python机器学习Github已达8.9Kstars模型解释器LIME
目录
- LIME
- 代 码
- 对单个样本进行预测解释
- 适用问题
简单的模型例如线性回归,LR等模型非常易于解释,但在实际应用中的效果却远远低于复杂的梯度提升树模型以及神经网络等模型。
现在大部分互联网公司的建模都是基于梯度提升树或者神经网络模型等复杂模型,遗憾的是,这些模型虽然效果好,但是我们却较难对其进行很好地解释,这也是目前一直困扰着大家的一个重要问题,现在大家也越来越加关注模型的解释性。
本文介绍一种解释机器学习模型输出的方法LIME。它可以认为是SHARP的升级版,Github链接:https://github.com/marcotcr/lime,有所收获多多支持
LIME
LIME(Local Interpretable Model-agnostic Explanations)支持的模型包括:
- 结构化模型的解释;
- 文本分类器的解释;
- 图像分类器的解释;
LIME被用作解释机器学习模型的解释,通过LIME我们可以知道为什么模型会这样进行预测。
本文我们就重点观测一下LIME是如何对预测结果进行解释的。
代 码
此处我们使用winequality-white数据集,并且将quality<=5设置为0,其它的值转变为1.
# !pip install lime import pandas as pd from xgboost import XGBClassifier import shap import numpy as np from sklearn.model_selection import train_test_split
df = pd.read_csv('./data/winequality-white.csv',sep = ';')
df['quality'] = df['quality'].apply(lambda x: 0 if x <= 5 else 1)
df.head()
# 训练集测试集分割
X = df.drop('quality', axis=1)
y = df['quality']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)
# 模型训练
model = XGBClassifier(n_estimators = 100, random_state=42)
model.fit(X_train, y_train)
score = model.score(X_test, y_test)
score
The use of label encoder in XGBClassifier is deprecated and will be removed in a future release. 0.832653061224489
对单个样本进行预测解释
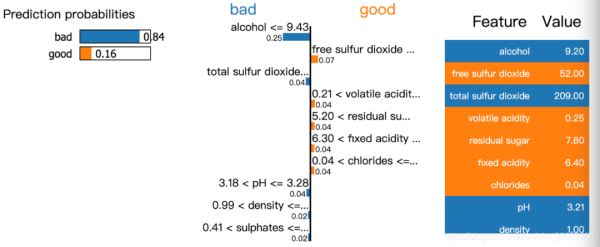
下面的图中表明了单个样本的预测值中各个特征的贡献。
import lime
from lime import lime_tabular
explainer = lime_tabular.LimeTabularExplainer(
training_data=np.array(X_train),
feature_names=X_train.columns,
class_names=['bad', 'good'],
mode='classification'
)
模型有84%的置信度是坏的wine,而其中alcohol,totals ulfur dioxide是最重要的。
import lime
from lime import lime_tabular
explainer = lime_tabular.LimeTabularExplainer(
training_data=np.array(X_train),
feature_names=X_train.columns,
class_names=['bad', 'good'],
mode='classification'
)
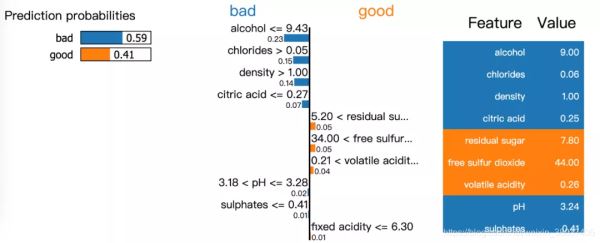
模型有59%的置信度是坏的wine,而其中alcohol,chlorides, density, citric acid是最重要的预测参考因素。
exp = explainer.explain_instance(data_row=X_test.iloc[1], predict_fn=model.predict_proba) exp.show_in_notebook(show_table=True)
适用问题
LIME可以认为是SHARP的升级版,它通过预测结果解释机器学习模型很简单。它为我们提供了一个很好的方式来向非技术人员解释地下发生了什么。您不必担心数据可视化,因为LIME库会为您处理数据可视化。
参考链接
https://www.kaggle.com/piyushagni5/white-wine-quality
LIME: How to Interpret Machine Learning Models With Python
https://github.com/marcotcr/lime
https://mp.weixin.qq.com/s/47omhEeHqJdQTtciLIN2Hw
以上就是Github已达8.9Kstars的最佳模型解释器LIME的详细内容,更多关于模型解释器LIME的资料请关注我们其它相关文章!
相关推荐
-

Pycharm学习教程(4) Python解释器的相关配置
Python解释器的相关配置,供大家参考,具体内容如下 1.准备工作 (1)Pycharm版本为3.4或者更高. (2)电脑上至少已经安装了一个Python解释器. (3)如果你希望配置一个远程解释器,则需要服务器的相关支持. 2.本地解释器配置 配置本地解释器的步骤相对简洁直观: (1)单击工具栏中的设置按钮. (2)在Settings/Preferences对话框中选中 Project Interpreter页面,在Project Interpreter对应的下拉列表中选择对应的解释器版本,
-
在Python文件中指定Python解释器的方法
以下针对Ubuntu系统,Windows系统没有测试过. Ubuntu中默认就安装有Python 2.x和Python 3.x,默认情况下python命令指的是Python 2.x.因此当将Python脚本设为可执行文件直接在命令行里执行时,系统调用的是Python 2.x的解释器. 如果在直接执行Python脚本(例如在命令行直接输入xxx.py)时,想调用Python 3.x解释器去解释脚本,一种方法是修改符号链接,让python命令指向Python3.这种方法在自己的系统上还行得通,如果脚
-
python机器学习使数据更鲜活的可视化工具Pandas_Alive
目录 安装方法 使用说明 支持示例展示 水平条形图 垂直条形图比赛 条形图 饼图 多边形地理空间图 多个图表 总结 数据动画可视化制作在日常工作中是非常实用的一项技能.目前支持动画可视化的库主要以Matplotlib-Animation为主,其特点为:配置复杂,保存动图容易报错. 安装方法 pip install pandas_alive # 或者 conda install pandas_alive -c conda-forge 使用说明 pandas_alive 的设计灵感来自 bar_ch
-
python数据挖掘使用Evidently创建机器学习模型仪表板
目录 1.安装包 2.导入所需的库 3.加载数据集 4.创建模型 5.创建仪表板 6.可用报告类型 1)数据漂移 2)数值目标漂移 3)分类目标漂移 4)回归模型性能 5)分类模型性能 6)概率分类模型性能 解释机器学习模型是一个困难的过程,因为通常大多数模型都是一个黑匣子,我们不知道模型内部发生了什么.创建不同类型的可视化有助于理解模型是如何执行的,但是很少有库可以用来解释模型是如何工作的. Evidently 是一个开源 Python 库,用于创建交互式可视化报告.仪表板和 JSON 配置文
-
python解释模型库Shap实现机器学习模型输出可视化
目录 安装所需的库 导入所需库 创建模型 创建可视化 1.Bar Plot 2.队列图 3.热图 4.瀑布图 5.力图 6.决策图 解释一个机器学习模型是一个困难的任务,因为我们不知道这个模型在那个黑匣子里是如何工作的.解释是必需的,这样我们可以选择最佳的模型,同时也使其健壮. 我们开始吧- 安装所需的库 使用pip安装Shap开始.下面给出的命令可以做到这一点. pip install shap 导入所需库 在这一步中,我们将导入加载数据.创建模型和创建该模型的可视化所需的库. df = pd
-
python机器学习Github已达8.9Kstars模型解释器LIME
目录 LIME 代 码 对单个样本进行预测解释 适用问题 简单的模型例如线性回归,LR等模型非常易于解释,但在实际应用中的效果却远远低于复杂的梯度提升树模型以及神经网络等模型. 现在大部分互联网公司的建模都是基于梯度提升树或者神经网络模型等复杂模型,遗憾的是,这些模型虽然效果好,但是我们却较难对其进行很好地解释,这也是目前一直困扰着大家的一个重要问题,现在大家也越来越加关注模型的解释性. 本文介绍一种解释机器学习模型输出的方法LIME.它可以认为是SHARP的升级版,Github链接:https
-
Python机器学习应用之基于线性判别模型的分类篇详解
目录 一.Introduction 1 LDA的优点 2 LDA的缺点 3 LDA在模式识别领域与自然语言处理领域的区别 二.Demo 三.基于LDA 手写数字的分类 四.小结 一.Introduction 线性判别模型(LDA)在模式识别领域(比如人脸识别等图形图像识别领域)中有非常广泛的应用.LDA是一种监督学习的降维技术,也就是说它的数据集的每个样本是有类别输出的.这点和PCA不同.PCA是不考虑样本类别输出的无监督降维技术. LDA的思想可以用一句话概括,就是"投影后类内方差最小,类间方
-
python机器学习朴素贝叶斯算法及模型的选择和调优详解
目录 一.概率知识基础 1.概率 2.联合概率 3.条件概率 二.朴素贝叶斯 1.朴素贝叶斯计算方式 2.拉普拉斯平滑 3.朴素贝叶斯API 三.朴素贝叶斯算法案例 1.案例概述 2.数据获取 3.数据处理 4.算法流程 5.注意事项 四.分类模型的评估 1.混淆矩阵 2.评估模型API 3.模型选择与调优 ①交叉验证 ②网格搜索 五.以knn为例的模型调优使用方法 1.对超参数进行构造 2.进行网格搜索 3.结果查看 一.概率知识基础 1.概率 概率就是某件事情发生的可能性. 2.联合概率 包
-
Python机器学习NLP自然语言处理基本操作词向量模型
目录 概述 词向量 词向量维度 Word2Vec CBOW 模型 Skip-Gram 模型 负采样模型 词向量的训练过程 1. 初始化词向量矩阵 2. 神经网络反向传播 词向量模型实战 训练模型 使用模型 概述 从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁. 词向量 我们先来说说词向量究竟是什么. 当我们把文本交给算法来处理的时候, 计算机并不能理解我们输入的文本, 词向量就由此而生了.
-
Python机器学习入门(六)优化模型
目录 1.集成算法 1.1袋装算法 1.1.1袋装决策树 1.1.2随机森林 1.1.3极端随机树 1.2提升算法 1.2.1AdaBoost 1.2.2随机梯度提升 1.3投票算法 2.算法调参 2.1网络搜索优化参数 2.2随机搜索优化参数 总结 有时提升一个模型的准确度很困难.你会尝试所有曾学习过的策略和算法,但模型正确率并没有改善.这时你会觉得无助和困顿,这也正是90%的数据科学家开始放弃的时候.不过,这才是考验真正本领的时候!这也是普通的数据科学家和大师级数据科学家的差距所在. 1.集
-
Python机器学习入门(四)选择模型
目录 1.数据分离与验证 1.1分离训练数据集和评估数据集 1.2K折交叉验证分离 1.3弃一交叉验证分离 1.4重复随机分离评估数据集与训练数据集 2.算法评估 2.1分类算法评估 2.1.1分类准确度 2.1.2分类报告 2.2回归算法评估 2.2.1平均绝对误差 2.2.2均方误差 2.2.3判定系数() 总结 1.数据分离与验证 要知道算法模型对未知的数据表现如何,最好的评估办法是利用已经明确知道结果的数据运行生成的算法模型进行验证.此外还可以使用新的数据来评估算法模型. 在评估机器学习
-
Python机器学习入门(四)之Python选择模型
目录 1.数据分离与验证 1.1分离训练数据集和评估数据集 1.2K折交叉验证分离 1.3弃一交叉验证分离 1.4重复随机分离评估数据集与训练数据集 2.算法评估 2.1分类算法评估 2.1.1分类准确度 2.1.2分类报告 2.2回归算法评估 2.2.1平均绝对误差 2.2.2均方误差 2.2.3判定系数() 1.数据分离与验证 要知道算法模型对未知的数据表现如何,最好的评估办法是利用已经明确知道结果的数据运行生成的算法模型进行验证.此外还可以使用新的数据来评估算法模型. 在评估机器学习算法时
-
Python机器学习入门(六)之Python优化模型
目录 1.集成算法 1.1袋装算法 1.1.1袋装决策树 1.1.2随机森林 1.1.3极端随机树 1.2提升算法 1.2.1AdaBoost 1.2.2随机梯度提升 1.3投票算法 2.算法调参 2.1网络搜索优化参数 2.2随机搜索优化参数 总结 有时提升一个模型的准确度很困难.你会尝试所有曾学习过的策略和算法,但模型正确率并没有改善.这时你会觉得无助和困顿,这也正是90%的数据科学家开始放弃的时候.不过,这才是考验真正本领的时候!这也是普通的数据科学家和大师级数据科学家的差距所在. 1.集
-
python接口调用已训练好的caffe模型测试分类方法
训练好了model后,可以通过python调用caffe的模型,然后进行模型测试的输出. 本次测试主要依靠的模型是在caffe模型里面自带训练好的结构参数:~/caffe/models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel,以及结构参数 :~/caffe/models/bvlc_reference_caffenet/deploy.prototxt相结合,用python接口进行调用. 训练的源代码以及相应的注释如下所示
-
Python机器学习pytorch模型选择及欠拟合和过拟合详解
目录 训练误差和泛化误差 模型复杂性 模型选择 验证集 K折交叉验证 欠拟合还是过拟合? 模型复杂性 数据集大小 训练误差和泛化误差 训练误差是指,我们的模型在训练数据集上计算得到的误差. 泛化误差是指,我们将模型应用在同样从原始样本的分布中抽取的无限多的数据样本时,我们模型误差的期望. 在实际中,我们只能通过将模型应用于一个独立的测试集来估计泛化误差,该测试集由随机选取的.未曾在训练集中出现的数据样本构成. 模型复杂性 在本节中将重点介绍几个倾向于影响模型泛化的因素: 可调整参数的数量.当可调