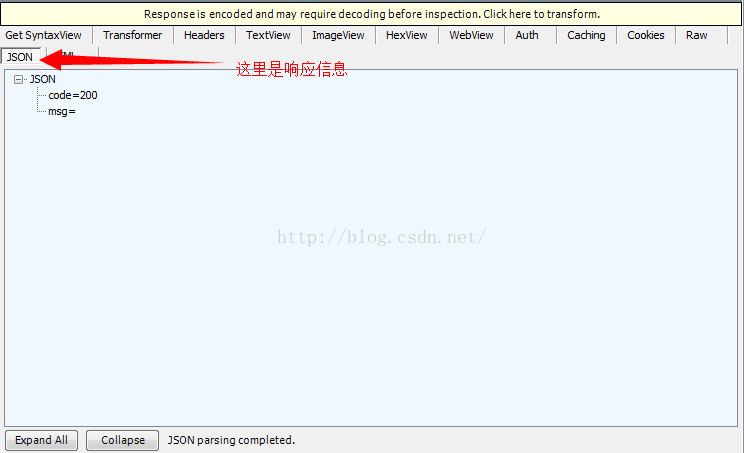
下面是程序后代打印的信息

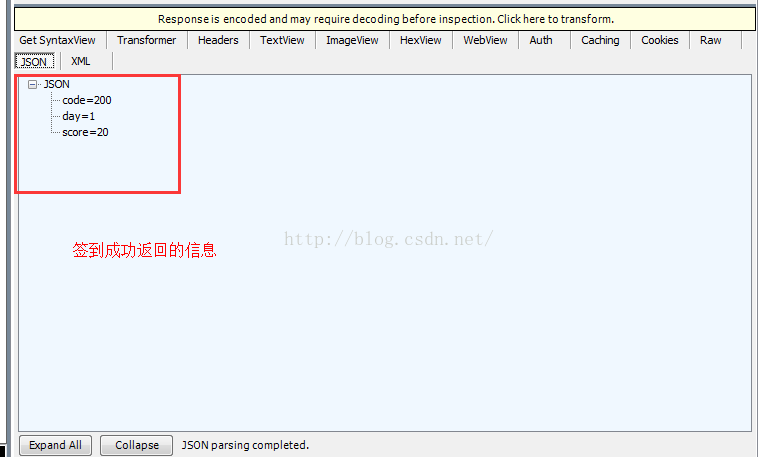
code=200表示登陆成功
解析来就需要获取到签到的url,这里你需要一个没有签到的账号在网站中点击签到按钮,然后通过Fiddler来获取到签到的链接和需要的信息。
然后点击“签到”,签到成功后到Fiddler中查看捕捉到的url
点击这个url可以在右边查看访问这个链接时所需要的头信息和cookies神马的,我们已经登录成功后直接使用cookies就行了,python对cookies的处理做好了封装,下面是我的代码中对cookies的使用
cj = http.cookiejar.CookieJar() pro = urllib.request.HTTPCookieProcessor(cj) opener = urllib.request.build_opener(pro)
下面是签到成功返回的信息:code=200表示请求成功,day=1表示连续签到一天,score=20表示获得的积分数
下面放出完整代码,当然,为了测试代码签到,你还需要你一没有签到过的账号
import urllib.request
import urllib
import gzip
import http.cookiejar
def getOpener(head):
# deal with the Cookies
cj = http.cookiejar.CookieJar()
pro = urllib.request.HTTPCookieProcessor(cj)
opener = urllib.request.build_opener(pro)
header = []
for key, value in head.items():
elem = (key, value)
header.append(elem)
opener.addheaders = header
return opener
def ungzip(data):
try: # 尝试解压
print('正在解压.....')
data = gzip.decompress(data)
print('解压完毕!')
except:
print('未经压缩, 无需解压')
return data
header = {
'Connection': 'Keep-Alive',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Accept': 'application/json, text/javascript, */*; q=0.01',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36',
'Accept-Encoding': 'gzip, deflate',
'X-Requested-With': 'XMLHttpRequest',
'Host': 'www.17sucai.com',
}
url = 'http://www.17sucai.com/auth'
opener = getOpener(header)
id = 'xxxxxxx'
password = 'xxxxxxx'
postDict = {
'email': id,
'password': password,
}
postData = urllib.parse.urlencode(postDict).encode()
op = opener.open(url, postData)
data = op.read()
data = ungzip(data)
print(data)
url = 'http://www.17sucai.com/member/signin' #签到的地址
op = opener.open(url)
data = op.read()
data = ungzip(data)
print(data)
相比登录,签到也就是在登录完成后重新打开一个链接而已,由于我的账号都已经签到过了,这里就不在贴运行代码的图 了。
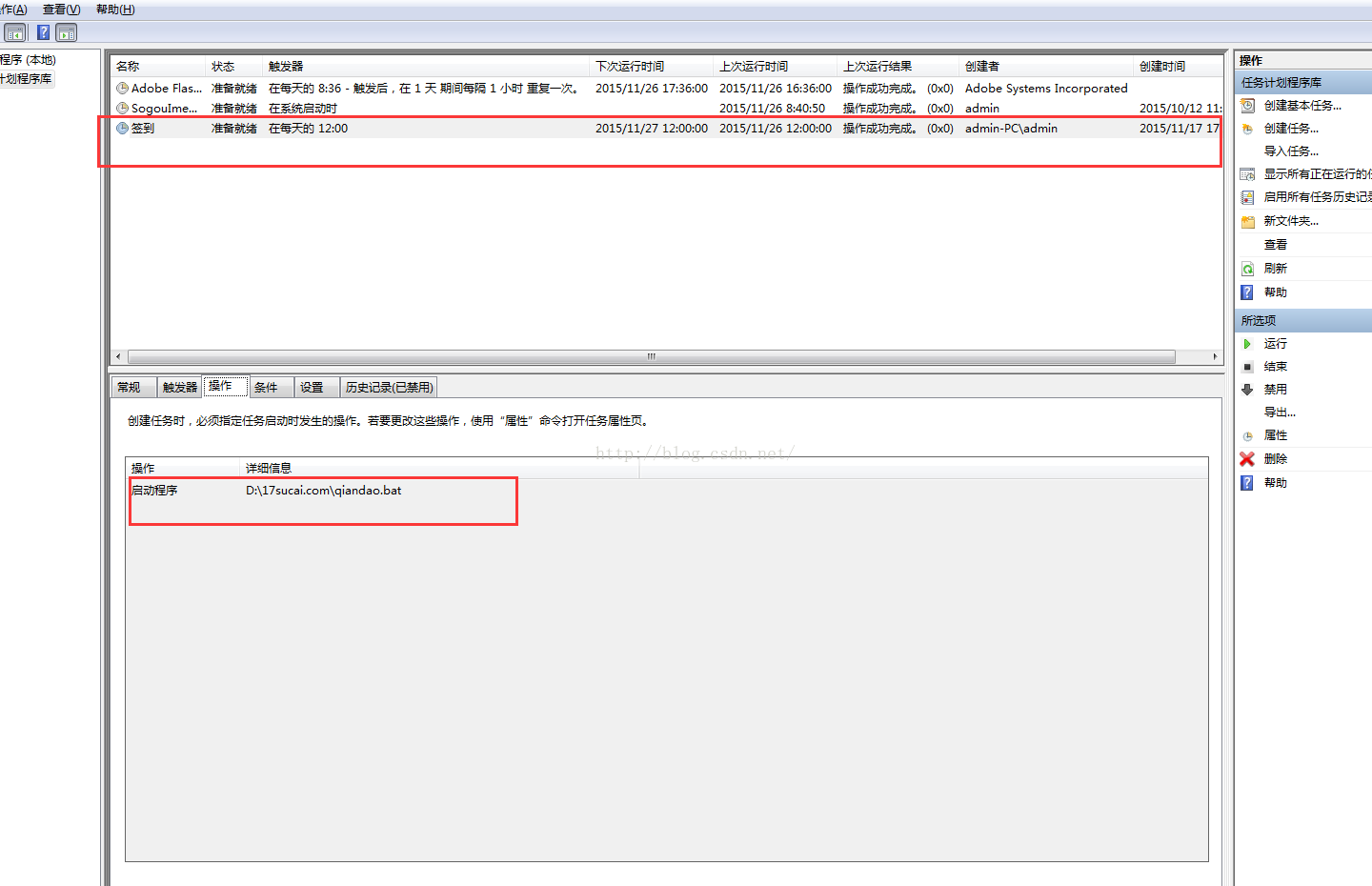
接下来要做的就是在你电脑上写个bat 脚本,再在“任务计划”中添加一个定时任务就行了。
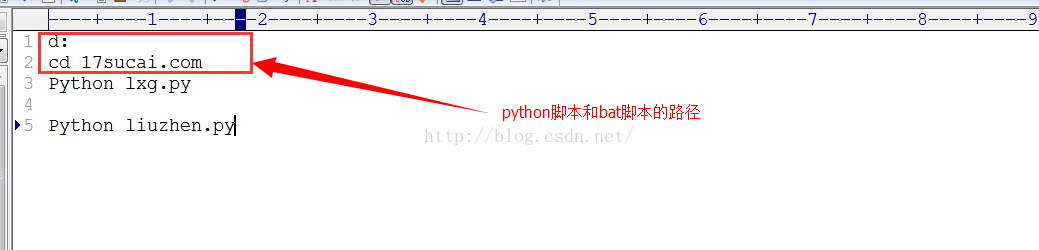
在此之前你还需要配置一下python的环境变量,这里就不在赘述了。
到此这篇关于Python爬虫实现自动登录、签到功能的代码的文章就介绍到这了,更多相关Python爬虫实现自动登录、签到内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python实现某论坛自动签到功能
1.[文件] DakeleSign.py ~ 4KB #!/usr/bin/env python # -*- coding: utf-8 -*- __author__ = 'poppy' ''' dakele bbs sigin ''' import sys import urllib2 import urllib import requests import cookielib import json from pyquery import PyQuery as pq import loggi
-
python3模拟百度登录并实现百度贴吧签到示例分享(百度贴吧自动签到)
baiduclient.py 复制代码 代码如下: import urllib.parseimport gzipimport jsonimport refrom http.client import HTTPConnectionfrom htmlutils import TieBaParserimport httputils as utils # 请求头headers = dict()headers["Connection"] = "keep-alive"heade
-
python+selenium实现京东自动登录及秒杀功能
本文实例为大家分享了selenium+python京东自动登录及秒杀的代码,供大家参考,具体内容如下 运行环境: python 2.7 python安装selenium 安装webdriver(这里是firefox) 其中selenium可以采用pip安装: pip install selenium webdriver下载地址 需要注意的是,webdriver的目录.对应浏览器的目录,都要添加到path. 代码如下: # _*_coding:utf-8_*_ from selenium impo
-
python实现网页自动签到功能
本文实例为大家分享了python实现网页自动签到功能的具体代码,供大家参考,具体内容如下 第1步.环境准备(用的chrome浏览器) 1.安装selenium包 pip install selenium 2.下载chromedriver驱动: 找到符合自己浏览器版本的chromedriver驱动,下载解压后,将chromedriver.exe文件放到Python目录下的Scripts目录下,也可以添加环境变量到Path中: 第2步.Selenium脚本源码 比较简单,而且有详细注释就不一一说明了
-

python实现二维码扫码自动登录淘宝
一个小项目自动登录淘宝联盟抓取数据,由于之前在Github上看过类似用Python写的代码因此选择用Python来写,第一次用Python正式写程序还是被其"简单"所震撼,当然用的时候还是对其(2.7版)编码.迁移环境等问题所困扰,还好后来都解决了. 言归正传,抓取淘宝联盟的数据首先要解决的就是登录的问题,之前一般会碰到验证码的困扰,现在支持二维码扫码登录反而简单了,以下是登录的Python代码,主要是获取二维码打印,然后不断的检查扫码状态,如果过期了重新请求二维码(主要看逻辑,由于有
-
Python3自动签到 定时任务 判断节假日的实例
不废话,直接上代码Python3.6 签到代码,只需修改url,账号,密码即可,此处是登录时无验证登录,有验证码的自行补充 # -*- coding:utf-8 -*- import json import urllib.request import datetime # 模拟浏览器打开网站 browser = webdriver.Chrome() browser.get('http://**.**.121.54/') # 将窗口最大化 browser.maximize_window() # 根
-
Python爬虫实现自动登录、签到功能的代码
更新 2016/8/9:最近发现目标网站已经屏蔽了这个登录签到的接口(PS:不过我还是用这个方式赚到了将近一万点积分·····) 前几天女朋友跟我说,她在一个素材网站上下载东西,积分总是不够用,积分是怎么来的呢,是每天登录网站签到获得的,当然也能购买,她不想去买,因为偶尔才会用一次,但是每到用的时候就发现积分不够,又记不得每天去签到,所以就有了这个纠结的事情.怎么办呢,想办法呗,于是我就用python写了个小爬虫,每天去自动帮她签到挣积分.废话不多说,下面就讲讲代码. 我这里用的是python3
-
python+selenium实现自动抢票功能实例代码
简介 什么是Selenium? Selenium是ThoughtWorks公司的一个强大的开源Web功能测试工具系列,采用Javascript来管理整个测试过程,包括读入测试套件.执行测试和记录测试结果.它采用Javascript单元测试工具JSUnit为核心,模拟真实用户操作,包括浏览页面.点击链接.输入文字.提交表单.触发鼠标事件等等,并且能够对页面结果进行种种验证.也就是说,只要在测试用例中把预期的用户行为与结果都描述出来,我们就得到了一个可以自动化运行的功能测试套件.(Selenium的
-
python爬虫之自动登录与验证码识别
在用爬虫爬取网站数据时,有些站点的一些关键数据的获取需要使用账号登录,这里可以使用requests发送登录请求,并用Session对象来自动处理相关Cookie. 另外在登录时,有些网站有时会要求输入验证码,比较简单的验证码可以直接用pytesser来识别,复杂的验证码可以依据相应的特征自己采集数据训练分类器. 以CSDN网站的登录为例,这里用Python的requests库与pytesser库写了一个登录函数.如果需要输入验证码,函数会首先下载验证码到本地,然后用pytesser识别验证码后登
-
python爬虫-模拟微博登录功能
微博模拟登录 这是本次爬取的网址:https://weibo.com/ 一.请求分析 找到登录的位置,填写用户名密码进行登录操作 看看这次请求响应的数据是什么 这是响应得到的数据,保存下来 exectime: 8 nonce: "HW9VSX" pcid: "gz-4ede4c6269a09f5b7a6490f790b4aa944eec" pubkey: "EB2A38568661887FA180BDDB5CABD5F21C7BFD59C090CB2D24
-
Python Flask前端自动登录功能实现详解
目录 引言 1. 登录时 2. 定义全局拦截器 引言 在已有的网站中,几乎所有的网站都已经实现了 自动登录 所谓自动登录,其实就是在你登录后,然后关闭浏览器,接着再启动浏览器重新进入刚刚的网站时,无需自己再次登录.更准确的说,在一段时间内,无需自己再次登录 思路:其实所谓的自动登录,到最后的后端逻辑,和你正常的登录逻辑是一样的,也是判断用户名和密码是否正确.只是我们要省略让用户再次输入用户名和密码的步骤,那么肯定就要将用户名和密码存储在一个地方.当检测到用户再次进入时,看看是否满足可以自动登录的
-
Python脚本实现虾米网签到功能
本文实例讲述了Python脚本实现虾米网签到功能的方法.分享给大家供大家参考,具体如下: 概述 这个脚本完成了自动登录虾米网.签到的功能. 大致要用到urllib.urllib2.cookielib这几个模块.其实就是用python实现向指定的url去post数据. 至于我怎么知道在浏览器里面登录和签到时浏览器都向服务器post了什么数据的问题,可以用强大的chrome:F12->Network里面可以看得到.有的服务器登录成功后会让客户端浏览器跳转或者立即刷新一次页面等等,会把登录时向服务器p
-
python爬虫_自动获取seebug的poc实例
简单的写了一个爬取www.seebug.org上poc的小玩意儿~ 首先我们进行一定的抓包分析 我们遇到的第一个问题就是seebug需要登录才能进行下载,这个很好处理,只需要抓取返回值200的页面,将我们的headers信息复制下来就行了 (这里我就不放上我的headers信息了,不过headers里需要修改和注意的内容会在下文讲清楚) headers = { 'Host':******, 'Connection':'close', 'Accept':******, 'User-Agent':*
-
使用Java servlet实现自动登录退出功能
UserDao.java从数据库中查询用户名与密码 //登录 public User login(User user) throws SQLException { QueryRunner qr = new QueryRunner(DataSourceUtils.getDataSource()); String sql = "select from user where username = ? and password = ?"; return qr.query(sql, new Be
-
Python实现12306自动抢火车票功能
目录 一.效果展示 二.代码详解 1 导入库 2 确定好购票基本信息 3 登录12306 4 模拟滑动滑块 5 处理疫情特殊要求 6 点击购票并填写出发地.目的地.出发时间 7 锁定车票 大家有没有这种感觉,一到国庆.春节这种长假,抢火车票就非常困难?各大互联网公司都推出抢票服务,只要加钱给服务费就可以增加抢到票的几率.有些火车票代售网点和一些加速买票软件,说你只要给100元服务费就可以优先帮忙抢到票.本文和你一起探索抢票软件背后的原理. 一.效果展示 在正式进入代码讲解之前,先来看下本文的实现
-
python爬虫使用cookie登录详解
前言: 什么是cookie? Cookie,指某些网站为了辨别用户身份.进行session跟踪而储存在用户本地终端上的数据(通常经过加密). 比如说有些网站需要登录后才能访问某个页面,在登录之前,你想抓取某个页面内容是不允许的.那么我们可以利用Urllib库保存我们登录的Cookie,然后再抓取其他页面,这样就达到了我们的目的. 一.Urllib库简介 Urllib是python内置的HTTP请求库,官方地址:https://docs.python.org/3/library/urllib.ht