hadoop中实现java网络爬虫(示例讲解)
这一篇网络爬虫的实现就要联系上大数据了。在前两篇java实现网络爬虫和heritrix实现网络爬虫的基础上,这一次是要完整的做一次数据的收集、数据上传、数据分析、数据结果读取、数据可视化。
需要用到
Cygwin:一个在windows平台上运行的类UNIX模拟环境,直接网上搜索下载,并且安装;
Hadoop:配置Hadoop环境,实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS,用来将收集的数据直接上传保存到HDFS,然后用MapReduce分析;
Eclipse:编写代码,需要导入hadoop的jar包,以可以创建MapReduce项目;
Jsoup:html的解析jar包,结合正则表达式能更好的解析网页源码;
----->
目录:
1、配置Cygwin
2、配置Hadoop黄静
3、Eclipse开发环境搭建
4、网络数据爬取(jsoup)
-------->
1、安装配置Cygwin
从官方网站下载Cygwin 安装文件,地址:https://cygwin.com/install.html
下载运行后进入安装界面。
安装时直接从网络镜像中下载扩展包,至少需要选择ssh和ssl支持包
安装后进入cygwin控制台界面,
运行ssh-host-config命令,安装SSH
输入:no,yes,ntsec,no,no
注意:win7下需要改为yes,yes,ntsec,no,yes,输入密码并确认这个步骤
完成后会在windows操作系统中配置好一个Cygwin sshd服务,启动该服务即可。

然后要配置ssh免密码登陆
重新运行cygwin。
执行ssh localhost,会要求使用密码进行登陆。
使用ssh-keygen命令来生成一个ssh密钥,一直回车结束即可。
生成后进入.ssh目录,使用命令:cp id_rsa.pub authorized_keys 命令来配置密钥。
之后使用exit退出即可。
重新进入系统后,通过ssh localhost就可以直接进入系统,不需要再输入密码了。
2、配置Hadoop环境
修改hadoop-env.sh文件,加入JDK安装目录的JAVA_HOME位置设置。
# The java implementation to use. Required. export JAVA_HOME=/cygdrive/c/Java/jdk1.7.0_67
如图注意:Program Files缩写为PROGRA~1

修改hdfs-site.xml,设置存放副本为1(因为配置的是伪分布式方式)
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>
注意:此图片多加了一个property,内容就是解决可能出现的权限问题!!!
HDFS:Hadoop 分布式文件系统
可以在HDFS中通过命令动态对文件或文件夹进行CRUD
注意有可能出现权限的问题,需要通过在hdfs-site.xml中配置以下内容来避免:
<property> <name>dfs.permissions</name> <value>false</value> </property>

修改mapred-site.xml,设置JobTracker运行的服务器与端口号(由于当前就是运行在本机上,直接写localhost 即可,端口可以绑定任意空闲端口)
<configuration> <property> <name>mapred.job.tracker</name> <value>localhost:9001</value> </property> </configuration>
配置core-site.xml,配置HDFS文件系统所对应的服务器与端口号(同样就在当前主机)
<configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> </configuration>
配置好以上内容后,在Cygwin中进入hadoop目录

在bin目录下,对HDFS文件系统进行格式化(第一次使用前必须格式化),然后输入启动命令:
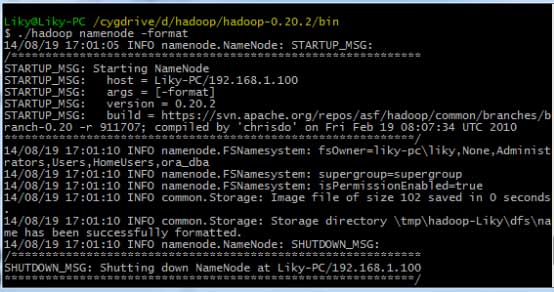
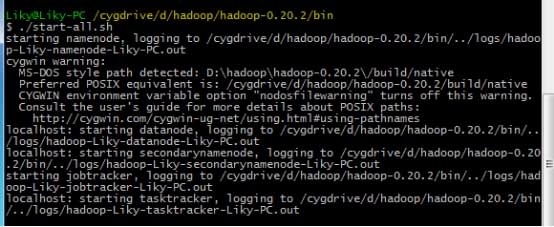
3、Eclipse开发环境搭建
这个在我写的博客 大数据【二】HDFS部署及文件读写(包含eclipse hadoop配置)中给出大致配置方法。不过此时需要完善一下。
将hadoop中的hadoop-eclipse-plugin.jar支持包拷贝到eclipse的plugin目录下,为eclipse添加Hadoop支持。
启动Eclipse后,切换到MapReduce界面。
在windows工具选项选择showviews的others里面查找map/reduce locations。
在Map/Reduce Locations窗口中建立一个Hadoop Location,以便与Hadoop进行关联。


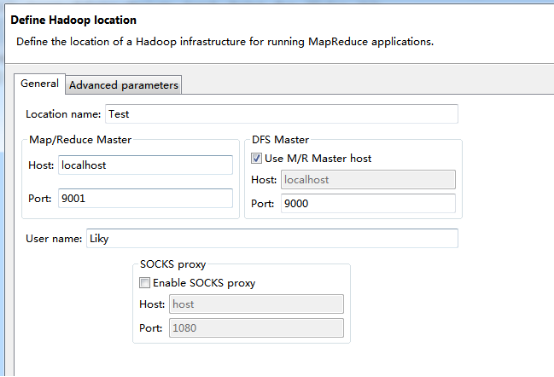
注意:此处的两个端口应为你配置hadoop的时候设置的端口!!!
完成后会建立好一个Hadoop Location
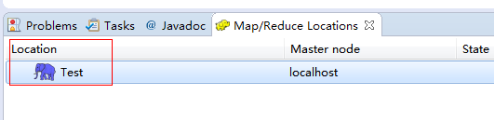
在左侧的DFS Location中,还可以看到HDFS中的各个目录
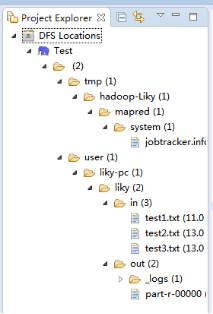
并且你可以在其目录下自由创建文件夹来存取数据。
下面你就可以创建mapreduce项目了,方法同正常创建一样。
4、网络数据爬取
现在我们通过编写一段程序,来将爬取的新闻内容的有效信息保存到HDFS中。
此时就有了两种网络爬虫的方法:
其一就是利用heritrix工具获取的数据;
其一就是java代码结合jsoup编写的网络爬虫。
方法一的信息保存到HDFS:
直接读取生成的本地文件,用jsoup解析html,此时需要将jsoup的jar包导入到项目中。
package org.liky.sina.save;
//这里用到了JSoup开发包,该包可以很简单的提取到HTML中的有效信息
import java.io.File;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class SinaNewsData {
private static Configuration conf = new Configuration();
private static FileSystem fs;
private static Path path;
private static int count = 0;
public static void main(String[] args) {
parseAllFile(new File(
"E:/heritrix-1.12.1/jobs/sina_news_job_02-20170814013255352/mirror/"));
}
public static void parseAllFile(File file) {
// 判断类型
if (file.isDirectory()) {
// 文件夹
File[] allFile = file.listFiles();
if (allFile != null) {
for (File f : allFile) {
parseAllFile(f);
}
}
} else {
// 文件
if (file.getName().endsWith(".html")
|| file.getName().endsWith(".shtml")) {
parseContent(file.getAbsolutePath());
}
}
}
public static void parseContent(String filePath) {
try {
//用jsoup的方法读取文件路径
Document doc = Jsoup.parse(new File(filePath), "utf-8");
//读取标题
String title = doc.title();
Elements descElem = doc.getElementsByAttributeValue("name",
"description");
Element descE = descElem.first();
// 读取内容
String content = descE.attr("content");
if (title != null && content != null) {
//通过Path来保存数据到HDFS中
path = new Path("hdfs://localhost:9000/input/"
+ System.currentTimeMillis() + ".txt");
fs = path.getFileSystem(conf);
// 建立输出流对象
FSDataOutputStream os = fs.create(path);
// 使用os完成输出
os.writeChars(title + "\r\n" + content);
os.close();
count++;
System.out.println("已经完成" + count + " 个!");
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
以上这篇hadoop中实现java网络爬虫(示例讲解)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
深入浅析Java Object Serialization与 Hadoop 序列化
一,Java Object Serialization 1,什么是序列化(Serialization) 序列化是指将结构化对象转化为字节流以便在网络上传输或者写到磁盘永久存储的过程.反序列化指将字节流转回结构化对象的逆过程.简单的理解就是对象转换为字节流用来传输和保存,字节流转换为对象将对象恢复成原来的状态. 2,序列化(Serialization)的作用 (1)一种持久化机制,把的内存中的对象状态保存到一个文件中或者数据库. (2)一种通信机制,用套接字在网络上传送对象. (3)Java远程方
-
Java执行hadoop的基本操作实例代码
Java执行hadoop的基本操作实例代码 向HDFS上传本地文件 public static void uploadInputFile(String localFile) throws IOException{ Configuration conf = new Configuration(); String hdfsPath = "hdfs://localhost:9000/"; String hdfsInput = "hdfs://localhost:9000/user/
-
Java访问Hadoop分布式文件系统HDFS的配置说明
配置文件 m103替换为hdfs服务地址. 要利用Java客户端来存取HDFS上的文件,不得不说的是配置文件hadoop-0.20.2/conf/core-site.xml了,最初我就是在这里吃了大亏,所以我死活连不上HDFS,文件无法创建.读取. <?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <co
-

hadoop上传文件功能实例代码
hdfs上的文件是手动执行命令从本地linux上传至hdfs的.在真实的运行环境中,我们不可能每次手动执行命令上传的,这样太过繁琐.那么,我们可以使用hdfs提供的Java api实现文件上传至hdfs,或者直接从ftp上传至hdfs. 然而,需要说明一点,之前笔者是要运行MR,都需要每次手动执行yarn jar,在实际的环境中也不可能每次手动执行.像我们公司是使用了索答的调度平台/任务监控平台,可以定时的以工作流执行我们的程序,包括普通java程序和MR.其实,这个调度平台就是使用了quart
-
java使用hadoop实现关联商品统计
最近几天一直在看Hadoop相关的书籍,目前稍微有点感觉,自己就仿照着WordCount程序自己编写了一个统计关联商品. 需求描述: 根据超市的销售清单,计算商品之间的关联程度(即统计同时买A商品和B商品的次数). 数据格式: 超市销售清单简化为如下格式:一行表示一个清单,每个商品采用 "," 分割,如下图所示: 需求分析: 采用hadoop中的mapreduce对该需求进行计算. map函数主要拆分出关联的商品,输出结果为 key为商品A,value为商品B,对于第一条三条结果拆分结
-
java结合HADOOP集群文件上传下载
对HDFS上的文件进行上传和下载是对集群的基本操作,在<HADOOP权威指南>一书中,对文件的上传和下载都有代码的实例,但是对如何配置HADOOP客户端却是没有讲得很清楚,经过长时间的搜索和调试,总结了一下,如何配置使用集群的方法,以及自己测试可用的对集群上的文件进行操作的程序.首先,需要配置对应的环境变量: 复制代码 代码如下: hadoop_HOME="/home/work/tools/java/hadoop-client/hadoop" for f in $hadoo
-
hadoop中实现java网络爬虫(示例讲解)
这一篇网络爬虫的实现就要联系上大数据了.在前两篇java实现网络爬虫和heritrix实现网络爬虫的基础上,这一次是要完整的做一次数据的收集.数据上传.数据分析.数据结果读取.数据可视化. 需要用到 Cygwin:一个在windows平台上运行的类UNIX模拟环境,直接网上搜索下载,并且安装: Hadoop:配置Hadoop环境,实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS,用来将收集的数据直接上传保存到HDFS,然后用MapReduce
-
java网络爬虫连接超时解决实例代码
本文研究的主要是java网络爬虫连接超时的问题,具体如下. 在网络爬虫中,经常会遇到如下报错.即连接超时.针对此问题,一般解决思路为:将连接时间.请求时间设置长一下.如果出现连接超时的情况,则在重新请求[设置重新请求次数]. Exception in thread "main" java.net.ConnectException: Connection timed out: connect 下面的代码便是使用httpclient解决连接超时的样例程序.直接上程序. package da
-
java编程实现简单的网络爬虫示例过程
本项目中需要用到两个第三方jar包,分别为 jsoup 和 commons-io. jsoup的作用是为了解析网页, commons-io 是为了把数据保存到本地. 1.爬取贴吧 第一步,打开eclipse,新建一个java项目,名字就叫做 pachong: 然后,新建一个类,作为我们程序的入口. 这个作为入口类,里面就写一个main方法即可. public class StartUp { public static void main(String[] args) { } } 第二步,导入我们
-
Java 网络爬虫新手入门详解
这是 Java 网络爬虫系列文章的第一篇,如果你还不知道 Java 网络爬虫系列文章,请参看Java 网络爬虫基础知识入门解析.第一篇是关于 Java 网络爬虫入门内容,在该篇中我们以采集虎扑列表新闻的新闻标题和详情页为例,需要提取的内容如下图所示: 我们需要提取图中圈出来的文字及其对应的链接,在提取的过程中,我们会使用两种方式来提取,一种是 Jsoup 的方式,另一种是 httpclient + 正则表达式的方式,这也是 Java 网络爬虫常用的两种方式,你不了解这两种方式没关系,后面会有相应
-
Java 网络爬虫基础知识入门解析
前言 说起网络爬虫,大家想起的估计都是 Python ,诚然爬虫已经是 Python 的代名词之一,相比 Java 来说就要逊色不少.有不少人都不知道 Java 可以做网络爬虫,其实 Java 也能做网络爬虫而且还能做的非常好,在开源社区中有不少优秀的 Java 网络爬虫框架,例如 webmagic .我的第一份正式工作就是使用 webmagic 编写数据采集程序,当时参与了一个舆情分析系统的开发,这里面涉及到了大量网站的新闻采集,我们就使用了 webmagic 进行采集程序的编写,由于当时不知
-
对Python中for复合语句的使用示例讲解
当Python中用到双重for循环设计的时候我一般会使用循环的嵌套,但是在Python中其实还存在另一种技巧--for复合语句. 简单写一个小程序,用于延时循环嵌套功能如下: #!/usr/bin/python defFunc1(ten_num,one_num): for i in range(ten_num): for j in range(one_num): print(10 * i + j) Func1(2,5)的执行结果如下: 0 1 2 3 4 10 11 12 13 14 以上是一个
-
Python网络爬虫实例讲解
聊一聊Python与网络爬虫. 1.爬虫的定义 爬虫:自动抓取互联网数据的程序. 2.爬虫的主要框架 爬虫程序的主要框架如上图所示,爬虫调度端通过URL管理器获取待爬取的URL链接,若URL管理器中存在待爬取的URL链接,爬虫调度器调用网页下载器下载相应网页,然后调用网页解析器解析该网页,并将该网页中新的URL添加到URL管理器中,将有价值的数据输出. 3.爬虫的时序图 4.URL管理器 URL管理器管理待抓取的URL集合和已抓取的URL集合,防止重复抓取与循环抓取.URL管理器的主要职能如下图
-
python使用rabbitmq实现网络爬虫示例
编写tasks.py 复制代码 代码如下: from celery import Celeryfrom tornado.httpclient import HTTPClientapp = Celery('tasks')app.config_from_object('celeryconfig')@app.taskdef get_html(url): http_client = HTTPClient() try: response = http_client.fetch(u
-
Hadoop中namenode和secondarynamenode工作机制讲解
1)流程 2)FSImage和Edits nodenode是HDFS的大脑,它维护着整个文件系统的目录树,以及目录树里所有的文件和目录,这些信息以俩种文件存储在文件系统:一种是命名空间镜像(也称为文件系统镜像,File System Image,FSImage),即HDFS元数据的完整快照,每次NameNode启动的时候,默认会加载最新的命名空间镜像,另一种是命令空间镜像的编辑日志(Edit log). FSImage文件其实是文件系统元数据的一个永久性检查点,但并非每一个写操作都会更新这个文件
-
Python网络爬虫中的同步与异步示例详解
一.同步与异步 #同步编程(同一时间只能做一件事,做完了才能做下一件事情) <-a_url-><-b_url-><-c_url-> #异步编程 (可以近似的理解成同一时间有多个事情在做,但有先后) <-a_url-> <-b_url-> <-c_url-> <-d_url-> <-e_url-> <-f_url-> <-g_url-> <-h_url-> <--i_ur