python使用requests库爬取拉勾网招聘信息的实现
按F12打开开发者工具抓包,可以定位到招聘信息的接口
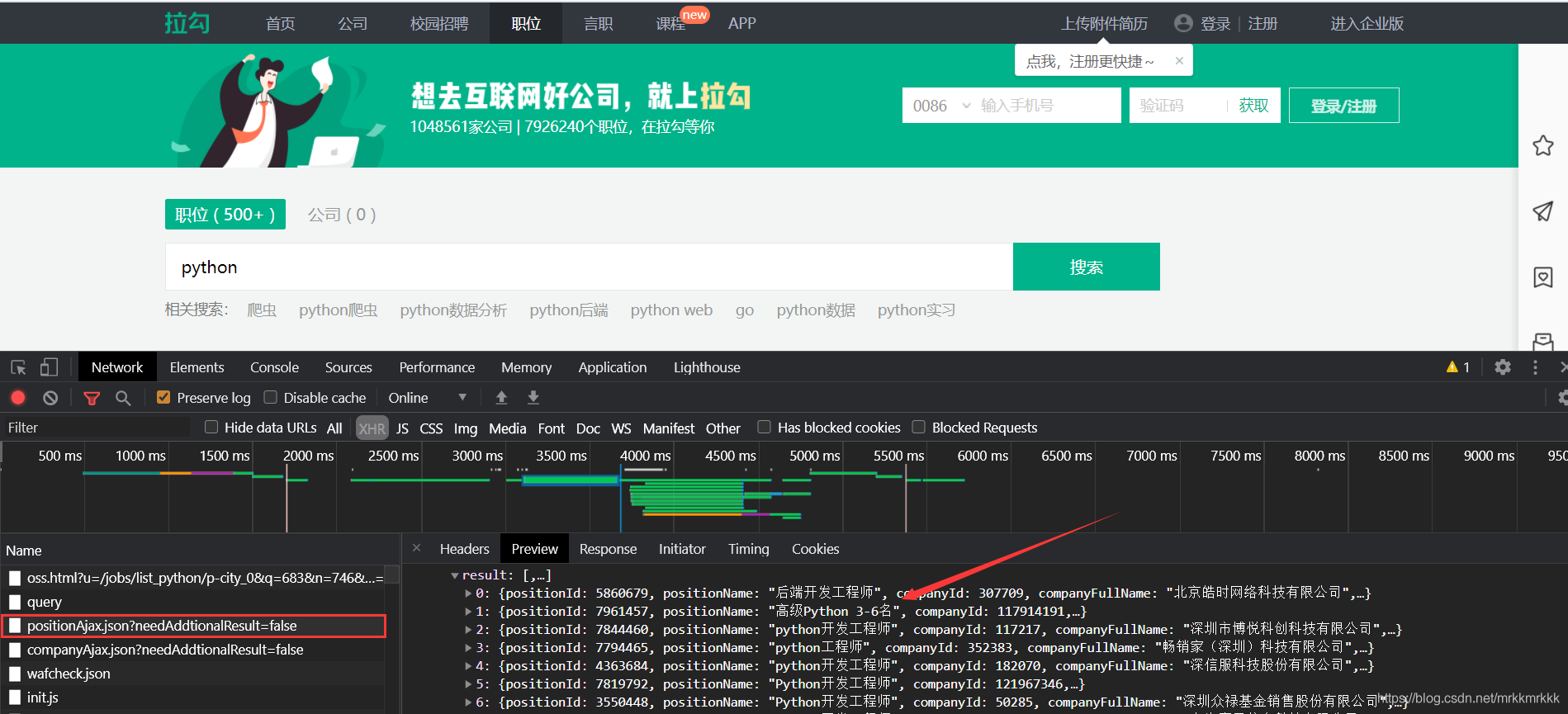
在请求中可以获取到接口的url和formdata,表单中pn为请求的页数,kd为关请求职位的关键字
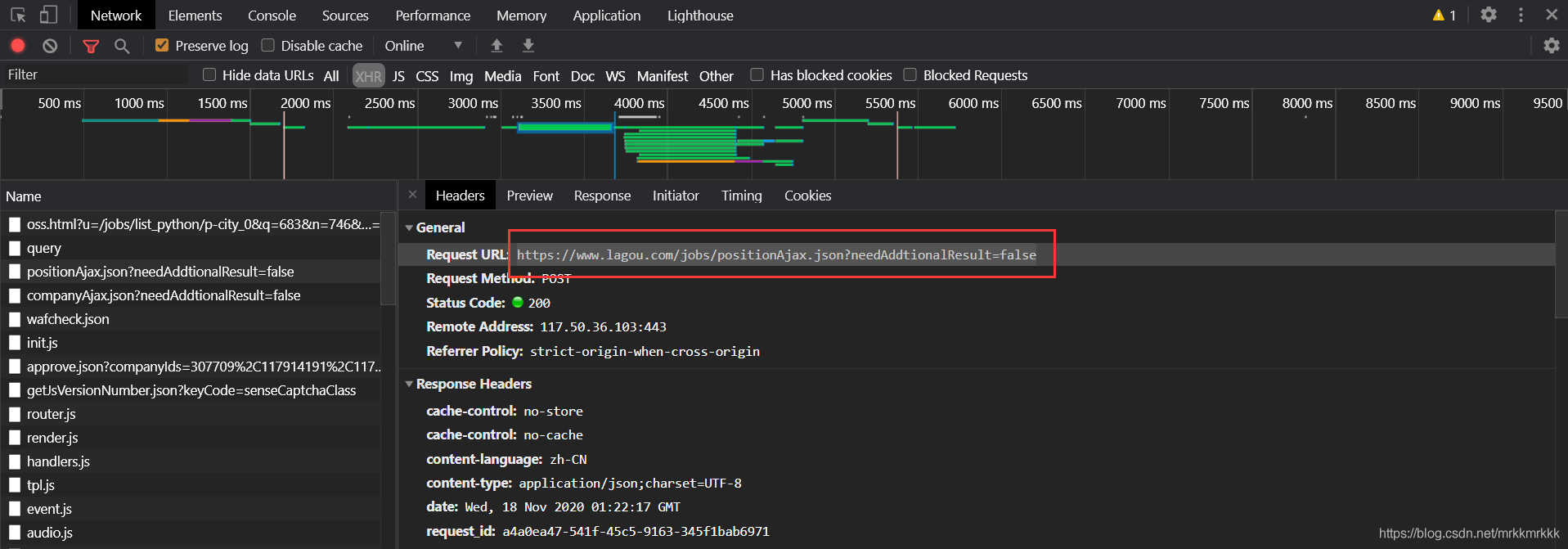
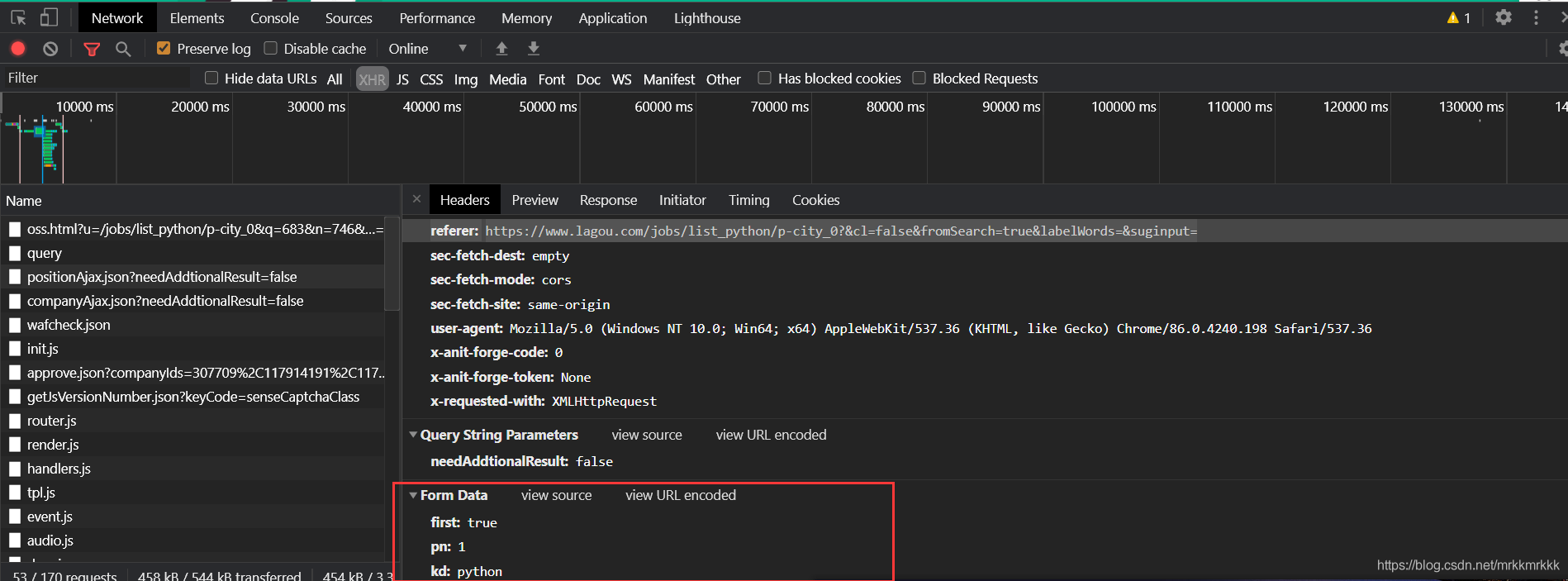
使用python构建post请求
data = {
'first': 'true',
'pn': '1',
'kd': 'python'
}
headers = {
'referer': 'https://www.lagou.com/jobs/list_python/p-city_0?&cl=false&fromSearch=true&labelWords=&suginput=',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
res = requests.post("https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false", data=data,headers=headers)
print(res.text)
发现没有从接口获取到数据

换了个网络后接口还是会返回操作频繁的错误信息,仔细检查后发现这个接口需要一个动态的cookies不然会一值返回错误频繁
data = {
'first': 'true',
'pn': '1',
'kd': 'python'
}
#头部中必须有user-agent和referer不然不会返回cookies
headers = {
'referer': 'https://www.lagou.com/jobs/list_python/p-city_0?&cl=false&fromSearch=true&labelWords=&suginput=',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
#通过访问主页获取cookies
r1= requests.get("https://www.lagou.com/jobs/list_python/p-city_0?&cl=false&fromSearch=true&labelWords=&suginput='",headers=headers)
#再post请求中传入cookies
r2 = requests.post("https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false", data=data,headers=headers, cookies=r2.cookies)
print(r2.text)
注意!每请求十次接口cookies也会刷新一次,下面贴上完整爬虫代码
import json
import logging
import requests
#获取cookie
def getCookie():
res = requests.get("https://www.lagou.com/jobs/list_python/p-city_0?&cl=false&fromSearch=true&labelWords=&suginput=",
headers=headers)
return res.cookies
#获取json数据
def getPage(i, cookies, kw):
data = {
'first': 'true',
'pn': i,
'kd': kw
}
res = requests.post("https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false", data=data,
headers=headers, cookies=cookies)
return json.loads(res.text)
#合并列表
def reduceList(l):
text = ""
for i in l:
text += i + " "
return text.strip()
#提取字段并保存到文件中
def saveInCsv(f, data):
js = data["content"]["positionResult"]["result"]
for node in js:
# 对空值进行处理
district = node["district"]
if district != None:
district = "-" + district
else:
district = ""
f.write(
node["positionName"] + "·" + node["city"] + district + "·" + node[
"salary"] + "·" +
node["workYear"] + "·" + node["education"] + "·" + reduceList(node["skillLables"]) + "·" +
node["companyShortName"] + "·" + node["companySize"] + "·" + node["positionAdvantage"] + "\n")
if __name__ == '__main__':
#定义头部
headers = {
'referer': 'https://www.lagou.com/jobs/list_python/p-city_0?&cl=false&fromSearch=true&labelWords=&suginput=',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36'
}
#初始化cookie
cookies = getCookie()
with open("file.csv", "w", encoding="utf-8") as f:
for i in range(1, 31):
#每十个请求重新获取cookie
if (i % 10 == 0):
cookies = getCookie()
#解析字段并存储
data = getPage(i, cookies, "python")
saveInCsv(f, data)
到此这篇关于python使用requests库爬取拉勾网招聘信息的实现的文章就介绍到这了,更多相关python requests爬取拉勾网内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python使用requests模块爬取百度翻译
requests模块: python中原生的一款基于网络请求的模块,功能非常强大,简单便捷,效率极高. 作用:模拟浏览器发请求. 提示:老版使用 urllib模块,但requests比urllib模块要简单好用,现在学习requests模块即可! requests模块编码流程 指定url 1.1 UA伪装 1.2 请求参数的处理 2.发起请求 3.获取响应数据 4.持久化存储 环境安装: pip install requests 案例一:破解百度翻译(post请求) 1.代码如下: #爬取百度翻
-

python requests库爬取豆瓣电视剧数据并保存到本地详解
首先要做的就是去豆瓣网找对应的接口,这里就不赘述了,谷歌浏览器抓包即可,然后要做的就是分析返回的json数据的结构: https://movie.douban.com/j/search_subjects?type=tv&tag=%E5%9B%BD%E4%BA%A7%E5%89%A7&sort=recommend&page_limit=20&page_start=0 这是接口地址,可以大概的分析一下各个参数的规则: type=tv,表示的是电视剧的分类 tag=国产剧,表示是
-
Python基于requests库爬取网站信息
requests库是一个简介且简单的处理HTTP请求的第三方库 get()是获取网页最常用的方式,其基本使用方式如下 使用requests库获取HTML页面并将其转换成字符串后,需要进一步解析HTML页面格式,这里我们常用的就是beautifulsoup4库,用于解析和处理HTML和XML 下面这段代码便是爬取百度的信息并简单输出百度的界面信息 import requests from bs4 import BeautifulSoup r=requests.get('http://www.bai
-
python3使用requests模块爬取页面内容的实战演练
1.安装pip 我的个人桌面系统用的linuxmint,系统默认没有安装pip,考虑到后面安装requests模块使用pip,所以我这里第一步先安装pip. $ sudo apt install python-pip 安装成功,查看PIP版本: $ pip -V 2.安装requests模块 这里我是通过pip方式进行安装: $ pip install requests 运行import requests,如果没提示错误,那说明已经安装成功了! 检验是否安装成功 3.安装beautifulsou
-
python3 requests库实现多图片爬取教程
最近对爬虫比较感兴趣,所以就学了一下,看人家都在网上爬取那么多美女图片养眼,我也迫不及待的试了一下,不多说,切入正题. 其实爬取图片和你下载图片是一个样子的,都是操作链接,也就是url,所以当我们确定要爬取的东西后就要开始寻找url了,所以先打开百度图片搜一下 然后使用浏览器F12进入开发者模式,或者右键检查元素 注意看xhr,点开观察有什么不一样的(如果没有xhr就在网页下滑) 第一个是这样的 第二个是这样的 注意看,pn是不是是30的倍数,而此时网页图片的数量也在增多,发现了这个,进url看
-
python requests爬取高德地图数据的实例
如下所示: 1.pip install requests 2.pip install lxml 3.pip install xlsxwriter import requests #想要爬必须引 from lxml import html #这个是用于页面爬取 import xlsxwriter#操作Excel表格库 workbook = xlsxwriter.Workbook('E:/test/test.xlsx')# 新建的Excel表格文档路径 worksheet = workbook.ad
-
python使用requests库爬取拉勾网招聘信息的实现
按F12打开开发者工具抓包,可以定位到招聘信息的接口 在请求中可以获取到接口的url和formdata,表单中pn为请求的页数,kd为关请求职位的关键字 使用python构建post请求 data = { 'first': 'true', 'pn': '1', 'kd': 'python' } headers = { 'referer': 'https://www.lagou.com/jobs/list_python/p-city_0?&cl=false&fromSearch=true&a
-
Python爬虫实例——scrapy框架爬取拉勾网招聘信息
本文实例为爬取拉勾网上的python相关的职位信息, 这些信息在职位详情页上, 如职位名, 薪资, 公司名等等. 分析思路 分析查询结果页 在拉勾网搜索框中搜索'python'关键字, 在浏览器地址栏可以看到搜索结果页的url为: 'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=', 尝试将?后的参数删除, 发现访问结果相同. 打开Chrome网页调试工具(F12), 分析每条搜索结果
-
Python用requests库爬取返回为空的解决办法
首先介紹一下我們用360搜索派取城市排名前20. 我们爬取的网址:https://baike.so.com/doc/24368318-25185095.html 我们要爬取的内容: html字段: robots协议: 现在我们开始用python IDLE 爬取 import requests r = requests.get("https://baike.so.com/doc/24368318-25185095.html") r.status_code r.text 结果分析,我们可以
-
通过python爬虫mechanize库爬取本机ip地址的方法
目录 需求分析 实现分析 实际使用 完整代码演示 需求分析 最近,各平台更新的ip属地功能非常火爆,因此呢,也出现了许多新的网络用语,比如说“xx加几分”,“xx扣大分”等等,非常的有趣啊 可是呢,最近一个小伙伴和我说,“仙草哥哥,我也想查看一下自己的ip地址,可是我不会啊,我应该怎么样才能查看到自己的ip地址呢?” 关于如何查看自己的ip地址,这个我记得我在很早之前已经写过了,有兴趣的话可以查看一下我的这篇文章,当然这次呢,我会换一个复古的方式,使用mechanize进行爬取 实现分析 pyt
-
Python通过正则库爬取淘宝商品信息代码实例
使用正则库爬取淘宝商品的商品信息,首先我们需要确定想要爬取的对象 我们在淘宝里搜索"python",出来的结果 从url连接中可以得到搜索商品的关键字是"q=",所以我们要用的起始url为:https://s.taobao.com/search?q=python 然后翻页,经过对比发现,翻页后,变化的关键字是s,每次翻页,s便以44的倍数增长(可以数一下每页显示的商品数量,刚好是44) 所以可以根据关键字"s=",来设置爬取的深度(爬取多少页)
-
node.js爬虫爬取拉勾网职位信息
简介 用node.js写了一个简单的小爬虫,用来爬取拉勾网上的招聘信息,共爬取了北京.上海.广州.深圳.杭州.西安.成都7个城市的数据,分别以前端.PHP.java.c++.python.Android.ios作为关键词进行爬取,爬到的数据以json格式储存到本地,为了方便观察,我将数据整理了一下供大家参考 数据结果 上述数据为3月13日22时爬取的数据,可大致反映各个城市对不同语言的需求量. 爬取过程展示 控制并发进行爬取 爬取到的数据文件 json数据文件 爬虫程序 实现思路 请求拉钩网的
-
Python如何使用正则表达式爬取京东商品信息
京东(JD.com)是中国最大的自营式电商企业,2015年第一季度在中国自营式B2C电商市场的占有率为56.3%.如此庞大的一个电商网站,上面的商品信息是海量的,小编今天就带小伙伴利用正则表达式,并且基于输入的关键词来实现主题爬虫. 首先进去京东网,输入自己想要查询的商品,小编在这里以关键词"狗粮"作为搜索对象,之后得到后面这一串网址: https://search.jd.com/Search?keyword=%E7%8B%97%E7%B2%AE&enc=utf-8,其实参数%