python的自变量选择(所有子集回归,后退法,逐步回归)
目录
- 1、为什么需要自变量选择?
- 2、自变量选择的几个准则
- (1)自由度调整复决定系数达到最大
- (2)赤池信息量AIC达到最小
- 3、所有子集回归
- (1)算法思想
- (2)数据集情况
- (3)代码部分
- (4)输出结果
- 4、后退法
- (1)算法思想
- (2)数据集情况
- (3)代码部分
- (4)结果展示
- 5、逐步回归
- (1)算法思想
- (2)数据集情况
- (3)代码部分
- (4)结果展示
1、为什么需要自变量选择?
一个好的回归模型,不是自变量个数越多越好。在建立回归模型的时候,选择自变量的基本指导思想是少而精。丢弃了一些对因变量y有影响的自变量后,所付出的代价就是估计量产生了有偏性,但是预测偏差的方差会下降。因此,自变量的选择有重要的实际意义。
2、自变量选择的几个准则
(1)自由度调整复决定系数达到最大
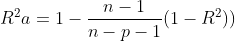

(2)赤池信息量AIC达到最小
3、所有子集回归
(1)算法思想
所谓所有子集回归,就是将总的自变量的所有子集进行考虑,查看哪一个子集是最优解。
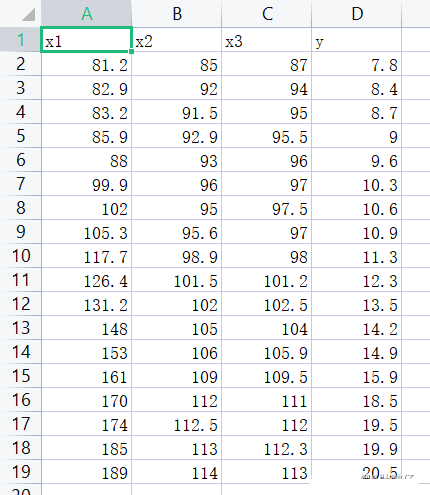
(2)数据集情况
(3)代码部分
import pandas as pd
import numpy as np
import statsmodels.api as sm
import statsmodels.formula.api as smf
from itertools import combinations
def allziji(df):
list1 = [1,2,3]
n = 18
R2 = []
names = []
#找到所有子集,并依次循环
for a in range(len(list1)+1):
for b in combinations(list1,a+1):
p = len(list(b))
data1 = pd.concat([df.iloc[:,i-1] for i in list(b) ],axis = 1)#结合所需因子
name = "y~"+("+".join(data1.columns))#组成公式
data = pd.concat([df['y'],data1],axis=1)#结合自变量和因变量
result = smf.ols(name,data=data).fit()#建模
#计算R2a
r2 = (n-1)/(n-p-1)
r2 = r2 * (1-result.rsquared**2)
r2 = 1 - r2
R2.append(r2)
names.append(name)
finall = {"公式":names, "R2a":R2}
data = pd.DataFrame(finall)
print("""根据自由度调整复决定系数准则得到:
最优子集回归模型为:{};
其R2a值为:{}""".format(data.iloc[data['R2a'].argmax(),0],data.iloc[data['R2a'].argmax(),1]))
result = smf.ols(name,data=df).fit()#建模
print()
print(result.summary())
df = pd.read_csv("data5.csv")
allziji(df)
(4)输出结果

4、后退法
(1)算法思想
后退法与前进法相反,通常先用全部m个变量建立一个回归方程,然后计算在剔除任意一个变量后回归方程所对应的AIC统计量的值,选出最小的AIC值所对应的需要剔除的变量,不妨记作x1;然后,建立剔除变量x1后因变量y对剩余m-1个变量的回归方程,计算在该回归方程中再任意剔除一个变量后所得回归方程的AIC值,选出最小的AIC值并确定应该剔除的变量;依此类推,直至回归方程中剩余的p个变量中再任意剔除一个 AIC值都会增加,此时已经没有可以继续剔除的自变量,因此包含这p个变量的回归方程就是最终确定的方程。
(2)数据集情况

(3)代码部分
import pandas as pd
import numpy as np
import statsmodels.api as sm
import statsmodels.formula.api as smf
def backward(df):
all_bianliang = [i for i in range(0,9)]#备退因子
ceshi = [i for i in range(0,9)]#存放加入单个因子后的模型
zhengshi = [i for i in range(0,9)]#收集确定因子
data1 = pd.concat([df.iloc[:,i+1] for i in ceshi ],axis = 1)#结合所需因子
name = 'y~'+'+'.join(data1.columns)
result = smf.ols(name,data=df).fit()#建模
c0 = result.aic #最小aic
delete = []#已删元素
while(all_bianliang):
aic = []#存放aic
for i in all_bianliang:
ceshi = [i for i in zhengshi]
ceshi.remove(i)
data1 = pd.concat([df.iloc[:,i+1] for i in ceshi ],axis = 1)#结合所需因子
name = "y~"+("+".join(data1.columns))#组成公式
data = pd.concat([df['y'],data1],axis=1)#结合自变量和因变量
result = smf.ols(name,data=data).fit()#建模
aic.append(result.aic)#将所有aic存入
if min(aic)>c0:#aic已经达到最小
data1 = pd.concat([df.iloc[:,i+1] for i in zhengshi ],axis = 1)#结合所需因子
name = "y~"+("+".join(data1.columns))#组成公式
break
else:
zhengshi.remove(all_bianliang[aic.index(min(aic))])#查找最小的aic并将最小的因子存入正式的模型列表当中
c0 = min(aic)
delete.append(aic.index(min(aic)))
all_bianliang.remove(all_bianliang[delete[-1]])#删除已删因子
name = "y~"+("+".join(data1.columns))#组成公式
print("最优模型为:{},其aic为:{}".format(name,c0))
result = smf.ols(name,data=df).fit()#建模
print()
print(result.summary())
df = pd.read_csv("data3.1.csv",encoding='gbk')
backward(df)
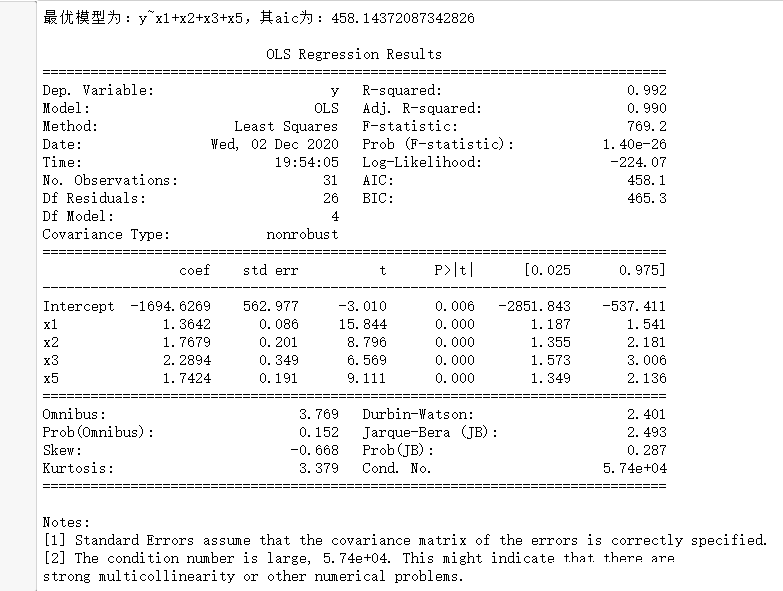
(4)结果展示
5、逐步回归
(1)算法思想
逐步回归的基本思想是有进有出。R语言中step()函数的具体做法是在给定了包含p个变量的初始模型后,计算初始模型的AIC值,并在此模型基础上分别剔除p个变量和添加剩余m-p个变量中的任一变量后的AIC值,然后选择最小的AIC值决定是否添加新变量或剔除已存在初始模型中的变量。如此反复进行,直至既不添加新变量也不剔除模型中已有的变量时所对应的AIC值最小,即可停止计算,并返回最终结果。
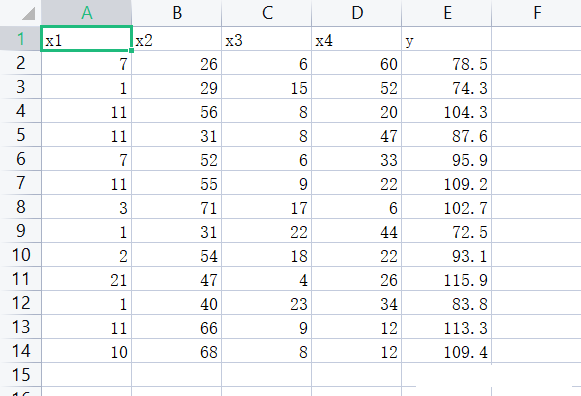
(2)数据集情况
(3)代码部分
import pandas as pd
import numpy as np
import statsmodels.api as sm
import statsmodels.formula.api as smf
def zhubuhuigui(df):
forward = [i for i in range(0,4)]#备选因子
backward = []#备退因子
ceshi = []#存放加入单个因子后的模型
zhengshi = []#收集确定因子
delete = []#被删因子
while forward:
forward_aic = []#前进aic
backward_aic = []#后退aic
for i in forward:
ceshi = [j for j in zhengshi]
ceshi.append(i)
data1 = pd.concat([df.iloc[:,i] for i in ceshi ],axis = 1)#结合所需因子
name = "y~"+("+".join(data1.columns))#组成公式
data = pd.concat([df['y'],data1],axis=1)#结合自变量和因变量
result = smf.ols(name,data=data).fit()#建模
forward_aic.append(result.aic)#将所有aic存入
for i in backward:
if (len(backward)==1):
pass
else:
ceshi = [j for j in zhengshi]
ceshi.remove(i)
data1 = pd.concat([df.iloc[:,i] for i in ceshi ],axis = 1)#结合所需因子
name = "y~"+("+".join(data1.columns))#组成公式
data = pd.concat([df['y'],data1],axis=1)#结合自变量和因变量
result = smf.ols(name,data=data).fit()#建模
backward_aic.append(result.aic)#将所有aic存入
if backward_aic:
if forward_aic:
c0 = min(min(backward_aic),min(forward_aic))
else:
c0 = min(backward_aic)
else:
c0 = min(forward_aic)
if c0 in backward_aic:
zhengshi.remove(backward[backward_aic.index(c0)])
delete.append(backward_aic.index(c0))
backward.remove(backward[delete[-1]])#删除已删因子
forward.append(backward[delete[-1]])
else:
zhengshi.append(forward[forward_aic.index(c0)])#查找最小的aic并将最小的因子存入正式的模型列表当中
forward.remove(zhengshi[-1])#删除已有因子
backward.append(zhengshi[-1])
name = "y~"+("+".join(data1.columns))#组成公式
print("最优模型为:{},其aic为:{}".format(name,c0))
result = smf.ols(name,data=data).fit()#建模
print()
print(result.summary())
df = pd.read_csv("data5.5.csv",encoding='gbk')
zhubuhuigui(df)
(4)结果展示

相关推荐
-
Python实现求一个集合所有子集的示例
方法一:回归实现 def PowerSetsRecursive(items): """Use recursive call to return all subsets of items, include empty set""" if len(items) == 0: #if the lsit is empty, return the empty list return [[]] subsets = [] first_elt = items[0]
-
Python编程实现从字典中提取子集的方法分析
本文实例讲述了Python编程实现从字典中提取子集的方法.分享给大家供大家参考,具体如下: 首先我们会想到使用字典推导式(dictionary comprehension)来解决这个问题,例如以下场景: prices={'ACME':45.23,'APPLE':666,'IBM':343,'HPQ':33,'FB':10} #选出价格大于 200 的 gt200={key:value for key,value in prices.items() if value > 200} print(gt
-

Python基于回溯法子集树模板解决野人与传教士问题示例
本文实例讲述了Python基于回溯法子集树模板解决野人与传教士问题.分享给大家供大家参考,具体如下: 问题 在河的左岸有N个传教士.N个野人和一条船,传教士们想用这条船把所有人都运过河去,但有以下条件限制: (1)修道士和野人都会划船,但船每次最多只能运M个人: (2)在任何岸边以及船上,野人数目都不能超过修道士,否则修道士会被野人吃掉. 假定野人会服从任何一种过河安排,请规划出一个确保修道士安全过河的计划. 分析 百度一下,网上全是用左岸的传教士和野人人数以及船的位置这样一个三元组作为状态,进
-
Python判断两个list是否是父子集关系的实例
list1 和list2 两个list , 想要得到list1是不是包含 list2 (是不是其子集 ) a = [1,2] b = [1,2,3] c = [0, 1] set(b) > set(a) set(b) > set(c) 返回 True False 以上这篇Python判断两个list是否是父子集关系的实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们. 您可能感兴趣的文章: Python求两个list的差集.交集与并集的方法 Python中类型关系
-
python判断一个集合是否为另一个集合的子集方法
实例如下所示: a = [1,2,3,4] b = set([1,2]) b.issubset(a) 以上这篇python判断一个集合是否为另一个集合的子集方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们. 您可能感兴趣的文章: python判断一个集合是否包含了另外一个集合中所有项的方法 深入解析Python中的集合类型操作符
-
如何基于python生成list的所有的子集
这篇文章主要介绍了如何基于python生成list的所有的子集,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 不使用递归且不引入标准库,单纯用两个for循环即可得出一个list的所有子集 L = [1, 2, 3, 4] List = [[]] for i in range(len(L)): # 定长 for j in range(len(List)): # 变长 sub_List = List[j] + [L[i]] if sub_List
-
python的自变量选择(所有子集回归,后退法,逐步回归)
目录 1.为什么需要自变量选择? 2.自变量选择的几个准则 (1)自由度调整复决定系数达到最大 (2)赤池信息量AIC达到最小 3.所有子集回归 (1)算法思想 (2)数据集情况 (3)代码部分 (4)输出结果 4.后退法 (1)算法思想 (2)数据集情况 (3)代码部分 (4)结果展示 5.逐步回归 (1)算法思想 (2)数据集情况 (3)代码部分 (4)结果展示 1.为什么需要自变量选择? 一个好的回归模型,不是自变量个数越多越好.在建立回归模型的时候,选择自变量的基本指导思想是少而精.丢弃
-
python sklearn库实现简单逻辑回归的实例代码
Sklearn简介 Scikit-learn(sklearn)是机器学习中常用的第三方模块,对常用的机器学习方法进行了封装,包括回归(Regression).降维(Dimensionality Reduction).分类(Classfication).聚类(Clustering)等方法.当我们面临机器学习问题时,便可根据下图来选择相应的方法. Sklearn具有以下特点: 简单高效的数据挖掘和数据分析工具 让每个人能够在复杂环境中重复使用 建立NumPy.Scipy.MatPlotLib之上 代
-
Python使用sklearn实现的各种回归算法示例
本文实例讲述了Python使用sklearn实现的各种回归算法.分享给大家供大家参考,具体如下: 使用sklearn做各种回归 基本回归:线性.决策树.SVM.KNN 集成方法:随机森林.Adaboost.GradientBoosting.Bagging.ExtraTrees 1. 数据准备 为了实验用,我自己写了一个二元函数,y=0.5*np.sin(x1)+ 0.5*np.cos(x2)+0.1*x1+3.其中x1的取值范围是0~50,x2的取值范围是-10~10,x1和x2的训练集一共有5
-
python机器学习基础线性回归与岭回归算法详解
目录 一.什么是线性回归 1.线性回归简述 2.数组和矩阵 数组 矩阵 3.线性回归的算法 二.权重的求解 1.正规方程 2.梯度下降 三.线性回归案例 1.案例概述 2.数据获取 3.数据分割 4.数据标准化 5.模型训练 6.回归性能评估 7.梯度下降与正规方程区别 四.岭回归Ridge 1.过拟合与欠拟合 2.正则化 一.什么是线性回归 1.线性回归简述 线性回归,是一种趋势,通过这个趋势,我们能预测所需要得到的大致目标值.线性关系在二维中是直线关系,三维中是平面关系. 我们可以使用如下模
-
python神经网络学习使用Keras进行回归运算
目录 学习前言 什么是Keras Keras中基础的重要函数 1.Sequential 2.Dense 3.model.compile 全部代码 学习前言 看了好多Github,用于保存模型的库都是Keras,我觉得还是好好学习一下的好 什么是Keras Keras是一个由Python编写的开源人工神经网络库,可以作Tensorflow.Microsoft-CNTK和Theano的高阶应用程序接口,进行深度学习模型的设计.调试.评估.应用和可视化. Keras相当于比Tensorflow和The
-
python实现梯度下降求解逻辑回归
本文实例为大家分享了python实现梯度下降求解逻辑回归的具体代码,供大家参考,具体内容如下 对比线性回归理解逻辑回归,主要包含回归函数,似然函数,梯度下降求解及代码实现 线性回归 1.线性回归函数 似然函数的定义:给定联合样本值X下关于(未知)参数 的函数 似然函数:什么样的参数跟我们的数据组合后恰好是真实值 2.线性回归似然函数 对数似然: 3.线性回归目标函数 (误差的表达式,我们的目的就是使得真实值与预测值之前的误差最小) (导数为0取得极值,得到函数的参数) 逻辑回归 逻辑回归是在线性
-
Python中条件选择和循环语句使用方法介绍
同C语言.Java一样,Python中也存在条件选择和循环语句,其风格和C语言.java的很类似,但是在写法和用法上还是有一些区别.今天就让我们一起来了解一下. 一.条件选择语句 Python中条件选择语句的关键字为:if .elif .else这三个.其基本形式如下: 复制代码 代码如下: if condition: block elif condition: block ... else block 其中elif和else语句块是可选的.对于if和elif只有condition为True时,
-
Python实现的选择排序算法原理与用法实例分析
本文实例讲述了Python实现的选择排序算法.分享给大家供大家参考,具体如下: 选择排序(Selection sort)是一种简单直观的排序算法.它的工作原理是每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排完. 比如在一个长度为N的无序数组中,在第一趟遍历N个数据,找出其中最小的数值与第一个元素交换,第二趟遍历剩下的N-1个数据,找出其中最小的数值与第二个元素交换......第N-1趟遍历剩下的2个数据,找出其中最小的数值与第N-1个元素
-
Python实现的选择排序算法示例
本文实例讲述了Python实现的选择排序算法.分享给大家供大家参考,具体如下: 选择排序(Selection sort)是一种简单直观的排序算法.它的工作原理是每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排完. 选择排序每次只记录最大数的索引值. 类似于冒泡排序, 也是要比较n-1次, 区别是冒泡排序每次都交换, 选择排序只在最后比较完后才进行交换 示例代码: #!/usr/bin/env python # coding:utf-8 de
-
Python语言描述机器学习之Logistic回归算法
本文介绍机器学习中的Logistic回归算法,我们使用这个算法来给数据进行分类.Logistic回归算法同样是需要通过样本空间学习的监督学习算法,并且适用于数值型和标称型数据,例如,我们需要根据输入数据的特征值(数值型)的大小来判断数据是某种分类或者不是某种分类. 一.样本数据 在我们的例子中,我们有这样一些样本数据: 样本数据有3个特征值:X0X0,X1X1,X2X2 我们通过这3个特征值中的X1X1和X2X2来判断数据是否符合要求,即符合要求的为1,不符合要求的为0. 样本数据分类存放在一个