C语言实现短字符串压缩的三种方法详解
目录
- 前言
- 一、通用算法的短字符压缩
- 二、短字符串压缩
- (1)Smaz
- (2)Shoco
- (3)Unisox2
- 三、总结
前言
上一篇探索了LZ4的压缩和解压性能,以及对LZ4和ZSTD的压缩、解压性能进行了横向对比。文末的最后也给了一个彩蛋:任意长度的字符串都可以被ZSTD、LZ4之类的压缩算压缩得很好吗?
本篇我们就来一探究竟。
一、通用算法的短字符压缩
开门见山,我们使用一段比较短的文本:Narrator: It is raining today. So, Peppa and George cannot play outside.Peppa: Daddy, it's stopped raining.
使用ZSTD与LZ4分别压缩一下上面这段短文本。下面分别是它们的压缩结果。
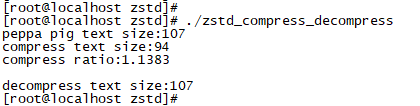
ZSTD:
LZ4:
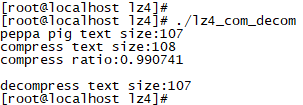
对短文本的压缩,zstd的压缩率很低,lz4压缩后的文本长度尽然超过了原有字符串的长度。这是为什么?说实话在这之前我也没想到。
引用两位大佬的名言:
Are you ok?
What's your problem?
二、短字符串压缩
从上面的结果可以得知,任何压缩算法都有它的使用场景,并不是所有长度的字符串都适合被某种算法压缩。一般原因是通用压缩算法维护了被压缩字符串的,用于字符串还原的相关数据结构,而这些数据结构的长度超过了被压缩短字符串的自身长度。
那么问题来了,“我真的有压缩短字符串的需求,我想体验压缩的极致感,怎么办?”。
短字符压缩算法它来了。这里挑选了3种比较优异的短字符压缩算法,分别是smaz,shoco,以及压轴的unisox2。跟前两章一样,还是从压缩率,压缩和解压缩性能的角度,一起看看他们在短字符压缩场景的各自表现吧。
(1)Smaz
1、Smaz的压缩和解压缩
#include <stdio.h>
#include <string.h>
#include <iostream>
#include "smaz.h"
using namespace std;
int main()
{
int buf_len;
int com_size;
int decom_size;
char com_buf[4096] = {0};
char decom_buf[4096] = {0};
char str_buf[1024] = "Narrator: It is raining today. So, Peppa and George cannot play outside.Peppa: Daddy, it's stopped raining.";
buf_len = strlen(str_buf);
com_size = smaz_compress(str_buf, buf_len, com_buf, 4096);
cout << "text size:" << buf_len << endl;
cout << "compress text size:" << com_size << endl;
cout << "compress ratio:" << (float)buf_len / (float)com_size << endl << endl;
decom_size = smaz_decompress(com_buf, com_size, decom_buf, 4096);
cout << "decompress text size:" << decom_size << endl;
if(strncmp(str_buf, decom_buf, buf_len)) {
cout << "decompress text is not equal to source text" << endl;
}
return 0;
}
执行结果如下:
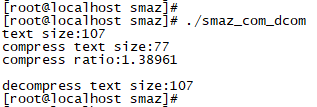
通过smaz压缩后的短字符串长度为77,和源字符串相比,减少了30Byte。
2、Smaz的压缩和解压缩性能
#include <stdio.h>
#include <string.h>
#include <iostream>
#include <sys/time.h>
#include "smaz.h"
using namespace std;
int main()
{
int cnt = 0;
int buf_len;
int com_size;
int decom_size;
timeval st, et;
char *com_ptr = NULL;
char* decom_ptr = NULL;
char str_buf[1024] = "Narrator: It is raining today. So, Peppa and George cannot play outside.Peppa: Daddy, it's stopped raining.";
buf_len = strlen(str_buf);
gettimeofday(&st, NULL);
while(1) {
com_ptr = (char *)malloc(buf_len);
com_size = smaz_compress(str_buf, buf_len, com_ptr, buf_len);
free(com_ptr);
cnt++;
gettimeofday(&et, NULL);
if(et.tv_sec - st.tv_sec >= 10) {
break;
}
}
cout << endl <<"compress per second:" << cnt/10 << " times" << endl;
cnt = 0;
com_ptr = (char *)malloc(buf_len);
com_size = smaz_compress(str_buf, buf_len, com_ptr, buf_len);
gettimeofday(&st, NULL);
while(1) {
// decompress length not more than origin buf length
decom_ptr = (char *)malloc(buf_len + 1);
decom_size = smaz_decompress(com_ptr, com_size, decom_ptr, buf_len + 1);
// check decompress length
if(buf_len != decom_size) {
cout << "decom error" << endl;
}
free(decom_ptr);
cnt++;
gettimeofday(&et, NULL);
if(et.tv_sec - st.tv_sec >= 10) {
break;
}
}
cout << "decompress per second:" << cnt/10 << " times" << endl << endl;
free(com_ptr);
return 0;
}
结果如何?
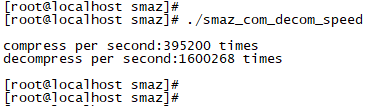
压缩性能在40w条/S,解压在百万级,好像还不错哈!
(2)Shoco
1、Shoco的压缩和解压缩
#include <stdio.h>
#include <string.h>
#include <iostream>
#include "shoco.h"
using namespace std;
int main()
{
int buf_len;
int com_size;
int decom_size;
char com_buf[4096] = {0};
char decom_buf[4096] = {0};
char str_buf[1024] = "Narrator: It is raining today. So, Peppa and George cannot play outside.Peppa: Daddy, it's stopped raining.";
buf_len = strlen(str_buf);
com_size = shoco_compress(str_buf, buf_len, com_buf, 4096);
cout << "text size:" << buf_len << endl;
cout << "compress text size:" << com_size << endl;
cout << "compress ratio:" << (float)buf_len / (float)com_size << endl << endl;
decom_size = shoco_decompress(com_buf, com_size, decom_buf, 4096);
cout << "decompress text size:" << decom_size << endl;
if(strncmp(str_buf, decom_buf, buf_len)) {
cout << "decompress text is not equal to source text" << endl;
}
return 0;
}
执行结果如下:
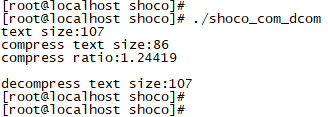
通过shoco压缩后的短字符串长度为86,和源字符串相比,减少了21Byte。压缩率比smaz要低。
2、Shoco的压缩和解压缩性能
#include <stdio.h>
#include <string.h>
#include <iostream>
#include <sys/time.h>
#include "shoco.h"
using namespace std;
int main()
{
int cnt = 0;
int buf_len;
int com_size;
int decom_size;
timeval st, et;
char *com_ptr = NULL;
char* decom_ptr = NULL;
char str_buf[1024] = "Narrator: It is raining today. So, Peppa and George cannot play outside.Peppa: Daddy, it's stopped raining.";
buf_len = strlen(str_buf);
gettimeofday(&st, NULL);
while(1) {
com_ptr = (char *)malloc(buf_len);
com_size = shoco_compress(str_buf, buf_len, com_ptr, buf_len);
free(com_ptr);
cnt++;
gettimeofday(&et, NULL);
if(et.tv_sec - st.tv_sec >= 10) {
break;
}
}
cout << endl <<"compress per second:" << cnt/10 << " times" << endl;
cnt = 0;
com_ptr = (char *)malloc(buf_len);
com_size = shoco_compress(str_buf, buf_len, com_ptr, buf_len);
gettimeofday(&st, NULL);
while(1) {
// decompress length not more than origin buf length
decom_ptr = (char *)malloc(buf_len + 1);
decom_size = shoco_decompress(com_ptr, com_size, decom_ptr, buf_len + 1);
// check decompress length
if(buf_len != decom_size) {
cout << "decom error" << endl;
}
free(decom_ptr);
cnt++;
gettimeofday(&et, NULL);
if(et.tv_sec - st.tv_sec >= 10) {
break;
}
}
cout << "decompress per second:" << cnt/10 << " times" << endl << endl;
free(com_ptr);
return 0;
}
执行结果如何呢?
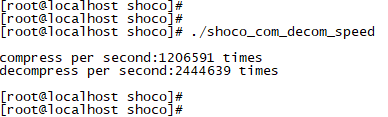
holy shit!压缩和解压缩居然都达到了惊人的百万级。就像算法作者们自己说的一样:“在长字符串压缩领域,shoco不想与通用压缩算法竞争,我们的优势是短字符的快速压缩,虽然压缩率很烂!”。这样说,好像也没毛病。
(3)Unisox2
我们再来看看unisox2呢。
1、Unisox2的压缩和解压缩
#include <stdio.h>
#include <string.h>
#include "unishox2.h"
int main()
{
int buf_len;
int com_size;
int decom_size;
char com_buf[4096] = {0};
char decom_buf[4096] = {0};
char str_buf[1024] = "Narrator: It is raining today. So, Peppa and George cannot play outside.Peppa: Daddy, it's stopped raining.";
buf_len = strlen(str_buf);
com_size = unishox2_compress_simple(str_buf, buf_len, com_buf);
printf("text size:%d\n", buf_len);
printf("compress text size:%d\n", com_size);
printf("compress ratio:%f\n\n", (float)buf_len / (float)com_size);
decom_size = unishox2_decompress_simple(com_buf, com_size, decom_buf);
printf("decompress text size:%d\n", decom_size);
if(strncmp(str_buf, decom_buf, buf_len)) {
printf("decompress text is not equal to source text\n");
}
return 0;
}
结果如下:
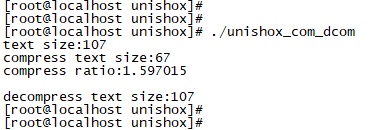
通过Unisox2压缩后的短字符串长度为67,和源字符串相比,减少了40Byte,相当于是打了6折啊!不错不错。
2、Unisox2的压缩和解压缩性能
Unisox2的压缩能力目前来看是三者中最好的,如果他的压缩和解压性能也不错的话,那就真的就比较完美了。再一起看看Unisox2的压缩和解压性能吧!
#include <stdio.h>
#include <string.h>
#include <malloc.h>
#include <sys/time.h>
#include "unishox2.h"
int main()
{
int cnt = 0;
int buf_len;
int com_size;
int decom_size;
struct timeval st, et;
char *com_ptr = NULL;
char* decom_ptr = NULL;
char str_buf[1024] = "Narrator: It is raining today. So, Peppa and George cannot play outside.Peppa: Daddy, it's stopped raining.";
buf_len = strlen(str_buf);
gettimeofday(&st, NULL);
while(1) {
com_ptr = (char *)malloc(buf_len);
com_size = unishox2_compress_simple(str_buf, buf_len, com_ptr);
free(com_ptr);
cnt++;
gettimeofday(&et, NULL);
if(et.tv_sec - st.tv_sec >= 10) {
break;
}
}
printf("\ncompress per second:%d times\n", cnt/10);
cnt = 0;
com_ptr = (char *)malloc(buf_len);
com_size = unishox2_compress_simple(str_buf, buf_len, com_ptr);
gettimeofday(&st, NULL);
while(1) {
// decompress length not more than origin buf length
decom_ptr = (char *)malloc(buf_len + 1);
decom_size = unishox2_decompress_simple(com_ptr, com_size, decom_ptr);
// check decompress length
if(buf_len != decom_size) {
printf("decom error\n");
}
free(decom_ptr);
cnt++;
gettimeofday(&et, NULL);
if(et.tv_sec - st.tv_sec >= 10) {
break;
}
}
printf("decompress per second:%d times\n\n", cnt/10);
free(com_ptr);
return 0;
}
执行结果如下:
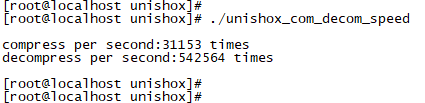
事与愿违,Unisox2虽然有三个算法中最好的压缩率,可是却也拥有最差的压缩和解压性能。跟前两章分析的不谋而合:有高压缩率,就会损失自身的压缩性能,两者不可兼得。
三、总结
本篇分享了smaz,shoco,unisox2三种短字符串压缩算法,分别探索了它们各自的压缩率与压缩和解压缩性能,结果如下表所示。
表1
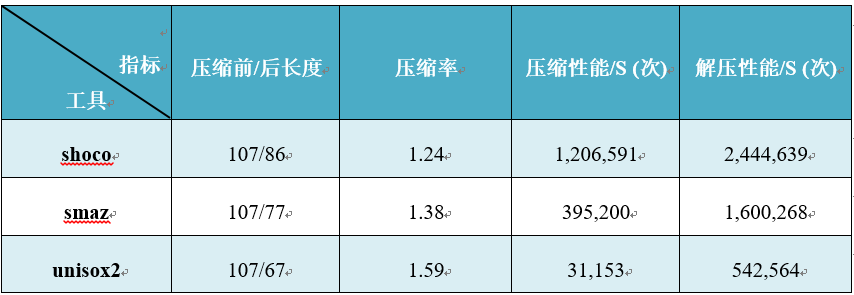
shoco的压缩率最低,但是拥有最高的压缩和解压速率;smaz居中;unisox2拥有最高的压缩率,可是它的压缩和解压性能最低。
结论与前两章有关长字符串压缩的分析不谋而合:拥有高压缩率,就会损失自身的压缩性能,两者不可兼得。
实际使用还是看自身需求和环境吧。如果适当压缩就好,那就可以选用shoco,毕竟性能高;想要节约更多的空间,那就选择smaz或者unisox2。
到此这篇关于C语言实现短字符串压缩的三种方法详解的文章就介绍到这了,更多相关C语言短字符串压缩内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
C语言字符串原地压缩实现方法
本文实例讲述了C语言字符串原地压缩的实现方法,对于学习字符串操作的算法设计有不错的借鉴价值.分享给大家供大家参考.具体方法如下: 字符串原地压缩示例: "eeeeeaaaff"压缩为"e5a3f2" 具体功能代码如下: /* * Copyright (c) 2011 alexingcool. All Rights Reserved. */ #include <iostream> #include <iterator> #include <
-
C语言字符串快速压缩算法代码
通过键盘输入一串小写字母(a~z)组成的字符串. 请编写一个字符串压缩程序,将字符串中连续出席的重复字母进行压缩,并输出压缩后的字符串. 压缩规则: 1.仅压缩连续重复出现的字符.比如字符串"abcbc"由于无连续重复字符,压缩后的字符串还是"abcbc". 2.压缩字段的格式为"字符重复的次数+字符".例如:字符串"xxxyyyyyyz"压缩后就成为"3x6yz". 示例 输入:"cccddec
-
C语言中压缩字符串的简单算法小结
应用中,经常需要将字符串压缩成一个整数,即字符串散列.比如下面这些问题: (1)搜索引擎会通过日志文件把用户每次检索使用的所有检索串都记录下来,每个查询串的长度为1-255字节.请找出最热门的10个检索串. (2)有一个1G大小的一个文件,里面每一行是一个词,词的大小不超过16字节,内存限制大小是1M.返回频数最高的100个词. (3)有10个文件,每个文件1G,每个文件的每一行存放的都是用户的query,每个文件的query都可能重复.要求你按照query的频度排序. (4)给定a.b两个文件
-

C语言实现短字符串压缩的三种方法详解
目录 前言 一.通用算法的短字符压缩 二.短字符串压缩 (1)Smaz (2)Shoco (3)Unisox2 三.总结 前言 上一篇探索了LZ4的压缩和解压性能,以及对LZ4和ZSTD的压缩.解压性能进行了横向对比.文末的最后也给了一个彩蛋:任意长度的字符串都可以被ZSTD.LZ4之类的压缩算压缩得很好吗? 本篇我们就来一探究竟. 一.通用算法的短字符压缩 开门见山,我们使用一段比较短的文本:Narrator: It is raining today. So, Peppa and George
-
Python实现解析参数的三种方法详解
目录 先决条件 使用 argparse 使用 JSON 文件 使用 YAML 文件 最后的想法 今天我们分享的主要目的就是通过在 Python 中使用命令行和配置文件来提高代码的效率 Let's go! 我们以机器学习当中的调参过程来进行实践,有三种方式可供选择.第一个选项是使用 argparse,它是一个流行的 Python 模块,专门用于命令行解析:另一种方法是读取 JSON 文件,我们可以在其中放置所有超参数:第三种也是鲜为人知的方法是使用 YAML 文件!好奇吗,让我们开始吧! 先决条件
-
python解析命令行参数的三种方法详解
这篇文章主要介绍了python解析命令行参数的三种方法详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 python解析命令行参数主要有三种方法:sys.argv.argparse解析.getopt解析 方法一:sys.argv -- 命令行执行:python test_命令行传参.py 1,2,3 1000 # test_命令行传参.py import sys def para_input(): print(len(sys.argv)) #
-
SpringMVC统一异常处理三种方法详解
这篇文章主要介绍了SpringMVC-统一异常处理三种方法详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 在 Spring MVC 应用的开发中,不管是对底层数据库操作,还是业务层或控制层操作,都会不可避免地遇到各种可预知的.不可预知的异常需要处理. 如果每个过程都单独处理异常,那么系统的代码耦合度高,工作量大且不好统一,以后维护的工作量也很大. 如果能将所有类型的异常处理从各层中解耦出来,这样既保证了相关处理过程的功能单一,又实现了异常信
-
Mybatis 逆向工程的三种方法详解
Mybatis 逆向工程 逆向工程通常包括由数据库的表生成 Java 代码 和 通过 Java 代码生成数据库表.而Mybatis 逆向工程是指由数据库表生成 Java 代码. Mybaits 需要程序员自己编写 SQL 语句,但是 Mybatis 官方提供逆向工程可以针对单表自动生成 Mybaits 执行所需要的代码,包括 POJO.Mapper.java.Mapper.xml -. 一.通过 Eclipse 插件完成 Mybatis 逆向工程 1. 在线安装 Eclipse 插件
-
Android开发之保存图片到相册的三种方法详解
目录 方法一 方法二 方法三 有三种方法如下:三个方法都需要动态申请读写权限否则保存图片到相册也会失败 方法一 /** * 保存bitmap到本地 * * @param bitmap Bitmap */ public static void saveBitmap(Bitmap bitmap, String path) { String savePath; File filePic; if (Environment.getExternalStorageState().equals(Environm
-
Python中提取人脸特征的三种方法详解
目录 1.直接使用dlib 2.使用深度学习方法查找人脸,dlib提取特征 3.使用insightface提取人脸特征 安装InsightFace 提取特征 1.直接使用dlib 安装dlib方法: Win10安装dlib GPU过程详解 思路: 1.使用dlib.get_frontal_face_detector()方法检测人脸的位置. 2.使用 dlib.shape_predictor()方法得到人脸的关键点. 3.使用dlib.face_recognition_model_v1()方法提取
-
Java比较两个对象大小的三种方法详解
目录 一. 为什么需要比较对象 二. 元素的比较 1. 基本类型的比较 2. 引用类型的比较 三. 对象比较的方法 1. equals方法比较 2. 基于Comparable接口的比较 3. 基于Comparator接口的比较 4. 三种比较方式对比 一. 为什么需要比较对象 上一节介绍了优先级队列,在优先级队列中插入的元素必须能比较大小,如果不能比较大小,如插入两个学生类型的元素,会报ClassCastException异常 示例: class Student{ String name; in
-
JS截取字符串的三种方法详解
JS提供三个截取字符串的方法,分别是:slice(),substring()和substr(),它们都可以接受一个或两个参数: var stmp = "rcinn.cn"; 使用一个参数 alert(stmp.slice(3));//从第4个字符开始,截取到最后个字符;返回"nn.cn" alert(stmp.substring(3));//从第4个字符开始,截取到最后个字符;返回"nn.cn" 使用两个参数 alert(stmp.slice(1
-
Python实现重建二叉树的三种方法详解
本文实例讲述了Python实现重建二叉树的三种方法.分享给大家供大家参考,具体如下: 学习算法中,探寻重建二叉树的方法: 用input 前序遍历顺序输入字符重建 前序遍历顺序字符串递归解析重建 前序遍历顺序字符串堆栈解析重建 如果懒得去看后面的内容,可以直接点击此处本站下载完整实例代码. 思路 学习算法中,python 算法方面的资料相对较少,二叉树解析重建更少,只能摸着石头过河. 通过不同方式遍历二叉树,可以得出不同节点的排序.那么,在已知节点排序的前提下,通过某种遍历方式,可以将排序进行解析