Pycharm无法使用已经安装Selenium的解决方法
电脑C盘安装python27的时候也安装了selenium,但是最近刚刚使用工具Pycharm,新建工程后,然后建立.py文件后,使用语句:from selenium.webdriver.support.wait import WebDriverWait
接着提示没有selenium这个模块,后来发现,在Pycharm上运行脚本时,使用的是其自带的虚拟环境,而不是电脑已经装配好的python27的环境:
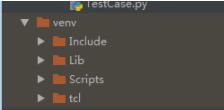
该环境本身缺少很多外部库,尝试在此环境下装selenium,但是失败了:

所以,接下来只能Project Interpreter为自己本机的python27环境:
通过file->setting进入修改,如下图对应位置,点击右边的+好,将其指向本机的python27环境即可

配置后好,运行脚本,脚本运行通过!
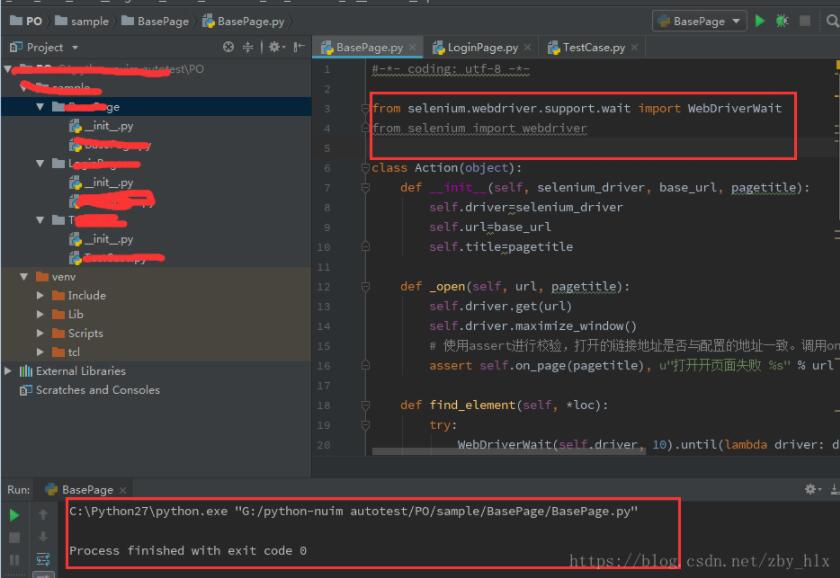
以上这篇Pycharm无法使用已经安装Selenium的解决方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Selenium元素的常用操作方法分析
本文实例讲述了Selenium元素的常用操作方法.分享给大家供大家参考,具体如下: Selenium是一个用于Web应用程序测试的工具.Selenium测试直接运行在浏览器中,就像真正的用户在操作一样.支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等.这个工具的主要功能包括:测试与浏览器的兼容性--测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上.测试系统功能--创建回归测试检验软件功能和
-
python+selenium实现登录账户后自动点击的示例
公司在codereview的时候限制了看代码的时间,实际上不少代码属于框架自动生成,并不需要花费太多时间看,为了达标,需要刷点时间(鼠标点击网页固定区域).我想到可以利用自动化测试的手段完成这种无效的体力劳动. 首先,明确一下需求: 自动打开网页 登陆账号 每隔一定时间点击一下固定区域 我想到的方案有两个,sikuli或者python+selenium.sikuli的优点是逻辑操作简单直接,使用图片作为标示,缺点是需要窗口固定,并且无法后台运行.selenium稍复杂一定,但是运行速度快,窗口可
-
python+selenium 定位到元素,无法点击的解决方法
报错 selenium.common.exceptions.WebDriverException: Message: Element is not clickable at point (234.75, 22). Other element would receive the click: <img class="logo" src="/public/desktop/common/img/game_logo.png"> 需要点击的按钮页面显示不了,需要下
-
Selenium定位元素操作示例
本文实例讲述了Selenium定位元素操作.分享给大家供大家参考,具体如下: Selenium是一个用于Web应用程序测试的工具.Selenium测试直接运行在浏览器中,就像真正的用户在操作一样.支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等.这个工具的主要功能包括:测试与浏览器的兼容性--测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上.测试系统功能--创建回归测试检验软件功能和用户需
-
selenium+python自动化测试之页面元素定位
上一篇博客selenium+python自动化测试(二)–使用webdriver操作浏览器讲解了使用webdriver操作浏览器的各种方法,可以实现对浏览器进行操作了,接下来就是对浏览器页面中的元素进行操作,操作页面元素,首先要找到操作的元素,对元素进行定位 查看页面源码 要定位页面元素,需要找到页面的源码,IE浏览器中,打开页面后,在页面上点击鼠标右键,会有"查看源代码"的选项,点击后就会进入页面源码页面,在这里就可以找到页面的所有元素 使用Chrome浏览器打开页面后,在浏览器的地
-
基于selenium 获取新页面元素失败的解决方法
当我们使用selenium 实现模拟登陆时,获取到登陆按钮元素后,直接调用它的click()方法就能实现登陆跳转,并且此时的webDriver 也是指向 当前页面,这个是没问题的,不过需要注意的是因为页面加载速度一般小于程序运行速度,所以在获取登陆后页面的元素之前,可以用WebDriverWait的util方法解决,也可以直接通过Thread.sleep()让程序睡眠一会(不推荐). 但是博主要说的重点是如果我们是通过点击普通超链接进入到新页面,那么通过上面的方法是获取不到新页面元素的,因为此时
-
Python 中的Selenium异常处理实例代码
自动化测试执行过程中,难免会有错误/异常出现,比如测试脚本没有发现对应元素,则会立刻抛出NoSuchElementException异常.这时不要怕,肯定是测试脚本或者测试环境哪里出错了!那如何处理才是关键?因为一般只是局部有问题,为了让脚本继续执行,so我们可以用try...except...raise捕获异常.该捕获异常后可以打印出相应的异常原因,这样以便于分析异常原因. 下面将举例说明,当异常抛出后将信息打印在控制台,同时截取当前浏览器窗口,作为后续bug的依据给相应开发人员更好下定位问题
-
Python selenium 三种等待方式详解(必会)
很多人在群里问,这个下拉框定位不到.那个弹出框定位不到-各种定位不到,其实大多数情况下就是两种问题:1 有frame,2 没有加等待.殊不知,你的代码运行速度是什么量级的,而浏览器加载渲染速度又是什么量级的,就好比闪电侠和凹凸曼约好去打怪兽,然后闪电侠打完回来之后问凹凸曼你为啥还在穿鞋没出门?凹凸曼分分中内心一万只羊驼飞过,欺负哥速度慢,哥不跟你玩了,抛个异常撂挑子了. 那么怎么才能照顾到凹凸曼缓慢的加载速度呢?只有一个办法,那就是等喽.说到等,又有三种等法,且听博主一一道来: 1. 强制等待
-
Pycharm无法使用已经安装Selenium的解决方法
电脑C盘安装python27的时候也安装了selenium,但是最近刚刚使用工具Pycharm,新建工程后,然后建立.py文件后,使用语句:from selenium.webdriver.support.wait import WebDriverWait 接着提示没有selenium这个模块,后来发现,在Pycharm上运行脚本时,使用的是其自带的虚拟环境,而不是电脑已经装配好的python27的环境: 该环境本身缺少很多外部库,尝试在此环境下装selenium,但是失败了: 所以,接下来只能P
-

python模块的安装以及安装失败的解决方法
Python 模块安装 一. 打开命令提示符 win + R 输入 cmd 点击确定 或者win + S 搜索输入 cmd 二. 环境变量没有问题的前提下 输入安装命令 pip install 模块名 如果你要安装 requests 模块 就输入 pip install requests 回车 如果你要安装selenium 模块 就输入 pip install selenium 回车 - Requirement already satisfied: 表示之前已经安装过这个模块 下面的 WARNI
-
Python中pyecharts安装及安装失败的解决方法
pyecharts 是一个用于生成 Echarts 图表的类库.Echarts 是百度开源的一个数据可视化 JS 库.这篇文章重点给大家介绍pyecharts安装失败的处理方法,具体详情如下: pyecharts库的安装 1.正常安装 首先在打开终端输入以下命令:pip install pyecharts 在终端输入pip list查看是否安装成功测试程序: from pyecharts.charts import Bar bar = Bar() bar.add_xaxis(["衬衫"
-
electron demo项目npm install安装失败的解决方法
electron官网提供的demo项目,在npm install 的时候总是报错显示安装失败, 解决办法:FQ即可成功安装. 以上这篇electron demo项目npm install安装失败的解决方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们. 您可能感兴趣的文章: 解决npm安装Electron缓慢网络超时导致失败的问题
-
pycharm new project变成灰色的解决方法
在ubuntu下面发生的 原因是:开了多个pycharm,关掉那个new project选项是灰色的,剩下的那个pycharm的new project应该就能用. 以上这篇pycharm new project变成灰色的解决方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
mysql本地登录无法使用端口号登录的解决方法
最近在使用linux上进行本地登录时,发现既然无法正常登录 , 报如下错误信息: [root@xxxx ~]# mysql -h localhost -u root -p -P 3306 Enter password: ERROR 2002 (HY000): Can't connect to local MySQL server through socket '/tmp/mysql.sock' (2) 分析:使用mysql --verbose --help进行分析,才发现原来port和socke
-
Pycharm无法显示动态图片的解决方法
最近在学习的时候遇到了一个问题始终没有解决,这个博客写的也不是完全解决了这个问题.指示换了一种可行的思路而已. 在运行一些显示动态的图片时,Pycharm只显示一帧,也没有找到什么解决办法,试着把项目在cmd指令下运行,发现竟然可以解决.所以原问题如果没有找到什么解决办法可以考虑这么做,如果找到了解决办法再更一下.实现的是python调用matplotlib画电视没有台的情形. import numpy as np from matplotlib import pyplot as plt fro
-
pycharm不能运行.py文件的解决方法
我的pycharm总会出现如下图中的问题: 按快捷键运行也不行,查了半天网上没人遇到这种错误??为什么我的code之路如此艰难T.T记录一下我的解决办法: 点这里: 编辑结构,然后出现: 按照图上步骤依次设置,点击确定.再点击运行按钮即可.虽然右键文件还是会出现不至于,但是直接点击右上角运行按钮即可正常运行. 以上这篇pycharm不能运行.py文件的解决方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
VisualStudio Community2019在安装的过程中无法进入安装界面的解决方法
今天在安装VS2019的时候,在安装的过程中一直无法进入安装界面,在网上找了各种方法试了将近40分钟都没有找到有效的办法,不过就快放弃的时候,问题解决了,哈哈哈!!!! 1.下载地址:https://visualstudio.microsoft.com/zh-hans/thank-you-downloading-visual-studio/?sku=Community&rel=16(官网) 2.运行之后,读完进度条之后,就退出了,无法进入到安装界面.类似下面的截图,截图是网上找的,懒得自己在重新
-
flutter的环境安装配置问题及解决方法
Flutter简介 Flutter是Google推出的基于Dart语言开发的跨平台开源UI框架,旨在统一纷纷扰扰的跨平台开发框架,在UI层面上多端共用一套Dart代码来实现多平台适配开发.目前应用比较广泛的还是移动端iOS和安卓,虽然传言Fuchsia会是亲儿子项目,那也不是当下考虑的. 下面重点给大家介绍下flutter的环境安装配置问题及解决方法. (1)安装android SDK时,会出现Android license 的问题,将JAVA JDK降级到SE8就可以了,很多版本没对应上,JA