Go 模块在下游服务抖动恢复后CPU占用无法恢复原因
目录
- 引言
- 优先复用
- 创建 g
- allgs 在什么地方会用到
引言
某团圆节日公司服务到达历史峰值 10w+ QPS,而之前没有预料到营销系统又在峰值期间搞事情,雪上加霜,流量增长到 11w+ QPS,本组服务差点被打挂(汗
所幸命大虽然 CPU idle 一度跌至 30 以下,最终还是幸存下来,没有背上过节大锅。与我们的服务代码写的好不无关系(拍飞
事后回顾现场,发现服务恢复之后整体的 CPU idle 和正常情况下比多消耗了几个百分点,感觉十分惊诧。恰好又祸不单行,工作日午后碰到下游系统抖动,虽然短时间恢复,我们的系统相比恢复前还是多消耗了两个百分点。如下图:
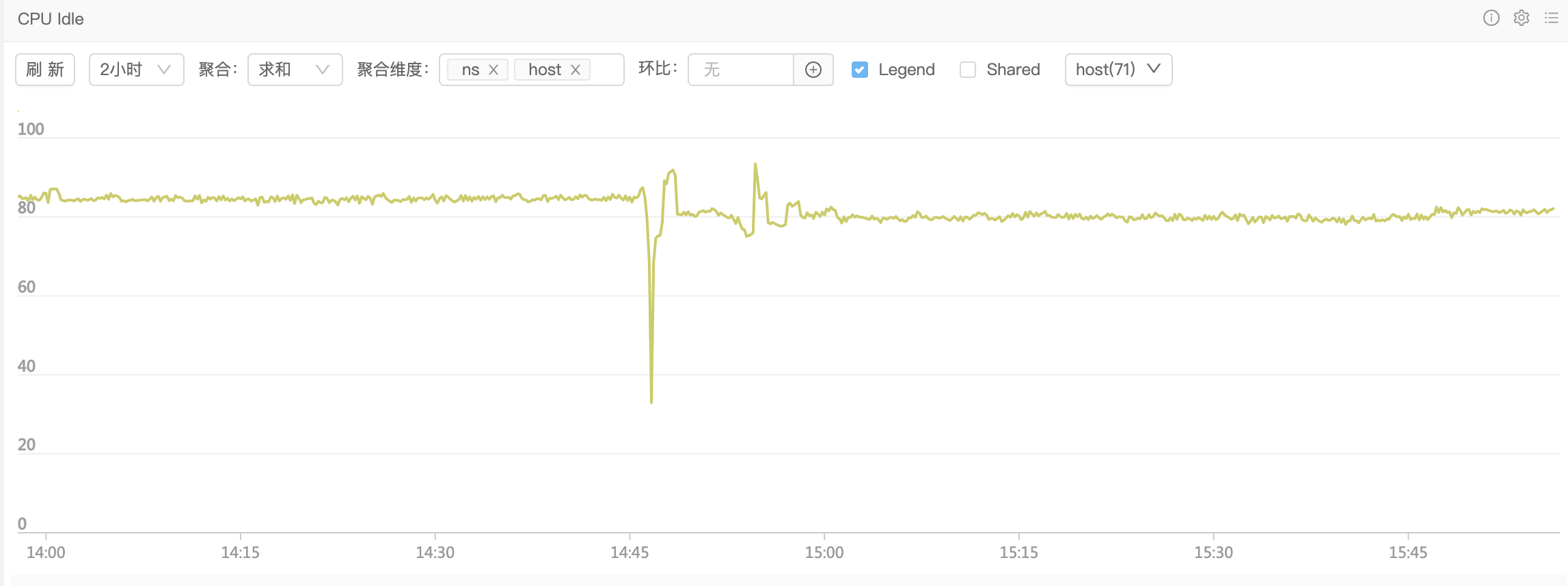
确实不太符合直觉,cpu 的使用率上会发现 GC 的各个函数都比平常用的 cpu 多了那么一点点,那我们只能看看 inuse 是不是有什么变化了,一看倒是吓了一跳:
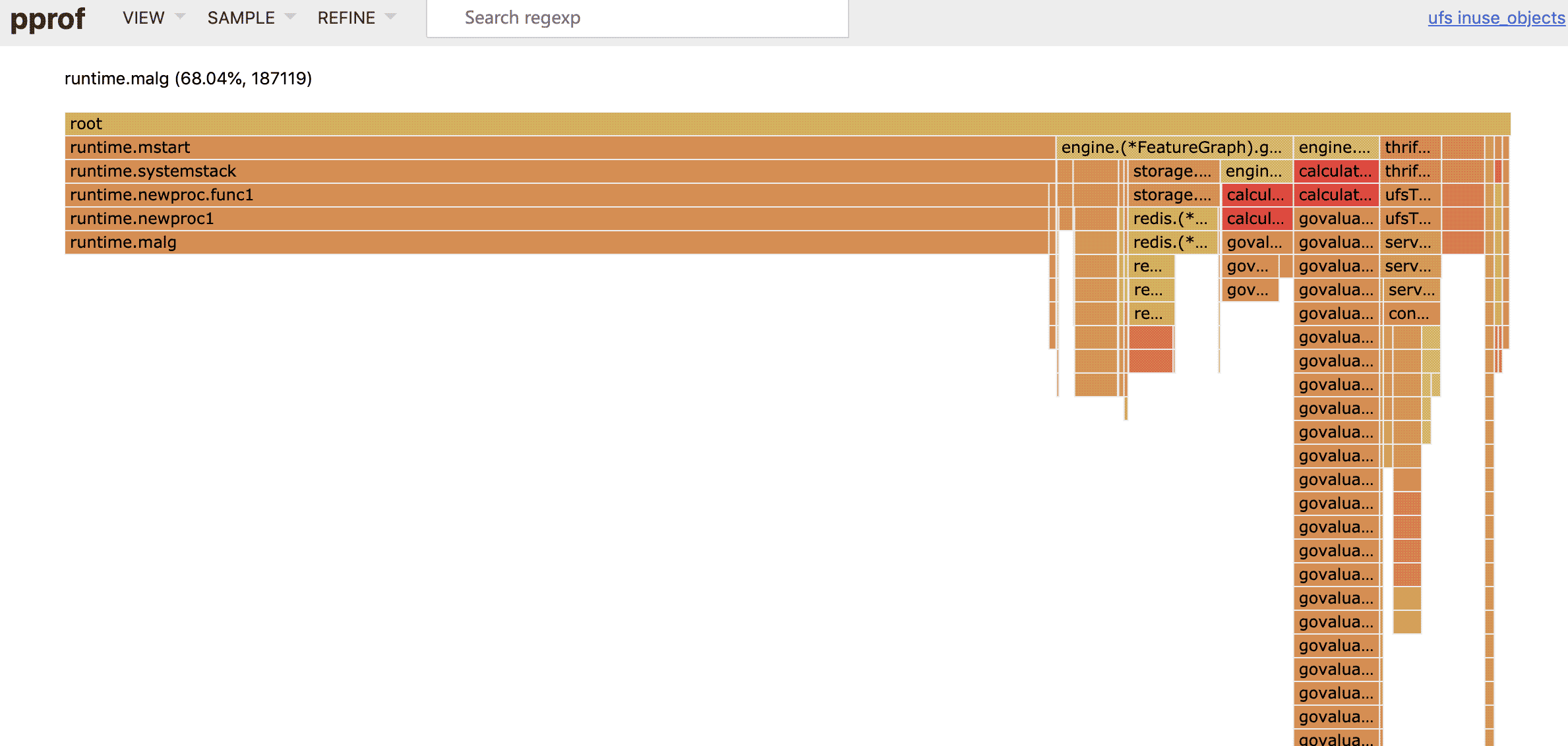
这个 mstart -> systemstack -> newproc -> malg 显然是 go func 的时候的函数调用链,按道理来说,创建 goroutine 结构体时,如果可用的 g 和 sudog 结构体能够复用,会优先进行复用:
优先复用
func gfput(_p_ *p, gp *g) {
if readgstatus(gp) != _Gdead {
throw("gfput: bad status (not Gdead)")
}
stksize := gp.stack.hi - gp.stack.lo
if stksize != _FixedStack {
// non-standard stack size - free it.
stackfree(gp.stack)
gp.stack.lo = 0
gp.stack.hi = 0
gp.stackguard0 = 0
}
_p_.gFree.push(gp)
_p_.gFree.n++
if _p_.gFree.n >= 64 {
lock(&sched.gFree.lock)
for _p_.gFree.n >= 32 {
_p_.gFree.n--
gp = _p_.gFree.pop()
if gp.stack.lo == 0 {
sched.gFree.noStack.push(gp)
} else {
sched.gFree.stack.push(gp)
}
sched.gFree.n++
}
unlock(&sched.gFree.lock)
}
}
func gfget(_p_ *p) *g {
retry:
if _p_.gFree.empty() && (!sched.gFree.stack.empty() || !sched.gFree.noStack.empty()) {
lock(&sched.gFree.lock)
for _p_.gFree.n < 32 {
// Prefer Gs with stacks.
gp := sched.gFree.stack.pop()
if gp == nil {
gp = sched.gFree.noStack.pop()
if gp == nil {
break
}
}
sched.gFree.n--
_p_.gFree.push(gp)
_p_.gFree.n++
}
unlock(&sched.gFree.lock)
goto retry
}
gp := _p_.gFree.pop()
if gp == nil {
return nil
}
_p_.gFree.n--
if gp.stack.lo == 0 {
systemstack(func() {
gp.stack = stackalloc(_FixedStack)
})
gp.stackguard0 = gp.stack.lo + _StackGuard
} else {
// ....
}
return gp
}
创建 g
怎么会出来这么多 malg 呢?再来看看创建 g 的代码:
func newproc1(fn *funcval, argp *uint8, narg int32, callergp *g, callerpc uintptr) {
_g_ := getg()
// .... 省略无关代码
_p_ := _g_.m.p.ptr()
newg := gfget(_p_)
if newg == nil {
newg = malg(_StackMin)
casgstatus(newg, _Gidle, _Gdead)
allgadd(newg) // 重点在这里
}
}
一旦在 当前 p 的 gFree 和全局的 gFree 找不到可用的 g,就会创建一个新的 g 结构体,该 g 结构体会被 append 到全局的 allgs 数组中:
var ( allgs []*g allglock mutex )
allgs 在什么地方会用到
GC 的时候
func gcResetMarkState() {
lock(&allglock)
for _, gp := range allgs {
gp.gcscandone = false // set to true in gcphasework
gp.gcscanvalid = false // stack has not been scanned
gp.gcAssistBytes = 0
}
}
检查死锁的时候:
func checkdead() {
// ....
grunning := 0
lock(&allglock)
for i := 0; i < len(allgs); i++ {
gp := allgs[i]
if isSystemGoroutine(gp, false) {
continue
}
}
}
检查死锁这个操作在每次 sysmon、创建 templateThread、线程进 idle 队列的时候都会调用,调用频率也不能说特别低。
翻阅了所有 allgs 的引用代码,发现该数组创建之后,并不会收缩。
我们可以根据上面看到的所有代码,来还原这种抖动情况下整个系统的情况了:
- 下游系统超时,很多 g 都被阻塞了,挂在 gopark 上,相当于提高了系统的并发
- 因为 gFree 没法复用,导致创建了比平时更多的 goroutine(具体有多少,就看你超时设置了多少
- 抖动时创建的 goroutine 会进入全局 allgs 数组,该数组不会进行收缩,且每次 gc、sysmon、死锁检查期间都会进行全局扫描
- 上述全局扫描导致我们的系统在下游系统抖动恢复之后,依然要去扫描这些抖动时创建的 g 对象,使 cpu 占用升高,idle 降低。
- 只能重启
看起来并没有什么解决办法,如果想要复现这个问题的读者,可以试一下下面这个程序:
package main
import (
"log"
"net/http"
_ "net/http/pprof"
"time"
)
func sayhello(wr http.ResponseWriter, r *http.Request) {}
func main() {
for i := 0; i < 1000000; i++ {
go func() {
time.Sleep(time.Second * 10)
}()
}
http.HandleFunc("/", sayhello)
err := http.ListenAndServe(":9090", nil)
if err != nil {
log.Fatal("ListenAndServe:", err)
}
}
启动后等待 10s,待所有 goroutine 都散过后,pprof 的 inuse 的 malg 依然有百万之巨。
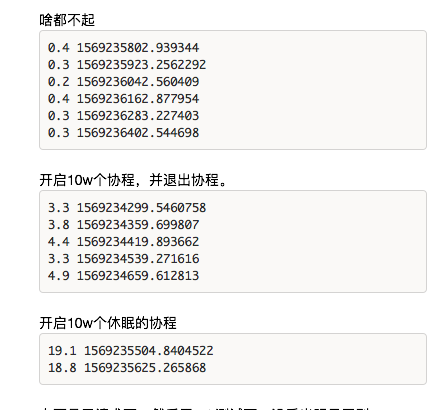
循环查看单个进程的 cpu 消耗:
import psutil
import time
p = psutil.Process(1) # 改成你自己的 pid 就行了
while 1:
v = str(p.cpu_percent())
if "0.0" != v:
print(v, time.time())
time.sleep(1)
以上就是Go 模块在下游服务抖动恢复后CPU占用无法恢复原因的详细内容,更多关于Go CPU占用无法恢复原因的资料请关注我们其它相关文章!
相关推荐
-

Golang如何编写内存高效及CPU调优的Go结构体
目录 前言 输出结果 输出结果 前言 结构体是包含多个字段的集合类型,用于将数据组合为记录.这样可以将与同一实体相关联的数据利落地封装到一个轻量的类型定义中,然后通过对该结构体类型定义方法来实现不同的行为. 本文会尝试从内存利用和CPU周期的角度讲解如何高效编写struct. 我们来看下面这一结构体,这是我们一个奇怪用例所定义的terraform资源类型: type TerraformResource struct { Cloud string // 16字节 Name string // 16
-
golang中定时器cpu使用率高的现象详析
前言: 废话少说,上线一个用golang写的高频的任务派发系统,上线跑着很稳定,但有个缺点就是当没有任务的时候,cpu的消耗也在几个百分点. 平均值在3%左右的cpu使用率.你没有任务的时候,cpu还跑到3%,这个说不过去呀.通过查看进程pidstat捕获得知,system系统的cpu消耗也不少. sys的cpu占用率高一般是由于大量的syscall系统调用引起的-. 下面的截图是用strace统计出来的系统调用-. 我们发现 futex 和 pselect6 的syscall非常的多-.
-
解决正则表示式匹配($regex)引起的一次mongo数据库cpu占用率高的问题
某一天,监控到mongo数据库cpu使用率高了很多,查了一下,发现是下面这种语句引起的: db.example_collection.find({ "idField" : { "$regex" : "123456789012345678" } , "dateField" : { "$regex" : "2019/10/10" }}) 通常,遇到这种情况,我第一反应是缺少相关字段的索引,导
-
MongoDb CPU利用率过高问题如何解决
在公司的项目中,突然出现过一个情况,mongodb 的CPU利用率到达100%,导致服务器这边卡死了,请求了半天无响应,提示请求超时. 因为,当时APP用户可能会在某一个时间段集中的使用,所以,请求量一下子就飙上去了,刚好APP打开请求的时候,有一个mongodb的请求. 当时因为Mongodb的服务器不在我们这边,所以一下子没反应过来,不过最后还是给排除出,并解决了.这里就来记录下排查和解决的全过程. 问题分析: 1.根据代码,定位到了是Mongodb的报错. 2.进入Mongodb 服务器的
-
linux下通过go语言获得系统进程cpu使用情况的方法
本文实例讲述了linux下通过go语言获得系统进程cpu使用情况的方法.分享给大家供大家参考.具体分析如下: 这段代码通过linux的系统命令 ps来分析cpu的使用情况,代码如下: 复制代码 代码如下: package main import ( "bytes" "log" "os/exec" "strconv" "strings" ) type Process s
-
golang通过node_exporter监控GPU及cpu频率、温度的代码
导语:通过node_exporter监控GPU以及cpu频率.温度,不想用一个node_exporter再加一个dcgm,分开监控.我这里监控的是热区的温度.如果需要监控各个cpu核心的温度需要修改一下代码. 结合了https://gitee.com/kevinliu_CQ/node_exporter监控GPU的代码. 加入了cpu的2项自定义监控https://gitee.com/jiaminxu/self_node_exporter 安装一下go wget https://dl.google
-
Go 模块在下游服务抖动恢复后CPU占用无法恢复原因
目录 引言 优先复用 创建 g allgs 在什么地方会用到 引言 某团圆节日公司服务到达历史峰值 10w+ QPS,而之前没有预料到营销系统又在峰值期间搞事情,雪上加霜,流量增长到 11w+ QPS,本组服务差点被打挂(汗 所幸命大虽然 CPU idle 一度跌至 30 以下,最终还是幸存下来,没有背上过节大锅.与我们的服务代码写的好不无关系(拍飞 事后回顾现场,发现服务恢复之后整体的 CPU idle 和正常情况下比多消耗了几个百分点,感觉十分惊诧.恰好又祸不单行,工作日午后碰到下游系统抖动
-
使用阿里云OSS的服务端签名后直传功能的流程分析
网站一般都会有上传功能,而对象存储服务oss是一个很好的选择.可以快速的搭建起自己的上传文件功能. 该文章以使用阿里云的OSS功能为例,记录如何在客户端使用阿里云的对象存储服务. 服务端签名后直传 背景 采用JavaScript客户端直接签名(参见JavaScript客户端签名直传)时,AccessKey ID和AcessKey Secret会暴露在前端页面,因此存在严重的安全隐患.因此,OSS提供了服务端签名后直传的方案. 流程介绍 流程如下图所示: 本示例中,Web端向服务端请求签名,然后直
-
SQL Server恢复模型之批量日志恢复模式
你是否想知道为什么事务日志文件会变得越来越大?事务日志有时候甚至会比你的实际数据库文件还要大,尤其是在应用数据仓库的情况下.为什么会发生这种情况呢?如何控制其大小?数据库恢复模型如何控制事务日志增长?在本系列文章中,我们就将一一给出解答. 批量日志恢复模式 批量日志恢复模式与完整恢复模式类似,都预期会有大批量的数据修改操作(例如,创建索引,SELECT INTO,INSERT SELECT,BCP,BULKINSERT),在这种情况下可以最小化日志记录量,因此它降低了性能影响.但是同时代价就是你
-
SQL Server数据库的三种恢复模式:简单恢复模式、完整恢复模式和大容量日志恢复模式
如何图形界面下修改恢复模式 找到你想修改的数据库 右键 > 属性 > 左侧 选项既可看到 1.Simple 简单恢复模式, Simple模式的旧称叫"Checkpoint with truncate log",其实这个名字更形象,在Simple模式下,SQL Server会在每次checkpoint或backup之后自动截断log,也就是丢弃所有的inactive log records,仅保留用于实例启动时自动发生的instance recovery所需的少量log,这
-
python进程结束后端口占用问题解析
目录 socket分配 例子 解决方案 其他 socket分配 一个服务端进程向操作系统申请一个 scoket 来监听,但是当进程退出后,还未关闭的连接不会立即消失,而是会留给操作系统处理.操作系统会尝试关闭这个连接.但是如果关闭时出现问题,这个连接就会一直处于 TIME_WAIT 或其他非正常状态,而这是相应的端口还处于占用状态,如果这个时候再重新启动这个服务端程序,就会出现地址被占用的情况 例子 测试代码: import socket s = socket.socket() s.bind((
-
pytorch程序异常后删除占用的显存操作
1-删除模型变量 del model_define 2-清空CUDA cache torch.cuda.empty_cache() 3-步骤2(异步)需要一定时间,设置时延 time.sleep(5) 完整代码如下: del styler torch.cuda.empty_cache() time.sleep(5) 以上这篇pytorch程序异常后删除占用的显存操作就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
vue打包后出现空白页的原因及解决方式详解
目录 路由模式 history 路由模式 hash 总结 1. 修改路径 2. 更改路由模式 路由模式拓展 路由的hash和history模式的区别 打包路由选择 路由模式 history 新建项目什么都不动,路由模式:history, 直接npm run build打包 打包之后,直接打开dist文件里面的ndex.html可以看到页面是空白的,控制台是这样的. 再看看网页源码, 对比dist文件夹结构可以看到资源路径的引入是错误的,应该用'./'而不是'/' 那怎么修改打包之后的路径呢?查看
-
java面试应用上线后Cpu使用率飙升如何排查
目录 引言 模拟一个高CPU场景 排查步骤 第一步,使用 top 找到占用 CPU 最高的 Java 进程 第二步,用 top -Hp 命令查看占用 CPU 最高的线程 第三步,查看堆栈信息,定位对应代码 小结 引言 上次面试官问了个问题:应用上线后Cpu使用率飙升如何排查? 其实这是个很常见的问题,也非常简单,那既然如此我为什么还要写呢?因为上次回答的时候我忘记将线程PID转换成16进制的命令了. 所以我决定再重温一遍这个问题,当然贴心的我还给大家准备好了测试代码,大家可以实际操作一下,这样下
-
node.js ws模块搭建websocket服务端的方法示例
首先下载websocket模块,命令行输入 npm install ws node.js的 模块ws,可用于创建websocket服务,基本的express 和 http模块的使用 var express = require('express'); var http = require('http'); var WebSocket = require('ws'); var app = express(); var server = http.createServer(app); var wss
-
python模块hashlib(加密服务)知识点讲解
官方文案:https://docs.python.org/zh-cn/3/library/hashlib.html hashlib --- 安全哈希与消息摘要 Python的hashlib提供了常见的摘要算法,如MD5,SHA1等等. 什么是摘要digest algorithms算法呢?摘要算法又称哈希hash算法.散列算法.它通过一个函数,把任意长度的数据转换为一个长度固定的数据串(通常用16进制的字符串表示). hash算法 每种类型的hash都有一个构建器方法,返回一个hash对象和相同的