MySQL 大表的count()优化实现
以下是基于我结合B+树的数据结构和对实验结果的推测作出的判断,如有错误,恳请指正!
今天实验了一下MySQL的count()操作优化, 以下讨论基于mysql5.7 InnoDB存储引擎. x86 windows操作系统。
创建的表的结构如下(数据量为100万):
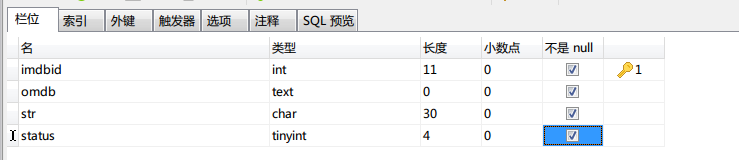
首先是关于mysql的count(*),count(PK), count(1)哪个快的问题。
实现结果如下:
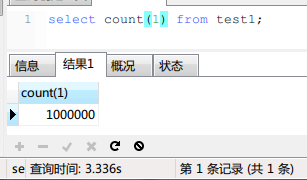
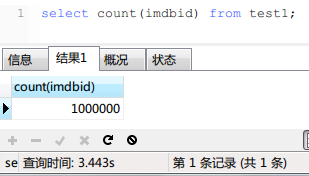
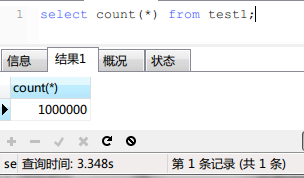
并没有什么区别!加上了WHERE子句之后3个查询的时间也是相同的,我就不贴图片了。
之前在公司的时候就写过一个select count(*) from table的SQL语句,在数据多的时候非常慢。所以要怎么优化呢?
这要从InnoDB的索引说起, InnoDB的索引是B+Tree。
对主键索引来说:它只有在叶子节点上存储数据,它的key是主键,并且value为整条数据。
对辅助索引来说:key为建索引的列,value为主键。
这给我们两个信息:
1. 根据主键会查到整条数据
2. 根据辅助索引只能查到主键,然后必须通过主键再查到剩余信息。
所以如果要优化count(*)操作的话,我们需要找一个短小的列,为它建立辅助索引。
在我的例子中就是status,虽然它的”severelity”几乎为0.
先建立索引:ALTER TABLE test1 ADD INDEX (status);
然后查询,如下图:
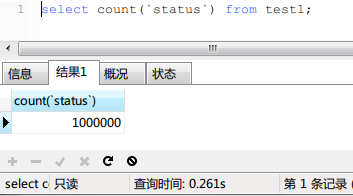
可以看到,查询时间从3.35s下降到了0.26s,查询速度提升近13倍。
如果索引是str这一列,结果又会是怎么样呢?
先建立索引: alter table test1 add index (str)
结果如下:
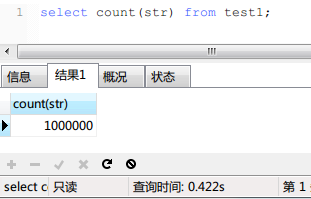
可以看到,时间为0.422s,也很快,但是比起status这列还是有着1.5倍左右的差距。
再大胆一点做个实验,我把status这列的索引删掉,建立一个status和left(omdb,200)(这一列平均1000个字符)的联合索引,然后看查询时间。
建立索引: alter table test1 add index (status,omdb(200))
结果如下:
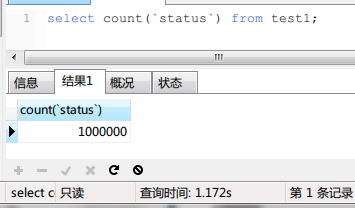
时间为1.172s
alter table test1 add index (status,imdbid);
补充!!
要注意索引失效的情况!
建立了索引后正常的的样子:

可以看到key_len为6, Extra的说明是using index.
而如果索引失效的话:

索引失效有很多种情况,比如使用函数,!=操作等,具体请参考官方文档。
对MySQL没有很深的研究,以上是基于我结合B+树的数据结构和对实验结果的推测作出的判断,如有错误,恳请指正!
到此这篇关于MySQL 大表的count()优化实现的文章就介绍到这了,更多相关MySQL 大表count()优化内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
关于mysql中innodb的count优化问题分享
一般采用二级索引去count:比如:id 是pk aid是secondary index 采用 复制代码 代码如下: select count(*) from table where id >=0;或select count(*) from table; 效果是一样的,都是默认使用pk索引,且都要全表扫描,虽然第一种性能可能高一些,但是没有明显区别. 但是如果用secondary index 复制代码 代码如下: select count(*) from table where aid>=0;
-
MySQL中聚合函数count的使用和性能优化技巧
本文的环境是Windows 10,MySQL版本是5.7.12-log 一. 基本使用 count的基本作用是有两个: 统计某个列的数据的数量: 统计结果集的行数: 用来获取满足条件的数据的数量.但是其中有一些与使用中印象不同的情况,比如当count作用一列.多列.以及使用*来表达整行产生的效果是不同的. 示例表如下: CREATE TABLE `NewTable` ( `id` int(11) NULL DEFAULT NULL , `name` varchar(30) NULL DEFAUL
-

MySQL 大表的count()优化实现
以下是基于我结合B+树的数据结构和对实验结果的推测作出的判断,如有错误,恳请指正! 今天实验了一下MySQL的count()操作优化, 以下讨论基于mysql5.7 InnoDB存储引擎. x86 windows操作系统. 创建的表的结构如下(数据量为100万): 首先是关于mysql的count(*),count(PK), count(1)哪个快的问题. 实现结果如下: 并没有什么区别!加上了WHERE子句之后3个查询的时间也是相同的,我就不贴图片了. 之前在公司的时候就写过一个select
-
浅谈MySQL大表优化方案
背景 阿里云RDS FOR MySQL(MySQL5.7版本)数据库业务表每月新增数据量超过千万,随着数据量持续增加,我们业务出现大表慢查询,在业务高峰期主业务表的慢查询需要几十秒严重影响业务 方案概述 一.数据库设计及索引优化 MySQL数据库本身高度灵活,造成性能不足,严重依赖开发人员的表设计能力以及索引优化能力,在这里给几点优化建议 时间类型转化为时间戳格式,用int类型储存,建索引增加查询效率 建议字段定义not null,null值很难查询优化且占用额外的索引空间 使用TINYINT类
-
MySQL大表中重复字段的高效率查询方法
MySQL大表重复字段应该如何查询到呢?这是很多人都遇到的问题,下面就教您一个MySQL大表重复字段的查询方法,供您参考. 数据库中有个大表,需要查找其中的名字有重复的记录id,以便比较.如果仅仅是查找数据库中name不重复的字段,很容易 复制代码 代码如下: SELECT min(`id`),`name` FROM `table` GROUP BY `name`; 但是这样并不能得到说有重复字段的id值.(只得到了最小的一个id值)查询哪些字段是重复的也容易 复制代码 代码如下: SELEC
-
MySQL 大表添加一列的实现
问题参考自: https://www.zhihu.com/question/440231149 ,mysql中,一张表里有3亿数据,未分表,要求是在这个大表里添加一列数据.数据库不能停,并且还有增删改操作.请问如何操作?答案为个人原创 以前老版本 MySQL 添加一列的方式: ALTER TABLE 你的表 ADD COLUMN 新列 char(128); 会造成锁表,简易过程如下: 新建一个和 Table1 完全同构的 Table2 对表 Table1 加写锁 在表 Table2 上执行 AL
-
mysql 大表批量删除大量数据的实现方法
问题参考自:https://www.zhihu.com/question/440066129/answer/1685329456 ,mysql中,一张表里有3亿数据,未分表,其中一个字段是企业类型,企业类型是一般企业和个体户,个体户的数据量差不多占50%,根据条件把个体户的行都删掉.请问如何操作?答案为个人原创 假设表的引擎是 Innodb, MySQL 5.7+ 删除一条记录,首先锁住这条记录,数据原有的被废弃,记录头发生变化,主要是打上了删除标记.也就是原有的数据 deleted_flag
-
从云数据迁移服务看MySQL大表抽取模式的原理解析
摘要:MySQL JDBC抽取到底应该采用什么样的方式,且听小编给你娓娓道来. 小编最近在云上的一个迁移项目中被MySQL抽取模式折磨的很惨.一开始爆内存被客户怼,再后来迁移效率低下再被怼.MySQL JDBC抽取到底应该采用什么样的方式,且听小编给你娓娓道来. 1.1 Java-JDBC通信原理 JDBC与数据库之间的通信是通过socket完,大致流程如下图所示.Mysql Server ->内核Socket Buffer -> 客户端Socket Buffer ->JDBC所在的JV
-
mysql千万级数据大表该如何优化?
1.数据的容量:1-3年内会大概多少条数据,每条数据大概多少字节: 2.数据项:是否有大字段,那些字段的值是否经常被更新: 3.数据查询SQL条件:哪些数据项的列名称经常出现在WHERE.GROUP BY.ORDER BY子句中等: 4.数据更新类SQL条件:有多少列经常出现UPDATE或DELETE 的WHERE子句中: 5.SQL量的统计比,如:SELECT:UPDATE+DELETE:INSERT=多少? 6.预计大表及相关联的SQL,每天总的执行量在何数量级? 7.表中的数据:更新为主的
-
MySQL千万级数据的大表优化解决方案
目录 1.数据库设计和表创建时就要考虑性能 设计表时要注意: 索引 简言之就是使用合适的数据类型,选择合适的索引 引擎 2.sql的编写需要注意优化 3.分区 分区的好处是: 分区的限制和缺点: 分区的类型: 4.分表 5.分库 mysql数据库中的表数据量几千万后,查询速度会很慢,日常各种卡慢,严重影响使用体验.在考虑升级数据库或者换用大数据解决方案前,必须优化现有mysql数据库表设计和sql语句. 1.数据库设计和表创建时就要考虑性能 mysql数据库本身高度灵活,造成性能不足,严重依赖开
-
如何批量生成MySQL不重复手机号大表实例代码
前言 在MySQL很多测试场景,需要人工生成一些测试数据来测试.本文提供一个构造MySQL大表存储过程,可以生成包含用户名,手机号码,出生日期等字段.也可以通过滤重来使得手机号码不重复,模拟现实场景. 一.生成脚本 生成说明: 以下使用存储过程批量生成包含用户名,手机号,出生日期等字段大表. 该存储过程使用基于uid作为主键,因此会生成少量重复手机号码,后面有滤重SQL脚本. 如果想一次性生成不重复手机号码,可以考虑修改以下脚本,去掉uid,基于mobile列作为主键 DROP TABLE IF