Pycharm github配置实现过程图解
Git是一个开源的分布式版本控制软件,用以有效、高速的处理从很小到非常大的项目版本管理。Git 最初是由Linus Torvalds设计开发的,用于管理Linux内核开发。Git 是根据GNU通用公共许可证版本2的条款分发的自由/免费软件,安装参见:http://git-scm.com/
GitHub是一个基于Git的远程文件托管平台(同GitCafe、BitBucket和GitLab等)。
Git本身完全可以做到版本控制,但其所有内容以及版本记录只能保存在本机,如果想要将文件内容以及版本记录同时保存在远程,则需要结合GitHub来使用。使用场景:
无GitHub:在本地 .git 文件夹内维护历时文件
有GitHub:在本地 .git 文件夹内维护历时文件,同时也将历时文件托管在远程仓库
其他:
集中式:远程服务器保存所有版本,用户客户端有某个版本
分布式:远程服务器保存所有版本,用户客户端有所有版本
准备工作:
本博客是为了懒癌患者不愿意敲git命令的同学准备的,前提需要具备git和github使用经验
git下载和安装github配置免密登录SSH KEY1.创建ssh key
打开终端,输入命令:
ssh-keygen

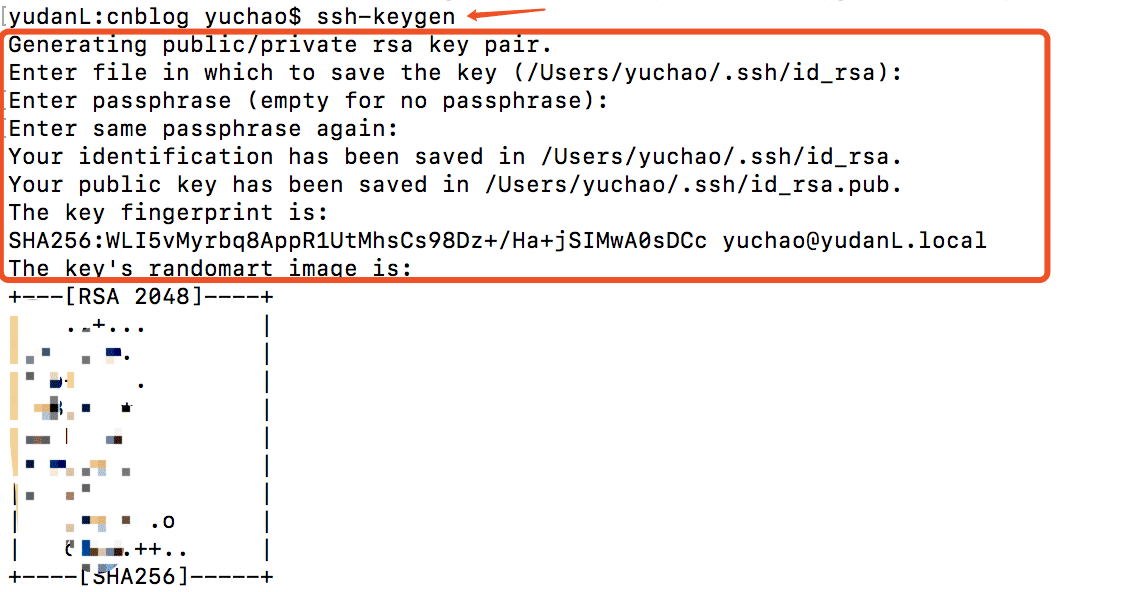
大多数 Git 服务器都会选择使用 SSH 公钥来进行授权。系统中的每个用户都必须提供一个公钥用于授权,没有的话就要生成一个。生成公钥的过程在所有操作系统上都差不多。 首先先确认一下是否已经有一个公钥了。SSH 公钥默认储存在账户的主目录下的~/.ssh目录。进去看看
2.检查公钥
这个文件默认存在用户家目录下.ssh文件中

有.pub后缀的文件就是公钥,另一个文件则是密钥。假如没有这些文件,或者干脆连.ssh目录都没有,可以用ssh-keygen来创建。该程序在 Linux/Mac 系统上由 SSH 包提供。
查看文件内容:

添加ssh key进入github
1.登录github.com
2.找到个人主页settings
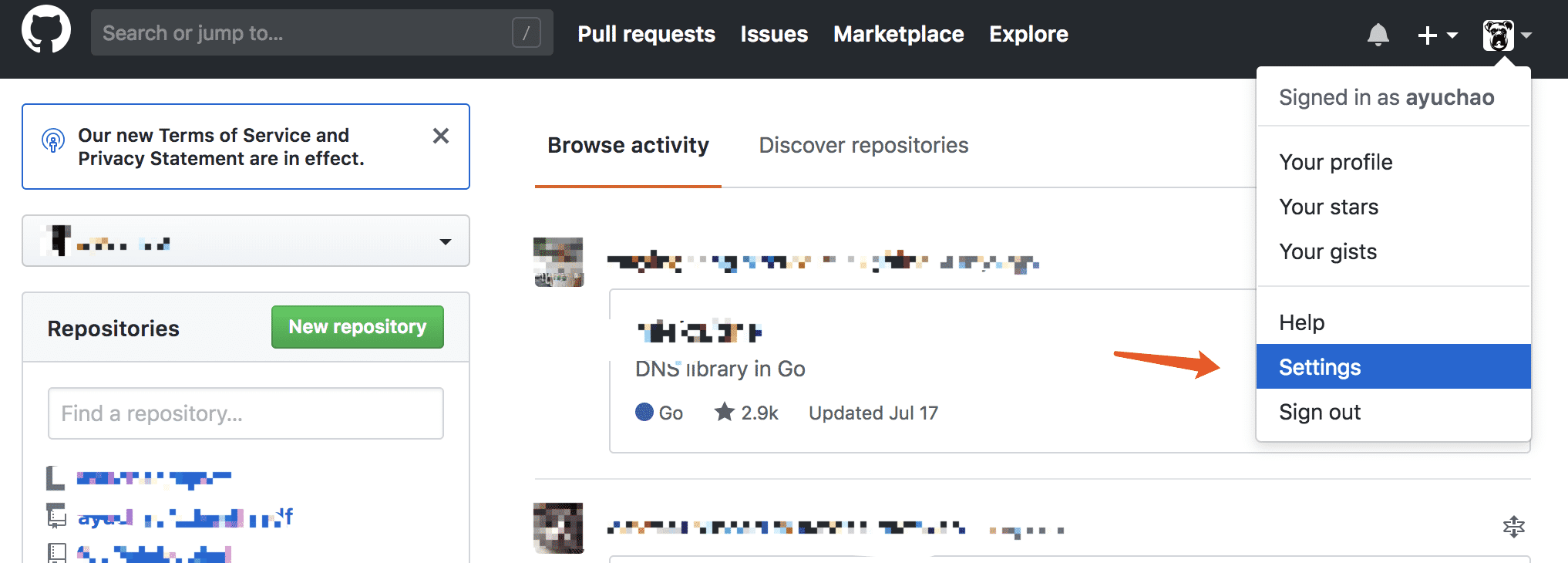
3.找到ssh and gpg keys,点击new ssh keys
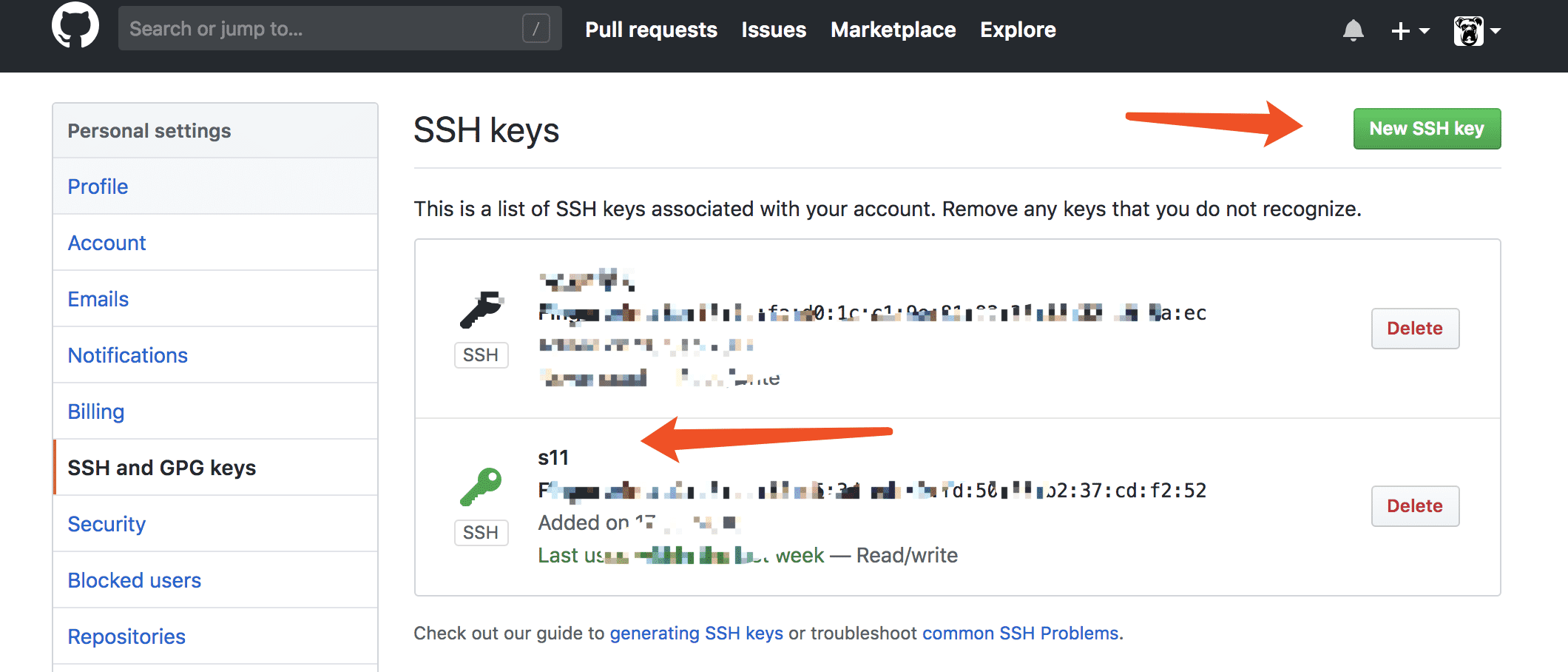
添加秘钥
验证是否成功
命令行输入:
ssh -T git@github.com
成功登录:

Pycharm和github的配置
一张图就懂了!!!找到pycharm的settings
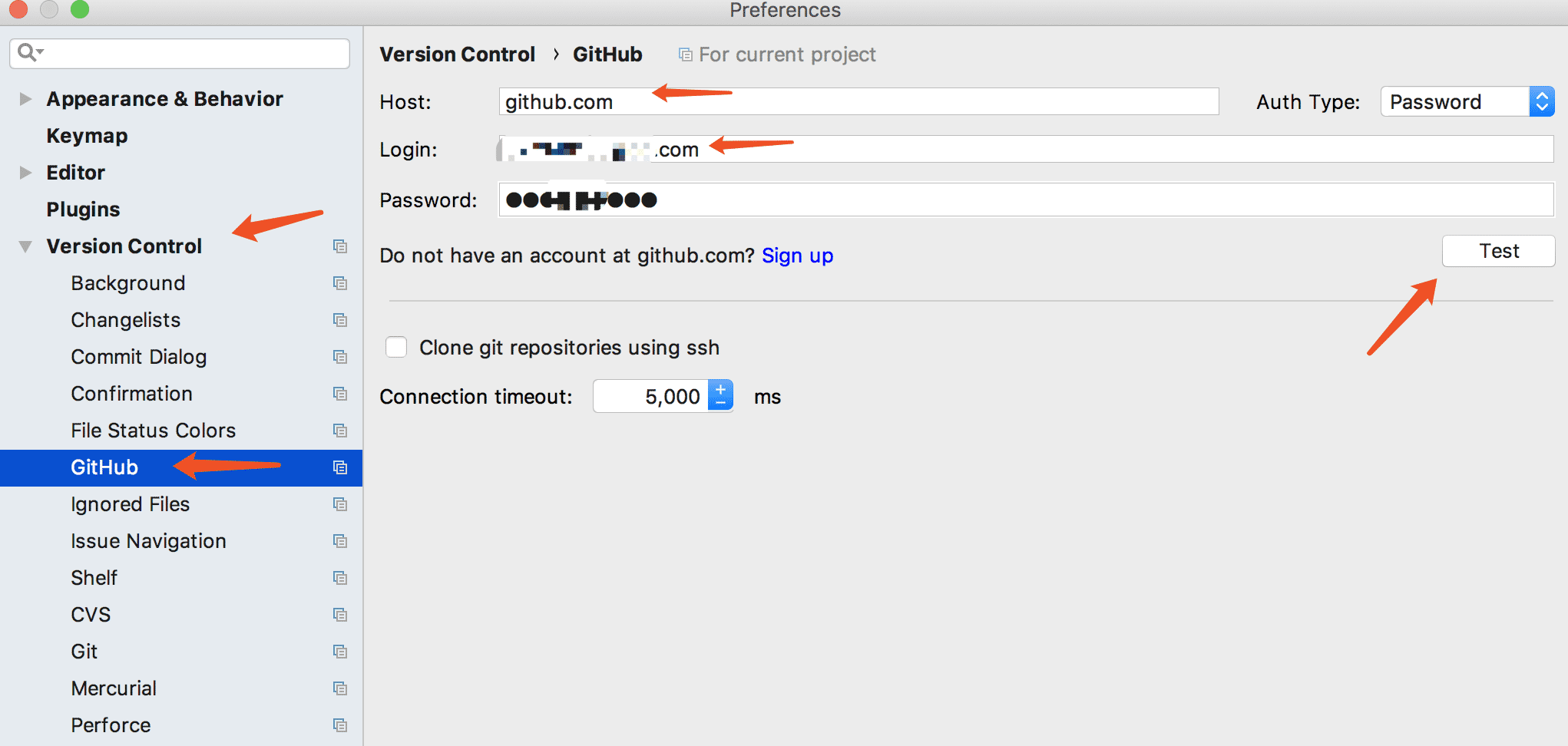
git的配置
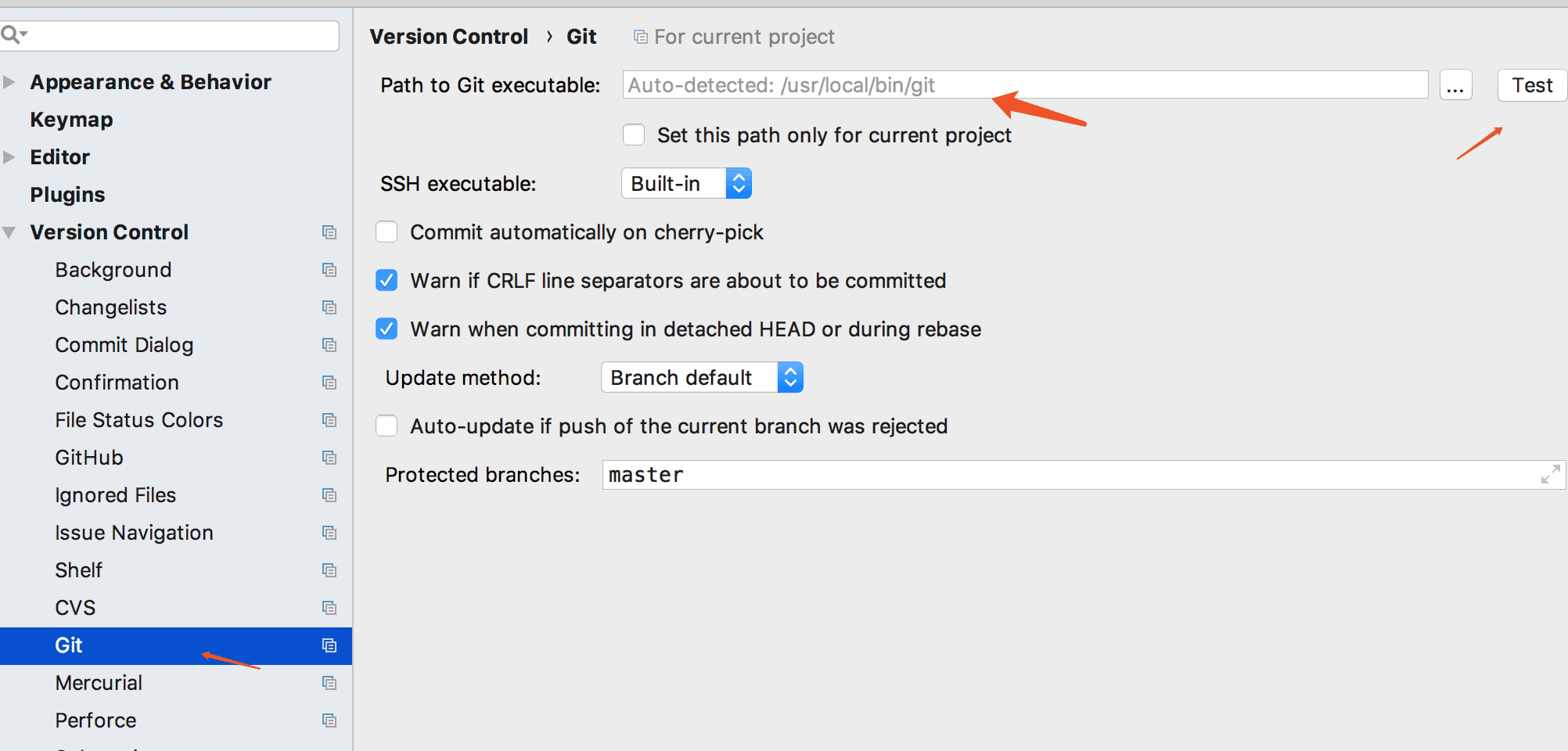
经过这两部。pycharm和github已经关联了,接下来看下开发中是怎么用的!!
创建github仓库
看图!
找到菜单栏vcs > import into version control > share project github
此时会弹出一个框,填入github信息
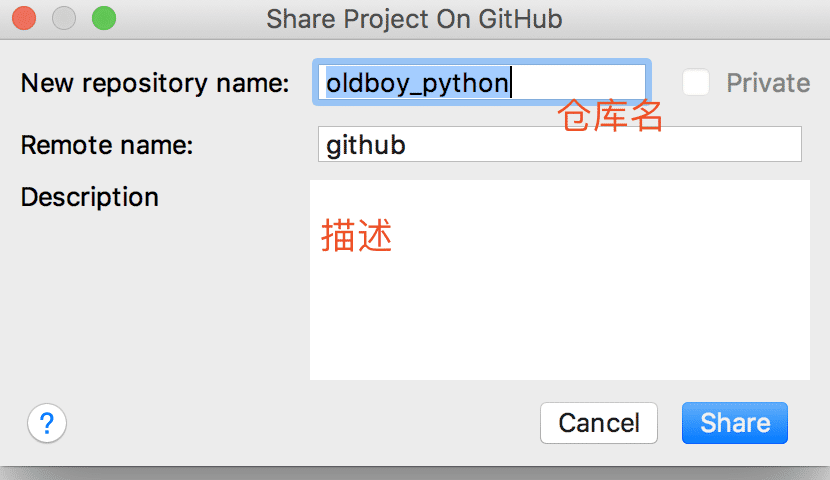
点击share之后,又会弹出一个框,让你选择需要添加的文件,选择自己需要上传的文件即可
查看自己的github是否有仓库
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
如何使用PyCharm将代码上传到GitHub上(图文详解)
说明:该篇博客是博主一字一码编写的,实属不易,请尊重原创,谢谢大家! 一丶说明 测试条件:需要有GitHub账号以及在本地安装了Git工具,无论是Linux环境还是Windows都是一样的 如果还没有GitHub账号的同学 请查看该篇博客 https://www.jb51.net/article/135606.htm Windows Git安装:https://www.jb51.net/softjc/711624.html Linux Git安装:https://www.jb51.net/art
-
使用Python快乐学数学Github万星神器Manim简介
高考在即,笔者想为孩子以后能够快乐学习数学.学习编程找到一个比较合适的项目,经过一番比较发现github上的万星项目manim(https://github.com/3b1b/manim)就非常好.它能够快速构建有关数学的动画,而且非常精确形象. 安装Manim 虽然manim已经支持Python3.7的,不过安装起来还是比较麻烦,我在ubantu18.04上直接使用安装的过程如下: 1.首先尝试直接使用pip install manimlib命令安装,但是会有以下报错 Cannot unin
-
python使用心得之获得github代码库列表
1.背景 项目需求,要求获得github的repo的api,以便可以提取repo的数据进行分析.研究了一天,终于解决了这个问题,虽然效率还是比较低下. 因为github的那个显示repo的api,列出了每个repo的详细信息,而且是json格式的.现在貌似还没有找到可以分析多个json格式数据的方法,所以用的是比较蠢得splite加re的方法.如果大家有更好的方法,不发留言讨论! 2.代码 import re import os def GetUrl(num): str = os.popen("
-

使用GitHub和Python实现持续部署的方法
借助 GitHub 的网络钩子webhook,开发者可以创建很多有用的服务.从触发一个 Jenkins 实例上的 CI(持续集成) 任务到配置云中的机器,几乎有着无限的可能性.这篇教程将展示如何使用 Python 和 Flask 框架来搭建一个简单的持续部署(CD)服务. 在这个例子中的持续部署服务是一个简单的 Flask 应用,其带有接受 GitHub 的网络钩子webhook请求的 REST 端点endpoint.在验证每个请求都来自正确的 GitHub 仓库后,服务器将拉取pull更改到仓
-
GitHub 热门:Python 算法大全,Star 超过 2 万
4 月 27 日,GitHub 趋势榜第 3 位是一个用 Python 编码实现的算法库,Star 数早已达到 26000+ 链接:https://github.com/TheAlgorithms/Python 这个库涵盖了多种算法和数据结构的介绍,比如: 排序算法(冒泡排序.希尔排序.插入排序.桶排序.合并排序.快速排序.堆排序.选择排序等). 查找算法(线性查找.二分查找.插值查找等) 加密算法(凯撒加密.RSA.ROT13 等) 机器学习 图 数字图像处理 动态规划 常见数据结构(队列.栈
-
利用PyCharm操作Github(仓库新建、更新,代码回滚)
Github是目前世界上最流行的代码存储和分享平台,而PyCharm是Python圈中最流行的IDE,它很好地支持了Git操作.本文将会介绍如何利用PyCharm来连接Github,同时演示Github上的仓库新建.更新,以及代码回滚. 在这之前,需要在你的电脑上安装Git,PyCharm.本文演示的系统为Windows系统,首先我们先从设置讲起. PyCharm设置 我们假定在电脑上已经安装了Git以及PyCharm.下面演示如何设置PyCharm,使其能够连接上Github.
-
在Pycharm中使用GitHub的方法步骤
Pycharm是当前进行python开发,尤其是Django开发最好的IDE.GitHub是程序员的圣地,几乎人人都在用. 本文假设你对pycharm和github都有一定的了解,并且希望在pycharm下直接使用github的版本控制功能. 废话不多说,下面图文详解,全是干货. 环境:pycharm 2016,git 2.8,github账户,windows7 一.配置Pycharm 不管你用哪种方法,进入pycharm的配置菜单. 选择上图中的version control.(这里插一句,不
-
Pycharm github配置实现过程图解
Git是一个开源的分布式版本控制软件,用以有效.高速的处理从很小到非常大的项目版本管理.Git 最初是由Linus Torvalds设计开发的,用于管理Linux内核开发.Git 是根据GNU通用公共许可证版本2的条款分发的自由/免费软件,安装参见:http://git-scm.com/ GitHub是一个基于Git的远程文件托管平台(同GitCafe.BitBucket和GitLab等). Git本身完全可以做到版本控制,但其所有内容以及版本记录只能保存在本机,如果想要将文件内容以及版本记录同
-
全网最详细的PyCharm+Anaconda的安装过程图解
一.下载安装包 1.安装网址 https://www.jetbrains.com/pycharm/ 2.在导航栏输入网址回车 3.点击 DOWNLOAD. 4.下载 它有专业版和社区版,我们下载社区版就可以使用了.(专业版要收费) 二.安装过程 5.双击安装包. 6.点击next 7.安装位置 它会有一个默认的安装位置,一般默认C盘,但我们可以点击 Browse... ,安装我们想要安装的位置,我安装在了D盘.如下图: 8.安装选择 数字1:create desktop shortcut(创建桌
-
Pycharm连接远程服务器过程图解
除了使用xshell等连接服务器以外,pycharm也可以连接服务器,在服务器上运行代码,上传下载文件等操作. 步骤如下:1.pycharm工具栏:Tools-->Deployment-->Configuration 2.左上角:点击+加号-->SFTP(最好选择这个) 3.给连接命名(自定义) 4.选择新建的连接-->Connection-->输入服务器.登录信息-->Test connection,测试能否连接成功. 连接成功后,会弹出如下窗口,否则是其他信息: 5
-
通过idea创建Spring Boot项目并配置启动过程图解
一.操作步骤 ①使用idea新建一个Spring Boot项目 ②修改pom.xml ③修改application.properties ④修改编写一个Hello Spring Boot的Controller ⑤启动项目访问 二.详细步骤 1.File-->New-->Project 2.选择Spring Initializr 然后Next 3.输入Artiface 然后Next 4.勾选Web .模版我们选择官方推荐的Thymeleaf模版引擎,其他框架.中间件.数据库根据需要选择即可,而
-
Pycharm修改python路径过程图解
今天安装Django的时候遇到了python版本冲突,找不到python路径,所以又重新安装了一个python3.6.5 安装完之后,突然发现自己的pycharm是之前Anaconda的3.5版本,那么就需要修改一下python版本了 首先点击左上角的File,再点击Default Settings,点击右侧Project Interpreter框框的下箭头,然后点击Show All 然后点击右侧绿色的+号,就能够添加新的地址,记住勾选就行. 以上就是本文的全部内容,希望对大家的学习有所帮助,也
-
Pycharm连接gitlab实现过程图解
一.从gitlab上clone代码到本地pycharm (一).gitlab上找到创建项目的连接地址,分两种: 1. http连接方式: http://10.22.1.72/derekchen/cxg.git 2. ssh连接方式: git@10.22.1.72:derekchen/cxg.git 免登陆方式:事先把client端的id_sda_pub里的公钥拷贝到gitlab 登陆方式:输入ssh的账号密码 (二).checkout gitlab (三).填入地址,并test测试下联通性: (
-
Github Copilot的申请以及在Pycharm的配置与使用详解
目录 前言 1.简介 2.copilot首页 3.copilot的申请 4.GitHub Copilot 官方使用文档 5.PyChram下载地址 6.Pychram下载 GitHub Copilot 7.jetbrains系列官方教程 8.申请通过之后的操作 9.使用过程 10.相关功能键: 11.退出Github Copilot 总结 前言 目前Github Copilot不是完全公开的,需要自己进入copilot官方网站进行申请,我申请下来是花了两天左右的时间. 1.简介 微软与OpenA
-
MySql 5.7.17压缩包免安装的配置过程图解
MySQL数据库管理软件有两种版本,一种是企业版,一种是社区版,其中,前者是收费的,如果是个人使用的,社区版足矣.下载mysql-5.7.17-winx64.zip,并将之解压于自己选定的目录后,如图1,会在文件夹里看到配置文件my-default.ini,此时,需将其复制,并粘贴进bin文件夹里,并将其重新命名为my.ini,如图2.至此准备工作完成,下面将详说具体的配置过程. 工具/原料 (1)电脑:Lenovo B460e: (2)操作系统:windows 7,64位: (3)mysq
-
SpringBoot配置类编写过程图解
这篇文章主要介绍了SpringBoot配置类编写过程图解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 1.编写properties文件 2.编写配置类 3.编译项目将target\classes\META-INF\spring-configuration-metadata.json文件copy到resources\META-INF目录 这样以达到配置文件中自动提示配置项 4.配置文件中配置 5.其他类中可自动注入使用 以上就是本文的全部内容,
-
jenkins配置python脚本定时任务过程图解
这篇文章主要介绍了jekins配置python脚本定时任务过程图解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 1.首先安装jekins环境,访问网页https://jenkins.io/zh/download/,下载长期稳定版如下: 2.下载安装包后直接运行,进行选择安装路径,傻瓜式安装.安装完成后,点Finished,弹出jekins输入密匙网页,根据网页提示路径,找到 对应的jekins密匙输入后,选择推荐插件安装即可.(也可以不安装插