Tensorflow加载模型实现图像分类识别流程详解
目录
- 前言
- 正文
- VGG19网络介绍
- 总结
前言
深度学习框架在市面上有很多。比如Theano、Caffe、CNTK、MXnet 、Tensorflow等。今天讲解的就是主角Tensorflow。Tensorflow的前身是Google大脑项目的一个分布式机器学习训练框架,它是一个十分基础且集成度很高的系统,它的目标就是为研究超大型规模的视觉项目,后面延申到各个领域。Tensorflow 在2015年正式开源,开源的一个月内就收获到1w多的starts,这足以说明Tensorflow的优越性以及Google的影响力。在Api方面Tensorflow为了满足绝大部分的开发者需求,这也是Google的一贯作风,集成了Java、Go、Python、C++等编程语言。
正文
图像识别是一件很有趣的事,话不多说,咱们先了解下特征提取VGG in Tensorflow。官网地址:VGG in TensorFlow · Davi Frossard。
VGG 是牛津大学的 K. Simonyan 和 A. Zisserman 在论文“Very Deep Convolutional Networks for Large-Scale Image Recognition”中提出的卷积神经网络模型。该模型在 ImageNet 中实现了 92.7% 的 top-5 测试准确率,这是一个包含 1000 个类别的超过 1400 万张图像的数据集。 在这篇简短的文章中,我们提供了 VGG16 的实现以及从原始 Caffe 模型转换为 TensorFlow 的权重。这句话是VGGNet官方的介绍,直接从它提供的数字可以看出来,它的识别率是十分高的,是不是很激动,动起手来吧。
开发步骤分4步,如下所示:
a) 依赖加载
import tensorflow as tf import numpy as np import matplotlib.pyplot as plt import os import scipy.io import scipy.misc from imagenet_classes import class_names
b)定义卷积、池化等函数
def _conv_layer(input,weight,bias):
conv = tf.nn.conv2d(input,weight,strides=[1,1,1,1],padding="SAME")
return tf.nn.bias_add(conv,bias)
def _pool_layer(input):
return tf.nn.max_pool(input,ksize=[1,2,2,1],strides=[1,2,2,1],padding="SAME")
def preprocess(image,mean_pixel):
'''简单预处理,全部图片减去平均值'''
return image-mean_pixel
def unprocess(image,mean_pixel):
return image+mean_pixel
c)图像的读取以及保存
def imread(path):
return scipy.misc.imread(path)
def imsave(image,path):
img = np.clip(image,0,255).astype(np.int8)
scipy.misc.imsave(path,image)
d) 定义网络结构,这里使用的是VGG19
def net(data_path,input_image,sess=None):
"""
读取VGG模型参数,搭建VGG网络
:param data_path: VGG模型文件位置
:param input_image: 输入测试图像
:return:
"""
layers = (
'conv1_1', 'conv1_2', 'pool1',
'conv2_1', 'conv2_2', 'pool2',
'conv3_1', 'conv3_2', 'conv3_3','conv3_4', 'pool3',
'conv4_1', 'conv4_2', 'conv4_3','conv4_4', 'pool4',
'conv5_1', 'conv5_2', 'conv5_3','conv5_4', 'pool5',
'fc1' , 'fc2' , 'fc3' ,
'softmax'
)
data = scipy.io.loadmat(data_path)
mean = data["normalization"][0][0][0][0][0]
input_image = np.array([preprocess(input_image, mean)]).astype(np.float32)#去除平均值
net = {}
current = input_image
net["src_image"] = tf.constant(current) # 存储数据
count = 0 #计数存储
for i in range(43):
if str(data['layers'][0][i][0][0][0][0])[:4] == ("relu"):
continue
if str(data['layers'][0][i][0][0][0][0])[:4] == ("pool"):
current = _pool_layer(current)
elif str(data['layers'][0][i][0][0][0][0]) == ("softmax"):
current = tf.nn.softmax(current)
elif i == (37):
shape = int(np.prod(current.get_shape()[1:]))
current = tf.reshape(current, [-1, shape])
kernels, bias = data['layers'][0][i][0][0][0][0]
kernels = np.reshape(kernels,[-1,4096])
bias = bias.reshape(-1)
current = tf.nn.relu(tf.add(tf.matmul(current,kernels),bias))
elif i == (39):
kernels, bias = data['layers'][0][i][0][0][0][0]
kernels = np.reshape(kernels,[4096,4096])
bias = bias.reshape(-1)
current = tf.nn.relu(tf.add(tf.matmul(current,kernels),bias))
elif i == 41:
kernels, bias = data['layers'][0][i][0][0][0][0]
kernels = np.reshape(kernels, [4096, 1000])
bias = bias.reshape(-1)
current = tf.add(tf.matmul(current, kernels), bias)
else:
kernels,bias = data['layers'][0][i][0][0][0][0]
#注意VGG存储方式为[,]
#kernels = np.transpose(kernels,[1,0,2,3])
bias = bias.reshape(-1)#降低维度
current = tf.nn.relu(_conv_layer(current,kernels,bias))
net[layers[count]] = current #存储数据
count += 1
return net, mean
e)加载模型进行识别
if __name__ == '__main__':
VGG_PATH = "./one/imagenet-vgg-verydeep-19.mat"
IMG_PATH = './one/3.jpg'
input_image =imread(IMG_PATH)
shape = (1, input_image.shape[0], input_image.shape[1], input_image.shape[2])
with tf.Session() as sess:
image = tf.placeholder('float', shape=shape)
nets, mean_pixel, all_layers= net(VGG_PATH, image)
input_image_pre=np.array([preprocess(input_image,mean_pixel)])
layers = all_layers
for i , layer in enumerate(layers):
print("[%d/%d] %s" % (i+1,len(layers),layers))
features = nets[layer].eval(feed_dict={image:input_image_pre})
print("Type of 'feature' is ",type(features))
print("Shape of 'features' is %s" % (features.shape,))
if 1:
plt.figure(i+1,figsize=(10,5))
plt.matshow(features[0,:,:,0],cmap=plt.cm.gray,fignum=i+1)
plt.title(""+layer)
plt.colorbar()
plt.show()
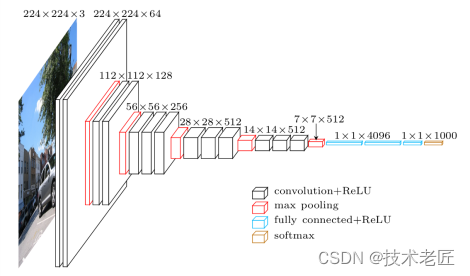
VGG19网络介绍
VGG19 的宏观架构如图所示。我们在 TensorFlow 中的文件 vgg19.py 中对其进行编码。请注意,我们包含一个预处理层,它采用像素值在 0-255 范围内的 RGB 图像并减去平均图像值(在整个 ImageNet 训练集上计算)。
总结
Tensorflow是一款十分不错的深度学习框架,它在工业上得到的十分的认可并进行了实践。因此,如果你还在犹豫生产落地使用框架,不要犹豫啦。VGGNet家族是一个十分优秀的网络结构,它在处理特征提取过程中,也是得到了很多公司和研究学者的认可,比较著名的有VGG16、VGG19等。
到此这篇关于Tensorflow加载模型实现图像分类识别流程详解的文章就介绍到这了,更多相关Tensorflow图像分类识别内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

tensorflow+k-means聚类简单实现猫狗图像分类的方法
一.前言 本文使用的是 kaggle 猫狗大战的数据集:https://www.kaggle.com/c/dogs-vs-cats/data 训练集中有 25000 张图像,测试集中有 12500 张图像.作为简单示例,我们用不了那么多图像,随便抽取一小部分猫狗图像到一个文件夹里即可. 通过使用更大.更复杂的模型,可以获得更高的准确率,预训练模型是一个很好的选择,我们可以直接使用预训练模型来完成分类任务,因为预训练模型通常已经在大型的数据集上进行过训练,通常用于完成大型的图像分类任务. tf.k
-
详解tensorflow训练自己的数据集实现CNN图像分类
利用卷积神经网络训练图像数据分为以下几个步骤 1.读取图片文件 2.产生用于训练的批次 3.定义训练的模型(包括初始化参数,卷积.池化层等参数.网络) 4.训练 1 读取图片文件 def get_files(filename): class_train = [] label_train = [] for train_class in os.listdir(filename): for pic in os.listdir(filename+train_class): class_train.app
-
tensorflow 1.0用CNN进行图像分类
tensorflow升级到1.0之后,增加了一些高级模块: 如tf.layers, tf.metrics, 和tf.losses,使得代码稍微有些简化. 任务:花卉分类 版本:tensorflow 1.0 数据:flower-photos 花总共有五类,分别放在5个文件夹下. 闲话不多说,直接上代码,希望大家能看懂:) 复制代码 # -*- coding: utf-8 -*- from skimage import io,transform import glob import os impor
-
python深度学习tensorflow训练好的模型进行图像分类
目录 正文 随机找一张图片 读取图片进行分类识别 最后输出 正文 谷歌在大型图像数据库ImageNet上训练好了一个Inception-v3模型,这个模型我们可以直接用来进来图像分类. 下载链接: https://pan.baidu.com/s/1XGfwYer5pIEDkpM3nM6o2A 提取码: hu66 下载完解压后,得到几个文件: 其中 classify_image_graph_def.pb 文件就是训练好的Inception-v3模型. imagenet_synset_to_huma
-
使用TensorFlow-Slim进行图像分类的实现
参考 https://github.com/tensorflow/models/tree/master/slim 使用TensorFlow-Slim进行图像分类 准备 安装TensorFlow 参考 https://www.tensorflow.org/install/ 如在Ubuntu下安装TensorFlow with GPU support, python 2.7版本 wget https://storage.googleapis.com/tensorflow/linux/gpu/tens
-
Tensorflow加载模型实现图像分类识别流程详解
目录 前言 正文 VGG19网络介绍 总结 前言 深度学习框架在市面上有很多.比如Theano.Caffe.CNTK.MXnet .Tensorflow等.今天讲解的就是主角Tensorflow.Tensorflow的前身是Google大脑项目的一个分布式机器学习训练框架,它是一个十分基础且集成度很高的系统,它的目标就是为研究超大型规模的视觉项目,后面延申到各个领域.Tensorflow 在2015年正式开源,开源的一个月内就收获到1w多的starts,这足以说明Tensorflow的优越性以及
-
Spring中Bean的加载与SpringBoot的初始化流程详解
目录 前言 第一章 Spring中Bean的一些简单概念 1.1 SpingIOC简介 1.2 BeanFactory 1.2.1 BeanDefinition 1.2.2 BeanDefinitionRegistry 1.2.3 BeanFactory结构图 1.3 ApplicationContext 第二章 SpringBoot的初始化流程 2.1 准备阶段 2.2 运行阶段 2.2.1 监听器分析 2.2.2 refreshContext 2.3 总结 前言 一直对它们之间的关系感到好奇
-
TensorFlow加载模型时出错的解决方式
当发现目录时出错如下: \windows\tensorflow\core\framework\op_kernel.cc:993] Not found: Unsuccessful TensorSliceReader constructor: Failed to find any matching files for params_cifar.ckpt 在Windows下要把目录写对才可以. 比如 default='tmp' 要写成这样 default='./tmp' 这样TF就找到相应的目录了.
-
Tensorflow 2.4加载处理图片的三种方式详解
目录 前言 数据准备 使用内置函数读取并处理磁盘数据 自定义方式读取和处理磁盘数据 从网络上下载数据 前言 本文通过使用 cpu 版本的 tensorflow 2.4 ,介绍三种方式进行加载和预处理图片数据. 这里我们要确保 tensorflow 在 2.4 版本以上 ,python 在 3.8 版本以上,因为版本太低有些内置函数无法使用,然后要提前安装好 pillow 和 tensorflow_datasets ,方便进行后续的数据加载和处理工作. 由于本文不对模型进行质量保证,只介绍数据的加
-
NodeJS Express使用ORM模型访问关系型数据库流程详解
目录 一.ORM模型 二.在Node中ORM的实现 一.ORM模型 设计思想,主要目的是简化计算机程序访问数据库 1.ORM:对象关系模型(对象关系映射) Object Releastion Model,将程序中的对象和数据库中关系(表格)进行映射.可以使开发者在程序中方便的对数据库进行操作(用户在程序操作对对象实际就是操作数据库的表格) 2.ORM的映射关系: (1)程序中的模型(即为类) <——>表名 (2)模型的类型(类中定义的属性)<——> 表的列 (3)由模型创建的对象(
-
基于vue中css预加载使用sass的配置方式详解
1.安装sass的依赖包 npm install --save-dev sass-loader //sass-loader依赖于node-sass npm install --save-dev node-sass 2.在build文件夹下的webpack.base.conf.js的rules里面添加配置,如下红色部分 { test: /\.sass$/, loaders: ['style', 'css', 'sass'] } <span style="color:#454545;"
-
Java使用路径通配符加载Resource与profiles配置使用详解
序言 Spring提供了一种强大的Ant模式通配符匹配,能从一个路径匹配一批资源. Ant路径通配符 Ant路径通配符支持"?"."*"."**",注意通配符匹配不包括目录分隔符"/": "?":匹配一个字符,如"config?.xml"将匹配"config1.xml": "*":匹配零个或多个字符串,如"cn/*/config.xml&
-
android加载系统相册图片并显示详解
1,下载ImageLoad.jar包放入项目libs文件夹中,并点击右键->add as Library 2,首先记得在Manifest.xml注册权限(注:6.0以后的版本要在代码中动态注册权限) <uses-permission android:name="android.permission.WRITE_EXTERNAL_STORAGE" /> <uses-permission android:name="android.permission.R
-
React 首页加载慢问题性能优化案例详解
学习了一段时间React,想真实的实践一下.于是便把我的个人博客网站进行了重构.花了大概一周多时间,网站倒是重构的比较成功,但是一上线啊,那个访问速度啊,是真心慢,慢到自己都不能忍受,那么小一个网站,没几篇文章,慢成那样,不能接受.我不是一个追求完美的人,但这样可不行.后面大概花了一点时间进行性能的研究.才发现慢是有原因的. React这类框架? 目前主流的前端框架React.Vue.Angular都是采用客户端渲染(服务端渲染暂时不在本文的考虑范围内).这当然极大的减轻了服务器的压力.相对的浏
-
java synchronized加载加锁-线程可重入详解及实例代码
java synchronized加载加锁-线程可重入 实例代码: public class ReGetLock implements Runnable { @Override public void run() { get(); } public synchronized void get() { System.out.println(Thread.currentThread().getId()); set(); } public synchronized void set() { Syste