java贪心算法初学感悟图解及示例分享
算法简介
1)贪心算法是指在对问题进行求解时,在每一步选择中都采取最好或者最优(即最有利)的选择,从而希望能够导致是最好或者最优的算法
2)贪心算法所得到的结果不一定是最优的结果(有时候会是最优解),但是都是相对近似(接近)最优解的结果。
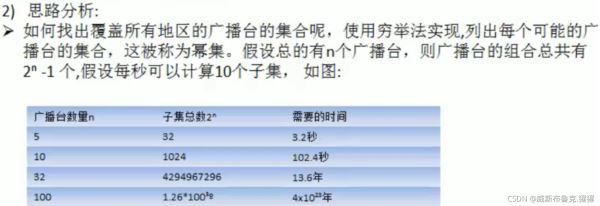
应用场景 --> 集合覆盖


public class GreedyAlgorithm {
public static void main(String[] args) {
// 创建广播电台,放入到Map
HashMap<String, HashSet<String>> broadcasts = new HashMap<String, HashSet<String>>();
// 将各个电台放入到broadcasts
HashSet<String> hashSet1 = new HashSet<String>();
hashSet1.add("北京");
hashSet1.add("上海");
hashSet1.add("天津");
HashSet<String> hashSet2 = new HashSet<String>();
hashSet2.add("广州");
hashSet2.add("上海");
hashSet2.add("天津");
HashSet<String> hashSet3 = new HashSet<String>();
hashSet3.add("成都");
hashSet3.add("上海");
hashSet3.add("杭州");
HashSet<String> hashSet4 = new HashSet<String>();
hashSet4.add("上海");
hashSet4.add("天津");
HashSet<String> hashSet5 = new HashSet<String>();
hashSet5.add("杭州");
hashSet5.add("大连");
// 加入到map
broadcasts.put("K1", hashSet1);
broadcasts.put("K2", hashSet2);
broadcasts.put("K3", hashSet3);
broadcasts.put("K4", hashSet4);
broadcasts.put("K5", hashSet5);
// allAreas,存放所有的地区
HashSet<String> allAreas = new HashSet<String>();
allAreas.add("北京");
allAreas.add("上海");
allAreas.add("天津");
allAreas.add("广州");
allAreas.add("深圳");
allAreas.add("成都");
allAreas.add("杭州");
allAreas.add("大连");
// 创建ArrayList,存放选择的电台集合
ArrayList<String> selects = new ArrayList<String>();
// 定义一个临时的集合,在遍历的过程中,存放遍历过程中的电台覆盖的地区和当前还没有覆盖的地区的交集
HashSet<String> tempSet = new HashSet<String>();
// 定义一个maxKey,保存在一次遍历过程中,能够覆盖最多未覆盖的地区对应的电台的key
// 如果maxKey不为null,则会加入到selects
String maxKey = null;
while (allAreas.size() != 0) {// 如果allAreas不为0,则表示还没有覆盖到所有的地区
// 每进行一次while,需要将maxKey置空
maxKey = null;
// 遍历broadcasts,取出对应key
for (String key : broadcasts.keySet()) {
// 每进行一次for
tempSet.clear();
// 当前这个key能够覆盖的地区
HashSet<String> areas = broadcasts.get(key);
tempSet.addAll(areas);
// 求出tempSet 和 allAreas集合的交集,交集会赋给tempSet
tempSet.retainAll(allAreas);// retainAll方法的作用就是求交集
// 如果当前这个集合包含的未覆盖地区的数量,比maxKey指向的集合地区还多
// 就需要重置maxKey
// tempSet.size() > broadcasts.get(maxKey).size()) 体现出贪心算法的特点,每次都选择最优的
if (tempSet.size() > 0 && (maxKey == null || tempSet.size() > broadcasts.get(maxKey).size())) {
maxKey = key;
}
}
// maxKey != null,就应该将maxKey加入selects
if (maxKey != null) {
selects.add(maxKey);
// 将maxKey指向的广播电台覆盖的地区,从allAreas去掉
allAreas.removeAll(broadcasts.get(maxKey));
}
}
System.out.println("得到的选择结果是" + selects);
}
}
以上就是java贪心算法初学感悟图解及示例分享的详细内容,更多关于java贪心算法的资料请关注我们其它相关文章!
相关推荐
-

二叉树递归迭代及morris层序前中后序遍历详解
目录 分析二叉树的前序,中序,后序的遍历步骤 1.层序遍历 方法一:广度优先搜索 方法二:递归 2.前序遍历 3.中序遍历 4.后序遍历 递归解法 前序遍历--递归 迭代解法 前序遍历--迭代 核心思想: 三种迭代解法的总结: Morris遍历 morris--前序遍历 morris--中序遍历 morris--后序遍历: 分析二叉树的前序,中序,后序的遍历步骤 1.层序遍历 方法一:广度优先搜索 (以下解释来自leetcode官方题解) 我们可以用广度优先搜索解决这个问题. 我们可以想到最
-
java图论弗洛伊德和迪杰斯特拉算法解决最短路径问题
目录 弗洛伊德算法 算法介绍 算法图解分析 迪杰斯特拉算法 算法介绍 算法过程 弗洛伊德算法 算法介绍 算法图解分析 第一轮循环中,以A(下标为:0)作为中间顶点 [即把作为中间顶点的所有情况都进行遍历,就会得到更新距离表和前驱关系],距离表和前驱关系更新为: 弗洛伊德算法和迪杰斯特拉算法的最大区别是: 弗洛伊德算法是从各个顶点出发,求最短路径: 迪杰斯特拉算法是从某个顶点开始,求最短路径. /** * 弗洛伊德算法 * 容易理解,容易实现 */ public void floyd
-
java暴力匹配及KMP算法解决字符串匹配问题示例详解
目录 要解决的问题? 一.暴力匹配算法 一个图例介绍KMP算法 二.KMP算法 算法介绍 一个图例介绍KMP算法 代码实现 要解决的问题? 一.暴力匹配算法 一个图例介绍KMP算法 String str1 = "BBC ABCDAB ABCDABCDABDE"; String str2 = "ABCDABD"; 1. S[0]为B,P[0]为A,不匹配,执行第②条指令:"如果失配(即S[i]! = P[j]),令i = i - (j - 1),
-
Java数据结构彻底理解关于KMP算法
大家好,前面的有一篇文章讲了子序列和全排列问题,今天我们再来看一个比较有难度的问题.那就是大名鼎鼎的KMP算法. 本期文章源码:GitHub源码 简介 KMP算法是一种改进的字符串匹配算法,由D.E.Knuth,J.H.Morris和V.R.Pratt提出的,因此人们称它为克努特-莫里斯-普拉特操作(简称KMP算法).KMP算法的核心是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的.具体实现就是通过一个next()函数实现,函数本身包含了模式串的局部匹配信息.KMP算法
-
java图论普利姆及克鲁斯卡算法解决最小生成树问题详解
目录 什么是最小生成树? 普利姆算法 算法介绍 应用 --> 修路问题 图解分析 克鲁斯卡尔算法 算法介绍 应用场景 -- 公交站问题 算法图解 算法分析 如何判断是否构成回路 什么是最小生成树? 最小生成树(Minimum Cost Spanning Tree),简称MST. 最小生成树要求图是连通图.连通图指图中任意两个顶点都有路径相通,通常指无向图.理论上如果图是有向.多重边的,也能求最小生成树,只是不太常见. 普利姆算法 算法介绍 应用 --> 修路问题 图解分析
-
java数据结构图论霍夫曼树及其编码示例详解
目录 霍夫曼树 一.基本介绍 二.霍夫曼树几个重要概念和举例说明 构成霍夫曼树的步骤 霍夫曼编码 一.基本介绍 二.原理剖析 注意: 霍夫曼编码压缩文件注意事项 霍夫曼树 一.基本介绍 二.霍夫曼树几个重要概念和举例说明 构成霍夫曼树的步骤 举例:以arr = {1 3 6 7 8 13 29} public class HuffmanTree { public static void main(String[] args) { int[] arr = { 13, 7, 8
-
java 中模式匹配算法-KMP算法实例详解
java 中模式匹配算法-KMP算法实例详解 朴素模式匹配算法的最大问题就是太低效了.于是三位前辈发表了一种KMP算法,其中三个字母分别是这三个人名的首字母大写. 简单的说,KMP算法的对于主串的当前位置不回溯.也就是说,如果主串某次比较时,当前下标为i,i之前的字符和子串对应的字符匹配,那么不要再像朴素算法那样将主串的下标回溯,比如主串为"abcababcabcabcabcabc",子串为"abcabx".第一次匹配的时候,主串1,2,3,4,5字符都和子串相应的
-
java贪心算法初学感悟图解及示例分享
算法简介 1)贪心算法是指在对问题进行求解时,在每一步选择中都采取最好或者最优(即最有利)的选择,从而希望能够导致是最好或者最优的算法 2)贪心算法所得到的结果不一定是最优的结果(有时候会是最优解),但是都是相对近似(接近)最优解的结果. 应用场景 --> 集合覆盖 public class GreedyAlgorithm { public static void main(String[] args) { // 创建广播电台,放入到Map HashMap<String, HashSet<
-
Java使用贪心算法解决电台覆盖问题(示例详解)
java使用贪心算法解决电台覆盖问题 代码实现 /** * 贪心算法实现集合覆盖 */ public class Demo { public static void main(String[] args) { // 创建电台和地区集合 HashMap<String, HashSet<String>> broadcasts = new HashMap<>(); // 创建各个电台 HashSet<String> k1 = new HashSet<>
-
Java贪心算法之Prime算法原理与实现方法详解
本文实例讲述了Java贪心算法之Prime算法原理与实现方法.分享给大家供大家参考,具体如下: Prime算法:是一种穷举查找算法来从一个连通图中构造一棵最小生成树.利用始终找到与当前树中节点权重最小的边,找到节点,加到最小生成树的节点集合中,直至所有节点都包括其中,这样就构成了一棵最小生成树.prime在算法中属于贪心算法的一种,贪心算法还有:Kruskal.Dijkstra以及哈夫曼树及编码算法. 下面具体讲一下prime算法: 1.首先需要构造一颗最小生成树,以及两个节点之间的权重数组,在
-
JS使用贪心算法解决找零问题示例
本文实例讲述了JS使用贪心算法解决找零问题.分享给大家供大家参考,具体如下: 前面介绍了JS贪心算法解决背包问题,这里再来看看找零问题的解决方法. 在现实生活中,经常遇到找零问题,假设有数目不限的面值为20,10,5,1的硬币. 给出需要找零数,求出找零方案,要求:使用数目最少的硬币. 对于此类问题,贪心算法采取的方式是找钱时,总是选取可供找钱的硬币的最大值.比如,需要找钱数为25时,找钱方式为20+5,而不是10+10+5. 贪心算法还是很常见的算法之一,这是由于它简单易行,构造贪心策略不是很
-
浅析java贪心算法
贪心算法的基本思路 1.建立数学模型来描述问题. 2.把求解的问题分成若干个子问题. 3.对每一子问题求解,得到子问题的局部最优解. 4.把子问题的解局部最优解合成原来解问题的一个解. 实现该算法的过程: 从问题的某一初始解出发: while 能朝给定总目标前进一步 do 求出可行解的一个解元素: 由所有解元素组合成问题的一个可行解. 贪心选择性质 所谓贪心选择性质是指所求问题的整体最优解可以通过一系列局部最优的选择,换句话说,当考虑做何种选择的时候,我们只考虑对当前问题最佳的选择而不考虑子问题
-
Java实现身份证号码验证源码示例分享
整理文档,搜刮出一个Java实现身份证号码验证源码示例代码,稍微整理精简一下做下分享. package xxx; /** * Created by wdj on 2017/6/21. */ import java.text.ParseException; import java.text.SimpleDateFormat; import java.util.Calendar; import java.util.Date; import java.util.Random; /** * 身份证验证的
-
java基于AspectJ(面向切面编程)编码示例分享
一.基本概念 AspectJ是一种面向切面程序设计的基于Java 的实现.它向 Java 中加入了连接点(Join Point)这个新概念,其实它也只是现存的一个 Java概念的名称而已.它向 Java 语言中加入少许新结构:切点(pointcut).通知(Advice).类型间声明(Inter-type declaration)和方面(Aspect).切点和通知动态地影响程序流程,类型间声明则是静态的影响程序的类等级结构,而切面则是对所有这些新结构的封装. 基于切面.连接点.切点.通知的概念如
-
java模拟post请求登录猫扑示例分享
复制代码 代码如下: import java.io.BufferedReader;import java.io.File;import java.io.FileOutputStream;import java.io.IOException;import java.io.InputStream;import java.io.InputStreamReader;import java.io.OutputStreamWriter;import java.net.HttpURLConnection;im
-
Java分页工具类及其使用(示例分享)
Pager.java package pers.kangxu.datautils.common; import java.io.Serializable; import java.util.List; /** * * <b> 分页通用类 </b> * * @author kangxu * @param <T> * */ public class Pager<T> implements Serializable { /** * */ private stati
-
java信号量控制线程打印顺序的示例分享
复制代码 代码如下: import java.util.concurrent.Semaphore; public class ThreeThread { public static void main(String[] args) throws InterruptedException { Semaphore sempA = new Semaphore(1); Semaphore sempB = new Semaphore(0); Semaphore sempC = new Semapho