Pytorch深度学习经典卷积神经网络resnet模块训练
目录
- 前言
- 一、resnet
- 二、resnet网络结构
- 三、resnet18
- 1.导包
- 2.残差模块
- 2.通道数翻倍残差模块
- 3.rensnet18模块
- 4.数据测试
- 5.损失函数,优化器
- 6.加载数据集,数据增强
- 7.训练数据
- 8.保存模型
- 9.加载测试集数据,进行模型测试
- 四、resnet深层对比
前言
随着深度学习的不断发展,从开山之作Alexnet到VGG,网络结构不断优化,但是在VGG网络研究过程中,人们发现随着网络深度的不断提高,准确率却没有得到提高,如图所示:
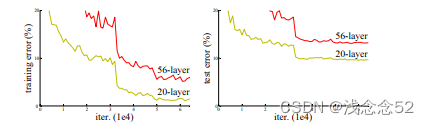
人们觉得深度学习到此就停止了,不能继续研究了,但是经过一段时间的发展,残差网络(resnet)解决了这一问题。
一、resnet
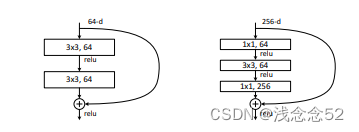
如图所示:简单来说就是保留之前的特征,有时候当图片经过卷积进行特征提取,得到的结果反而没有之前的很好,所以resnet提出保留之前的特征,这里还需要经过一些处理,在下面代码讲解中将详细介绍。
二、resnet网络结构
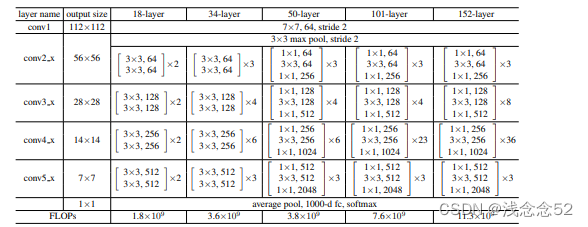
本文将主要介绍resnet18
三、resnet18
1.导包
import torch import torchvision.transforms as trans import torchvision as tv import torch.nn as nn from torch.autograd import Variable from torch.utils import data from torch.optim import lr_scheduler
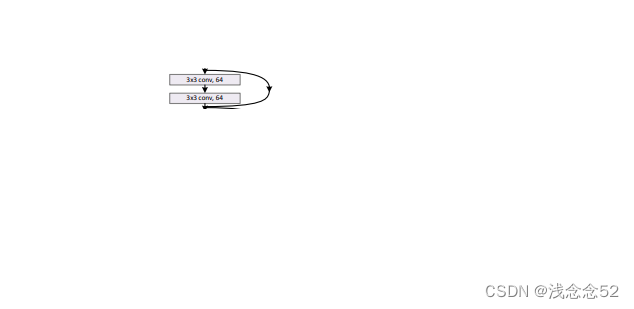
2.残差模块
这个模块完成的功能如图所示:
class tiao(nn.Module):
def __init__(self,shuru,shuchu):
super(tiao, self).__init__()
self.conv1=nn.Conv2d(in_channels=shuru,out_channels=shuchu,kernel_size=(3,3),padding=(1,1))
self.bath=nn.BatchNorm2d(shuchu)
self.relu=nn.ReLU()
def forward(self,x):
x1=self.conv1(x)
x2=self.bath(x1)
x3=self.relu(x2)
x4=self.conv1(x3)
x5=self.bath(x4)
x6=self.relu(x5)
x7=x6+x
return x7
2.通道数翻倍残差模块
模块完成功能如图所示:
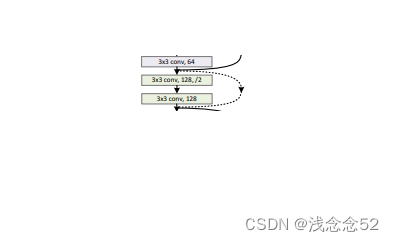
在这个模块中,要注意原始图像的通道数要进行翻倍,要不然后面是不能进行相加。
class tiao2(nn.Module):
def __init__(self,shuru):
super(tiao2, self).__init__()
self.conv1=nn.Conv2d(in_channels=shuru,out_channels=shuru*2,kernel_size=(3,3),stride=(2,2),padding=(1,1))
self.conv11=nn.Conv2d(in_channels=shuru,out_channels=shuru*2,kernel_size=(1,1),stride=(2,2))
self.batch=nn.BatchNorm2d(shuru*2)
self.relu=nn.ReLU()
self.conv2=nn.Conv2d(in_channels=shuru*2,out_channels=shuru*2,kernel_size=(3,3),stride=(1,1),padding=(1,1))
def forward(self,x):
x1=self.conv1(x)
x2=self.batch(x1)
x3=self.relu(x2)
x4=self.conv2(x3)
x5=self.batch(x4)
x6=self.relu(x5)
x11=self.conv11(x)
x7=x11+x6
return x7
3.rensnet18模块
class resnet18(nn.Module):
def __init__(self):
super(resnet18, self).__init__()
self.conv1=nn.Conv2d(in_channels=3,out_channels=64,kernel_size=(7,7),stride=(2,2),padding=(3,3))
self.bath=nn.BatchNorm2d(64)
self.relu=nn.ReLU()
self.max=nn.MaxPool2d(2,2)
self.tiao1=tiao(64,64)
self.tiao2=tiao(64,64)
self.tiao3=tiao2(64)
self.tiao4=tiao(128,128)
self.tiao5=tiao2(128)
self.tiao6=tiao(256,256)
self.tiao7=tiao2(256)
self.tiao8=tiao(512,512)
self.a=nn.AdaptiveAvgPool2d(output_size=(1,1))
self.l=nn.Linear(512,10)
def forward(self,x):
x1=self.conv1(x)
x2=self.bath(x1)
x3=self.relu(x2)
x4=self.tiao1(x3)
x5=self.tiao2(x4)
x6=self.tiao3(x5)
x7=self.tiao4(x6)
x8=self.tiao5(x7)
x9=self.tiao6(x8)
x10=self.tiao7(x9)
x11=self.tiao8(x10)
x12=self.a(x11)
x13=x12.view(x12.size()[0],-1)
x14=self.l(x13)
return x14
这个网络简单来说16层卷积,1层全连接,训练参数相对较少,模型相对来说比较简单。
4.数据测试
model=resnet18().cuda() input=torch.randn(1,3,64,64).cuda() output=model(input) print(output)

5.损失函数,优化器
损失函数
loss=nn.CrossEntropyLoss()
在优化器中,将学习率进行每10步自动衰减
opt=torch.optim.SGD(model.parameters(),lr=0.001,momentum=0.9)exp_lr=lr_scheduler.StepLR(opt,step_size=10,gamma=0.1)opt=torch.optim.SGD(model.parameters(),lr=0.001,momentum=0.9) exp_lr=lr_scheduler.StepLR(opt,step_size=10,gamma=0.1)

在这里可以看一下对比图,发现添加学习率自动衰减,loss下降速度会快一些,这说明模型拟合效果比较好。
6.加载数据集,数据增强
这里我们仍然选择cifar10数据集,首先对数据进行增强,增加模型的泛华能力。
transs=trans.Compose([
trans.Resize(256),
trans.RandomHorizontalFlip(),
trans.RandomCrop(64),
trans.ColorJitter(brightness=0.5,contrast=0.5,hue=0.3),
trans.ToTensor(),
trans.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))
])
ColorJitter函数中brightness(亮度)contrast(对比度)saturation(饱和度)hue(色调)
加载cifar10数据集:
train=tv.datasets.CIFAR10(
root=r'E:\桌面\资料\cv3\数据集\cifar-10-batches-py',
train=True,
download=True,
transform=transs
)
trainloader=data.DataLoader(
train,
num_workers=4,
batch_size=8,
shuffle=True,
drop_last=True
)
7.训练数据
for i in range(3):
running_loss=0
for index,data in enumerate(trainloader):
x,y=data
x=x.cuda()
y=y.cuda()
x=Variable(x)
y=Variable(y)
opt.zero_grad()
h=model(x)
loss1=loss(h,y)
loss1.backward()
opt.step()
running_loss+=loss1.item()
if index%100==99:
avg_loos=running_loss/100
running_loss=0
print("avg_loss",avg_loos)
8.保存模型
torch.save(model.state_dict(),'resnet18.pth')
9.加载测试集数据,进行模型测试
首先加载训练好的模型
model.load_state_dict(torch.load('resnet18.pth'),False)
读取数据
test = tv.datasets.ImageFolder(
root=r'E:\桌面\资料\cv3\数据',
transform=transs,
)
testloader = data.DataLoader(
test,
batch_size=16,
shuffle=False,
)
测试数据
acc=0
total=0
for data in testloader:
inputs,indel=data
out=model(inputs.cuda())
_,prediction=torch.max(out.cpu(),1)
total+=indel.size(0)
b=(prediction==indel)
acc+=b.sum()
print("准确率%d %%"%(100*acc/total))
四、resnet深层对比
上面提到VGG网络层次越深,准确率越低,为了解决这一问题,才提出了残差网络(resnet),那么在resnet网络中,到底会不会出现这一问题。
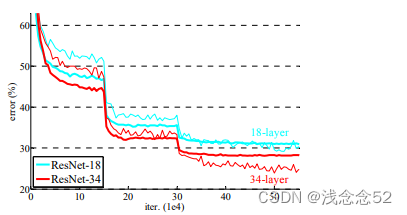
如图所示:随着,训练层次不断提高,模型越来越好,成功解决了VGG网络的问题,到现在为止,残差网络还是被大多数人使用。
以上就是Pytorch深度学习经典卷积神经网络resnet模块训练的详细内容,更多关于卷积神经网络resnet模块训练的资料请关注我们其它相关文章!
相关推荐
-
PyTorch实现ResNet50、ResNet101和ResNet152示例
PyTorch: https://github.com/shanglianlm0525/PyTorch-Networks import torch import torch.nn as nn import torchvision import numpy as np print("PyTorch Version: ",torch.__version__) print("Torchvision Version: ",torchvision.__version__) _
-

pytorch实现ResNet结构的实例代码
1.ResNet的创新 现在重新稍微系统的介绍一下ResNet网络结构. ResNet结构首先通过一个卷积层然后有一个池化层,然后通过一系列的残差结构,最后再通过一个平均池化下采样操作,以及一个全连接层的得到了一个输出.ResNet网络可以达到很深的层数的原因就是不断的堆叠残差结构而来的. 1)亮点 网络中的亮点 : 超深的网络结构( 突破1000 层) 提出residual 模块 使用Batch Normalization 加速训练( 丢弃dropout) 但是,一般来说,并不是一直的加深神经
-
使用Keras预训练模型ResNet50进行图像分类方式
Keras提供了一些用ImageNet训练过的模型:Xception,VGG16,VGG19,ResNet50,InceptionV3.在使用这些模型的时候,有一个参数include_top表示是否包含模型顶部的全连接层,如果包含,则可以将图像分为ImageNet中的1000类,如果不包含,则可以利用这些参数来做一些定制的事情. 在运行时自动下载有可能会失败,需要去网站中手动下载,放在"~/.keras/models/"中,使用WinPython则在"settings/.ke
-
Pytorch修改ResNet模型全连接层进行直接训练实例
之前在用预训练的ResNet的模型进行迁移训练时,是固定除最后一层的前面层权重,然后把全连接层输出改为自己需要的数目,进行最后一层的训练,那么现在假如想要只是把 最后一层的输出改一下,不需要加载前面层的权重,方法如下: model = torchvision.models.resnet18(pretrained=False) num_fc_ftr = model.fc.in_features model.fc = torch.nn.Linear(num_fc_ftr, 224) model =
-
pytorch实现用Resnet提取特征并保存为txt文件的方法
接触pytorch一天,发现pytorch上手的确比TensorFlow更快.可以更方便地实现用预训练的网络提特征. 以下是提取一张jpg图像的特征的程序: # -*- coding: utf-8 -*- import os.path import torch import torch.nn as nn from torchvision import models, transforms from torch.autograd import Variable import numpy as np
-
Pytorch深度学习经典卷积神经网络resnet模块训练
目录 前言 一.resnet 二.resnet网络结构 三.resnet18 1.导包 2.残差模块 2.通道数翻倍残差模块 3.rensnet18模块 4.数据测试 5.损失函数,优化器 6.加载数据集,数据增强 7.训练数据 8.保存模型 9.加载测试集数据,进行模型测试 四.resnet深层对比 前言 随着深度学习的不断发展,从开山之作Alexnet到VGG,网络结构不断优化,但是在VGG网络研究过程中,人们发现随着网络深度的不断提高,准确率却没有得到提高,如图所示: 人们觉得深度学习到此
-
TensorFlow深度学习之卷积神经网络CNN
一.卷积神经网络的概述 卷积神经网络(ConvolutionalNeural Network,CNN)最初是为解决图像识别等问题设计的,CNN现在的应用已经不限于图像和视频,也可用于时间序列信号,比如音频信号和文本数据等.CNN作为一个深度学习架构被提出的最初诉求是降低对图像数据预处理的要求,避免复杂的特征工程.在卷积神经网络中,第一个卷积层会直接接受图像像素级的输入,每一层卷积(滤波器)都会提取数据中最有效的特征,这种方法可以提取到图像中最基础的特征,而后再进行组合和抽象形成更高阶的特征,因此
-
Pytorch深度学习之实现病虫害图像分类
目录 一.pytorch框架 1.1.概念 1.2.机器学习与深度学习的区别 1.3.在python中导入pytorch成功截图 二.数据集 三.代码复现 3.1.导入第三方库 3.2.CNN代码 3.3.测试代码 四.训练结果 4.1.LOSS损失函数 4.2. ACC 4.3.单张图片识别准确率 四.小结 一.pytorch框架 1.1.概念 PyTorch是一个开源的Python机器学习库,基于Torch,用于自然语言处理等应用程序. 2017年1月,由Facebook人工智能研究院(FA
-
pyTorch深度学习多层感知机的实现
目录 激活函数 多层感知机的PyTorch实现 激活函数 前两节实现的传送门 pyTorch深度学习softmax实现解析 pyTorch深入学习梯度和Linear Regression实现析 前两节实现的linear model 和 softmax model 是单层神经网络,只包含一个输入层和一个输出层,因为输入层不对数据进行transformation,所以只算一层输出层. 多层感知机(mutilayer preceptron)加入了隐藏层,将神经网络的层级加深,因为线性层的串联结果还是线
-
PyTorch深度学习模型的保存和加载流程详解
一.模型参数的保存和加载 torch.save(module.state_dict(), path):使用module.state_dict()函数获取各层已经训练好的参数和缓冲区,然后将参数和缓冲区保存到path所指定的文件存放路径(常用文件格式为.pt..pth或.pkl). torch.nn.Module.load_state_dict(state_dict):从state_dict中加载参数和缓冲区到Module及其子类中 . torch.nn.Module.state_dict()函数
-
pyTorch深度学习softmax实现解析
目录 用PyTorch实现linear模型 模拟数据集 定义模型 加载数据集 optimizer 模型训练 softmax回归模型 Fashion-MNIST cross_entropy 模型的实现 利用PyTorch简易实现softmax 用PyTorch实现linear模型 模拟数据集 num_inputs = 2 #feature number num_examples = 1000 #训练样本个数 true_w = torch.tensor([[2],[-3.4]]) #真实的权重值 t
-
Pytorch深度学习gather一些使用问题解决方案
目录 问题场景描述 问题的思考 gather的说明 问题的解决 问题场景描述 我在复现Faster-RCNN模型的过程中遇到这样一个问题: 有一个张量,它的形状是 (128, 21, 4) roi_loc.shape = (128, 21, 4) 与之对应的还有一个label数据 gt_label.shape = (128) 我现在的需求是将label当作第一个张量在dim=1上的索引,将其中的数据拿出来. 具体来说就是,现在有128个样本数据,每个样本中有21个长度为4的向量.label也是1
-
PyTorch深度学习LSTM从input输入到Linear输出
目录 LSTM介绍 LSTM参数 Inputs Outputs batch_first 案例 LSTM介绍 关于LSTM的具体原理,可以参考: https://www.jb51.net/article/178582.htm https://www.jb51.net/article/178423.htm 系列文章: PyTorch搭建双向LSTM实现时间序列负荷预测 PyTorch搭建LSTM实现多变量多步长时序负荷预测 PyTorch搭建LSTM实现多变量时序负荷预测 PyTorch搭建LSTM
-
python深度学习tensorflow卷积层示例教程
目录 一.旧版本(1.0以下)的卷积函数:tf.nn.conv2d 二.1.0版本中的卷积函数:tf.layers.conv2d 一.旧版本(1.0以下)的卷积函数:tf.nn.conv2d 在tf1.0中,对卷积层重新进行了封装,比原来版本的卷积层有了很大的简化. conv2d( input, filter, strides, padding, use_cudnn_on_gpu=None, data_format=None, name=None ) 该函数定义在tensorflow/pytho
-
如何在conda虚拟环境中配置cuda+cudnn+pytorch深度学习环境
首先,我们要明确,我们是要在虚拟环境中安装cuda和cuDNN!!!只需要在虚拟环境中安装就可以了. 下面的操作默认你安装好了python 一.conda创建并激活虚拟环境 前提:确定你安装好了anaconda并配置好了环境变量,如果没有,网上有很多详细的配置教程,请自行学习 在cmd命令提示符中输入conda命令查看anaconda 如果显示和上图相同,那么可以继续向下看 1.进入anaconda的base环境 方法1 在cmd命令提示符中输入如下命令 activate 方法2 直接在搜索栏里