Python定时爬取微博热搜示例介绍
目录
- 前言
- 页面分析
- 采集代码
- 设置定时运行
前言
相信大家在工作无聊时,总想掏出手机,看看微博热搜在讨论什么有趣的话题,但又不方便直接打开微博浏览,今天就和大家分享一个有趣的小爬虫,定时采集微博热搜榜&热评,下面让我们来看看具体的实现方法。
页面分析
热搜页
热榜首页:https://s.weibo.com/top/summary?cate=realtimehot
热榜首页的榜单中共五十条数据,在这个页面,我们需要获取排行、热度、标题,以及详情页的链接。

我们打开页面后要先 登录,之后使用 F12 打开开发者工具,Ctrl + R 刷新页面后找到第一条数据包。这里需要记录一下自己的 Cookie 与 User-Agent。
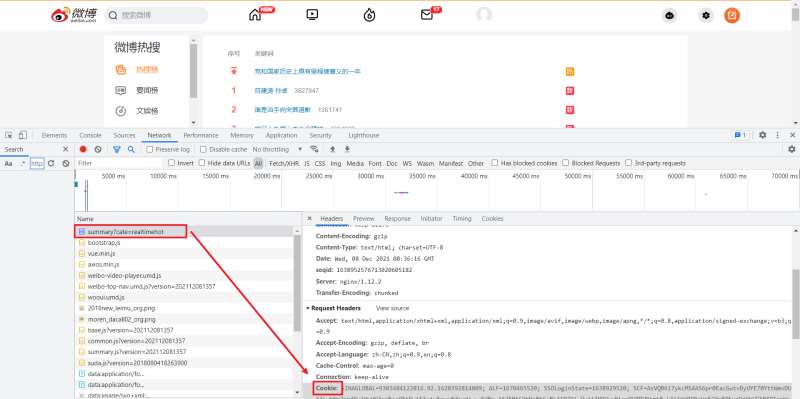
对于标签的定位,直接使用 Google 工具获取标签的 xpath 表达式即可。
详情页
对于详情页,我们需要获取评论时间、用户名称、转发次数、评论次数、点赞次数、评论内容这部分信息。

方法与热搜页采集方式基本相同,下面看看如何用代码实现!
采集代码
首先导入所需要的模块。
import requests from time import sleep import pandas as pd import numpy as np from lxml import etree import re
定义全局变量。
headers:请求头all_df:DataFrame,保存采集的数据
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.54 Safari/537.36',
'Cookie': '''你的Cookie'''
}
all_df = pd.DataFrame(columns=['排行', '热度', '标题', '评论时间', '用户名称', '转发次数', '评论次数', '点赞次数', '评论内容'])
热搜榜采集代码,通过 requests 发起请求,获取详情页链接后,跳转进入详情页采集 get_detail_page。
def get_hot_list(url):
'''
微博热搜页面采集,获取详情页链接后,跳转进入详情页采集
:param url: 微博热搜页链接
:return: None
'''
page_text = requests.get(url=url, headers=headers).text
tree = etree.HTML(page_text)
tr_list = tree.xpath('//*[@id="pl_top_realtimehot"]/table/tbody/tr')
for tr in tr_list:
parse_url = tr.xpath('./td[2]/a/@href')[0]
detail_url = 'https://s.weibo.com' + parse_url
title = tr.xpath('./td[2]/a/text()')[0]
try:
rank = tr.xpath('./td[1]/text()')[0]
hot = tr.xpath('./td[2]/span/text()')[0]
except:
rank = '置顶'
hot = '置顶'
get_detail_page(detail_url, title, rank, hot)
根据详情页链接,解析所需页面数据,并保存到全局变量 all_df 中,对于每个热搜只采集热评前三条,热评不够则跳过。
def get_detail_page(detail_url, title, rank, hot):
'''
根据详情页链接,解析所需页面数据,并保存到全局变量 all_df
:param detail_url: 详情页链接
:param title: 标题
:param rank: 排名
:param hot: 热度
:return: None
'''
global all_df
try:
page_text = requests.get(url=detail_url, headers=headers).text
except:
return None
tree = etree.HTML(page_text)
result_df = pd.DataFrame(columns=np.array(all_df.columns))
# 爬取3条热门评论信息
for i in range(1, 4):
try:
comment_time = tree.xpath(f'//*[@id="pl_feedlist_index"]/div[4]/div[{i}]/div[2]/div[1]/div[2]/p[1]/a/text()')[0]
comment_time = re.sub('\s','',comment_time)
user_name = tree.xpath(f'//*[@id="pl_feedlist_index"]/div[4]/div[{i}]/div[2]/div[1]/div[2]/p[2]/@nick-name')[0]
forward_count = tree.xpath(f'//*[@id="pl_feedlist_index"]/div[4]/div[{i}]/div[2]/div[2]/ul/li[1]/a/text()')[1]
forward_count = forward_count.strip()
comment_count = tree.xpath(f'//*[@id="pl_feedlist_index"]/div[4]/div[{i}]/div[2]/div[2]/ul/li[2]/a/text()')[0]
comment_count = comment_count.strip()
like_count = tree.xpath(f'//*[@id="pl_feedlist_index"]/div[4]/div[{i}]/div[2]/div[2]/ul/li[3]/a/button/span[2]/text()')[0]
comment = tree.xpath(f'//*[@id="pl_feedlist_index"]/div[4]/div[{i}]/div[2]/div[1]/div[2]/p[2]//text()')
comment = ' '.join(comment).strip()
result_df.loc[len(result_df), :] = [rank, hot, title, comment_time, user_name, forward_count, comment_count, like_count, comment]
except Exception as e:
print(e)
continue
print(detail_url, title)
all_df = all_df.append(result_df, ignore_index=True)
调度代码,向 get_hot_list 中传入热搜页的 url ,最后进行保存即可。
if __name__ == '__main__':
url = 'https://s.weibo.com/top/summary?cate=realtimehot'
get_hot_list(url)
all_df.to_excel('工作文档.xlsx', index=False)
对于采集过程中对于一些可能发生报错的地方,为保证程序的正常运行,都通过异常处理给忽略掉了,整体影响不大!
工作文档.xlsx

设置定时运行
至此,采集代码已经完成,想要实现每小时自动运行代码,可以使用任务计划程序。
在此之前需要我们简单修改一下上面代码中的Cookie与最后文件的保存路径(建议使用绝对路径),如果在 Jupyter notebook 中运行的需要导出一个 .py 文件
打开任务计划程序,【创建任务】

输入名称,名称随便起就好。

选择【触发器】>>【新建】>>【设置触发时间】

选择【操作】>>【新建】>>【选择程序】

最后确认即可。到时间就会自动运行,或者右键任务手动运行。
运行效果

到此这篇关于Python定时爬取微博热搜示例介绍的文章就介绍到这了,更多相关Python爬取微博热搜内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python爬虫分析微博热搜关键词的实现代码
1,使用到的第三方库 requests BeautifulSoup 美味汤 worldcloud 词云 jieba 中文分词 matplotlib 绘图 2,代码实现部分 import requests import wordcloud import jieba from bs4 import BeautifulSoup from matplotlib import pyplot as plt from pylab import mpl #设置字体 mpl.rcParams['font.sans
-
python实战之Scrapy框架爬虫爬取微博热搜
前言:大概一年前写的,前段时间跑了下,发现还能用,就分享出来了供大家学习,代码的很多细节不太记得了,也尽力做了优化. 因为毕竟是微博,反爬技术手段还是很周全的,怎么绕过反爬的话要在这说都可以单独写几篇文章了(包括网页动态加载,ajax动态请求,token密钥等等,特别是二级评论,藏得很深,记得当时想了很久才成功拿到),直接上代码. 主要实现的功能: 0.理所应当的,绕过了各种反爬. 1.爬取全部的热搜主要内容. 2.爬取每条热搜的相关微博. 3.爬取每条相关微博的评论,评论用户的各种详细信息.
-
如何用python爬取微博热搜数据并保存
主要用到requests和bf4两个库 将获得的信息保存在d://hotsearch.txt下 import requests; import bs4 mylist=[] r = requests.get(url='https://s.weibo.com/top/summary?Refer=top_hot&topnav=1&wvr=6',timeout=10) print(r.status_code) # 获取返回状态 r.encoding=r.apparent_encoding demo
-
Python网络爬虫之爬取微博热搜
微博热搜的爬取较为简单,我只是用了lxml和requests两个库 url= https://s.weibo.com/top/summary?Refer=top_hot&topnav=1&wvr=6 1.分析网页的源代码:右键--查看网页源代码. 从网页代码中可以获取到信息 (1)热搜的名字都在<td class="td-02">的子节点<a>里 (2)热搜的排名都在<td class=td-01 ranktop>的里(注意置顶微博是
-
Python定时爬取微博热搜示例介绍
目录 前言 页面分析 采集代码 设置定时运行 前言 相信大家在工作无聊时,总想掏出手机,看看微博热搜在讨论什么有趣的话题,但又不方便直接打开微博浏览,今天就和大家分享一个有趣的小爬虫,定时采集微博热搜榜&热评,下面让我们来看看具体的实现方法. 页面分析 热搜页 热榜首页:https://s.weibo.com/top/summary?cate=realtimehot 热榜首页的榜单中共五十条数据,在这个页面,我们需要获取排行.热度.标题,以及详情页的链接. 我们打开页面后要先 登录,之后使用 F
-
python+selenium爬取微博热搜存入Mysql的实现方法
最终的效果 废话不多少,直接上图 这里可以清楚的看到,数据库里包含了日期,内容,和网站link 下面我们来分析怎么实现 使用的库 import requests from selenium.webdriver import Chrome, ChromeOptions import time from sqlalchemy import create_engine import pandas as pd 目标分析 这是微博热搜的link:点我可以到目标网页 首先我们使用selenium对目标网页进
-
Python爬虫爬取微博热搜保存为 Markdown 文件的源码
什么是爬虫? 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本.另外一些不常使用的名字还有蚂蚁.自动索引.模拟程序或者蠕虫. 其实通俗的讲就是通过程序去获取web页面上自己想要的数据,也就是自动抓取数据 爬虫可以做什么? 你可以爬取小姐姐的图片,爬取自己有兴趣的岛国视频,或者其他任何你想要的东西,前提是,你想要的资源必须可以通过浏览器访问的到. 爬虫的本质是什么? 上面关于爬虫可以做什么,定义了一个前提
-
Python 爬取微博热搜页面
前期准备: fiddler 抓包工具Python3.6谷歌浏览器 分析: 1.清理浏览器缓存cookie以至于看到整个请求过程,因为Python代码开始请求的时候不带任何缓存.2.不考虑过多的header参数,先请求一次,看看返回结果 图中第一个链接是无缓存cookie直接访问的,状态码为302进行了重定向,用返回值.url会得到该url后面会用到(headers里的Referer参数值)2 ,3 链接没有用太大用处为第 4 个链接做铺垫但是都可以用固定参数可以不用访问 cb 和fp参数都是前两
-
Python 爬取微博热搜页面
前期准备: fiddler 抓包工具Python3.6谷歌浏览器 分析: 1.清理浏览器缓存cookie以至于看到整个请求过程,因为Python代码开始请求的时候不带任何缓存.2.不考虑过多的header参数,先请求一次,看看返回结果 图中第一个链接是无缓存cookie直接访问的,状态码为302进行了重定向,用返回值.url会得到该url后面会用到(headers里的Referer参数值)2 ,3 链接没有用太大用处为第 4 个链接做铺垫但是都可以用固定参数可以不用访问 访问https://pa
-
用Python实现爬取百度热搜信息
目录 前言 库函数准备 数据爬取 网页爬取 数据解析 数据保存 总结 前言 何为爬虫,其实就是利用计算机模拟人对网页的操作 例如 模拟人类浏览购物网站 使用爬虫前一定要看目标网站可刑不可刑 :-) 可以在目标网站添加/robots.txt 查看网页具体信息 例如对天猫 可输入 https://brita.tmall.com/robots.txt 进行查看 User-agent 代表发送请求的对象 星号*代表任何搜索引擎 Disallow 代表不允许访问的部分 /代表从根目录开始 Allow代
-
python爬虫爬取微博评论案例详解
前几天,杨超越编程大赛火了,大家都在报名参加,而我也是其中的一员. 在我们的项目中,我负责的是数据爬取这块,我主要是把对于杨超越 的每一条评论的相关信息. 数据格式:{"name":评论人姓名,"comment_time":评论时间,"comment_info":评论内容,"comment_url":评论人的主页} 以上就是我们需要的信息. 爬虫前的分析: 以上是杨超越的微博主页,这是我们首先需要获取到的内容. 因为我们需要等