python中如何对多变量连续赋值
看到一段代码,如下
self.batch_size = batch_size = 128
初一看很诧异,仔细想想其实很合理的。
在python可能会需要同时声明多个变量,并对多个变量赋予相同的初始值,可以采用如下的方式赋值
a=b=c=1
但这里也需要注意,如果赋值为列表或者字典,比如
a=b=c=[1,2,3]
则a、b、c都是指向列表的指针,而不是复制,改变一个,其它的也会改变。
比如令 a[1] = 4, 则 b=[1,4,3]
python 赋值和拷贝 你真的了解吗?
现象:先上一段代码。
>>> import copy
>>> a = [1,2,3,4,['a','b']]
>>> b = a
>>> c = copy.copy(a)
>>> d = copy.deepcopy(a)
>>> a.append(5)
>>> print(a)
[1, 2, 3, 4, ['a', 'b'], 5]
>>> print(b)
[1, 2, 3, 4, ['a', 'b'], 5]
>>> print(c)
[1, 2, 3, 4, ['a', 'b']]
>>> print(d)
[1, 2, 3, 4, ['a', 'b']]
>>> a[4].append('c')
>>> print(a)
[1, 2, 3, 4, ['a', 'b', 'c'], 5]
>>> print(b)
[1, 2, 3, 4, ['a', 'b', 'c'], 5]
>>> print(c)
[1, 2, 3, 4, ['a', 'b', 'c']]
>>> print(d)
[1, 2, 3, 4, ['a', 'b']]######内存地址########
>>> id(a)44350024>>> id(b)44350024>>> id(c)44410440>>> id(d)44410760
一、概念(原理)
1、在详细的了解python中赋值、copy和deepcopy之前
我们还是要花一点时间来了解一下python内存中变量的存储情况。
在高级语言中,变量是对内存及其地址的抽象。对于python而言,python的一切变量都是对象,变量的存储,采用了引用语义的方式,存储的只是一个变量的值所在的内存地址,而不是这个变量的只本身。
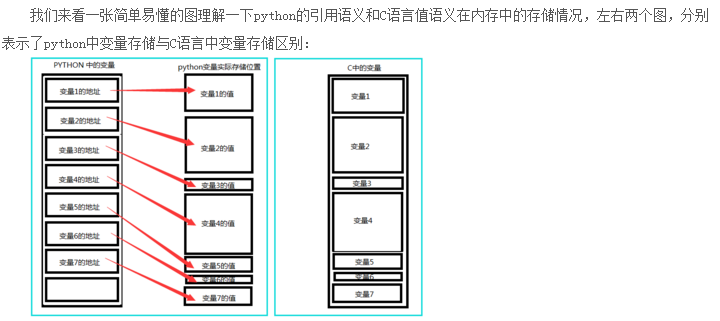
2、赋值
在python中,对象的赋值就是简单的对象引用,这点和C++不同。如下:
list_a = [1,2,3,"hello",["python","C++"]] list_b = list_a
这种情况下,list_b和list_a是一样的,他们指向同一片内存,list_b不过是list_a的别名,是引用。
我们可以使用 list_b is list_a 来判断,返回true,表明他们地址相同,内容相同。也可使用id(x) for x in list_a, list_b 来查看两个list的地址。
赋值操作(包括对象作为参数、返回值)不会开辟新的内存空间,它只是复制了新对象的引用。也就是说,除了list_b这个名字以外,没有其它的内存开销。
修改了list_a,就影响了list_b;同理,修改了list_b就影响了list_a。
3、浅拷贝
浅拷贝会创建新对象,其内容是原对象的引用。
浅拷贝有三种形式:切片操作,工厂函数,copy模块中的copy函数
比如对上述list_a,
切片操作:list_b = list_a[:] 或者 list_b = [each for each in list_a]
工厂函数:list_b = list(list_a)
copy函数:list_b = copy.copy(list_a)
浅拷贝产生的list_b不再是list_a了,使用is可以发现他们不是同一个对象,使用id查看,发现它们也不指向同一片内存。但是当我们使用 id(x) for x in list_a 和 id(x) for x in list_b 时,可以看到二者包含的元素的地址是相同的。
在这种情况下,list_a和list_b是不同的对象,修改list_b理论上不会影响list_a。比如list_b.append([4,5])。
但是要注意,浅拷贝之所以称为浅拷贝,是它仅仅只拷贝了一层,在list_a中有一个嵌套的list,如果我们修改了它,情况就不一样了。
list_a[4].append("C")。查看list_b,你将发现list_b也发生了变化。这是因为,你修改了嵌套的list。修改外层元素,会修改它的引用,让它们指向别的位置,修改嵌套列表中的元素,列表的地址并为发生变化,指向的都是同一个位置。
4、深拷贝
深拷贝只有一种形式,copy模块中的deepcopy函数。
和浅拷贝对应,深拷贝拷贝了对象的所有元素,包括多层嵌套的元素。因而,它的时间和空间开销要高。
同样对list_a,若使用list_b = copy.deepcopy(list_a),再修改list_b将不会影响到list_a了。即使嵌套的列表具有更深的层次,也不会产生任何影响,因为深拷贝出来的对象根本就是一个全新的对象,不再与原来的对象有任何关联。
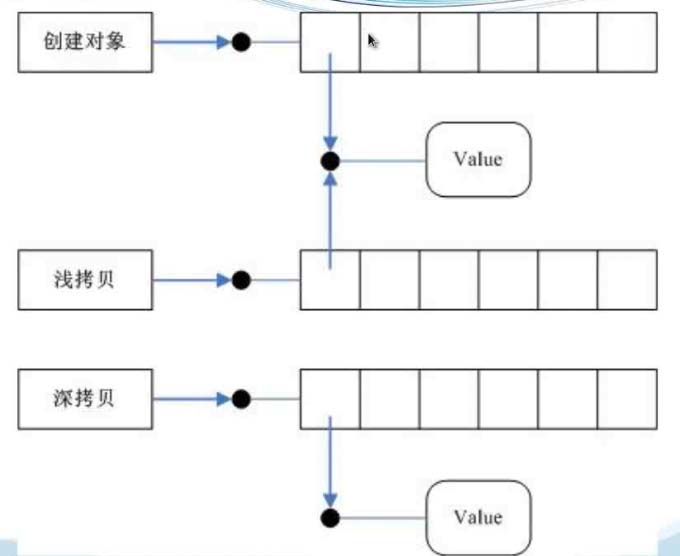
二、关于拷贝的警告
1、对于非容器类型,如数字,字符,以及其它“原子”类型,没有拷贝一说。产生的都是原对象的引用。
2、如果元组变量值包含原子类型对象,即使采用了深拷贝,也只能得到浅拷贝。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
python for循环赋值问题
背景 写代码的时候,你会发现你的代码越写越多. 然而,功能需要也越来越多,然后你的冗余代码就多得不能再多了~~~怎么办,我太难了. 那就寻求一些高级写法,一般的高级写法都是尽可能地短. 另外,把重复的代码抽取出来,封装成函数,每次使用直接调函数即可. For循环赋值 前提条件:我创建了一个road类,这个类里面有这些属性.我先初始化给road赋值,然后再把这些对象放到roadObjList集合里面. 目标:从roadObjList集合里面取出每个road对象的objectid值,然后放入到新的列
-
python模块中判断全局变量的赋值的实例讲解
1.在模块中,我们需要判断__name__是否被赋值为"__main__". python fibo.py <arguments> 2.在脚本执行的情况下,模块的__name__属性将被赋值为__main__,这就是原因所在. $ python fibo.py 50 0 1 1 2 3 5 8 13 21 34 3.若以模块导入,则不会执行: >>> import fibo >>> 知识点扩展: Python动态声明变量赋值代码实例 通过
-
Python连续赋值需要注意的一些问题
Python连续赋值的注意事项 在python中是可以使用连续赋值的方式来一次为多个变量进行赋值的,比如: a = b = c = 1 a, b, c = 1, 1, 1 这些都可以完成变量的赋值,但是就有一个问题了,比如: a = 3 a, b = 1, a 如果按照正常的思维逻辑,先进行a = 1,在进行b = a,最后b应该等于1,但是这里b应该等于3,因为在连续赋值语句中等式右边其实都是局部变量,而不是真正的变量值本身,比如,上面例子中右边的a,在python解析的时候,只是把变量a的指
-
python 使用pandas同时对多列进行赋值
如dataframe data1['月份']=int(month) #加入月份和企业名称 data1['企业']=parmentname 可以增加单列,并赋值,如果想同时对多列进行赋值 data1['月份','企业']=int(month) , parmentname #加入月份和企业名称 会出错 ValueError: Length of values does not match length of index data[['合计','平均']]='数据','月份' 类似这样的,也无效 Ke
-
Python基础之赋值,浅拷贝,深拷贝的区别
一.赋值 不会开辟新的内存空间,只是复制了新对象的引用.所以当一个数据发生变化时,另外一个数据也会随之改变. 二. 浅拷贝 创建新对象,其内容是对原对象的引用.浅拷贝之所以称为浅拷贝,是因为它仅仅只拷贝了第一层,即只拷贝了最外层的对象本身,内部的元素都只是拷贝了一个引用而已,即内部元素如果被修改,则另外一个数据也会发生变化. 浅拷贝的三种形式: A = [1, 2, 3, 4] 切片操作 # 第1种 B = A[:] # 第2种 B = [a for a in A] 工厂函数 B = list(
-

python批量创建变量并赋值操作
一,简单的情况: 核心是exec函数,exec函数可以执行我们输入的代码字符串.exec函数的简单例子: exec ('print "hello world"') hello world 可以很清晰的看到,我们给exec传入一个字符串'print "hello world"',exec是执行字符串里面的代码print "hello world".根据这个特性,我们可以用占位符实现我们对变量的定义,如: exec ("temp%s=1&q
-
python 实现循环定义、赋值多个变量的操作
exec函数,可以循环定义.赋值多个变量 exec ("temp%s=1"%1) 这段代码的意思是,让exec执行temp1=1.字符串里面的%s由'1'代替了. 我们在外面再套一个循环就可以实现对多个变量的定义了. for i in range(10): exec ("temp%s=1"%i) 在这里,通过一个循环来生成10个变量,i的变化从0到9.用变量i替代%s,所以在每次循环里面,分别给temp0.temp1.temp2--赋值为1. 如果想要替换多个占位符
-
python中如何对多变量连续赋值
看到一段代码,如下 self.batch_size = batch_size = 128 初一看很诧异,仔细想想其实很合理的. 在python可能会需要同时声明多个变量,并对多个变量赋予相同的初始值,可以采用如下的方式赋值 a=b=c=1 但这里也需要注意,如果赋值为列表或者字典,比如 a=b=c=[1,2,3] 则a.b.c都是指向列表的指针,而不是复制,改变一个,其它的也会改变. 比如令 a[1] = 4, 则 b=[1,4,3] python 赋值和拷贝 你真的了解吗? 现象:先上一段代码
-
Python中for循环详解
与其它大多数语言一样,Python 也拥有 for 循环.你到现在还未曾看到它们的唯一原因就是,Python 在其它太多的方面表现出色,通常你不需要它们. 其它大多数语言没有像 Python 一样的强大的 list 数据类型,所以你需要亲自做很多事情,指定开始,结束和步长,来定义一定范围的整数或字符或其它可重复的实体.但是在 Python 中,for 循环简单地在一个列表上循环,与 list 解析的工作方式相同. 1. for 循环介绍 复制代码 代码如下: >>> li = ['a'
-
Python中赋值运算符的含义与使用方法
目录 引言 一.赋值运算符含义: 二.赋值运算符写法: 2.1单个变量赋值 2.2多个变量赋值 2.3多变量赋值相同值 附:扩展后的赋值运算符 总结 引言 在Python中但凡提到的赋值运算符其实讲的就是等号=,在编程语言中的等号含义再也不是数学中的1+1=2的这种等号,真实含义是将=右侧的结果赋值给等号左侧的变量. 好比定义一个变量num=1,先计算等号右边的把这个计算的结果再赋值到等号左边的变量当中,其实此时num变量就是1这个数据在内存当中的一个引用地址,后期想使用1这个数据的时候直接把n
-
python中的变量命名规则详情
目录 1.变量命名 1)命名的规范性 2)编程语言常用驼峰命名法 2. 变量命名的描述性 3.变量名尽量短,但是不要太短 4.合理使用变量 5. 变量定义尽量靠近使用 6. 合理使用namedtuple/dict 6. 控制单个函数内的变量数量 7. 删除掉没用的变量 8. 定义临时变量提高可读性 9. The Zen of Python 1.变量命名 1)命名的规范性 变量名可以包括字母.数字.下划线,但是数字不能做为开头. 系统关键字不能做变量名使用 除了下划线之个,其它符号不能做为变量名使
-
python中for循环的多种使用实例
目录 前言 for循环迭代字符串 for打印数字 注意for循环不能迭代数值类型 for循环打印数字的话要借用range函数 for循环可用来初始化列表 简单的往列表里添加数据 列表推导式 总结 前言 本文简单总结了一下python中for循环的使用 python中for循环一般用来迭代字符串,列表,元组等. 当for循环用于迭代时不需要考虑循环次数,循环次数由后面的对象长度来决定. for循环迭代字符串 for循环可以把字符串里面的元素都依次取出来,自动赋值给变量i然后再执行循环体内的代码块
-
简单了解Python中的几种函数
几个特殊的函数(待补充) python是支持多种范型的语言,可以进行所谓函数式编程,其突出体现在有这么几个函数: filter.map.reduce.lambda.yield lambda >>> g = lambda x,y:x+y #x+y,并返回结果 >>> g(3,4) 7 >>> (lambda x:x**2)(4) #返回4的平方 16 lambda函数的使用方法: 在lambda后面直接跟变量 变量后面是冒号 冒号后面是表达式,表达式计算
-
基于python中的TCP及UDP(详解)
python中是通过套接字即socket来实现UDP及TCP通信的.有两种套接字面向连接的及无连接的,也就是TCP套接字及UDP套接字. TCP通信模型 创建TCP服务器 伪代码: ss = socket() # 创建服务器套接字 ss.bind() # 套接字与地址绑定 ss.listen() # 监听连接 inf_loop: # 服务器无限循环 cs = ss.accept() # 接受客户端连接 comm_loop: # 通信循环 cs.recv()/cs.send() # 对话(接收/发
-
python中文件变化监控示例(watchdog)
在python中文件监控主要有两个库,一个是pyinotify ( https://github.com/seb-m/pyinotify/wiki),一个是watchdog(http://pythonhosted.org/watchdog/).pyinotify依赖于Linux平台的inotify,后者则对不同平台的的事件都进行了封装.因为我主要用于Windows平台,所以下面着重介绍watchdog(推荐大家阅读一下watchdog实现源码,有利于深刻的理解其中的原理). watchdog在不
-
python中模块的__all__属性详解
python模块中的__all__属性,可用于模块导入时限制,如: from module import * 此时被导入模块若定义了__all__属性,则只有__all__内指定的属性.方法.类可被导入. 若没定义,则导入模块内的所有公有属性,方法和类 # kk.py class A(): def __init__(self,name,age): self.name=name self.age=age class B(): def __init__(self,name,id): self.nam
-
python中requests使用代理proxies方法介绍
学习网络爬虫难免遇到使用代理的情况,下面介绍一下如何使用requests设置代理: 如果需要使用代理,你可以通过为任意请求方法提供 proxies 参数来配置单个请求: import requests proxies = { "http": "http://10.10.1.10:3128", "https": "http://10.10.1.10:1080", } requests.get("http://examp