一分钟搞懂Redis的慢查询日志操作
目录
- 什么是慢查询?
- 什么是慢查询日志?
- 如何获取慢查询日志?
- 如何获取慢查询日志的长度?
- 如何清理慢查询日志?
- 怎么配置慢查询的参数?
- slowlog-log-slower-than
- slowlog-max-len
- 如何进行配置
- 总结
什么是慢查询?
慢查询,顾名思义就是比较慢的查询,但是究竟是哪里慢呢?首先,我们了解一下Redis命令执行的整个过程:
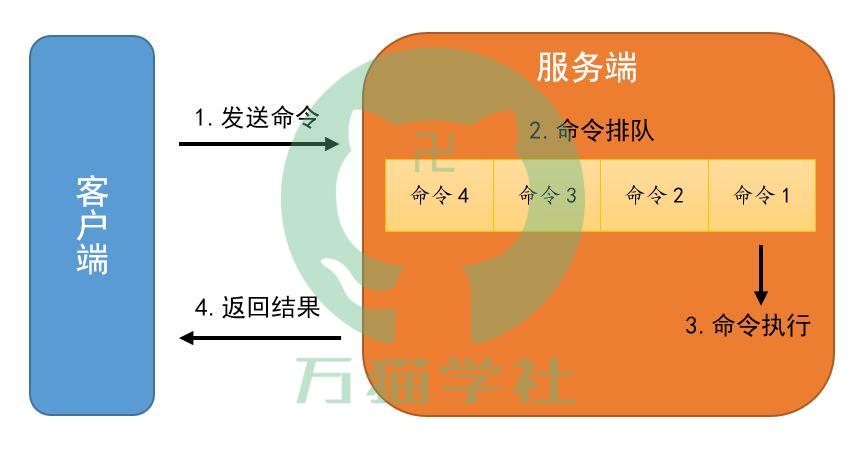
- 发送命令
- 命令排队
- 命令执行
- 返回结果
在慢查询的定义中,统计比较慢的时间段指的是命令执行这个步骤。没有慢查询,并不表示客户端没有超时问题,有可能网络传输有延迟,也有可能排队的命令比较多。
因为Redis中命令执行的排队机制,慢查询会导致其他命令的级联阻塞,所以当客户端出现请求超时的时候,需要检查该时间点是否有慢查询,从而分析出由于慢查询导致的命令级联阻塞。
什么是慢查询日志?
慢查询日志是Redis服务端在命令执行前后计算每条命令的执行时长,当超过某个阈值是记录下来的日志。日志中记录了慢查询发生的时间,还有执行时长、具体什么命令等信息,它可以用来帮助开发和运维人员定位系统中存在的慢查询。
如何获取慢查询日志?
可以使用slowlog get命令获取慢查询日志,在slowlog get后面还可以加一个数字,用于指定获取慢查询日志的条数,比如,获取3条慢查询日志:
> slowlog get 3
1) 1) (integer) 6107
2) (integer) 1616398930
3) (integer) 3109
4) 1) "config"
2) "rewrite"
2) 1) (integer) 6106
2) (integer) 1613701788
3) (integer) 36004
4) 1) "flushall"
3) 1) (integer) 6105
2) (integer) 1608722338
3) (integer) 20449
4) 1) "scan"
2) "0"
3) "MATCH"
4) "*comment*"
5) "COUNT"
6) "10000"
从上面的例子中,可以看出每一条慢查询日志都有4个属性组成:
- 唯一标识ID
- 命令执行的时间戳
- 命令执行时长
- 执行的命名和参数
如何获取慢查询日志的长度?
可以使用slowlog len命令获取慢查询日志的长度,比如:
> slowlog len (integer) 121
在上例中,当前Redis中有121条慢查询日志。
如何清理慢查询日志?
可以使用slowlog reset命令清理慢查询日志,比如:
> slowlog len (integer) 121 > slowlog reset OK > slowlog len (integer) 0
怎么配置慢查询的参数?
正如上面提到的,慢查询需要如下两个配置:
- 命令执行时长的指定阈值。
- 存放慢查询日志的条数。
Redis对应提供了两个参数:slowlog-log-slower-than和slowlog-max-len,接下来我们详细介绍一下这两个参数。
slowlog-log-slower-than
slowlog-log-slower-than的作用是指定命令执行时长的阈值,执行命令的时长超过这个阈值时就会被记录下来。它的单位是微秒(1秒 = 1000毫秒 = 1000000微秒),默认是10000微秒。如果把slowlog-log-slower-than设置为0,将会记录所有命令到日志中。如果把slowlog-log-slower-than设置小于0,将会不记录任何命令到日志中。
在实际的生产环境中,需要根据Redis并发量来调整该配置。因为Redis采用单线程响应命令,如果命令执行时间在1000微秒以上,那么Redis最多可支撑OPS不到1000,所以对于高并发场景的Redis建议设置为1000微秒。
slowlog-max-len
slowlog-max-len的作用是指定慢查询日志最多存储的条数。实际上,Redis使用了一个列表存放慢查询日志,slowlog-max-len就是这个列表的最大长度。当一个新的命令满足满足慢查询条件时,被插入这个列表中。当慢查询日志列表已经达到最大长度时,最早插入的那条命令将被从列表中移出。比如,slowlog-max-len被设置为10,当有第11条命令插入时,在列表中的第1条命令先被移出,然后再把第11条命令放入列表。
记录慢查询是Redis会对长命令进行截断,不会大量占用大量内存。在实际的生产环境中,为了减缓慢查询被移出的可能和更方便地定位慢查询,建议将慢查询日志的长度调整的大一些。比如可以设置为1000以上。
如何进行配置
在Redis中有两个修改配置的方法:
slowlog-log-slower-than 1000 slowlog-max-len 1200
修改Redis配置文件。比如,把slowlog-log-slower-than设置为1000,slowlog-max-len设置为1200:
使用config set命令动态修改。比如,还是把slowlog-log-slower-than设置为1000,slowlog-max-len设置为1200:
> config set slowlog-log-slower-than 1000 OK > config set slowlog-max-len 1200 OK > config rewrite OK
如果要Redis把配置持久化到本地配置文件,需要执行config rewrite命令。
总结
慢查询指的是命令执行时长比较长的查询。通过slowlog get命令获取慢查询日志;通过slowlog len命令获取慢查询日志的长度;通过slowlog reset命令清理慢查询日志。通过slowlog-log-slower-than配置命令执行时长的阈值;通过slowlog-max-len配置慢查询日志最多存储的条数。
到此这篇关于一分钟搞懂Redis的慢查询日志操作的文章就介绍到这了,更多相关Redis 慢查询内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
详解Redis的慢查询日志
Redis慢查询日志帮助开发和运维人员定位系统存在的慢操作.慢查询日志就是系统在命令执行前后计算每条命令的执行时间,当超过预设阀值,就将这条命令的相关信息(慢查询ID,发生时间戳,耗时,命令的详细信息)记录下来. Redis客户端一条命令分为如下四部分执行: 需要注意的是,慢查询日志只是统计步骤3)执行命令的时间,所以慢查询并不代表客户端没有超时问题.需要注意的是,慢查询日志只是统计步骤3)执行命令的时间,所以慢查询并不代表客户端没有超时问题. 一.慢查询的配置参数: 慢查询的预设阀值 slow
-
Redis分析慢查询操作的实例教程
什么是慢查询 慢查询的作用:通过慢查询分析,找到有问题的命令进行优化. 和mysql的慢SQL日志分析一样,redis也有类似的功能,来帮助定位一些慢查询操作. Redis slowlog是Redis用来记录查询执行时间的日志系统. 查询执行时间指的是不包括像客户端响应(talking).发送回复等IO操作,而单单是执行一个查询命令所耗费的时间. 另外,slow log保存在内存里面,读写速度非常快,因此你可以放心地使用它,不必担心因为开启slow log而损害Redis的速度. 慢查询日志四个
-

一分钟搞懂Redis的慢查询日志操作
目录 什么是慢查询? 什么是慢查询日志? 如何获取慢查询日志? 如何获取慢查询日志的长度? 如何清理慢查询日志? 怎么配置慢查询的参数? slowlog-log-slower-than slowlog-max-len 如何进行配置 总结 什么是慢查询? 慢查询,顾名思义就是比较慢的查询,但是究竟是哪里慢呢?首先,我们了解一下Redis命令执行的整个过程: 发送命令 命令排队 命令执行 返回结果 在慢查询的定义中,统计比较慢的时间段指的是命令执行这个步骤.没有慢查询,并不表示客户端没有超时问题,有
-
一文带你搞懂Redis分布式锁
目录 1.分布式锁简介 2.setnx 3.Redis-分布式锁-阶段1 4.Redis-分布式锁-阶段2 5.Redis-分布式锁-阶段3 6.Redis-分布式锁-阶段4 7.Redis-分布式锁-阶段5 1.分布式锁简介 分布式锁是控制分布式系统不同进程共同访问共享资源的一种锁的实现.如果不同的系统或同一个系统的不同主机之间共享了某个临界资源,往往需要互斥来防止彼此干扰,以保证一致性. 业界流行的分布式锁实现,一般有这3种方式: 基于数据库实现的分布式锁 基于Redis实现的分布式锁 基于
-
一文搞懂Mybatis-plus的分页查询操作
目录 1. 简单说明 2. 介绍说明 3. 完整配置类代码 4. 示例代码 5. 最后总结 1. 简单说明 嗨,大家好!今天给大家分享的是Mybatis-plus 插件的分页机制,说起分页机制,相信我们程序员都不陌生,今天,我就给大家分享一下Mybatis-plus的分页机制,供大家学习和Copy. 2. 介绍说明 如果你想看代码,可以直接跳到代码区域,这里只是一些简单的说明,如果你想学习,建议可以看看这一块的任容. 本章节将介绍 BaseMapper 中的分页查询,BaseMapper 接口提
-
一篇文章带你彻底搞懂Redis 事务
目录 Redis 事务简介 Redis 事务基本指令 实例分析 Redis 事务与 ACID 总结 Redis 事务简介 Redis 只是提供了简单的事务功能.其本质是一组命令的集合,事务支持一次执行多个命令,在事务执行过程中,会顺序执行队列中的命令,其他客户端提交的命令请求不会插入到本事务执行命令序列中.命令的执行过程是顺序执行的,但不能保证原子性.无法像 MySQL 那样,有隔离级别,出了问题之后还能回滚数据等高级操作.后面会详细分析. Redis 事务基本指令 Redis 提供了如下几个事
-
五分钟搞懂Vuex实用知识(小结)
这段时间一直在用vue写项目,vuex在项目中也会依葫芦画瓢使用,但是总有一种朦朦胧胧的感觉.于是决定彻底搞懂它. 看了一下午的官方文档,以及资料,才发现vuex so easy! 作为一个圈子中的人,决定输出一下文档,如果你仔细看完这篇文章,保证你对vuex熟练掌握. 我把自己的代码上传到了github,大家有需要的可以拉下来:github 先说一下vuex到底是什么? vuex 是一个专门为vue.js应用程序开发的状态管理模式. 这个状态我们可以理解为在data中的属性,需要共享给其他组件
-
一文快速搞懂Redis的几种数据类型方式
目录 Redis简介 Redis有几种数据类型 Redis的基本指令 String(字符串) List(列表) Set(集合) Hash(哈希) Zset(sorted set:有序集合) RedisDesktopManager数据查看工具 Redis简介 Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库.缓存和消息中间件. 它支持多种类型的数据结构,如 字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(so
-
三分钟搞懂react-hooks及实例代码
目录 背景 useState 类组件 函数组件 多状态声明 useEffect 类组件中componentDidMount和componentDidUpdate useEffect模拟类组件中componentDidMount和componentDidUpdate useEffect实现componmentWillUnment 父子组件传值useContext useReducer 背景 介绍Hooks之前,首先要说一下React的组件创建方式,一种是类组件,一种是纯函数组件,并且React团队
-
一文搞懂Redis中String数据类型
概述: 字符串类型是Redis中最为基础的数据存储类型,它在Redis中是二进制安全的,这便意味着该类型可以接受任何格式的数据,如JPEG图像数据或Json对象描述信息等.在Redis中字符串类型的Value最多可以容纳的数据长度是512M. 相关命令列表: 命令原型 时间复杂度 命令描述 返回值 APPEND O(1) 如果该Key已经存在,APPEND命令将参数Value的数据追加到已存在Value的末尾.如果该Key不存在,APPEND命令将会创建一个新的Key/Value. 追加后Va
-
几分钟搞懂c#之FileStream对象读写大文件(推荐)
还是一样,我先上代码,但是为了你们测试结果和我一样,必须先有准备工作,否则会找不到目录或者文件就没有效果: 既然是读取大文件,那么这个文本必须存在 现在来看目标目录 其实这里的文本文件可以删除,因为我们写入文本数据的时候的模式是当没有找到文件就创建新的. 下面上的上代码 "` using System; using System.Collections.Generic; using System.IO; using System.Reflection; using System.Text; na