详解python 破解网站反爬虫的两种简单方法
最近在学爬虫时发现许多网站都有自己的反爬虫机制,这让我们没法直接对想要的数据进行爬取,于是了解这种反爬虫机制就会帮助我们找到解决方法。
常见的反爬虫机制有判别身份和IP限制两种,下面我们将一一来进行介绍。
(一) 判别身份
首先我们看一个例子,看看到底什么时反爬虫。
我们还是以 豆瓣电影榜top250(https://movie.douban.com/top250) 为例。`
import requests # 豆瓣电影榜top250的网址 url = 'https://movie.douban.com/top250' # 请求与网站的连接 res = requests.get(url) # 打印获取的文本 print(res.text)
这是段简单的请求与网站连接并打印获取数据的代码,我们来看看它的运行结果。

我们可以发现我们什么数据都没有获取到,这就是由于这个网站有它的身份识别功能,把我们识别为了爬虫,拒绝为我们提供数据。不管是浏览器还是爬虫访问网站时都会带上一些信息用于身份识别。而这些信息都被存储在一个叫请求头(request headers) 的地方。而这个请求头中我们只需要了解其中的一个叫user-agent(用户代理) 的就可以了。user-agent里包含了操作系统、浏览器类型、版本等信息,通过修改它我们就能成功地伪装成浏览器。
下面我们来看怎么找这个user-agent吧。
首先得打开浏览器,随便打开一个网站,再打开开发者工具。
再点击network标签,接着点第一个请求,再找到Request Headers,最后找到user-agent字段。(有时候可能点击network标签后是空白得,这时候刷新下网页就好啦!)
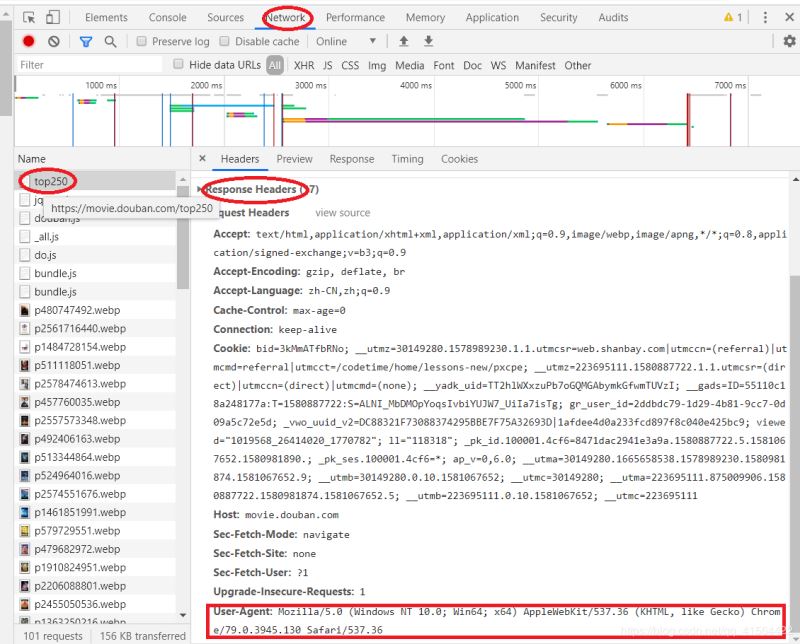
找到请求头后,我们只需要把他放进一个字典里就好啦,具体操作见下面代码。
import requests
# 复制刚才获取得请求头
headers = {
'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'
}
# 豆瓣电影榜top250的网址
url = 'https://movie.douban.com/top250'
# 请求与网站的连接
res = requests.get(url, headers=headers)
# 打印获取的文本
print(res.text)
现在我们再来看部分输出结果。

我们可以发现已经将该网站的HTML文件全部爬取到了,至此第一种方法就将完成了。下面我们来看第二种方法。
(二) IP限制
IP(Internet Protocol) 全称互联网协议地址,意思是分配给用户上网使用的网际协议的设备的数字标签。它就像我们身份证号一样,只要知道你的身份证号就能查出你是哪个人。
当我们爬取大量数据时,如果我们不加以节制地访问目标网站,会使网站超负荷运转,一些个人小网站没什么反爬虫措施可能因此瘫痪。而大网站一般会限制你的访问频率,因为正常人是不会在 1s 内访问几十次甚至上百次网站的。所以,如果你访问过于频繁,即使改了 user-agent 伪装成浏览器了,也还是会被识别为爬虫,并限制你的 IP 访问该网站。
因此,我们常常使用 time.sleep() 来降低访问的频率,比如上一篇博客中的爬取整个网站的代码,我们每爬取一个网页就暂停一秒。
import requests
import time
from bs4 import BeautifulSoup
# 将获取豆瓣电影数据的代码封装成函数
def get_douban_movie(url):
# 设置反爬虫的请求头
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36'
}
# 请求网站的连接
res = requests.get('https://movie.douban.com/top250', headers=headers)
# 将网站数据存到BeautifulSoup对象中
soup = BeautifulSoup(res.text,'html.parser')
# 爬取网站中所有标签为'div',并且class='pl2'的数据存到Tag对象中
items = soup.find_all('div', class_='hd')
for i in items:
# 再筛选出所有标签为a的数据
tag = i.find('a')
# 只读取第一个class='title'作为电影名
name = tag.find(class_='title').text
# 爬取书名对应的网址
link = tag['href']
print(name,link)
url = 'https://movie.douban.com/top250?start={}&filter='
# 将所有网址信息存到列表中
urls = [url.format(num*25) for num in range(10)]
for item in urls:
get_douban_movie(item)
# 暂停 1 秒防止访问太快被封
time.sleep(1)
部分运行结果:
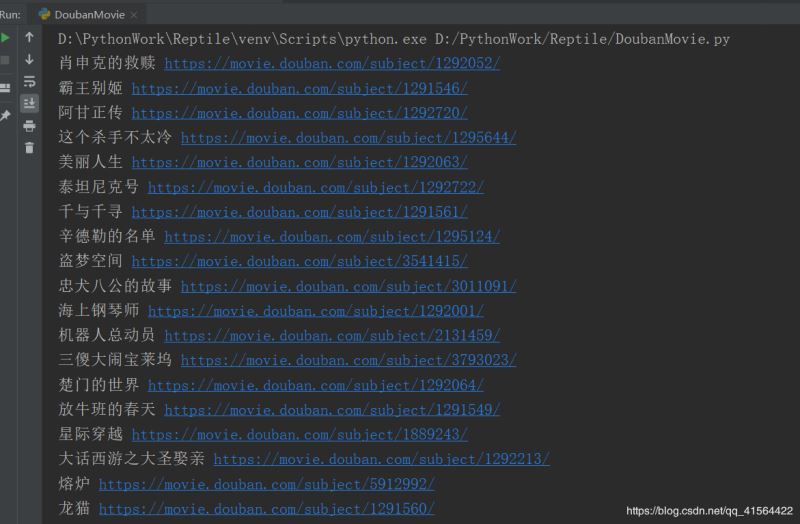
至此两种比较简单的应对反爬虫方法就讲完啦,希望能对大家有所帮助,如果有问题,请及时给予我指正,感激不尽!
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

python爬虫 urllib模块反爬虫机制UA详解
方法: 使用urlencode函数 urllib.request.urlopen() import urllib.request import urllib.parse url = 'https://www.sogou.com/web?' #将get请求中url携带的参数封装至字典中 param = { 'query':'周杰伦' } #对url中的非ascii进行编码 param = urllib.parse.urlencode(param) #将编码后的数据值拼接回url中 url += p
-
用python3 urllib破解有道翻译反爬虫机制详解
前言 最近在学习python 爬虫方面的知识,网上有一博客专栏专门写爬虫方面的,看到用urllib请求有道翻译接口获取翻译结果.发现接口变化很大,用md5加了密,于是自己开始破解.加上网上的其他文章找源码方式并不是通用的,所有重新写一篇记录下. 爬取条件 要实现爬取的目标,首先要知道它的地址,请求参数,请求头,响应结果. 进行抓包分析 打开有道翻译的链接:http://fanyi.youdao.com/.然后在按f12 点击Network项.这时候就来到了网络监听窗口,在这个页面中发送的所有网络
-
python通过伪装头部数据抵抗反爬虫的实例
0x00 环境 系统环境:win10 编写工具:JetBrains PyCharm Community Edition 2017.1.2 x64 python 版本:python-3.6.2 抓包工具:Fiddler 4 0x01 头部数据伪装思路 通过http向服务器提交数据,以下是通过Fiddler 抓取python没有伪装的报文头信息 GET /u012870721 HTTP/1.1 Accept-Encoding: identity Host: blog.csdn.net User-Ag
-
python解决网站的反爬虫策略总结
本文详细介绍了网站的反爬虫策略,在这里把我写爬虫以来遇到的各种反爬虫策略和应对的方法总结一下. 从功能上来讲,爬虫一般分为数据采集,处理,储存三个部分.这里我们只讨论数据采集部分. 一般网站从三个方面反爬虫:用户请求的Headers,用户行为,网站目录和数据加载方式.前两种比较容易遇到,大多数网站都从这些角度来反爬虫.第三种一些应用ajax的网站会采用,这样增大了爬取的难度(防止静态爬虫使用ajax技术动态加载页面). 1.从用户请求的Headers反爬虫是最常见的反爬虫策略. 伪装header
-
python网络爬虫之如何伪装逃过反爬虫程序的方法
有的时候,我们本来写得好好的爬虫代码,之前还运行得Ok, 一下子突然报错了. 报错信息如下: Http 800 Internal internet error 这是因为你的对象网站设置了反爬虫程序,如果用现有的爬虫代码,会被拒绝. 之前正常的爬虫代码如下: from urllib.request import urlopen ... html = urlopen(scrapeUrl) bsObj = BeautifulSoup(html.read(), "html.parser") 这
-
Python3爬虫学习之应对网站反爬虫机制的方法分析
本文实例讲述了Python3爬虫学习之应对网站反爬虫机制的方法.分享给大家供大家参考,具体如下: 如何应对网站的反爬虫机制 在访问某些网站的时候,网站通常会用判断访问是否带有头文件来鉴别该访问是否为爬虫,用来作为反爬取的一种策略. 例如打开搜狐首页,先来看一下Chrome的头信息(F12打开开发者模式)如下: 如图,访问头信息中显示了浏览器以及系统的信息(headers所含信息众多,具体可自行查询) Python中urllib中的request模块提供了模拟浏览器访问的功能,代码如下: from
-
Python反爬虫技术之防止IP地址被封杀的讲解
在使用爬虫爬取别的网站的数据的时候,如果爬取频次过快,或者因为一些别的原因,被对方网站识别出爬虫后,自己的IP地址就面临着被封杀的风险.一旦IP被封杀,那么爬虫就再也爬取不到数据了. 那么常见的更改爬虫IP的方法有哪些呢? 1,使用动态IP拨号器服务器. 动态IP拨号服务器的IP地址是可以动态修改的.其实动态IP拨号服务器并不是什么高大上的服务器,相反,属于配置很低的一种服务器.我们之所以使用动态IP拨号服务器,不是看中了它的计算能力,而是能够实现秒换IP. 动态IP拨号服务器有一个特点,就是每
-
详解python 破解网站反爬虫的两种简单方法
最近在学爬虫时发现许多网站都有自己的反爬虫机制,这让我们没法直接对想要的数据进行爬取,于是了解这种反爬虫机制就会帮助我们找到解决方法. 常见的反爬虫机制有判别身份和IP限制两种,下面我们将一一来进行介绍. (一) 判别身份 首先我们看一个例子,看看到底什么时反爬虫. 我们还是以 豆瓣电影榜top250(https://movie.douban.com/top250) 为例.` import requests # 豆瓣电影榜top250的网址 url = 'https://movie.douban
-
详解Python修复遥感影像条带的两种方式
GDAL修复Landsat ETM+影像条带 Landsat7 ETM+卫星影像由于卫星传感器故障,导致此后获取的影像出现了条带.如下图所示, 影像中均匀的布满条带. 使用GDAL修复影像条带的代码如下: def gdal_repair(tif_name, out_name, bands): """ tif_name(string): 源影像名 out_name(string): 输出影像名 bands(integer): 影像波段数 """ #
-
详解python连接telnet和ssh的两种方式
目录 Telnet 连接方式 ssh连接方式 Telnet 连接方式 #!/usr/bin/env python # coding=utf-8 import time import telnetlib import logging __author__ = 'Evan' save_log_path = 'result.txt' file_mode = 'a+' format_info = '%(asctime)s - %(filename)s[line:%(lineno)d] - %(level
-
详解Python列表赋值复制深拷贝及5种浅拷贝
概述 在列表复制这个问题,看似简单的复制却有着许多的学问,尤其是对新手来说,理所当然的事情却并不如意,比如列表的赋值.复制.浅拷贝.深拷贝等绕口的名词到底有什么区别和作用呢? 列表赋值 # 定义一个新列表 l1 = [1, 2, 3, 4, 5] # 对l2赋值 l2 = l1 print(l1) l2[0] = 100 print(l1) 示例结果: [1, 2, 3, 4, 5] [100, 2, 3, 4, 5] 可以看到,更改赋值后的L2后L1同样也会被更改,看似简单的"复制"
-
详解Python+opencv裁剪/截取图片的几种方式
前言 在计算机视觉任务中,如图像分类,图像数据集必不可少.自己采集的图片往往存在很多噪声或无用信息会影响模型训练.因此,需要对图片进行裁剪处理,以防止图片边缘无用信息对模型造成影响.本文介绍几种图片裁剪的方式,供大家参考. 一.手动单张裁剪/截取 selectROI:选择感兴趣区域,边界框框选x,y,w,h selectROI(windowName, img, showCrosshair=None, fromCenter=None): . 参数windowName:选择的区域被显示在的窗口的名字
-
详解Python进行数据相关性分析的三种方式
目录 相关性实现 NumPy 相关性计算 SciPy 相关性计算 Pandas 相关性计算 线性相关实现 线性回归:SciPy 实现 等级相关 排名:SciPy 实现 等级相关性:NumPy 和 SciPy 实现 等级相关性:Pandas 实现 相关性的可视化 带有回归线的 XY 图 相关矩阵的热图 matplotlib 相关矩阵的热图 seaborn 相关性实现 统计和数据科学通常关注数据集的两个或多个变量(或特征)之间的关系.数据集中的每个数据点都是一个观察值,特征是这些观察值的属性或属性.
-
详解Python获取线程返回值的三种方式
目录 方法一 方法二 方法三 最后的话 提到线程,你的大脑应该有这样的印象:我们可以控制它何时开始,却无法控制它何时结束,那么如何获取线程的返回值呢?今天就分享一下自己的一些做法. 方法一 使用全局变量的列表,来保存返回值 ret_values = [] def thread_func(*args): ... value = ... ret_values.append(value) 选择列表的一个原因是:列表的 append() 方法是线程安全的,CPython 中,GI
-
详解PyQt5中textBrowser显示print语句输出的简单方法
开发python程序处理大数据量的时候,少不了使用print语句看看输出结果:长时间处理数据时用print输出处理进展情况.使用PyQt5开发了UI界面后,本能地想让已自己调试好的py代码中的print输出到UI的textBrowser中显示出来.在CSDN上查了不少结果,一般都是使用多线程.我对多线程研究不多,就采用了变通办法,效果还挺好. 在Ui界面程序(Ui_startaml.py)中设置textBrowser用于显示程序输出信息,并自己定义代码(def printf ),以后将.py程序
-
详解pytorch的多GPU训练的两种方式
目录 方法一:torch.nn.DataParallel 1. 原理 2. 常用的配套代码如下 3. 优缺点 方法二:torch.distributed 1. 代码说明 方法一:torch.nn.DataParallel 1. 原理 如下图所示:小朋友一个人做4份作业,假设1份需要60min,共需要240min. 这里的作业就是pytorch中要处理的data. 与此同时,他也可以先花3min把作业分配给3个同伙,大家一起60min做完.最后他再花3min把作业收起来,一共需要66min. 这个
-
详解JavaScript发送埋点请求的两种方式
目录 一.用法 1.动态创建<img> 2.动态创建<script> 二.区别 区别1 区别2 三.选择哪种方式 四.总结 对于统计页面数据这样的情景(俗称埋点),我们常用的方式就是动态创建<img>或<script>,至于原因,一般有以下几点: 1.埋点一般不用关心请求的结果 2.可以实现跨域请求 3.无需使用ajax就能达到发请求的目的 4.都是原生实现,兼容性好 现就两种方式做一下对比和总结: 一.用法 1.动态创建<img> 方式1:通过