如何用python免费看美剧
最早一部《越狱》转变了我对美剧的看法。主人公scofield的聪明才智和坚强的毅力,《绝命毒师》里面主人公的中年逆袭,《纸牌屋》里面老谋深算的政客,等等,这些美剧和里面鲜活的任务,至今令人记忆尤新。
最近,又迷上了美剧,无奈多数视频平台上的美剧都是收费的。对于一个资深Pythoner,我们可以用Python自动获取美剧的网址,下载了慢慢看。

我们以天天看M剧这个网站为例,来展示如何分析和下载这些内容,这里提供一种思路供大家学习。当然,我们还是得支持正版内容,这里是介绍技术,大家勿用于非法用途哦,电影下载后请遵照网站协议及时删除。
准备网址
网址大家自己找。我们在主页搜索“危机边缘”

然后我们获得1-5季的网址内容,如下图

我们知道了1-5季的网址信息,然后,我们来看一下每一个页面的结构。
分析页面内容
我们打开第一季的页面,看下需要获取的内容,如下图:
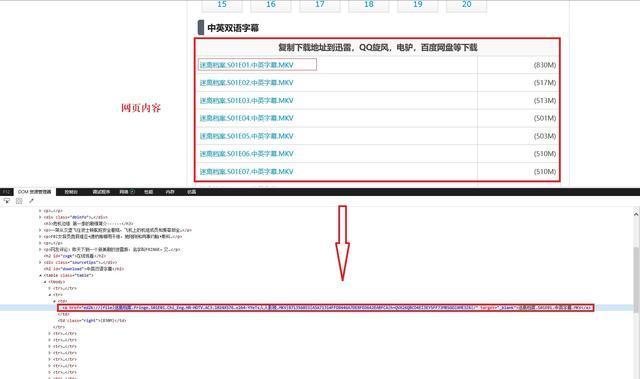
我们需要的是每一集的网址信息(上图中红色框线中的内容),通过将各个季的每一集网址内容下载下来,按季保存为txt文件,然后使用下载工具导入下载即可。
Python如何实现
我们知道,爬取信息主要使用的一些经典库。

我们这里主要使用两个经典的库requests和bs4。亲测该网站没有反爬措施,因此我们没有涉及这些内容,感兴趣的小伙伴自己学习下相关内容。
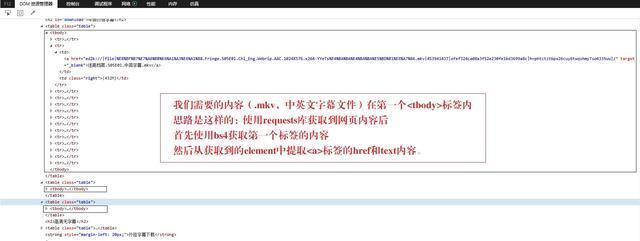
我们的一般思路是这样的,下面来看下Python实现过程。
我们定义三个函数,主要代码如下:
【获取网页内容】
def getHtml(url): return requests.get(url)
直接返回了网页的文本内容。
【获取每页网址信息】
def getInfo(html):
lst = []
bs = BeautifulSoup(html.text, 'html.parser')
urls = bs.findAll('tbody')[0]
for item in urls.findAll('a'):
lst.append((item.get("href"), item.text))
return lst
传入每一季的页面内容,以列表信息返回每一集的网址和每一集的名字。
【保存内容】
def saveInfo(name, lst):
with open('第{}季.txt'.format(name), 'w') as f:
for item in lst:
f.write(item[0] + '\n')
传入每一季的名称的该季中的每一集的网址列表,保存在本地。
做轮子
没错,简单的三步实现了我们需要的效果。下面,我们开始“造轮子”。

下面我们来看看我们实现的功能。
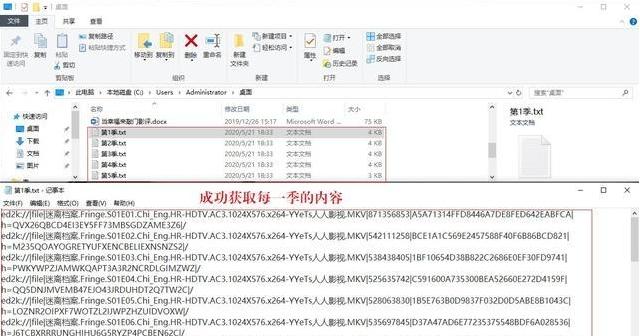
好了,我们的内容成功获取到了,然后自己下载吧!
程序扩展
聪明的小伙伴一定想到了,还有很多好看的美剧呢,我们如何下载其它的内容呢?
如何下载其它视频呢?
过程同上,先到主页搜索,然后更改我们的url_list列表,执行程序即可!接触过前端的小伙伴肯定知道,每个网站的结构基本是相同的,我们这样的方法在天天看M剧的主页上应该是通用的。感兴趣的小伙伴自己下载看看咯。
到此这篇关于如何用python免费看美剧的文章就介绍到这了,更多相关Python看美剧的方法内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
如何用python免费看美剧
最早一部<越狱>转变了我对美剧的看法.主人公scofield的聪明才智和坚强的毅力,<绝命毒师>里面主人公的中年逆袭,<纸牌屋>里面老谋深算的政客,等等,这些美剧和里面鲜活的任务,至今令人记忆尤新. 最近,又迷上了美剧,无奈多数视频平台上的美剧都是收费的.对于一个资深Pythoner,我们可以用Python自动获取美剧的网址,下载了慢慢看. 我们以天天看M剧这个网站为例,来展示如何分析和下载这些内容,这里提供一种思路供大家学习.当然,我们还是得支持正版内容,这里是介绍技
-
Python+PyQt5实现美剧爬虫可视工具的方法
美剧<权力的游戏>终于要开播最后一季了,作为马丁老爷子的忠实粉丝,为了能够看得懂第八季复杂庞大的剧情架构,本人想着将前几季再稳固一下,所以就上美剧天堂下载来看,可是每次都上去下载太麻烦了,于是干脆自己写个爬虫爬下来得了. 话不多说,先上图片. 本人才疏学浅,就写了个简单的可视化软件,关键是功能实现就行了嘛. 实现语言:Python ,版本 3.7.1 实现思路:首先运用 Python 工具爬取到数据再实现图形化软件. 由于这里只是实现简单的爬取数据,并没有牵扯到 cookie 之类的敏感信息,
-

Python爬虫爬取美剧网站的实现代码
一直有爱看美剧的习惯,一方面锻炼一下英语听力,一方面打发一下时间.之前是能在视频网站上面在线看的,可是自从广电总局的限制令之后,进口的美剧英剧等貌似就不在像以前一样同步更新了.但是,作为一个宅diao的我又怎甘心没剧追呢,所以网上随便查了一下就找到一个能用迅雷下载的美剧下载网站[天天美剧],各种资源随便下载,最近迷上的BBC的高清纪录片,大自然美得不要不要的. 虽说找到了资源网站可以下载了,但是每次都要打开浏览器,输入网址,找到该美剧,然后点击链接才能下载.时间长了就觉得过程好繁琐,而且有时候网
-
看看如何用Python绘制小米新版天价logo
最终呈现效果 哈哈,咋们在讲述之前,首先看看最终呈现的效果吧,整体来说还是很不错的. 小米 "新" logo背后的数学 前段时间,小米公司发布了一条微博,引发了热议,原来小米换了新logo了. 很多人,都觉得雷总被骗了.说实话,我当时猛的一看,也是很蒙蔽,可能咋们不懂美学,不懂新logo背后蕴藏的文化底蕴吧! 但是,原设计者原研哉说到:最新设计的小米logo,融入了东方哲学的思考,从而提出了一个具有「超椭圆」数学之美的小米新 LOGO,同时还增加了黑色和科技银来作为小米品牌色彩的新搭档
-
如何用Python来搭建一个简单的推荐系统
在这篇文章中,我们会介绍如何用Python来搭建一个简单的推荐系统. 本文使用的数据集是MovieLens数据集,该数据集由明尼苏达大学的Grouplens研究小组整理.它包含1,10和2亿个评级. Movielens还有一个网站,我们可以注册,撰写评论并获得电影推荐.接下来我们就开始实战演练. 在这篇文章中,我们会使用Movielens构建一个基于item的简易的推荐系统.在开始前,第一件事就是导入pandas和numPy. import pandas as pd import numpy a
-
如何用python处理excel表格
openpyxl是一个第三方库,可以处理xlsx格式的Excel文件.pip install openpyxl安装. 读取Excel文件 需要导入相关函数 from openpyxl import load_workbook # 默认可读写,若有需要可以指定write_only和read_only为True wb = load_workbook('pythontab.xlsx') 默认打开的文件为可读写,若有需要可以指定参数read_only为True. 获取工作表--Sheet # 获得所有s
-
如何用python批量调整视频声音
今天来研究python中moviepy模块的用途 近来有大量处理视频的需求, 常会碰到一个问题是下载的视频音量过小, 会需要将它调大声, 虽然有在线工具VideoLouder可以免费调整视频音量大小, 但毕竟若量很大的话一个一个上传视频也是挺麻烦的事情, 因此决定再用程序帮忙解决. 使用教学 基础程序 调整一个视频音量的代码如下: from moviepy.editor import VideoFileClip,concatenate_videoclips clip = VideoFileCli
-
如何用python 操作zookeeper
ZooKeeper 简介 ZooKeeper 是一个分布式的.开放源码的分布式应用程序协调服务,是 Google 的 Chubby 一个开源的实现,是 Hadoop 和 Hbase 的重要组件.它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护.域名服务.分布式同步.组服务等.ZooKeeper 支持大部分开发语言,除了某些特定的功能只支持 Java 和 C.python 通过 kazoo 可以实现操作 ZooKeeper . 一.安装 这个简单,使用 pip 命令安装 pip3
-
如何用 Python 处理不平衡数据集
1. 什么是数据不平衡 所谓的数据不平衡(imbalanced data)是指数据集中各个类别的数量分布不均衡:不平衡数据在现实任务中十分的常见.如 信用卡欺诈数据:99%都是正常的数据, 1%是欺诈数据 贷款逾期数据 不平衡数据一般是由于数据产生的原因导致的,类别少的样本通常是发生的频率低,需要很长的周期进行采集. 在机器学习任务(如分类问题)中,不平衡数据会导致训练的模型预测的结果会偏向于样本数量多的类别,这个时候除了要选择合适的评估指标外,想要提升模型的性能,就要对数据和模型做一些预处理.
-
如何用python实现一个HTTP连接池
一. 连接池的原理 首先, HTTP连接是基于TCP连接的, 与服务器之间进行HTTP通信, 本质就是与服务器之间建立了TCP连接后, 相互收发基于HTTP协议的数据包. 因此, 如果我们需要频繁地去请求某个服务器的资源, 我们就可以一直维持与个服务器的TCP连接不断开, 然后在需要请求资源的时候, 把连接拿出来用就行了. 一个项目可能需要与服务器之间同时保持多个连接, 比如一个爬虫项目, 有的线程需要请求服务器的网页资源, 有的线程需要请求服务器的图片等资源, 而这些请求都可以建立在同一条TC