Java中的zookeeper常用命令详解
目录
- 1.zkCli.sh客户端
- 2.多节点类型创建
- 3.查询节点
- 4.set数据
- 5.删除节点
- 6.权限设置
- 7.其他命令
注意我这里用的是官方最稳定的版本3.7.1,版本之间有个别命令是有差距的!
1.zkCli.sh客户端
zkCli.sh可以理解成客户端,也可以理解成命令行工具,把命令交给他,让他和zk的服务端打交道。
类似于mysql,我们安装完mysql想要执行命令,那么就必须要通过mysql -u账号 -p密码进入命令行工具里面,才能执行sql。
在zookeeper/bin 目录下:

执行./zkCli.sh就进入到了客户端
ls /:查询当前目录下的节点create /test1:创建test1节点
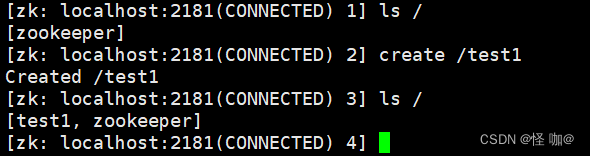
客户端关闭:
输入quit 或者按 Ctrl + C
2.多节点类型创建
- 创建持久节点:
create /test2 - 创建持久序号节点:
create -s /test2 - 创建临时节点:
create -e /test2 - 创建临时序号节点:
create -e -s /test2 - 创建容器节点:
create -c /test2
创建test3临时节点,并向节点赋值数据1(其他节点创建的时候赋值同样如此,在后面跟上数据即可):create -e /test3 1
3.查询节点
- 查询子节点:
- 查询当前节点的子节点:
ls / - 就是获取test2下的子节点:
ls /test2 - 普通节点下的数据:
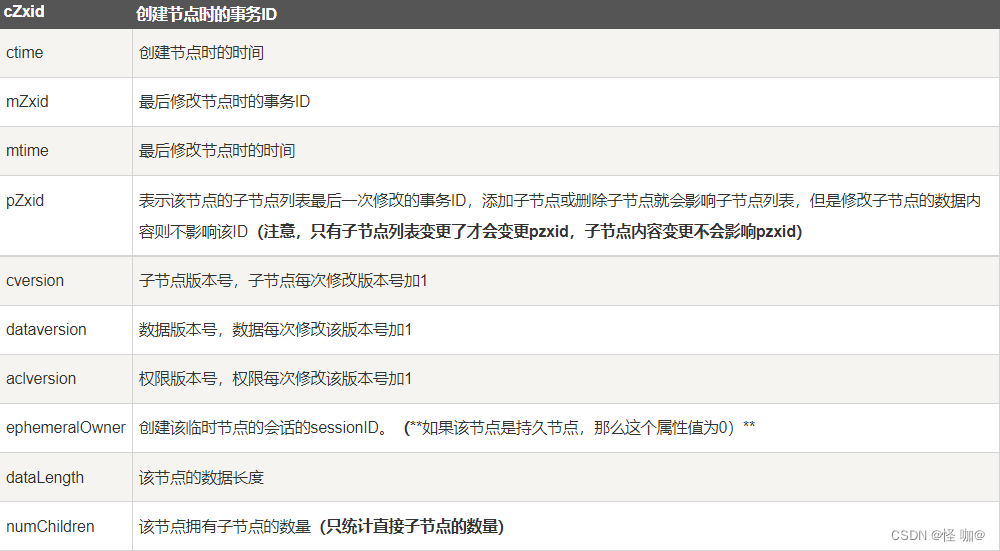
get /test2 - 查询节点详细信息:
get -s /test2||start /test2||ls -s /test2(这三种都可以的)
4.set数据
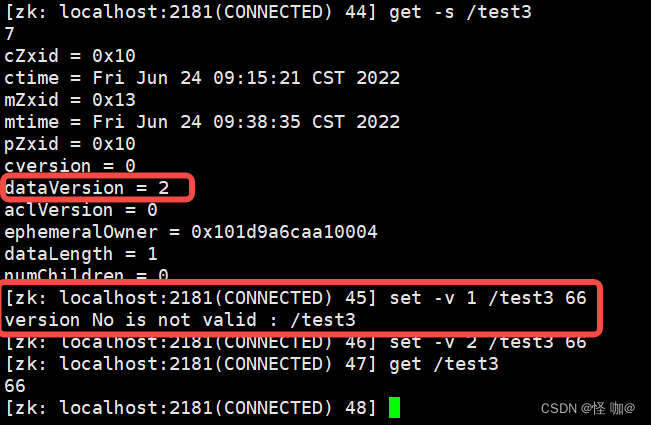
set [-s] [-v version] path data
- path:节点路径。
- data:需要存储的数据。
- [-v version]:可选项,版本号(可用作乐观锁)。
- [-s]:set后返回详情,不添加-s就是返回的set的数据
版本不对就set不成功!
5.删除节点
- 普通删除
- 删除a下的b节点:
delete /a/b - 删除a节点:
delete /a - 不管有没有子节点都删除:
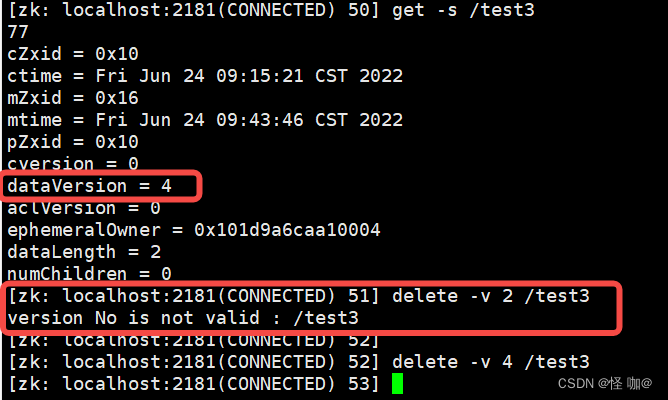
deleteall /test1 - 乐观锁删除(1就是get -s查询出来的dataVersion版本,版本不对删除就失败):
delete -v 1 /test2
6.权限设置
acl:权限,定义了什么样的⽤户能够操作这个节点,且能够进⾏怎样的操作。
- c: create 创建权限,允许在该节点下创建⼦节点
- w:write 更新权限,允许更新该节点的数据
- r:read 读取权限,允许读取该节点的内容以及⼦节点的列表信息
- d:delete 删除权限,允许删除该节点的⼦节点
- a:admin 管理者权限,允许对该节点进⾏acl权限设置
常用命令:
- 获取某个节点的 acl 权限信息:
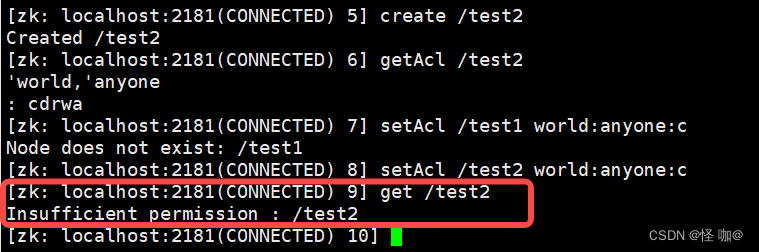
getAcl /test2 - 设置某个节点的 acl 权限信息:
- 指定该节点只有c的权限:
setAcl /test2 world:anyone:c - 指定某个ip具有什么权限:
setAcl /runoob/ip ip:192.168.3.7:cdrwa
注册当前会话的账号和密码:
addauth digest xiaowang:123456
创建一个节点赋值abcd数据,然后必须使用xiaoming账号密码才能进行读写权限,这时候使用别的会话是访问不了这个节点的。
create /test-node abcd auth:xiaowang:123456:cdwra
在另⼀个会话中必须先使⽤账号密码,才能拥有操作该节点的权限

7.其他命令
当命令输入错误的时候会出现命令帮助文档的!
查看当前会话的历史命令:history
到此这篇关于Java中的zookeeper常用命令详解的文章就介绍到这了,更多相关zookeeper常用命令内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

详解Zookeeper基础知识
目录 1. 简介 2. 数据模型 2.1 模型结构 2.2 模型的特点 2.3 节点分类 2.3.1 Persistent 2.3.2 Persistent Sequential 2.3.3 Ephemeral 2.3.4 Ephemeral Sequential 3. 安装 3.1 官方 3.2 docker 3.3 docker-compose 3.4 配置信息 4. 基础命令 4.1 创建会话 4.2 ls 4.3 create 4.4 get 4.5 stat 4.6 set 4.7 d
-
java Zookeeper简述
目录 Zookeeper 角色 Leader Follower Observer Zookeeper 工作原理(原子广播) Znode 四种形式的目录节点 ZooKeeper 安装和使用 常用命令 总结 Zookeeper 是一个分布式协调服务,可用于服务发现,分布式锁,分布式领导选举,配置管理等.Zookeeper 提供了一个类似于 Linux 文件系统的树形结构(可认为是轻量级的内存文件系统,但只适合存少量信息,完全不适合存储大量文件或者大文件),同时提供了对于每个节点的监控通知机制. Zo
-
zookeeper集群搭建超详细过程
目录 一.准备三台虚拟机,并列出对应的IP地址和主机名,如下图所示 二.环境准备(下面的步骤每一台虚拟机都需要做!!) 1.关闭防火墙 2. 配置操作系统 3. 设置本机IP地址与MAC地址 三.安装与配置zookeeper 四.zookeeper集群测试 一.准备三台虚拟机,并列出对应的IP地址和主机名,如下图所示 IP Hostname 192.168.154.133 zookeeper1 192.168.154.134 zookeeper2 192.168.154.135 zookeepe
-
分析ZooKeeper分布式锁的实现
目录 一.分布式锁方案比较 二.ZooKeeper实现分布式锁 2.1.方案一 2.2.方案二 一.分布式锁方案比较 方案 实现思路 优点 缺点 利用 MySQL 的实现方案 利用数据库自身提供的锁机制实现,要求数据库支持行级锁 实现简单 性能差,无法适应高并发场景:容易出现死锁的情况:无法优雅的实现阻塞式锁 利用 Redis 的实现方案 使用 Setnx 和 lua 脚本机制实现,保证对缓存操作序列的原子性 性能好 实现相对复杂,有可能出现死锁:无法优雅的实现阻塞式锁 利用 ZooKeeper
-
centos7下搭建ZooKeeper3.4中间件常用命令小结
一.下载解压 1.Zookeeper简介 Zookeeper 作为一个分布式的服务框架,主要用来解决分布式集群中应用系统的一致性问题,它能提供基于类似于文件系统的目录节点树方式的数据存储,但是 Zookeeper 并不是用来专门存储数据的,它的作用主要是用来维护和监控你存储的数据的状态变化.通过监控这些数据状态的变化,从而可以达到基于数据的集群管理. 2.下载 环境版本 centos7 zookeeper 3.4.14 [root@localhost mysoft]$ cd /usr/local
-
Java之Zookeeper注册中心原理剖析
RPC框架中有3个重要的角色: 注册中心 :保存所有服务的名字,服务提供者的IP列表,服务消费者的IP列表 服务提供者: 提供跨进程服务 服务消费者: 寻找到指定命名的服务并消费. Zookeeper用作注册中心 简单来讲,zookeeper可以充当一个服务注册表(Service Registry),让多个服务提供者形成一个集群,让服务消费者通过服务注册表获取具体的服务访问地址(IP+端口)去访问具体的服务提供者.如下图所示: 具体来说,zookeeper就是个分布式文件系统,每当一个服务提供者
-
Java中的zookeeper常用命令详解
目录 1.zkCli.sh客户端 2.多节点类型创建 3.查询节点 4.set数据 5.删除节点 6.权限设置 7.其他命令 注意我这里用的是官方最稳定的版本3.7.1,版本之间有个别命令是有差距的! 1.zkCli.sh客户端 zkCli.sh可以理解成客户端,也可以理解成命令行工具,把命令交给他,让他和zk的服务端打交道.类似于mysql,我们安装完mysql想要执行命令,那么就必须要通过mysql -u账号 -p密码进入命令行工具里面,才能执行sql. 在zookeeper/bin 目录下
-
Nodejs中 npm常用命令详解
npm是什么 NPM的全称是Node Package Manager,是随同NodeJS一起安装的包管理和分发工具,它很方便让JavaScript开发者下载.安装.上传以及管理已经安装的包. npm是一个node包管理和分发工具,已经成为了非官方的发布node模块(包)的标准.有了npm,可以很快的找到特定服务要使用的包,进行下载.安装以及管理已经安装的包. 1.npm install moduleNames:安装Node模块 安装完毕后会产生一个node_modules目录,其目录下就是安装的
-
hbase shell基础和常用命令详解
HBase是Google Bigtable的开源实现,它利用Hadoop HDFS作为其文件存储系统,利用Hadoop MapReduce来处理HBase中的海量数据,利用Zookeeper作为协同服务. 1. 简介 HBase是一个分布式的.面向列的开源数据库,源于google的一篇论文<bigtable:一个结构化数据的分布式存储系统>.HBase是Google Bigtable的开源实现,它利用Hadoop HDFS作为其文件存储系统,利用Hadoop MapReduce来处理HBase
-
java 中enum的使用方法详解
java 中enum的使用方法详解 enum 的全称为 enumeration, 是 JDK 1.5 中引入的新特性,存放在 java.lang 包中. 下面是我在使用 enum 过程中的一些经验和总结. 原始的接口定义常量 public interface IConstants { String MON = "Mon"; String TUE = "Tue"; String WED = "Wed"; String THU = "Thu
-
Maven 配置文件 生命周期 常用命令详解
当前,JVM生态圈主要的三大构建工具: Apache Ant(带着Ivy) Maven Gradle 对于初学者,Ant是最清晰的,只要读懂Xml配置文件你就能够理解它干了什么,但是ant文件很容易变的更加复杂.Maven有自己的工程目录规则和内置的构建生成周期,从而使构建文件更加简单.gradle有很多开箱即用的插件,语法更加短小精悍,易于理解. 在讲解maven之前这里我们先简单比较下Maven和Ant.下面是一个简单的Ant例子.这个例子可以看出我们需要明确的告诉Ant.我们想让他做什么.
-
Java中正则表达式的使用和详解(下)
在上篇给大家介绍了Java中正则表达式的使用和详解(上),具体内容如下所示: 1.常用正则表达式 规则 正则表达式语法 一个或多个汉字 ^[\u0391-\uFFE5]+$ 邮政编码 ^[1-9]\d{5}$ QQ号码 ^[1-9]\d{4,10}$ 邮箱 ^[a-zA-Z_]{1,}[0-9]{0,}@(([a-zA-z0-9]-*){1,}\.){1,3}[a-zA-z\-]{1,}$ 用户名(字母开头 + 数字/字母/下划线) ^[A-Za-z][A-Za-z1-9_-]+$ 手
-
django之常用命令详解
Django 基本命令 本节主要是为了让您了解一些django最基本的命令,请尝试着记住它们,并且多多练习下 1. 新建一个 django project django-admin.py startproject project-name 一个 project 为一个项目,project-name 项目名称,改成你自己的,要符合Python 的变量命名规则(以下划线或字母开头) 2. 新建 app python manage.py startapp app-name 或 django-admin
-
Java中Math类常用方法代码详解
近期用到四舍五入想到以前整理了一点,就顺便重新整理好经常见到的一些四舍五入,后续遇到常用也会直接在这篇文章更新... public class Demo{ public static void main(String args[]){ /** *Math.sqrt()//计算平方根 *Math.cbrt()//计算立方根 *Math.pow(a, b)//计算a的b次方 *Math.max( , );//计算最大值 *Math.min( , );//计算最小值 */ System.out.pri
-
Java中Servlet的生命周期详解
目录 Web基础和HTTP协议 什么是Servlet Servlet的生命周期 Web基础和HTTP协议 ┌─────────┐ ┌─────────┐ │░░░░░░░░░│ │O ░░░░░░░│ ├─────────┤ ├─────────┤ │░░░░░░░░░│ │ │ ├─────────┤ │ │ │░░░░░░░░░│ └─────────┘ └─────────┘ │ request 1 │ │─────────────────────>│ │ request 2 │ │───
-
Java中String类常用方法总结详解
目录 一. String对象的比较 1. ==比较是否引用同一个对象 2. boolean equals(Object anObject) 3. int compareTo(String s) 4. int compareToIgnoreCase(String str) 二. 字符串查找 三. 转化 1. 数值和字符串转化 2. 大小写转化 3. 字符串和数组的转换 4. 格式化 四. 字符串替换 五. 字符串拆分 六. 字符串截取 七. 其他操作方法 1. String trim() 2. b