Python 统计Jira的bug 并发送邮件功能
1.首先在pycharm上使用pip安装
pip install html-table pip install jira
2.初始化发件人邮箱,账号,密码
# 发件人邮箱账号 my_sender = 'username@xxx.com.cn' # user登录邮箱的用户名,password登录邮箱的密码(授权码,即客户端密码,非网页版登录密码),但用腾讯邮箱的登录密码也能登录成功 my_pass = 'xxxxx' # 收件人邮箱账号 my_users=['username@xxx.com.cn']
3.登录Jira
class JiraTool:
#初始化
def __init__(self):
self.server = 'http://ip:5500' //连接Jira的Ip地址
self.basic_auth = ('username', 'password') //连接Jira的账户和密码
self.jiraClinet = None
4.登录Jira
def login(self):
self.jiraClinet = JIRA(server=self.server, basic_auth=self.basic_auth)
if self.jiraClinet != None:
print("登录成功!")
return True
else:
return False
5.获取Jira问题列表
def get_issue_list_by_jql(self, jql):
issue_list = []
issue_key_list = self.jiraClinet.search_issues(jql_str=jql,startAt=0,maxResults=1000) //Jira默认统计50条,maxResults设置大小
for key_list in issue_key_list:
issue = self.jiraClinet.issue(key_list.key)
issue_list.append(issue)
# print(issue.key) #关键字
# print(issue.fields.summary) #bug描述
# print(issue.fields.status) bug状态
# print(issue.fields.assignee) #经办人
# print(issue.fields.components[0].name) #模块
# print(issue.fields.priority) #优先级
return issue_list
6.创建一个表格
def gen_new_bug_caption_str(issue_list):
dict = {}
for issue in issue_list:
dict[issue.fields.status.name] = dict.get(issue.fields.status.name, 0) + 1
#dict[issue.key.split('-')[0]] = dict.get(issue.key.split('-')[0],0) + 1
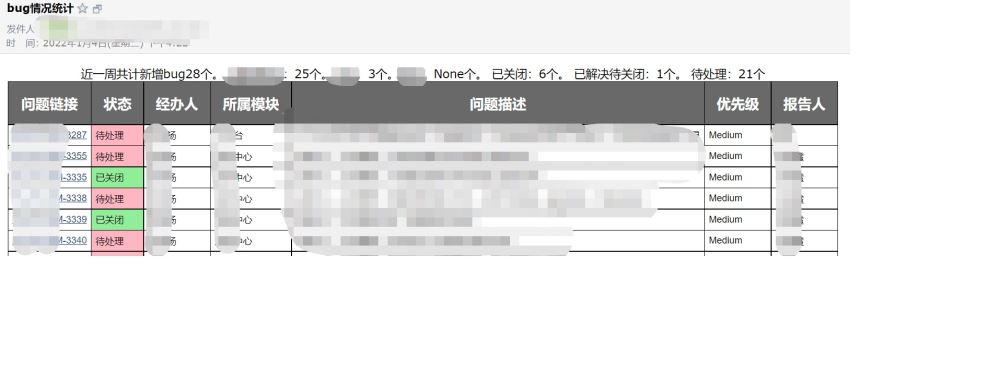
caption_str = '近一周共计新增bug' + str(len(issue_list)) + '个。 已关闭:' + str(dict.get('已关闭')) + '个。 已解决待关闭:' + str(dict.get('已解决')) + '个。 待处理:' +str(dict.get('待处理')) + '个'
#print(caption_str)
return caption_str
7.生成html
#标题样式
# table.caption.set_style({'font-size':'15px','align':'left'})
table.caption.set_style({'font-size':'15px'})
# 表格样式,即<table>标签样式
table.set_style({
'border-collapse':'collapse',
'word-break':'keep-all',
'white-space':'nowrap',
'font-size':'14px'
})
#设置每个单元格的样式,主要是规定边框样式:
table.set_cell_style({
'border-color':'#000',
'border-width':'1px',
'border-style':'solid',
'padding':'5px',
})
#设置表头单元格样式,规定颜色,字体大小,以及填充大小:
#表头样式
table.set_header_row_style({
'color':'#fff',
'background-color':'#696969',
'font-size':'18px',
})
#覆盖表单单元格字体样式
table.set_header_cell_style({
'padding':'15px',
})
#遍历数据行,根据不同状态设置背景颜色
for row in table.iter_data_rows():
if row[1].value in "待处理":
row[1].set_style({
'background-color': '#FFB6C1',
})
if row[1].value in "已解决":
row[1].set_style({
'background-color': '#E1FFFF',
})
if row[1].value in "已关闭":
row[1].set_style({
'background-color': '#90EE99',
})
if row[1].value in "重新打开":
row[1].set_style({
'background-color': '#DC143C',
})
if row[1].value in "开发中":
row[1].set_style({
'background-color': '#f7d7a7',
})
#生成HTML文本:
html = table.to_html()
# print(html)
return html
8.发送邮件
def sendmail(html):
ret=True
try:
# 邮件内容
msg=MIMEText(html,'html','utf-8')
# 括号里的对应发件人邮箱昵称、发件人邮箱账号
msg['From']=formataddr(["张三",my_sender])
# 括号里的对应收件人邮箱昵称、收件人邮箱账号
#msg['To']=formataddr(["李四",my_user])
# 邮件的主题
msg['Subject']="bug情况统计"
server=smtplib.SMTP_SSL("smtp.exmail.qq.com", 465)
# 登录服务器,括号中对应的是发件人邮箱账号、邮箱密码
server.login(my_sender, my_pass)
# 发送邮件,括号中对应的是发件人邮箱账号、收件人邮箱账号、发送邮件
server.sendmail(my_sender, my_users, msg.as_string())
# 关闭连接
server.quit()
# 如果 try 中的语句没有执行,则会执行下面的 ret=False
except Exception:
ret=False
return ret
9.调试
new_bug_jql = "project in (AAA, BBB, CCC) AND issuetype in (Bug, 缺陷) AND created >= -1w ORDER BY component ASC, assignee ASC, priority DESC, updated DESC"
old_bug_jql = "project in (AAA, BBB, CCC) AND issuetype in (Bug, 缺陷) AND status in (待处理, 开发中, Reopened) AND created <= -1w ORDER BY component ASC, assignee ASC, priority DESC, updated DESC"
jiraTool = JiraTool()
jiraTool.login()
new_issue_list = jiraTool.get_issue_list_by_jql(new_bug_jql)
new_bug_caption_str = gen_new_bug_caption_str(new_issue_list)
new_bug_html = gen_html_table(new_issue_list,new_bug_caption_str)
# print(new_bug_html)
old_issue_list = jiraTool.get_issue_list_by_jql(old_bug_jql)
old_bug_html = gen_html_table(old_issue_list, "超过一周未关闭bug")
eamil_html = (new_bug_html + "<br/><br/><br/>" + old_bug_html).replace(">", ">").replace(""", "\"").replace("<", "<")
# print(eamil_html)
ret=sendmail(eamil_html)
if ret:
print("邮件发送成功")
else:
print("邮件发送失败")
到此这篇关于Python 统计Jira的bug 并发送邮件的文章就介绍到这了,更多相关Python 统计Jira的bug 内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python操作Jira库常用方法解析
Jira提供了完善的RESTful API,如果不想直接请求API接口可以使用Python的Jira库来操作Jira Jira Python文档 安装方法 pip install jira 认证 Jira的访问是有权限的,在访问Jira项目时首先要进行认证,Jira Python库提供了3种认证方式: 通过Cookis方式认证(用户名,密码) 通过Basic Auth方式认证(用户名,密码) 通过OAuth方式认证 认证方式只需要选择一种即可,以下代码为使用Cookies方式认证. form j
-
Python用Jira库来操作Jira
Jira简介 Jira是一款功能非常强大的管理工具,广泛的用来 缺陷跟踪.用例管理.需求收集.任务跟踪.工时管理.项目计划管理等工作领域.所以使用这款产品的公司很多,这篇博客讲述在执行自动化测试用例过程中,将失败的用例自动在jira系统记录bug. 提供了完善的RESTful API,如果不想直接请求API接口可以使用Python的Jira库来操作Jira. 官方文档 一.安装 # 安装第三方jira库 pip install jira 二.认证 官网提供了4种认证方式: Cookie Base
-

Python中Cookies导出某站用户数据的方法
应朋友需要,想将某客户的数据从某站里导出,先去某站搞个账号,建几条数据观察一番,心里有底后开搞. 1.Python环境搭建 之前电脑有安装过PyCharm Community 2019.1,具体安装过程就不写了,先跑个HelloWorld,输出正常后正式开整. 2.利用抓包工具或者Google浏览器调试模式拿到请求参数 Cookies参数如下: cookies = { 'JSESSIONID': 'XXX', 'phone': 'XXX', 'password': 'XXX', 'isAuto'
-
Python 统计Jira的bug 并发送邮件功能
1.首先在pycharm上使用pip安装 pip install html-table pip install jira 2.初始化发件人邮箱,账号,密码 # 发件人邮箱账号 my_sender = 'username@xxx.com.cn' # user登录邮箱的用户名,password登录邮箱的密码(授权码,即客户端密码,非网页版登录密码),但用腾讯邮箱的登录密码也能登录成功 my_pass = 'xxxxx' # 收件人邮箱账号 my_users=['username@xxx.com.cn
-
利用Python统计Jira数据并可视化
目录 1. 准备 2. 实战一下 3. 总结 大家好,我是安果! 目前公司使用 Jira 作为项目管理工具,在每一次迭代完成后的复盘会上,我们都需要针对本次迭代的 Bug 进行数据统计,以帮助管理层能更直观的了解研发的代码质量 本篇文章将介绍如何利用统计 Jira 数据,并进行可视化 1. 准备 首先,安装 Python 依赖库 # 安装依赖库 pip3 install jira pip3 install html-table pip3 install pyecharts pip3 instal
-
Python django实现简单的邮件系统发送邮件功能
本文实例讲述了Python django实现简单的邮件系统发送邮件功能.分享给大家供大家参考,具体如下: django邮件系统 Django发送邮件官方中文文档 总结如下: 1.首先这份文档看三两遍是不行的,很多东西再看一遍就通顺了. 2.send_mail().send_mass_mail()都是对EmailMessage类使用方式的一个轻度封装,所以要关注底层的EmailMessage. 3.异常处理防止邮件头注入. 4.一定要弄懂Email backends 邮件发送后端 5.多线程的邮件
-
python发送邮件功能实现代码
本文实例为大家分享了python发邮件精简代码,供大家参考,具体内容如下 import smtplib from email.mime.text import MIMEText from email.utils import formataddr #发送邮件功能 def send_mail(send_message_txt,*senders_list,**send_to_people): flag = True try: #编写发送的内容 send_msg = MIMEText(send_mes
-
python实现发送邮件功能
本文实例为大家分享了python实现发送邮件功能的具体代码,供大家参考,具体内容如下 依赖: Python代码实现发送邮件,使用的模块是smtplib.MIMEText,实现代码之前需要导入包: import smtplib from email.mime.text import MIMEText 使用163邮件发送邮件,具体代码实现如下: import smtplib from email.mime.text import MIMEText ''' 发送邮件函数,默认使用163smtp :pa
-
python实现发送邮件功能代码
本文实例为大家分享了python实现发送邮件功能的具体代码,供大家参考,具体内容如下 # -*- coding: utf-8 -*- # Author :Gogh # @Time :2017/11/28 16:56 # @Email :361910002@qq.com from email import encoders from email.header import Header from email.mime.text import MIMEText from email.utils im
-
Python发送邮件功能示例【使用QQ邮箱】
本文实例讲述了Python发送邮件功能.分享给大家供大家参考,具体如下: 这里以QQ邮箱为例说明 登录邮箱点账号 开启smtp 开启时会要求你发送一条短信,发送完成后点已发送. 就有授权码了 代码如下,只需更改发件人.收件人等信息即可 # encoding: utf-8 import logging import smtplib from email.mime.text import MIMEText import email.utils from datetime import datetim
-
使用python 3实现发送邮件功能
下面一段简短代码给大家介绍python 3实现发送邮件功能,具体代码如下所示: import smtplib from email.mime.text import MIMEText SMTPsever="smtp.163.com" #邮箱服务器 sender="**********@163.com" #邮件地址 password="Whl3386087" #密码 receivers=["********@qq.com"] c
-
Python基于SMTP协议实现发送邮件功能详解
本文实例讲述了Python基于SMTP协议实现发送邮件功能.分享给大家供大家参考,具体如下: SMTP(Simple Mail Transfer Protocol),即简单邮件传输协议,它是一组由源地址到目的地址传送邮件的规则,由它来控制信件的中转方式.Python内置对SMTP的支持,可以发送纯文本邮件.HTML邮件以及带附件的邮件. Python对SMTP支持有smtplib和email两个模块,email负责构造邮件,smtplib负责发送邮件. Python创建SMTP语法如下: imp
-
Python smtplib实现发送邮件功能
本文实例为大家分享了Python smtplib发送邮件功能的具体代码,供大家参考,具体内容如下 解决之前版本的问题,下面为最新版 #!/usr/bin/env python # coding:gbk """ FuncName: sendemail.py Desc: sendemail with text,image,audio,application... Date: 2016-06-20 10:30 Home: http://blog.csdn.net/z_johnny