Python confluent kafka客户端配置kerberos认证流程详解
kafka的认证方式一般有如下3种:
1.SASL/GSSAPI 从版本0.9.0.0开始支持
2.SASL/PLAIN 从版本0.10.0.0开始支持
3.SASL/SCRAM-SHA-256 以及 SASL/SCRAM-SHA-512 从版本0.10.2.0开始支持
其中第一种SASL/GSSAPI的认证就是kerberos认证,对于java来说有原生的支持,但是对于python来说配置稍微麻烦一些,下面说一下具体的配置过程,confluent kafka模块底层依赖于librdkafka,这是使用c编写的高性能的kafka客户端库,有好多语言的库都是依赖于这个,所以GSSAPI接口的开启也需要在librdkafka编译的时候支持
librdkafka源码:https://github.com/edenhill/librdkafka
编译之前需要先安装必要的开发包,否则相关的接口编译不进去
首先是openssl库,使用yum安装为:yum -y install openssl openssl-devel,编译openssl只能支持默认的PLAIN还有SCRAM这两种机制,无法支持GSSAPI的机制,还需要编译libsasl2依赖,yum安装命令如下:
yum install cyrus-sasl-gssapi cyrus-sasl-devel
在ubuntu下使用命令:apt-get install libsasl2-modules-gssapi-mit libsasl2-dev安装libsasl2开发包
然后确认一下是否有zlib库,这个是方便对kafka消息压缩使用的,一般都会存在,安装命令:yum install zlib-devel,如果需要更高的性能可以手动编译安装zstd并且启用压缩,这里不再详细叙述
上面的库都安装成功就可以开始编译librdkafka源码了,这里源码包为:librdkafka-1.2.1.tar.gz,安装命令如下:
# 解压包 tar -xvzf librdkafka-1.2.1.tar.gz cd librdkafka-1.2.1 # 编译源码 ./configure make make install
上面注意一下在执行命令./configure之后,根据输出确认libssl以及libsasl2是否被开启,如下:
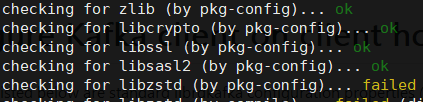
这里libssl以及libsasl2都显示ok说明是可以的,现在SSL和SASL SCRAM以及SASL GSSAPI都已经支持了,执行configure阶段没指定prefix则默认安装位置为/usr/local,动态库位置就为:/usr/local/lib,需要将这个目录添加到动态库连接列表中,比如加到/etc/ld.so.conf,保存后执行ldconfig生效
最后可以编译和安装python的confluent kafka模块,这里安装的版本是1.2.0,安装之后可以运行下面的代码测试:
#!/usr/bin/env python3
# coding=utf-8
from confluent_kafka import Producer
def delivery_report(err, msg):
""" Called once for each message produced to indicate delivery result.
Triggered by poll() or flush(). """
if err is not None:
print('Message delivery failed: {}'.format(err))
else:
print('Message delivered to {} [{}]'.format(msg.topic(), msg.partition()))
if __name__ == '__main__':
producer_conf = {
"bootstrap.servers": '192.168.0.3:9092,192.168.0.4:9092,192.168.0.5:9092',
"security.protocol": 'sasl_plaintext',
'sasl.kerberos.service.name': 'kafka',
'sasl.kerberos.keytab': '/opt/user.keytab',
'sasl.kerberos.principal': 'kafkauser',
}
p = Producer(producer_conf)
p.poll(0)
p.produce('testTopic', 'confluent kafka test'.encode('utf-8'),
callback=delivery_report)
p.flush()
print('done')
如果生产消息正常就配置成功了,使用GSSAPI只需要配置security.protocol以及keytab的路径即可,其他的认证参数比如用户名和密码在不同的认证机制下配置,更多的配置参数参考文档:
https://github.com/edenhill/librdkafka/blob/master/CONFIGURATION.md
librdkafka SASL认证的详细配置流程参考:https://github.com/edenhill/librdkafka/wiki/Using-SASL-with-librdkafka
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
python3实现从kafka获取数据,并解析为json格式,写入到mysql中
项目需求:将kafka解析来的日志获取到数据库的变更记录,按照订单的级别和订单明细级别写入数据库,一条订单的所有信息包括各种维度信息均保存在一条json中,写入mysql5.7中. 配置信息: [Global] kafka_server=xxxxxxxxxxx:9092 kafka_topic=mes consumer_group=test100 passwd = tracking port = 3306 host = xxxxxxxxxx user = track schema = track
-
深入了解如何基于Python读写Kafka
这篇文章主要介绍了深入了解如何基于Python读写Kafka,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 本篇会给出如何使用python来读写kafka, 包含生产者和消费者. 以下使用kafka-python客户端 生产者 爬虫大多时候作为消息的发送端, 在消息发出去后最好能记录消息被发送到了哪个分区, offset是多少, 这些记录在很多情况下可以帮助快速定位问题, 所以需要在send方法后加入callback函数, 包括成功和失败的处理
-
kafka-python 获取topic lag值方式
说真,这个问题看上去很简单,但"得益"与kafka-python神奇的文档,真的不算简单,反正我是搜了半天还看了半天源码. 直接上代码吧 from kafka import SimpleClient, KafkaConsumer from kafka.common import OffsetRequestPayload, TopicPartition def get_topic_offset(brokers, topic): """ 获取一个topic的o
-
在python环境下运用kafka对数据进行实时传输的方法
背景: 为了满足各个平台间数据的传输,以及能确保历史性和实时性.先选用kafka作为不同平台数据传输的中转站,来满足我们对跨平台数据发送与接收的需要. kafka简介: Kafka is a distributed,partitioned,replicated commit logservice.它提供了类似于JMS的特性,但是在设计实现上完全不同,此外它并不是JMS规范的实现.kafka对消息保存时根据Topic进行归类,发送消息者成为Producer,消息接受者成为Consumer,此外ka
-
python操作kafka实践的示例代码
1.先看最简单的场景,生产者生产消息,消费者接收消息,下面是生产者的简单代码. #!/usr/bin/env python # -*- coding: utf-8 -*- import json from kafka import KafkaProducer producer = KafkaProducer(bootstrap_servers='xxxx:x') msg_dict = { "sleep_time": 10, "db_config": { "
-
python读取Kafka实例
1. 新建.py文件 # pip install kafka-python from kafka import KafkaConsumer import setting conf = setting.luyang_kafka_setting consumer = KafkaConsumer(bootstrap_servers=conf['host'], group_id=conf['groupid']) print('consumer start to consuming...') consum
-
python每5分钟从kafka中提取数据的例子
我就废话不多说了,直接上代码吧! import sys sys.path.append("..") from datetime import datetime from utils.kafka2file import KafkaDownloader import os """ 实现取kafka数据,文件按照取数据的间隔命名 如每5分钟从kafka取数据写入文件中,文件名为当前时间加5 """ TOPIC = "rtz
-
python消费kafka数据批量插入到es的方法
1.es的批量插入 这是为了方便后期配置的更改,把配置信息放在logging.conf中 用elasticsearch来实现批量操作,先安装依赖包,sudo pip install Elasticsearch2 from elasticsearch import Elasticsearch class ImportEsData: logging.config.fileConfig("logging.conf") logger = logging.getLogger("msg&
-
Python confluent kafka客户端配置kerberos认证流程详解
kafka的认证方式一般有如下3种: 1.SASL/GSSAPI 从版本0.9.0.0开始支持 2.SASL/PLAIN 从版本0.10.0.0开始支持 3.SASL/SCRAM-SHA-256 以及 SASL/SCRAM-SHA-512 从版本0.10.2.0开始支持 其中第一种SASL/GSSAPI的认证就是kerberos认证,对于java来说有原生的支持,但是对于python来说配置稍微麻烦一些,下面说一下具体的配置过程,confluent kafka模块底层依赖于librdkafka,
-

在IDEA中maven配置MyBatis的流程详解
一.MyBatis简介 1)MyBatis 是一款优秀的持久层框架 2)MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集的过程 3)MyBatis 可以使用简单的 XML 或注解来配置和映射原生信息,将接口和 Java 的 实体类 [Plain Old Java Objects,普通的 Java对象]映射成数据库中的记录. 如果想了解maven请转到我的上一篇文章中: 二.MyBatis获取 1)在这个网址下获取MyBatis:https://mvnrepositor
-
Springboot整合JPA配置多数据源流程详解
目录 1. Maven 2. 基本配置 DataSource 3. 多数据源配置 3.1 JpaConfigOracle 3.2 JpaConfigMysql 4. Dao层接口 1. Maven <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency>
-
SpringSecurity认证流程详解
SpringSecurity基本原理 在之前的文章<SpringBoot + Spring Security 基本使用及个性化登录配置>中对SpringSecurity进行了简单的使用介绍,基本上都是对于接口的介绍以及功能的实现. 这一篇文章尝试从源码的角度来上对用户认证流程做一个简单的分析. 在具体分析之前,我们可以先看看SpringSecurity的大概原理: SpringSecurity基本原理 其实比较简单,主要是通过一系列的Filter对请求进行拦截处理. 认证处理流程说明 我们直接
-
Python使用smtplib模块发送电子邮件的流程详解
1.登录SMTP服务器 首先使用网上的方法(这里使用163邮箱,smtp.163.com是smtp服务器地址,25为端口号): import smtplib server = smtplib.SMTP('smtp.163.com', 25) server.login('j_hao104@163.com', 'password') Traceback (most recent call last): File "C:/python/t.py", line 192, in <modu
-
Spring security自定义用户认证流程详解
1.自定义登录页面 (1)首先在static目录下面创建login.html 注意:springboot项目默认可以访问resources/resources,resources/staic,resources/public目录下面的静态文件 <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>登录页面</titl
-
python Socket之客户端和服务端握手详解
简单的学习下利用socket来建立客户端和服务端之间的连接并且发送数据 1. 客户端socketClient.py代码 import socket s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # 建立连接: s.connect(('127.0.0.1', 9999)) # 接收欢迎消息: print(s.recv(1024).decode('utf-8')) for data in [b'Michael', b'Tracy', b'
-
Python threading模块condition原理及运行流程详解
Condition的处理流程如下: 首先acquire一个条件变量,然后判断一些条件. 如果条件不满足则wait: 如果条件满足,进行一些处理改变条件后,通过notify方法通知其他线程,其他处于wait状态的线程接到通知后会重新判断条件. 不断的重复这一过程,从而解决复杂的同步问题. Condition的基本原理如下: 可以认为Condition对象维护了一个锁(Lock/RLock)和一个waiting池.线程通过acquire获得Condition对象,当调用wait方法时,线程会释放Co
-
Python实现发送与接收邮件的方法详解
本文实例讲述了Python实现发送与接收邮件的方法.分享给大家供大家参考,具体如下: 一.发送邮件 这里实现给网易邮箱发送邮件功能: import smtplib import tkinter class Window: def __init__(self,root): label1 = tkinter.Label(root,text='SMTP') label2 = tkinter.Label(root,text='Port') label3 = tkinter.Label(root,text
-
Redis Sentinel服务配置流程(详解)
1.Redis Sentinel服务配置 1.1简介 Redis 的 Sentinel 系统用于管理多个 Redis 服务器(instance), 该系统执行以下三个任务: 监控(Monitoring): Sentinel 会不断地检查你的主服务器和从服务器是否运作正常. 提醒(Notification): 当被监控的某个 Redis 服务器出现问题时, Sentinel 可以通过API 向管理员或者其他应用程序发送通知. 自动故障迁移(Automatic failover): 当一个主服务器不