Python 通过爬虫实现GitHub网页的模拟登录的示例代码
1. 实例描述
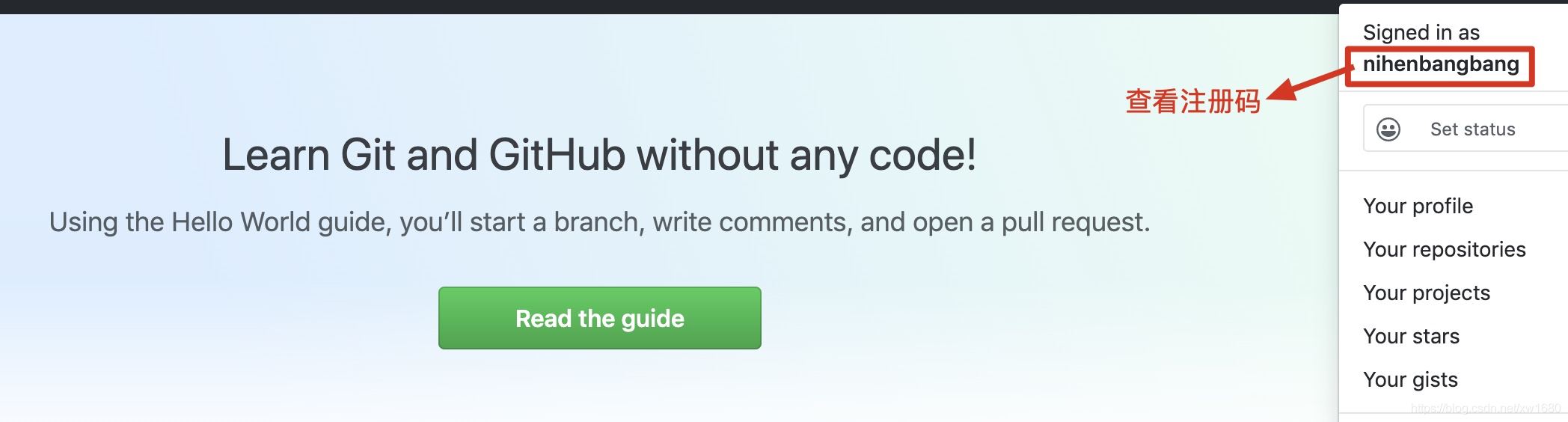
通过爬虫获取网页的信息时,有时需要登录网页后才可以获取网页中的可用数据,例如获取 GitHub 网页中的注册号码时,就需要先登录账号才能在登录后的页面中看到该信息,如下图所示。那么该如何实现模拟登录的功能呢?本文实现将通过爬虫实现 GitHub 网页的模拟登录。
2. 代码实现
在实现 GitHub 网页的模拟登录时,首先需要查看提交登录请求时都要哪些请求参数,然后获取登录请求的所有参数,再发送登录请求。如果登录成功的情况下获取页面中的注册号码信息即可。具体步骤如下:
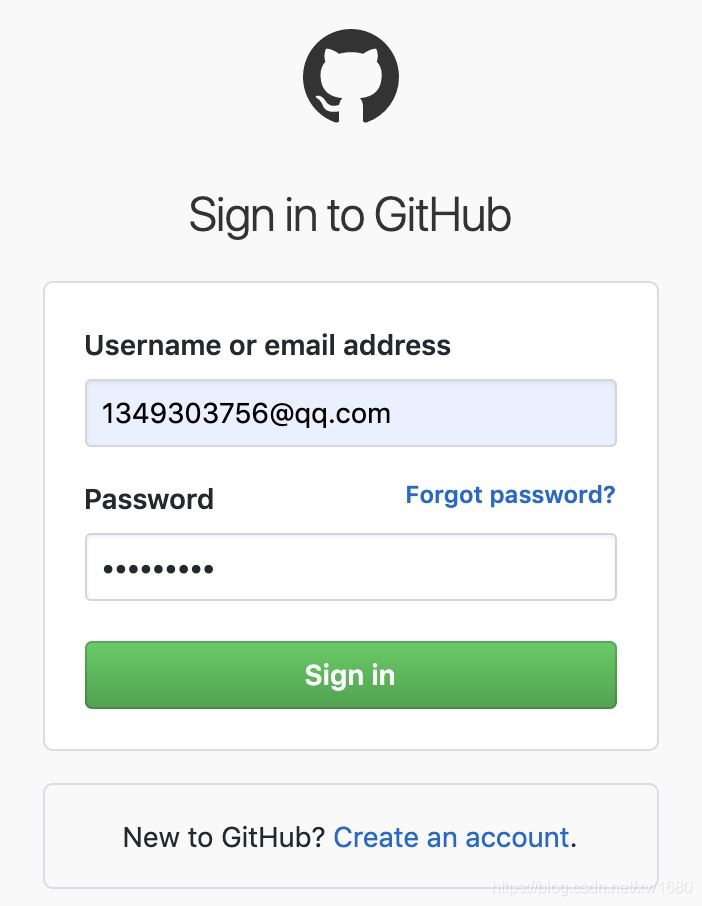
(1) 点击 此处 打开 GitHub 的登录页面,然后输入账号与密码,如下图所示。
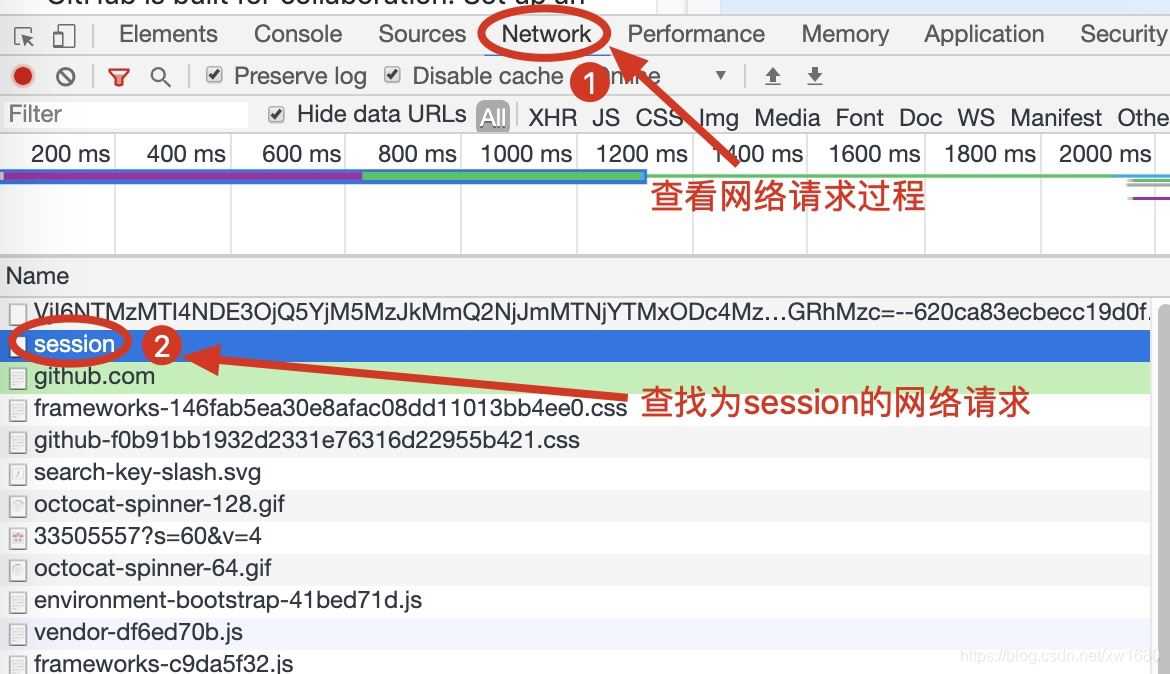
(2) 用 F12 或者 鼠标右键单击网页选择 检查 打开浏览器的开发者工具,选择获取网络请求过程,然后单击登录页面中的 Sign in 按钮,此时开发者工具中将显示 GitHub 网页的登录请求过程,重点查找名称为 session 的网络请求。如下图所示。
(3) 单击名称为 session 的网络请求,然后在 Headers 请求信息中主要查看 Request Headers与 Form Data 中的各种信息,其中红框内为重要参数与数据。如下图所示。
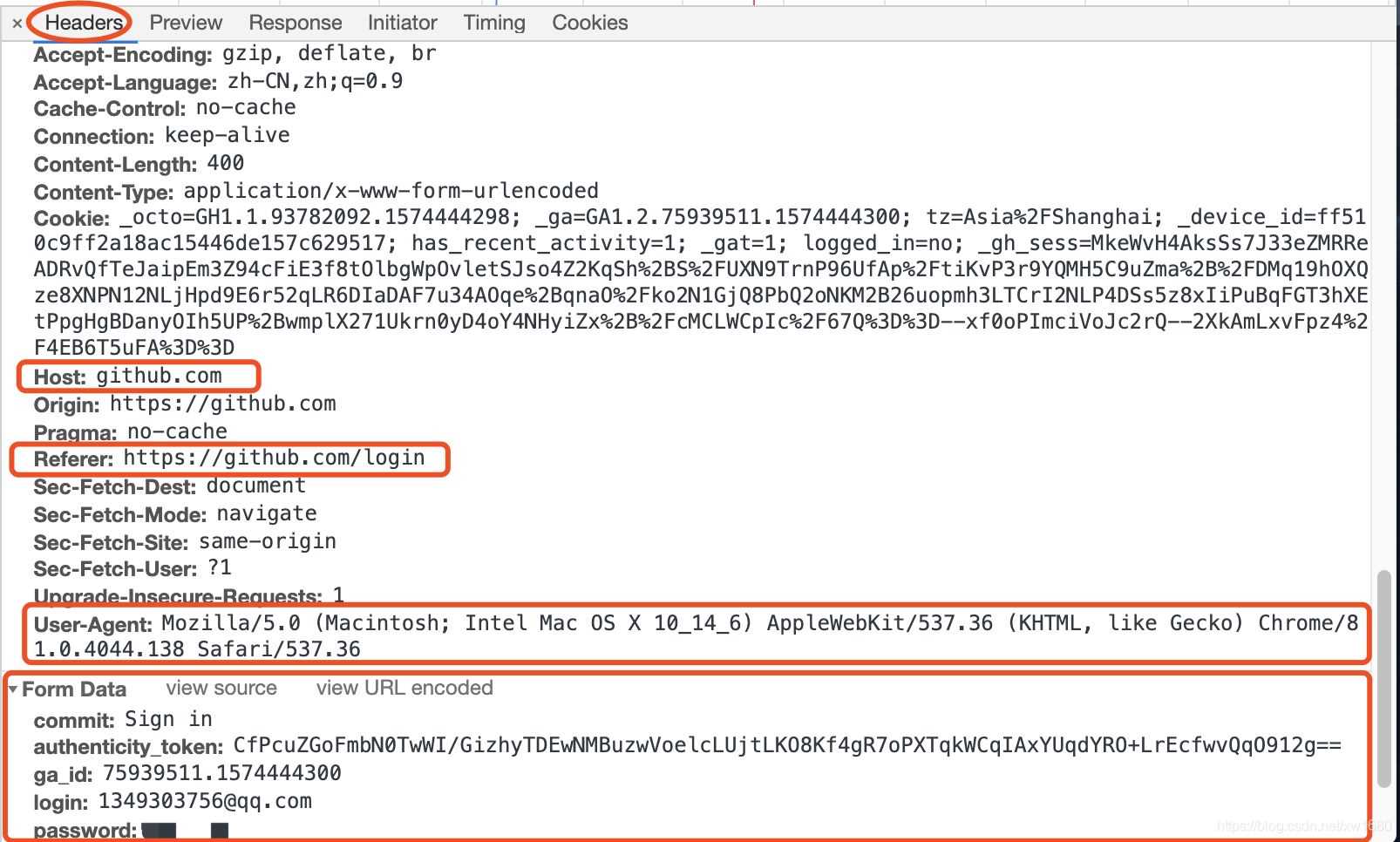
说明:Host 为主页面地址,Referer 为当前请求的来源地址。User-Agent 为浏览器的头部信息。Form Data 中的所有信息都是登录请求的所用参数,其中动态参数为重要参数,authenticity_token 为加密字符串,login 为登录的账号,password 为密码,其它参数为静态参数。由于动态参数只有 authenticity_token、login 以及password ,而用户名与密码只需要将动态字符串填写对应的位置即可,所以接下来需要获取 authenticity_token 参数所对应的加密字符串。
(4) 在浏览器中退出所登录的 GitHub 账号,返回 GitHub 的登录页面,打开浏览器开发者工具,查看网页的 html 代码,然后在代码中搜索 authenticity_token 关键词,标签内 value 所对应的值为 authenticity_token 参数的加密字符串。如下图所示。

(5) 实现爬虫代码,首先导入所需模块,然后创建头部信息,再通过 Session 会话对象发送网络请求获取 authenticity_token 信息,最后通过所有的登陆请求参数实现 GitHub 网页的登陆请求并提取注册号码。具体代码如下:
# -*- coding: utf-8 -*-
# @Time : 2020/5/10 23:25
# @Author : 我就是任性-Amo
# @FileName: 77.通过爬虫实现GitHub网页的模拟登录.py
# @Software: PyCharm
# @Blog :https://blog.csdn.net/xw1680
import requests # 导入网络请求模块
from lxml import etree # 导入数据解析模块 都是第三方模块需要安装
# pip install requests/lxml如果太慢 可以加上镜像服务器 或者在Pycharm中使用图形化界面进行安装
class GitHubLogin(object):
def __init__(self, username, password):
# 构造头部信息
self.headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36",
"Host": "github.com",
"Referer": "https://github.com/login"
}
self.login_url = "https://github.com/login" # 登录页面地址
self.post_url = "https://github.com/session" # 实现登录的请求地址
self.session = requests.Session() # 创建Session会话对象
self.user_name = username # 用户名
self.password = password # 密码
# 获取authenticity_token信息
def get_token(self):
# 发送登录页面的网络请求
response = self.session.get(self.login_url, headers=self.headers)
if response.status_code == 200: # 判断请求是否成功
html = etree.HTML(response.text) # 解析html
# 提取authenticity_token信息
token = html.xpath("//div[@id='login']/form/input[1]/@value")[0]
# print(token) 测试是否能够获取到token
return token # 返回信息
# 实现登录
def login(self):
# 请求参数
post_data = {
"commit": "Sign in",
"authenticity_token": self.get_token(),
"login": self.user_name,
"password": self.password,
"webauthn - support": "supported"
}
# 发送登录请求
response = self.session.post(self.post_url, headers=self.headers, data=post_data)
if response.status_code == 200: # 判断请求是否成功
html = etree.HTML(response.text) # 解析html
# 获取注册号码
register_number = html.xpath("//div[contains(@class,'Header-item')][last()]//strong")[0]
print(f"注册号码为: {register_number.text}")
else:
print("登录失败")
if __name__ == '__main__':
user_name = input("请输入您的用户名:") # 获取输入的用户名
password = input("请输入您的密码:") # 获取输入的密码
login = GitHubLogin(user_name, password) # 创建登录类对象并传递输入的用户名与密码
login.login()
执行以上代码,输入用户名与密码,即可显示获取的注册号码。如下图所示:

到此这篇关于Python 通过爬虫实现GitHub网页的模拟登录的示例代码的文章就介绍到这了,更多相关Python GitHub模拟登录内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python3以GitHub为例来实现模拟登录和爬取的实例讲解
我们先以一个最简单的实例来了解模拟登录后页面的抓取过程,其原理在于模拟登录后 Cookies 的维护. 1. 本节目标 本节将讲解以 GitHub 为例来实现模拟登录的过程,同时爬取登录后才可以访问的页面信息,如好友动态.个人信息等内容. 我们应该都听说过 GitHub,如果在我们在 Github 上关注了某些人,在登录之后就会看到他们最近的动态信息,比如他们最近收藏了哪个 Repository,创建了哪个组织,推送了哪些代码.但是退出登录之后,我们就无法再看到这些信息. 如果希望爬取 GitH
-
Python 通过爬虫实现GitHub网页的模拟登录的示例代码
1. 实例描述 通过爬虫获取网页的信息时,有时需要登录网页后才可以获取网页中的可用数据,例如获取 GitHub 网页中的注册号码时,就需要先登录账号才能在登录后的页面中看到该信息,如下图所示.那么该如何实现模拟登录的功能呢?本文实现将通过爬虫实现 GitHub 网页的模拟登录. 2. 代码实现 在实现 GitHub 网页的模拟登录时,首先需要查看提交登录请求时都要哪些请求参数,然后获取登录请求的所有参数,再发送登录请求.如果登录成功的情况下获取页面中的注册号码信息即可.具体步骤如下: (1) 点
-

Scrapy实现模拟登录的示例代码
为什么要模拟登录 有些网站是需要登录之后才能访问的,即便是同一个网站,在用户登录前后页面所展示的内容也可能会大不相同,例如,未登录时访问Github首页将会是以下的注册页面: 然而,登录后访问Github首页将包含如下页面内容: 如果我们要爬取的是一些需要登录之后才能访问的页面数据就需要模拟登录了.通常我们都是利用的 Cookies 来实现模拟登录,在Scrapy中,模拟登陆网站一般有如下两种实现方式: (1) 请求时携带Cookies (2) 发送P
-
Python实现抓取腾讯视频所有电影的示例代码
目录 运行环境 实现目的与思路 目的 思路 完整代码 视频缓存ts文件 实现效果 运行环境 IDE丨pycharm 版本丨Python3.6 系统丨Windows 实现目的与思路 目的 实现对腾讯视频目标url的解析与下载,由于第三方vip解析,只提供在线观看,隐藏想实现对目标视频的下载 思路 首先拿到想要看的腾讯电影url,通过第三方vip视频解析网站进行解析,通过抓包,模拟浏览器发送正常请求,通过拿到缓存ts文件,下载视频ts文件,最后通过转换为mp4文件,即可实现正常播放 完整代码 imp
-
python实现网站微信登录的示例代码
最近微信登录开放公测,为了方便微信用户使用,我们的产品也决定加上微信登录功能,然后就有了这篇笔记. 根据需求选择相应的登录方式 python实现网站微信登录的示例代码 微信现在提供两种登录接入方式 移动应用微信登录 网站应用微信登录 这里我们使用的是网站应用微信登录 按照 官方流程 1 注册并通过开放平台开发者资质认证 注册微信开放平台帐号后,在帐号中心中填写开发者资质认证申请,并等待认证通过. 2 创建网站应用 通过填写网站应用名称.简介和图标,以及各平台下载地址等资料,创建网站应用 3 接入
-
python按照list中字典的某key去重的示例代码
一.需求说明 当我们写爬虫的时候,经常会遇到json格式的数据,它通常是如下结构: data = [{'name':'小K','score':100}, {'name':'小J','score':98}, {'name':'小Q','score':95}, {'name':'小K','score':100}] 很显然名字为小K的数据重复了,我们需要进行去重.通常对于list的去重,我们可以用set()函数,即: data = list(set(data)) 然而,运行之后你会发现它报错了: li
-
python实现模拟器爬取抖音评论数据的示例代码
目标: 由于之前和朋友聊到抖音评论的爬虫,demo做出来之后一直没整理,最近时间充裕后,在这里做个笔记. 提示:大体思路 通过fiddle + app模拟器进行抖音抓包,使用python进行数据整理 安装需要的工具: python3 下载 fiddle 安装及配置 手机模拟器下载 抖音部分: 模拟器下载好之后, 打开模拟器 在应用市场下载抖音 对抖音进行fiddle配置,配置成功后就可以当手机一样使用了 一.工具配置及抓包: 我们随便打开一个视频之后,fiddle就会刷新新的数据包 在json中
-
python+opencv3.4.0 实现HOG+SVM行人检测的示例代码
参照opencv官网例程写了一个基于python的行人检测程序,实现了和自带检测器基本一致的检测效果. 网址 :https://docs.opencv.org/3.4.0/d5/d77/train_HOG_8cpp-example.html opencv版本:3.4.0 训练集和opencv官方用了同一个,可以从http://pascal.inrialpes.fr/data/human/下载,在网页的最下方"here(970MB处)",用迅雷下载比较快(500kB/s).训练集文件比较
-
python 高效去重复 支持GB级别大文件的示例代码
如下所示: #coding=utf-8 import sys, re, os def getDictList(dict): regx = '''[\w\~`\!\@\#\$\%\^\&\*\(\)\_\-\+\=\[\]\{\}\:\;\,\.\/\<\>\?]+''' with open(dict) as f: data = f.read() return re.findall(regx, data) def rmdp(dictList): return list(set(dictL
-
使用python的pexpect模块,实现远程免密登录的示例
说明 当我们需要用脚本实现,远程登录或者远程操作的时候,都要去解决如何自动输入密码的问题,一般来说有3种实现方式: 1).配置公钥私钥 2).使用shell下的命令,expect 3).使用python的pexpect模块 下面介绍的代码,是使用python的pexpect模块实现的: 代码 import os import sys import pexpect import datetime #获取昨天的日期 date_yes = (datetime.date.today()-datetime
-
Java模拟UDP通信示例代码
Java基础:模拟UDP通信 1.一次发送,一次接收 1.1.发送方 // 发送端,不需要连接服务器 public class UdpClientDemo { public static void main(String[] args) throws Exception { // 1. 发送数据包需要一个Socket DatagramSocket socket = new DatagramSocket(); // 1.2 建立一个包