Spark SQL 2.4.8 操作 Dataframe的两种方式
目录
- 一、测试数据
- 二、创建DataFrame
- 方式一:DSL方式操作
- 方式二:SQL方式操作
一、测试数据
7369,SMITH,CLERK,7902,1980/12/17,800,20
7499,ALLEN,SALESMAN,7698,1981/2/20,1600,300,30
7521,WARD,SALESMAN,7698,1981/2/22,1250,500,30
7566,JONES,MANAGER,7839,1981/4/2,2975,20
7654,MARTIN,SALESMAN,7698,1981/9/28,1250,1400,30
7698,BLAKE,MANAGER,7839,1981/5/1,2850,30
7782,CLARK,MANAGER,7839,1981/6/9,2450,10
7788,SCOTT,ANALYST,7566,1987/4/19,3000,20
7839,KING,PRESIDENT,1981/11/17,5000,10
7844,TURNER,SALESMAN,7698,1981/9/8,1500,0,30
7876,ADAMS,CLERK,7788,1987/5/23,1100,20
7900,JAMES,CLERK,7698,1981/12/3,9500,30
7902,FORD,ANALYST,7566,1981/12/3,3000,20
7934,MILLER,CLERK,7782,1982/1/23,1300,10
二、创建DataFrame
方式一:DSL方式操作
- 实例化SparkContext和SparkSession对象
- 利用StructType类型构建schema,用于定义数据的结构信息
- 通过SparkContext对象读取文件,生成RDD
- 将RDD[String]转换成RDD[Row]
- 通过SparkSession对象创建dataframe
- 完整代码如下:
package com.scala.demo.sql
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.sql.types.{DataType, DataTypes, StructField, StructType}
object Demo01 {
def main(args: Array[String]): Unit = {
// 1.创建SparkContext和SparkSession对象
val sc = new SparkContext(new SparkConf().setAppName("Demo01").setMaster("local[2]"))
val sparkSession = SparkSession.builder().getOrCreate()
// 2. 使用StructType来定义Schema
val mySchema = StructType(List(
StructField("empno", DataTypes.IntegerType, false),
StructField("ename", DataTypes.StringType, false),
StructField("job", DataTypes.StringType, false),
StructField("mgr", DataTypes.StringType, false),
StructField("hiredate", DataTypes.StringType, false),
StructField("sal", DataTypes.IntegerType, false),
StructField("comm", DataTypes.StringType, false),
StructField("deptno", DataTypes.IntegerType, false)
))
// 3. 读取数据
val empRDD = sc.textFile("file:///D:\\TestDatas\\emp.csv")
// 4. 将其映射成ROW对象
val rowRDD = empRDD.map(line => {
val strings = line.split(",")
Row(strings(0).toInt, strings(1), strings(2), strings(3), strings(4), strings(5).toInt,strings(6), strings(7).toInt)
})
// 5. 创建DataFrame
val dataFrame = sparkSession.createDataFrame(rowRDD, mySchema)
// 6. 展示内容 DSL
dataFrame.groupBy("deptno").sum("sal").as("result").sort("sum(sal)").show()
}
}
结果如下:

方式二:SQL方式操作
- 实例化SparkContext和SparkSession对象
- 创建case class Emp样例类,用于定义数据的结构信息
- 通过SparkContext对象读取文件,生成RDD[String]
- 将RDD[String]转换成RDD[Emp]
- 引入spark隐式转换函数(必须引入)
- 将RDD[Emp]转换成DataFrame
- 将DataFrame注册成一张视图或者临时表
- 通过调用SparkSession对象的sql函数,编写sql语句
- 停止资源
- 具体代码如下:
package com.scala.demo.sql
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.types.{DataType, DataTypes, StructField, StructType}
// 0. 数据分析
// 7499,ALLEN,SALESMAN,7698,1981/2/20,1600,300,30
// 1. 定义Emp样例类
case class Emp(empNo:Int,empName:String,job:String,mgr:String,hiredate:String,sal:Int,comm:String,deptNo:Int)
object Demo02 {
def main(args: Array[String]): Unit = {
// 2. 读取数据将其映射成Row对象
val sc = new SparkContext(new SparkConf().setMaster("local[2]").setAppName("Demo02"))
val mapRdd = sc.textFile("file:///D:\\TestDatas\\emp.csv")
.map(_.split(","))
val rowRDD:RDD[Emp] = mapRdd.map(line => Emp(line(0).toInt, line(1), line(2), line(3), line(4), line(5).toInt, line(6), line(7).toInt))
// 3。创建dataframe
val spark = SparkSession.builder().getOrCreate()
// 引入spark隐式转换函数
import spark.implicits._
// 将RDD转成Dataframe
val dataFrame = rowRDD.toDF
// 4.2 sql语句操作
// 1、将dataframe注册成一张临时表
dataFrame.createOrReplaceTempView("emp")
// 2. 编写sql语句进行操作
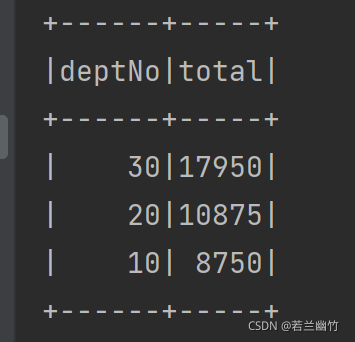
spark.sql("select deptNo,sum(sal) as total from emp group by deptNo order by total desc").show()
// 关闭资源
spark.stop()
sc.stop()
}
}
结果如下:
到此这篇关于Spark SQL 2.4.8 操作 Dataframe的两种方式的文章就介绍到这了,更多相关Spark SQL 操作 Dataframe内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
spark rdd转dataframe 写入mysql的实例讲解
dataframe是在spark1.3.0中推出的新的api,这让spark具备了处理大规模结构化数据的能力,在比原有的RDD转化方式易用的前提下,据说计算性能更还快了两倍.spark在离线批处理或者实时计算中都可以将rdd转成dataframe进而通过简单的sql命令对数据进行操作,对于熟悉sql的人来说在转换和过滤过程很方便,甚至可以有更高层次的应用,比如在实时这一块,传入kafka的topic名称和sql语句,后台读取自己配置好的内容字段反射成一个class并利用出入的sql对实时数据进行
-
pyspark.sql.DataFrame与pandas.DataFrame之间的相互转换实例
代码如下,步骤流程在代码注释中可见: # -*- coding: utf-8 -*- import pandas as pd from pyspark.sql import SparkSession from pyspark.sql import SQLContext from pyspark import SparkContext #初始化数据 #初始化pandas DataFrame df = pd.DataFrame([[1, 2, 3], [4, 5, 6]], index=['row1
-
DataFrame:通过SparkSql将scala类转为DataFrame的方法
如下所示: import java.text.DecimalFormat import com.alibaba.fastjson.JSON import com.donews.data.AppConfig import com.typesafe.config.ConfigFactory import org.apache.spark.sql.types.{StructField, StructType} import org.apache.spark.sql.{Row, SaveMode, Da
-
SparkSQL使用IDEA快速入门DataFrame与DataSet的完美教程
目录 1.使用IDEA开发Spark SQL 1.1创建DataFrame/DataSet 1.1.1指定列名添加Schema 1.1.2StructType指定Schema 1.1.3反射推断Schema 1.使用IDEA开发Spark SQL 1.1创建DataFrame/DataSet 1.指定列名添加Schema 2.通过StrucType指定Schema 3.编写样例类,利用反射机制推断Schema 1.1.1指定列名添加Schema //导包 import org.apache.sp
-
浅谈DataFrame和SparkSql取值误区
1.DataFrame返回的不是对象. 2.DataFrame查出来的数据返回的是一个dataframe数据集. 3.DataFrame只有遇见Action的算子才能执行 4.SparkSql查出来的数据返回的是一个dataframe数据集. 原始数据 scala> val parquetDF = sqlContext.read.parquet("hdfs://hadoop14:9000/yuhui/parquet/part-r-00004.gz.parquet") df: or
-

Spark SQL 2.4.8 操作 Dataframe的两种方式
目录 一.测试数据 二.创建DataFrame 方式一:DSL方式操作 方式二:SQL方式操作 一.测试数据 7369,SMITH,CLERK,7902,1980/12/17,800,20 7499,ALLEN,SALESMAN,7698,1981/2/20,1600,300,30 7521,WARD,SALESMAN,7698,1981/2/22,1250,500,30 7566,JONES,MANAGER,7839,1981/4/2,2975,20 7654,MARTIN,SALESMAN,
-
Python使用flask框架操作sqlite3的两种方式
本文实例讲述了Python使用flask框架操作sqlite3的两种方式.分享给大家供大家参考,具体如下: 方式一:raw_sql import sqlite3 from flask import Flask, request, jsonify app = Flask(__name__) DATABASE_URI = ":memory:" # 创建表格.插入数据 @app.before_first_request def create_db(): # 连接 conn = sqlite3
-
Java和scala实现 Spark RDD转换成DataFrame的两种方法小结
一:准备数据源 在项目下新建一个student.txt文件,里面的内容为: 1,zhangsan,20 2,lisi,21 3,wanger,19 4,fangliu,18 二:实现 Java版: 1.首先新建一个student的Bean对象,实现序列化和toString()方法,具体代码如下: package com.cxd.sql; import java.io.Serializable; @SuppressWarnings("serial") public class Stude
-
Python操作MySQL数据库的两种方式实例分析【pymysql和pandas】
本文实例讲述了Python操作MySQL数据库的两种方式.分享给大家供大家参考,具体如下: 第一种 使用pymysql 代码如下: import pymysql #打开数据库连接 db=pymysql.connect(host='1.1.1.1',port=3306,user='root',passwd='123123',db='test',charset='utf8') cursor=db.cursor()#使用cursor()方法获取操作游标 sql = "select * from tes
-
pyspark 读取csv文件创建DataFrame的两种方法
方法一:用pandas辅助 from pyspark import SparkContext from pyspark.sql import SQLContext import pandas as pd sc = SparkContext() sqlContext=SQLContext(sc) df=pd.read_csv(r'game-clicks.csv') sdf=sqlc.createDataFrame(df) 方法二:纯spark from pyspark import SparkCo
-
深入SqlServer2008 数据库同步的两种方式(Sql JOB)的分析介绍
下面介绍的就是数据库同步的两种方式: 1.SQL JOB的方式 sql Job的方式同步数据库就是通过SQL语句,将一个数据源中的数据同步到目标数据库中.特点是它可以灵活的通过SQL的方式进行数据库之间的同步操作.可以在制定的时间时间作为任务计划自动执行.缺点是需要写SQL来进行操作.既然是数据库之间的同步就涉及到数据库之间的连接.建立连接是同步的第一步.SQL Server建立连接可以通过系统存储过程建立[是否还有其他方式,我还不清楚].存储过程有以下几个:sp_droplinkedsrvl
-
Mysql效率优化定位较低sql的两种方式
关于mysql效率优化一般通过以下两种方式定位执行效率较低的sql语句. 通过慢查询日志定位那些执行效率较低的 SQL 语句,用 --log-slow-queries[=file_name] 选项启动时, mysqld 会 写一个包含所有执行时间超过 long_query_time 秒的 SQL 语句的日志文件,通过查看这个日志文件定位效率较低的 SQL . 慢查询日志在查询结束以后才纪录,所以在应用反映执行效率出现问题的时候查询慢查询日志并不能定位问题,可以使用 show processlis
-
Springboot整合MongoDB进行CRUD操作的两种方式(实例代码详解)
1 简介 Springboot是最简单的使用Spring的方式,而MongoDB是最流行的NoSQL数据库.两者在分布式.微服务架构中使用率极高,本文将用实例介绍如何在Springboot中整合MongoDB的两种方法:MongoRepository和MongoTemplate. 代码结构如下: 2 项目准备 2.1 启动MongoDB实例 为了方便,使用Docker来启动MongoDB,详细指导文档请参考:基于Docker的MongoDB实现授权访问的方法,这里不再赘述. 2.2 引入相关依赖
-
国产化中的 .NET Core 操作达梦数据库DM8的两种方式(操作详解)
目录 背景 环境 SDK 操作数据库 DbHelperSQL方式 Dapper方式 背景 某个项目需要实现基础软件全部国产化,其中操作系统指定银河麒麟,数据库使用达梦V8,CPU平台的范围包括x64.龙芯.飞腾.鲲鹏等.考虑到这些基础产品对.NET的支持,最终选择了.NET Core 3.1. 环境 CPU平台:x86-64 / Arm64 操作系统:银河麒麟 v4 数据库:DM8 .NET:.NET Core 3.1 SDK 达梦自己提供了.NET操作其数据库的SDK,可以通过NuGet安装,
-
oracle中得到一条SQL语句的执行时间的两种方式
oracle中如果需要得到一条SQL语句的执行时间可以用如下2种方式 复制代码 代码如下: SQL> set timing on; SQL> select count(*) from wea; COUNT(*) ---------- 39490 已用时间: 00: 00: 00.06 SQL> select sql_text, elapsed_time from v$sql 2 where sql_text like 'select count(*) from wea'; 未选定行 已用