python利用 pytesseract快速识别提取图片中的文字((图片识别)
目录
- 前言
- 一、配置环境
- 1. 安装python依赖
- 2. 安装识别引擎
- 二、使用步骤
- 1.引入库
- 2.提取图片文字
- 3.运行效果
- 总结

提示:本文多图,请手机端注意流量。
前言
利用python做图片识别,识别提取图片中的文字会有很多方法,但是想要简单一点怎么办,那就可以使用tesseract识别引擎来实现,一行代码就可以做到提取图片文本。
一、配置环境
1. 安装python依赖
本程序用到了两个python库,pytesseract和PIL,所以先来安装。
运行以下命令
pip install Pillow pip install pytesseract
如果在python中没有报错,说明程序安装成功,

2. 安装识别引擎
安装完以上两个依赖还需要对应的识别引擎。点击去下载
咱们直接使用5月10号构建的最新版本。
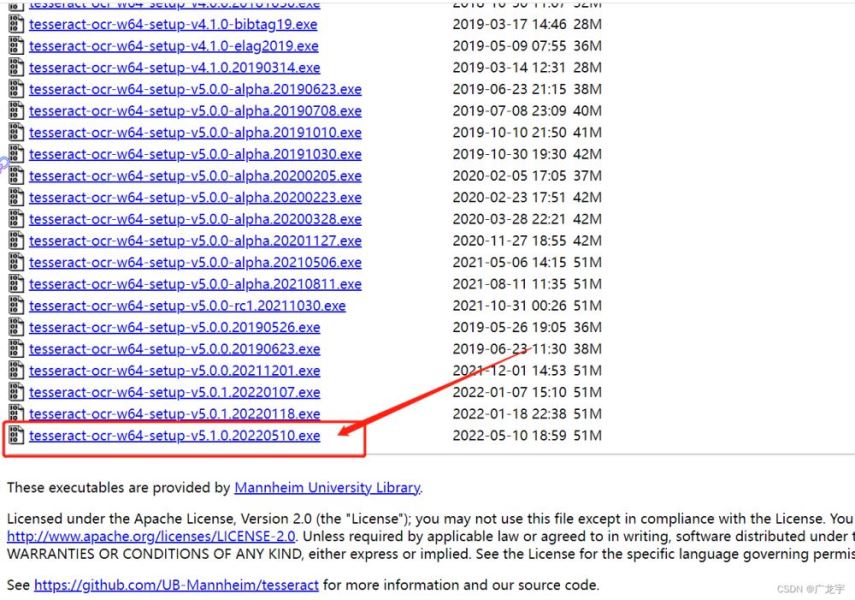
安装tesseract识别引擎(可跳过)
下载完成后打开程序进行安装,先选择语言,这里选择英语English就行,然后点ok

接下来就是next,完了点击I Agree同意协议,
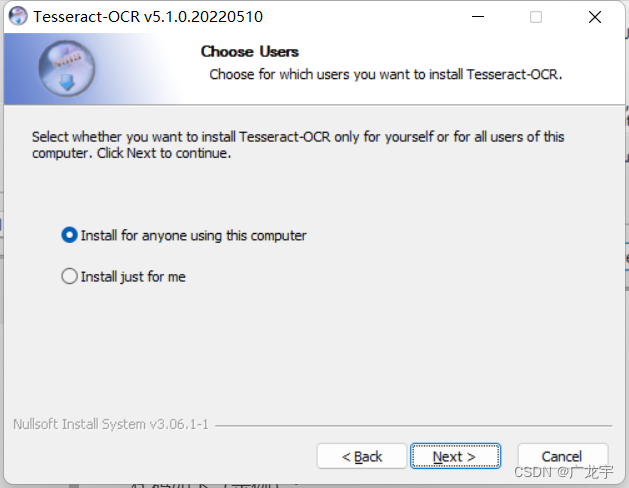
为所有用户安装,然后点next,如图,
接下来安装中文的语言包用来识别中文,需要滑到下面,选择中文,我这里横排简体中文和竖排简体中文都选择了,完成后点击next,
选择安装路径,建议安装到C盘以外,然后点击next
这里点击安装install,

等待安装完成
安装完成后,点击next,再点击finish完成安装,
验证是否安装成功
添加环境变量,就是你安装到的那个文件夹路径,直接加到path里面,
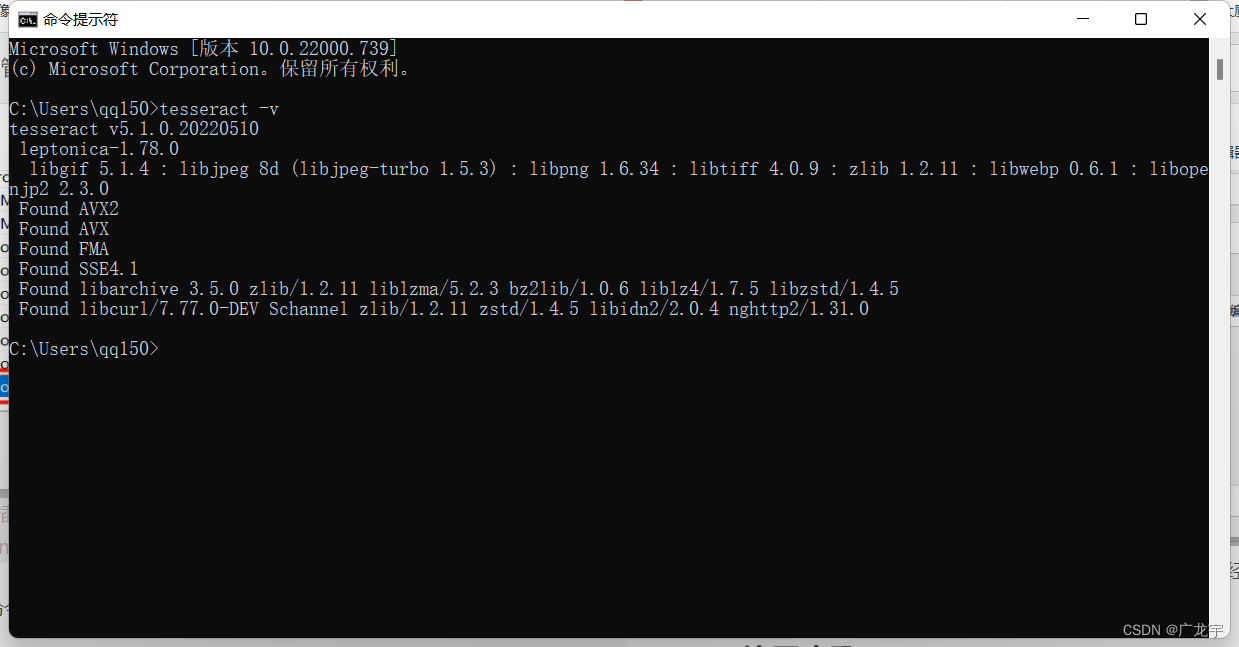
然后在命令行运行tesseract -v,如果和下图一样,说明你已经安装成功了,
二、使用步骤
1.引入库
from PIL import Image import pytesseract
2.提取图片文字
将读取图片的一行代码封装为一个函数,
def read_image(name):
print(pytesseract.image_to_string(Image.open(name), lang='chi_sim'))
在main函数中直接调用即可,
def main():
read_image('1657158527412.jpg')
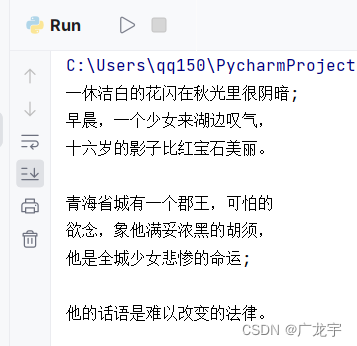
3.运行效果
以以下图片为例,

运行效果如下,
总结
本文介绍了tesseract的python调用,也就是pytesseract库,其中还有一些其他的内容并没有涉及,仅涉及到了图片提取文字,如果你对其感兴趣,可以深入探索一下,也希望能和我探讨一下。
完整代码
from PIL import Image
import pytesseract
def read_image(name):
print(pytesseract.image_to_string(Image.open(name), lang='chi_sim'))
def main():
read_image('img.png')
if __name__ == '__main__':
main()
到此这篇关于python利用 pytesseract快速识别提取图片中的文字( 图片识别)的文章就介绍到这了,更多相关python pytesseract识别图片文字内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python基于内置库pytesseract实现图片验证码识别功能
这篇文章主要介绍了Python基于内置库pytesseract实现图片验证码识别功能,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 环境准备: 1.安装Tesseract模块 git文档地址:https://digi.bib.uni-mannheim.de/tesseract/ 下载后就是一个exe安装包,直接右击安装即可,安装完成之后,配置一下环境变量,编辑 系统变量里面 path,添加下面的安装路径: 2.如果您想使用其他语言,请下载相应的
-
Python通过pytesseract库实现识别图片中的文字
目录 前言 一.pytesseract 1.pytesseract是什么 2.安装pytesseract 3.查看pytesseract版本 4.安装PIL 5.查看PIL版本 二.Tesseract OCR 1.Tesseract OCR是什么 2.安装Tesseract OCR 3.安装 Tesseract OCR 语言包 三.使用方法 1.引入库 2.打开图片文件 3.使用Tesseract进行文字识别 4.输出识别结果 总结 前言 大家好,我是空空star,本篇给大家分享一下通过Pyth
-
python利用pytesseract 实现本地识别图片文字
#!/usr/bin/env python3 # -*- coding: utf-8 -*- import glob from os import path import os import pytesseract from PIL import Image from queue import Queue import threading import datetime import cv2 def convertimg(picfile, outdir): '''调整图片大小,对于过大的图片进行
-
Python3使用腾讯云文字识别(腾讯OCR)提取图片中的文字内容实例详解
百度OCR体验地址: https://ai.baidu.com/tech/imagerecognition/general 腾讯OCR体验地址: https://cloud.tencent.com/act/event/ocrdemo 测试结果是:腾讯的效果要比百度的好 腾讯云目前额度是: 每个接口 1,000次/月免费,有6个文字识别的接口,一共是6,000次/月 百度接口调用之前写过文章 python实现百度OCR图片识别过程解析 使用步骤 1.注册账号: https://cloud.tenc
-

Python利用PyPDF2快速拆分PDF文档
目录 安装PyPDF2模块 创建文件,准备PDF文档 万事俱备,准备开拆 文档的拆分思路 python拆分计算公式: 具体怎么拆? 完整拆分程序: 列表拆分法实现拆分PDF 写在最后 "人生苦短,快学Python",因为这句口号,我也加入了学习Python的浩浩大军,但由于Python真的是可以做的事情太多了,一时迷了眼,不知道自己应该去专攻哪个方向. 经过多方向试探,我还是选择了广而不深的web开发,Python的web开发自然离不开大名鼎鼎的Django,有一次突发奇想,下载了Dj
-
Python利用Rows快速操作csv文件
目录 1.准备 2.基本使用 3.命令行工具 Rows 是一个专门用于操作表格的第三方Python模块. 只要通过 Rows 读取 csv 文件,她就能生成可以被计算的 Python 对象. 相比于 pandas 的 pd.read_csv, 我认为 Rows 的优势在于其易于理解的计算语法和各种方便的导出和转换语法.它能非常方便地提取pdf中的文字.将csv转换为sqlite文件.合并csv等,还能对csv文件执行sql语法,还是比较强大的. 当然,它的影响力肯定没有 Pandas 大,不过了
-
Python利用逻辑回归模型解决MNIST手写数字识别问题详解
本文实例讲述了Python利用逻辑回归模型解决MNIST手写数字识别问题.分享给大家供大家参考,具体如下: 1.MNIST手写识别问题 MNIST手写数字识别问题:输入黑白的手写阿拉伯数字,通过机器学习判断输入的是几.可以通过TensorFLow下载MNIST手写数据集,通过import引入MNIST数据集并进行读取,会自动从网上下载所需文件. %matplotlib inline import tensorflow as tf import tensorflow.examples.tutori
-
python 利用PyAutoGUI快速构建自动化操作脚本
一.背景 大家好,我是安果! 我们经常遇到需要进行大量重复操作的时候,比如:网页上填表,对 web 版本 OA 进行操作,自动化测试或者给新系统首次添加数据等 这些操作的特点往往是:数据同构,大多是已经有了的结构化数据:操作比较呆板,都是同一个流程的点击.输入:数据量大,极大消耗操作人精力 那么能不能自动化呢? 二.自动化的方案 如果你在 web 上进行操作, Python 的 Selenium 可以满足要求.如果需要对 GUI 界面进行操作,你恐怕得试验下"按键精灵"能不能满足要求.
-
Python利用正则表达式从字符串提取数字
目录 前言 利用正则表达式从字符串提取数字 附python正则表达式抽取文本中的时间日期 总结 前言 正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配. Python 自1.5版本起增加了re 模块,它提供 Perl 风格的正则表达式模式. re 模块使 Python 语言拥有全部的正则表达式功能. 利用正则表达式从字符串提取数字 主要用到下面几个函数 (1)compile 函数根据一个模式字符串和可选的标志参数生成一个正则表达式对象.该对象拥有一系列方法用于正则
-
python利用urllib实现爬取京东网站商品图片的爬虫实例
本例程使用urlib实现的,基于python2.7版本,采用beautifulsoup进行网页分析,没有第三方库的应该安装上之后才能运行,我用的IDE是pycharm,闲话少说,直接上代码! # -*- coding: utf-8 -* import re import os import urllib import urllib2 from bs4 import BeautifulSoup def craw(url,page): html1=urllib2.urlopen(url).read(
-
如何利用Python识别图片中的文字
一.前言 不知道大家有没有遇到过这样的问题,就是在某个软件或者某个网页里面有一篇文章,你非常喜欢,但是不能复制.或者像百度文档一样,只能复制一部分,这个时候我们就会选择截图保存.但是当我们想用到里面的文字时,还是要一个字一个字打出来.那么我们能不能直接识别图片中的文字呢?答案是肯定的. 二.Tesseract 文字识别是ORC的一部分内容,ORC的意思是光学字符识别,通俗讲就是文字识别.Tesseract是一个用于文字识别的工具,我们结合Python使用可以很快的实现文字识别.但是在此之前我们需
-
如何利用Python识别图片中的文字详解
一.Tesseract 文字识别是ORC的一部分内容,ORC的意思是光学字符识别,通俗讲就是文字识别.Tesseract是一个用于文字识别的工具,我们结合Python使用可以很快的实现文字识别.但是在此之前我们需要完成一个繁琐的工作. (1)Tesseract的安装及配置 Tesseract的安装我们可以移步到该网址 https://digi.bib.uni-mannheim.de/tesseract/,我们可以看到如下界面: 有很多版本供大家选择,大家可以根据自己的需求选择.其中w32表示32