python 利用浏览器 Cookie 模拟登录的用户访问知乎的方法
首先在火狐浏览器上登录知乎,然后使用火狐浏览器插件 Httpfox 获取 GET 请求的Cookie,这里注意使用状态值为 200(获取成功)的某次GET.
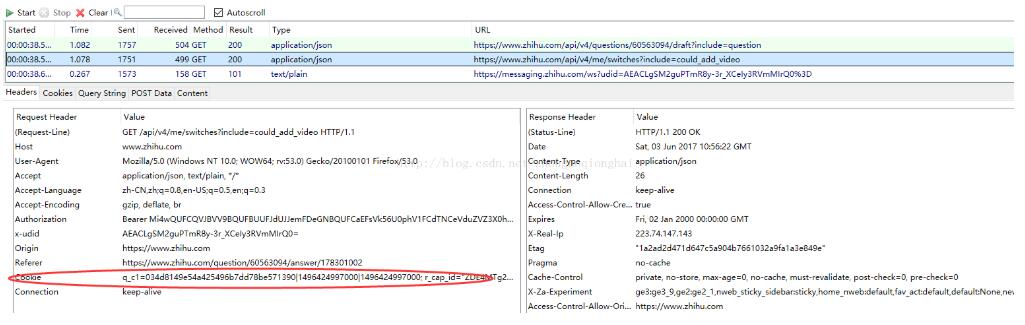
将 Cookies 复制出来,注意这一行非常长,不要人为添加换行符。而且 Cookie 中使用了双引号,最后复制到代码里使用单引号包起来。
使用下边代码检验是否是模拟了登录的用户的请求:
import requests
import re
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0',
'Cookie':'q_c1=034d8149e54a425496b7dd78be571390|1496424997000|1496424997000; r_cap_id="ZDE4MTg2NGFhMjdlNDlhMTllZWFlMmJmNjkzN2MyMzI=|1496487358|d6df41ad90d6d1a94bcbd27f2962fea69d2ec1b6"; cap_id="OTc1NmViYzJlNDZjNDVlY2E1YTZiNTZjNTFkMjZkNDY=|1496487358|52ac19a9e05ee48e155d2b4d57d414792873c062"; d_c0="AEACLgSM2guPTmR8y-3r_XCeIy3RVmMIrQ0=|1496424997"; __utma=51854390.870770348.1496424950.1496483801.1496485796.4; __utmz=51854390.1496485796.4.3.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; __utmv=51854390.100--|2=registration_date=20141101=1^3=entry_date=20141101=1; _zap=5b305d08-cca7-4182-b1a8-1d8190e94a3b; aliyungf_tc=AQAAAFdv8y0T4AMAj5NK3+HVvqiouPgb; acw_tc=AQAAAHPUpVJ7LQQAj5NK35xm3ILOPUBu; _xsrf=85bb3aa751345649abdd275cb42ed704; __utmc=51854390; capsion_ticket="2|1:0|10:1496486629|14:capsion_ticket|44:ODJkNDE0MDQ1MjNmNDYwZTlhZGViZWNhNWNlZDI4Y2E=|6ded3f3e82c25526f236a4bd135705bb334e25d8df96750d89afa5ae4ab49a04"; __utmb=51854390.8.10.1496485796; __utmt=1; z_c0=Mi4wQUFCQVJBVV9BQUFBUUFJdUJJemFDeGNBQUFCaEFsVk56U0phV1FCdTNCeVduZVZ3X0hweWxnWTRIeTZmMmtyUEFn|1496487376|d6107bbdbb3ccd015757953a40ee1ecedae6834c'
}
r = requests.get("https://www.zhihu.com/question/20273782", headers = headers)
text = r.text
re.compile(r"加入知乎").search(text)
如果是登录的用户,响应的内容中包含用户名。没用登录的话,响应的内容中包含 “登录”,“加入知乎” ,可以据此来判断。
Cookie 每次登录的值都不一样,退出之后再登录需要重新采集。
以上这篇python 利用浏览器 Cookie 模拟登录的用户访问知乎的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

Python 爬虫模拟登陆知乎
在之前写过一篇使用python爬虫爬取电影天堂资源的文章,重点是如何解析页面和提高爬虫的效率.由于电影天堂上的资源获取权限是所有人都一样的,所以不需要进行登录验证操作,写完那篇文章后又花了些时间研究了一下python模拟登陆,网上关于这部分的资料很多,很多demo都是登陆知乎的,原因是知乎的登陆比较简单,只需要post几个参数,保存cookie.而且还没有进行加密,很适合用来做教学.我也是是新手,一点点的摸索终于成功登陆上了知乎.就通过这篇文章分享一下学习这部分的心得,希望对那些和我一样的初学者
-
python爬虫框架scrapy实现模拟登录操作示例
本文实例讲述了python爬虫框架scrapy实现模拟登录操作.分享给大家供大家参考,具体如下: 一.背景: 初来乍到的pythoner,刚开始的时候觉得所有的网站无非就是分析HTML.json数据,但是忽略了很多的一个问题,有很多的网站为了反爬虫,除了需要高可用代理IP地址池外,还需要登录.例如知乎,很多信息都是需要登录以后才能爬取,但是频繁登录后就会出现验证码(有些网站直接就让你输入验证码),这就坑了,毕竟运维同学很辛苦,该反的还得反,那我们怎么办呢?这不说验证码的事儿,你可以自己手动输入验
-
基于Python打造账号共享浏览器功能
本篇文章介绍的内容会涉及到以下知识: PyQt5的使用; Selenium的使用; 代理服务器的架设和使用: 一.账号限制之痛 在如今的互联网中,免费的信息和资源占据了很大一部分,各类互联网应用提供了各行各业的资讯和资源.这是互联网能够不断繁荣和扩大的重要原因之一. 与此同时,一些收费或不公开的互联网应用则构成了互联网世界中更有价值和意义的部分. 一些限制性较低的网站,可能仅仅需要进行用户登录即可使用服务: 一些限制性中等的网站,则可能会出于账户安全或是其他方面的因素考虑,限制账号在一定时间一定
-
Python爬虫之模拟知乎登录的方法教程
前言 对于经常写爬虫的大家都知道,有些页面在登录之前是被禁止抓取的,比如知乎的话题页面就要求用户登录才能访问,而 "登录" 离不开 HTTP 中的 Cookie 技术. 登录原理 Cookie 的原理非常简单,因为 HTTP 是一种无状态的协议,因此为了在无状态的 HTTP 协议之上维护会话(session)状态,让服务器知道当前是和哪个客户在打交道,Cookie 技术出现了 ,Cookie 相当于是服务端分配给客户端的一个标识. 浏览器第一次发起 HTTP 请求时,没有携带任何 Co
-
python 利用浏览器 Cookie 模拟登录的用户访问知乎的方法
首先在火狐浏览器上登录知乎,然后使用火狐浏览器插件 Httpfox 获取 GET 请求的Cookie,这里注意使用状态值为 200(获取成功)的某次GET. 将 Cookies 复制出来,注意这一行非常长,不要人为添加换行符.而且 Cookie 中使用了双引号,最后复制到代码里使用单引号包起来. 使用下边代码检验是否是模拟了登录的用户的请求: import requests import re headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT
-
python网络爬虫之模拟登录 自动获取cookie值 验证码识别的具体实现
目录 1.爬取网页分析 2.验证码识别 3.cookie自动获取 4.程序源代码 chaojiying.py sign in.py 1.爬取网页分析 爬取的目标网址为:https://www.gushiwen.cn/ 在登陆界面需要做的工作有,获取验证码图片,并识别该验证码,才能实现登录. 使用浏览器抓包工具可以看到,登陆界面请求头包括cookie和user-agent,故在发送请求时需要这两个数据.其中user-agent可通过手动添加到请求头中,而cookie值需要自动获取. 分析完毕,实践
-
python利用requests库模拟post请求时json的使用教程
我们都见识过requests库在静态网页的爬取上展现的威力,我们日常见得最多的为get和post请求,他们最大的区别在于安全性上: 1.GET是通过URL方式请求,可以直接看到,明文传输. 2.POST是通过请求header请求,可以开发者工具或者抓包可以看到,同样也是明文的. 3.GET请求会保存在浏览器历史纪录中,还可能会保存在Web的日志中. 两者用法上也有显著差异(援引自知乎): 1.GET用于从服务器端获取数据,包括静态资源(HTML|JS|CSS|Image等等).动态数据展示(列表
-
Android利用爬虫实现模拟登录的实现实例
Android利用爬虫实现模拟登录的实现实例 为了用手机登录校网时不用一遍一遍的输入账号密码,于是决定用爬虫抓取学校登录界面,然后模拟填写本次保存的账号.密码,模拟点击登录按钮.实现过程折腾好几个. 一开始选择的是htmlunit解析登录界面html,在pc上测的能实现,结果在android上运行不起来,因为htmlunit利用了javax中的类实现的解析,android不支持javax,所以就跑不起来. 不过pc还是ok的 实例代码: package com.yasin; import jav
-
python+selenium实现12306模拟登录的步骤
简介: 这里是利用了selenium+图片识别验证,来实现12306的模拟登录,中间也参考了好几个项目,实现了这个小demo,中间也遇到了很多的坑,主要难点在于图片识别和滑动验证这两个方面,图片识别是利用超级鹰的服务进行验证识别的,其次一个难点就是在账户密码和图片识别都过了以后的滑动验证,因为12306网站做了反爬,利用selenium滑动时,会报错,提示你一直刷新,这里也是更改了滑动框. 技术栈: python.selenium.图片验证.滑动验证 思路: 提前卧槽,12306网站的并发真的牛
-
python使用requests.session模拟登录
最近开发一套接口,写个Python脚本,使用requests.session模拟一下登录. 因为每次需要获取用户信息,登录需要带着session信息,所以所有请求需要带着session. 请求使用post方式,请求参数类型为raw方式,参数为json类型. 登录接口参数和结果如下: 脚本如下: 1. 引入需要的第三方包 #! /usr/bin/env python3 # -*- coding: utf-8 -*- import requests # import re import json #
-
Python利用appium实现模拟手机滑动操控的操作
目录 滑动操控 如何获取设备屏幕坐标系 模拟实现一个简单的滑动操作 将 “滑动操控” 改为公共的方法 其实在前面两个章节的元素定位的场景,我们已经对 app 中的自动化操作已经略知一二.这里我们发现, 实际上 appium 复用了 selenium 的很多很多的操作方式,所以像一些 “点击.输入” 等操作,这种常规的操作的方式与在 WEB 自动化中的方式基本上是完全一致的,就不再进行赘述了. 唯一一个与 WEB 端不太一样的地方就是关于 “滑动操控” ,所以 “页面的滑动” 在实际操作手机过程中
-
JS基于cookie实现来宾统计记录访客信息的方法
本文实例讲述了JS基于cookie实现来宾统计记录访客信息的方法.分享给大家供大家参考.具体如下: 这里使用JavaScript记录访客的来宾信息,记录是第几次来访,显示的信息有:您的名字;您浏览该网页的次数;您上次浏览网页的时间.可以更改姓名. 运行效果如下图所示: 具体代码如下: <html> <head> <title>记录客户信息</title> <script language="JavaScript"> <!
-
python实现网站的模拟登录
本文主要用python实现了对网站的模拟登录.通过自己构造post数据来用Python实现登录过程. 当你要模拟登录一个网站时,首先要搞清楚网站的登录处理细节(发了什么样的数据,给谁发等...).我是通过HTTPfox来抓取http数据包来分析该网站的登录流程.同时,我们还要分析抓到的post包的数据结构和header,要根据提交的数据结构和heander来构造自己的post数据和header. 分析结束后,我们要构造自己的HTTP数据包,并发送给指定url.我们通过urllib2等几个模块提供
-
使用Python中的cookielib模拟登录网站
前面简单提到了 Python 模拟登录的程序,但是没写清楚,这里再补上一个带注释的 Python 模拟登录的示例程序.简单说一下流程:先用cookielib获取cookie,再用获取到的cookie,进入需要登录的网站. # -*- coding: utf-8 -*- # !/usr/bin/python import urllib2 import urllib import cookielib import re auth_url = 'http://www.nowamagic.net/' h