Facebook开源一站式服务python时序利器Kats详解
目录
- 什么是 Kats?
- 安装 Kats
- 将数据转换为时间序列
- 预测
- 从使用 Prophet 进行预测开始:
- 可视化
- Holt-Winters
- 检测变化点
- 机器学习
- 深度学习
- 孤立点检测
- 时间序列特征
- 小结
转自微信公众号:机器学习社区,经作者授权转载
时间序列分析是数据科学中一个非常重要的领域,它主要包含统计分析、检测变化点、异常检测和预测未来趋势。然而,这些时间序列技术通常由不同的库实现。有没有一种方法可以让你在一个库中获得所有这些技术?
答案是肯定的,本文中我将分享一个非常棒的工具包 Kats,它可以完美解决上述问题。

什么是 Kats?
目前时间序列分析以及建模的技术非常多,但相对散乱,本次 FaceBook 开源了 Kats,它是一款轻量级的、易于使用的、通用的时间序列分析框架,包括:预测、异常检测、多元分析和特征提取嵌入。你可以将 Kats 视为 Python 中时间序列分析的一站式工具包。
安装 Kats
pip install --upgrade pip pip install kats
为了了解 Kats 的功能,我们将使用这个框架来分析 Kaggle 上的 StackOverflow问题计数问题。数据链接为:https://www.kaggle.com/aishu200023/stackindex
首先我们从读取数据开始。
import pandas as pd
df = pd.read_csv("MLTollsStackOverflow.csv")
# Turn the month column into datetime
df["month"] = pd.to_datetime(df["month"], format="%y-%b")
df = df.set_index("month")

现在让我们分析一下与 Python 相关的 StackOverflow 问题计数。数据被分成一列和一个测试集来评估预测。
python = df["python"].to_frame() # Split data into train and test set train_len = 102 train = python.iloc[:train_len] test = python.iloc[train_len:]
将数据转换为时间序列
首先构造一个时间序列对象。我们使用time_col_name='month'指定时间列。
from kats.consts import TimeSeriesData # Construct TimeSeriesData object ts = TimeSeriesData(train.reset_index(), time_col_name="month")
要绘制数据,调用plot方法:
ts.plot(cols=["python"])

酷!看起来关于 Python 的问题的数量随着时间的推移而增加。我们能预测未来30天的趋势吗?是的,我们可以和 Kats 一起做。
预测
Kats目前支持以下10种预测模型:
Linear
Quadratic
ARIMA
SARIMA
Holt-Winters
Prophet
AR-Net
LSTM
Theta
VAR
上述模型较多,让我们试一下其中两种类型吧!
从使用 Prophet 进行预测开始:
from kats.models.prophet import ProphetModel, ProphetParams # Specify parameters params = ProphetParams(seasonality_mode="multiplicative") # Create a model instance m = ProphetModel(ts, params) # Fit mode m.fit() # Forecast fcst = m.predict(steps=30, freq="MS") fcst

可视化
m.plot()

酷!让我们通过与测试数据的比较来评估预测。
import matplotlib.pyplot as plt fig, ax = plt.subplots(figsize=(12, 7)) train.plot(ax=ax, label="train", color="black") test.plot(ax=ax, color="black") fcst.plot(x="time", y="fcst", ax=ax, color="blue") ax.fill_between(test.index, fcst["fcst_lower"], fcst["fcst_upper"], alpha=0.5) ax.get_legend().remove()
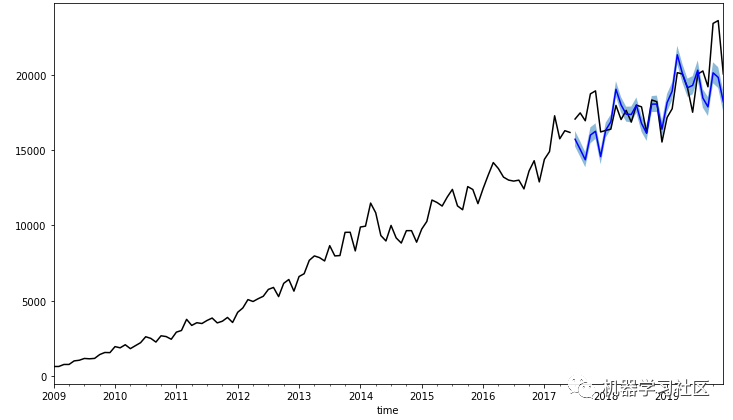
预报似乎很好地符合观察结果!
Holt-Winters
我们将尝试的下一个模式是Holt-Winters。它是一种捕捉季节性的方法。下面是如何在 Kats 中使用 Holt-Winters 方法。
from kats.models.holtwinters import HoltWintersParams, HoltWintersModel
import warnings
warnings.simplefilter(action='ignore')
params = HoltWintersParams(
trend="add",
seasonal="mul",
seasonal_periods=12,
)
m = HoltWintersModel(
data=ts,
params=params)
m.fit()
fcst = m.predict(steps=30, alpha = 0.1)
m.plot()

检测变化点
你有没有想过在你的时间序列中发生统计上显著的均值变化的时间?

Kats 允许使用 CUSUM 算法检测变化点。Cusum 是一种检测时间序列中均值上下移动的方法。
让我们看看如何检测 Kats 中的变化点。
from kats.consts import TimeSeriesData, TimeSeriesIterator
from kats.detectors.cusum_detection import CUSUMDetector
import matplotlib.pyplot as plt
detector = CUSUMDetector(ts)
change_points = detector.detector(change_directions=["increase", "decrease"])
print("The change point is on", change_points[0][0].start_time)
# plot the results
plt.xticks(rotation=45)
detector.plot(change_points)
plt.show()

酷!让我们尝试检测 StackOverflow 问题计数的其他类别的变化点。
首先创建一个函数来检测主题提供的更改点。
def get_ts(topic: str):
return TimeSeriesData(df[topic].to_frame().reset_index(), time_col_name="month")
def detect_change_point(topic: str):
ts = get_ts(topic)
detector = CUSUMDetector(ts)
change_points = detector.detector()
for change_point in change_points:
print("The change point is on", change_point[0].start_time)
# plot the results
plt.xticks(rotation=45)
detector.plot(change_points)
plt.show()
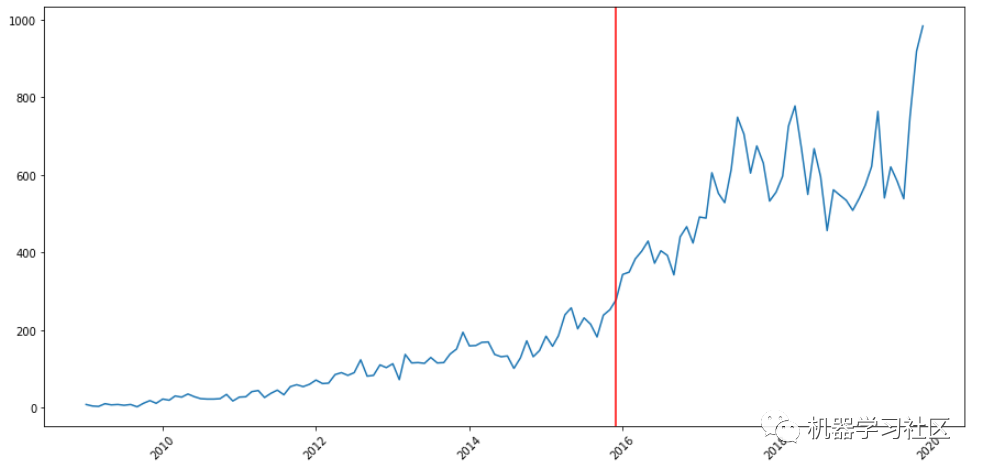
机器学习
detect_change_point("machine-learning")
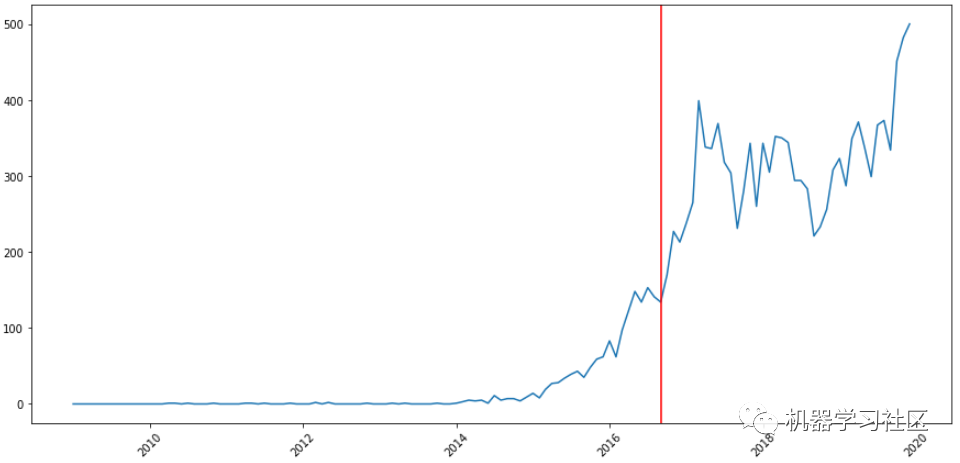
深度学习
detect_change_point("deep-learning")
孤立点检测
你在看NLP的时间序列时看到了什么?
df["nlp"].plot()

从2018年到2019年,NLP的问题数量有所下降。
问题数量的下降是一个异常值。检测异常值很重要,因为它们可能会在下游处理中造成问题。
然而,通过查看数据来发现异常值并不总是高效和容易的。幸运的是,Kats还允许您检测时间序列中的异常值!
用kat检测异常值只需要几行行代码。
from kats.detectors.outlier import OutlierDetector
# Get time series object
ts = get_ts("nlp")
# Detect outliers
ts_outlierDetection = OutlierDetector(ts, "additive")
ts_outlierDetection.detector()
# Print outliers
outlier_range1 = ts_outlierDetection.outliers[0]
print(f"The outliers range from {outlier_range1[0]} to {outlier_range1[1]}")
The outliers range from 2018-01-01 00:00:00 to 2019-03-01 00:00:00
酷!结果证实了我们从上图中看到的情况。
时间序列特征
除了统计数据外,时间序列中还有其他一些特性,如线性、趋势强度、季节性强度、季节性参数等,您可能会感兴趣。
Kats 允许通过 TsFeatures 查找有关时间序列特征的重要信息:
from kats.tsfeatures.tsfeatures import TsFeatures model = TsFeatures() output_features = model.transform(ts) output_features

小结
我们刚刚学习了如何使用 Kats 来预测、检测变化点、检测异常值和提取时间序列特征。我希望这篇文章能帮助到大家解决工作中的时间序列问题,并从数据中提取有价值的信息。
以上就是Facebook开源一站式服务python时序利器Kats详解的详细内容,更多关于Facebook开源时序利器Kats的资料请关注我们其它相关文章!
相关推荐
-
pyhton学习与数据挖掘self原理及应用分析
目录 1. 什么是class,什么是instance,什么是object? 2. 什么是method,什么是function? 3. 重点SELF分析 总结 对,你没看错,这是我初学 python 时的灵魂发问. 我们总会在class里面看见self,但是感觉他好像也没什么用处,就是放在那里占个位子. 如果你也有同样的疑问,那么恭喜你,你的class没学明白. 所以,在解释self是谁之前,我们先明确几个问题: 什么是class,什么是instance? 什么是object? 什么是method
-

python机器学习使数据更鲜活的可视化工具Pandas_Alive
目录 安装方法 使用说明 支持示例展示 水平条形图 垂直条形图比赛 条形图 饼图 多边形地理空间图 多个图表 总结 数据动画可视化制作在日常工作中是非常实用的一项技能.目前支持动画可视化的库主要以Matplotlib-Animation为主,其特点为:配置复杂,保存动图容易报错. 安装方法 pip install pandas_alive # 或者 conda install pandas_alive -c conda-forge 使用说明 pandas_alive 的设计灵感来自 bar_ch
-
提高python代码可读性利器pycodestyle使用详解
目录 关于PEP-8 目的 安装 基本用法 高级用法 结论 编程是数据科学中不可或缺的技能,虽然创建脚本来执行基本功能很容易,但编写大规模可读性良好的代码需要更多的思考. 关于PEP-8 pycodestyle 检查器提供基于 PEP-8 样式约定的代码建议.那么 PEP-8 到底是什么呢? PEP 代表 Python 增强建议,PEP-8 是一个概述编写 Python 代码最佳实践的指南.它的主要目标是通过标准化代码样式来提高代码的整体一致性和可读性. 目的 快速浏览一下PEP-8文档,就会发
-
pyCaret效率倍增开源低代码的python机器学习工具
目录 PyCaret 时间序列模块 加载数据 初始化设置 统计测试 探索性数据分析 模型训练和选择 保存模型 PyCaret 是一个开源.低代码的 Python 机器学习库,可自动执行机器学习工作流.它是一种端到端的机器学习和模型管理工具,可以以指数方式加快实验周期并提高您的工作效率.欢迎收藏学习,喜欢点赞支持,文末提供技术交流群. 与其他开源机器学习库相比,PyCaret 是一个替代的低代码库,可用于仅用几行代码替换数百行代码. 这使得实验速度和效率呈指数级增长. PyCaret 本质上是围绕
-
python数据挖掘使用Evidently创建机器学习模型仪表板
目录 1.安装包 2.导入所需的库 3.加载数据集 4.创建模型 5.创建仪表板 6.可用报告类型 1)数据漂移 2)数值目标漂移 3)分类目标漂移 4)回归模型性能 5)分类模型性能 6)概率分类模型性能 解释机器学习模型是一个困难的过程,因为通常大多数模型都是一个黑匣子,我们不知道模型内部发生了什么.创建不同类型的可视化有助于理解模型是如何执行的,但是很少有库可以用来解释模型是如何工作的. Evidently 是一个开源 Python 库,用于创建交互式可视化报告.仪表板和 JSON 配置文
-
python算法深入理解风控中的KS原理
目录 一.业务背景 二.直观理解区分度的概念 三.KS统计量的定义 四.KS计算过程及业务分析 KS常用的计算方法: 上标指标计算逻辑: 五.风控中选择KS的原因 例1:模糊性 例2:连续性 一.业务背景 在金融风控领域,常常使用KS指标来衡量评估模型的区分度(discrimination),这也是风控模型最为追求的指标之一.下面将从区分度概念.KS计算方法.业务指导意义.几何解析.数学思想等角度,对KS进行深入剖析. 二.直观理解区分度的概念 在数据探索中,若想大致判断自变量x对因变量y有没有
-
Facebook开源一站式服务python时序利器Kats详解
目录 什么是 Kats? 安装 Kats 将数据转换为时间序列 预测 从使用 Prophet 进行预测开始: 可视化 Holt-Winters 检测变化点 机器学习 深度学习 孤立点检测 时间序列特征 小结 转自微信公众号:机器学习社区,经作者授权转载 时间序列分析是数据科学中一个非常重要的领域,它主要包含统计分析.检测变化点.异常检测和预测未来趋势.然而,这些时间序列技术通常由不同的库实现.有没有一种方法可以让你在一个库中获得所有这些技术? 答案是肯定的,本文中我将分享一个非常棒的工具包 Ka
-
Python自动化测试利器selenium详解
目录 1 自动化测试 1.1 单元测试 1.2 接口测试 1.3 UI测试 1.3.1 UI自动化测试的优点 1.3.2 UI自动化测试的适用对象 1.4 自动化测试流程 2 selenium 3 selenium IDE 录制脚本 1 自动化测试 自动化测试指软件测试的自动化,在预设状态下运行应用程序或者系统,预设条件包括正常和异常,最后评估运行结果.将人为驱动的测试行为转化为机器执行的过程. 自动化测试包括UI自动化,接口自动化,单元测试自动化.按照这个金字塔模型来进行自动化测试规划,可以产
-
ImageMagick免费开源图片批处理利器使用详解
目录 正文 1. Homebrew 2. MacPorts 3. 下载官方安装包 常用的 ImageMagick 命令案例 剪裁图片 改变图片大小 图片旋转 添加图片水印 文字水印 压缩图片 调整图片大小 旋转图片 裁剪图片 图像模糊 添加水印 将目录下的所有图片全部裁剪并保存到另一个目录中: 总结 正文 ImageMagick是一个开源的图形图像编辑软件库,可以通过命令行或API与许多编程语言进行交互.它可以用于创建.编辑和合成位图图像,并支持超过100种文件格式.他支持许多常见的图像处理操作
-
python http服务flask架构实用代码详解分析
依赖库 flask安装,使用豆瓣源加速. pip install flask -i https://pypi.douban.com/simple gevent安装,使用豆瓣源加速. pip install gevent -i https://pypi.douban.com/simple 代码 #!/user/bin/env python # coding=utf-8 """ @project : TestDemo @author : huyi @file : app.py @
-
Python locust工具使用详解
今年负责部门的人员培养工作,最近在部门内部分享和讲解了locust这个工具,今天再博客园记录下培训细节.相信你看完博客,一定可以上手locust这个性能测试框架了. 一.简介 1.优势 locust是python语言开发的一款的开源的的性能测试框架,他比jmeter更加的轻量级,主要是通过协程(gevent)的方式去实现并发,通过协程的方式可以大幅提高单机的并发能力,同时避免系统级的资源调度.locust具有开源性.分布式.支持高并发,支持webUI的操作方式. 2.劣势 locust的图表功能
-
Python 异常处理的实例详解
Python 异常处理的实例详解 与许多面向对象语言一样,Python 具有异常处理,通过使用 try...except 块来实现. Note: Python v s. Java 的异常处理 Python 使用 try...except 来处理异常,使用 raise 来引发异常.Java 和 C++ 使用 try...catch 来处理异常,使用 throw 来引发异常. 异常在 Python 中无处不在:实际上在标准 Python 库中的每个模块都使用了它们,并且 Python 自已会在许多不
-
Python模块WSGI使用详解
WSGI(Web Server Gateway Interface):Web服务网关接口,是Python中定义的服务器程序和应用程序之间的接口. Web程序开发中,一般分为服务器程序和应用程序.服务器程序负责对socket服务的数据进行封装和整理,而应用程序则负责对Web请求进行逻辑处理. Web应用本质上也是一个socket服务器,用户的浏览器就是一个socket客户端. 我们先用socket编程实现一个简单的Web服务器: import socket def handle_request(c
-
Docker如何部署Python项目的实现详解
Docker 是一个开源项目,为开发人员和系统管理员提供了一个开放平台,可以将应用程序构建.打包为一个轻量级容器,并在任何地方运行.Docker 会在软件容器中自动部署应用程序. 在本篇中,我将介绍如何 docker 化一个 Python Django 应用程序,然后使用一个 docker-compose 脚本将应用程序作为容器部署到 docker 环境. 环境 操作系统 dbnuo@localhost ~ sw_vers ProductName: Mac OS X ProductVersion
-
cookies应对python反爬虫知识点详解
在保持合理的数据采集上,使用python爬虫也并不是一件坏事情,因为在信息的交流上加快了流通的频率.今天小编为大家带来了一个稍微复杂一点的应对反爬虫的方法,那就是我们自己构造cookies.在开始正式的构造之前,我们先进行简单的分析如果不构造cookies爬虫时会出现的一些情况,相信这样更能体会出cookies的作用. 网站需要cookies才能正常返回,但是该网站的cookies过期很快,我总不能用浏览器开发者工具获取cookies,然后让程序跑一会儿,每隔几分钟再手动获取cookies,再让
-
python闭包的实例详解
1.在外部函数中定义内部函数,内部函数包含访问外部函数.即使外部函数的生命周期结束后,内部函数仍然可以访问外部函数变量. 2.外部函数的返回值是内部函数本身. 实例 def outer(): cheer = 'hello ' def inner(name): return cheer + name return inner if __name__ == "__main__": #输出hello kevin print(outer()('kevin')) 知识点扩展: 闭包的概念 我们尝