源码解析带你了解LinkedHashMap
目录
- 元素存储关系
- 继承体系
- 属性
- 构造方法
- 无参
- 有参
- 按插入顺序访问
- newNode
- linkNodeLast
- 链表节点的删除
- LRU(Least recently used,最近最少使用)
- 栗子
- 元素被移到队尾
LinkedHashMap维护插入的顺序。
元素存储关系
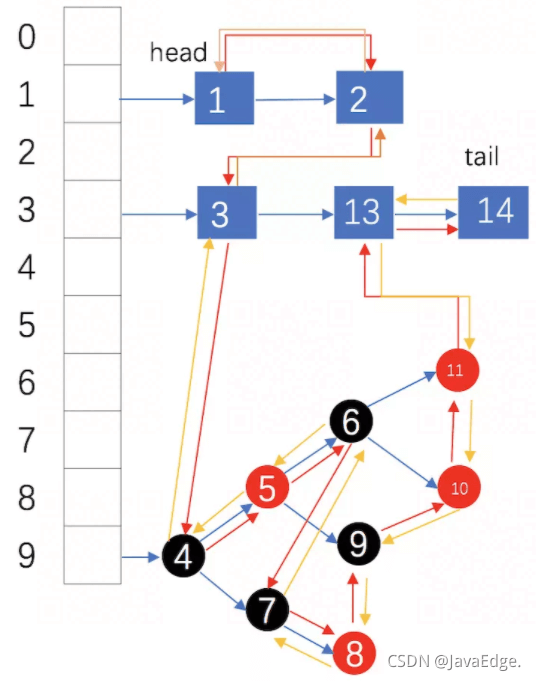
红黄箭头:元素添加顺序
蓝箭头:单链表各个元素的存储顺序
head:链表头部
tail:链表尾部
继承体系
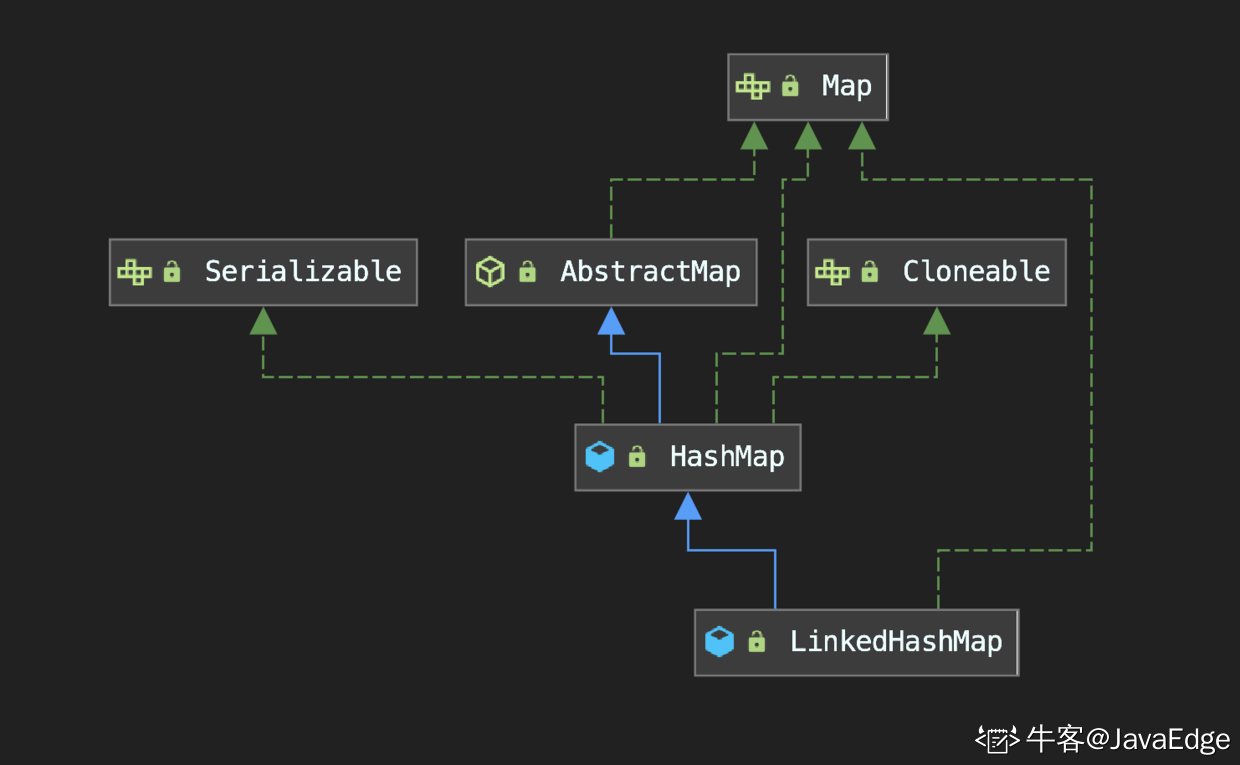
- 继承自 HashMap ,因此 HashMap 拥有的荣耀它也都有.

属性
- 双向链表的头(最老)

- 双链表的末尾(最小)

- HashMap.Node的子类:常规 LinkedHashMap 节点,增加了 before 和 after 属性,维护双向链表的结构

此 LinkedHashMap 的迭代排序方法:
- true: 访问顺序
- false(默认): 插入顺序

构造方法
构造方法都是先执行父类 HashMap 的构造方法.
无参
- 构造一个空的维护插入顺序的LinkedHashMap实例,其默认初始容量(16)和负载因子(0.75).

有参
- 构造一个空的LinkedHashMap实例,可自己指定初始容量,负载因子和排序模式.

- 构造一个维护插入顺序的LinkedHashMap实例,该实例具有与指定map相同的映射关系,创建的LinkedHashMap实例具有默认的加载因子(0.75)和足以容纳指定map中映射的初始容量.

下面我们开始研究该类的主要特性是如何通过代码实现的.
按插入顺序访问
LinkedHashMap 默认 accessOrder 为 false,提供按照插入顺序的访问,并没有重写父类 HashMap 的 put 方法.但在 HashMap 中,put 的是 HashMap 的 Node 类型节点,LinkedHashMap 的 Entry 与其结构并不同,又是怎样建立起双向链表的呢?下面一起看下 LinkedHashMap 插入相关代码.
忽略未重写的 put=>putValue代码部分,我们直接观察重写的
newNode
- HashMap

- LinkedHashMap 重写

控制新增节点追加到链表的尾部,这样每次新节点都追加到尾部,即可保证插入顺序了.
继续研究 linkNodeLast
linkNodeLast
新增节点,并追加到链表的尾部.
`// link at the end of list`
`private` `void` `linkNodeLast(LinkedHashMap.Entry<K,V> p) {`
`LinkedHashMap.Entry<K,V> last = tail;`
`// 新增于尾节点`
`tail = p;`
`// last 为null,说明链表为空`
`if` `(last == ``null``)`
`head = p;`
`// 链表非空,建立新节点和上一个尾节点的前后关系`
`else` `{`
`// 将新节点 p 直接接在链尾`
`p.before = last;`
`last.after = p;`
`}`
`}`
由此得知,通过在 HashMap 基础上新增的头尾节点,节点的 before 和 after 属性,就能实现在每次新增时,把节点直接追加到尾节点,即可达到维护按照插入顺序的链表结构的目的!
- 图解链表创建步骤
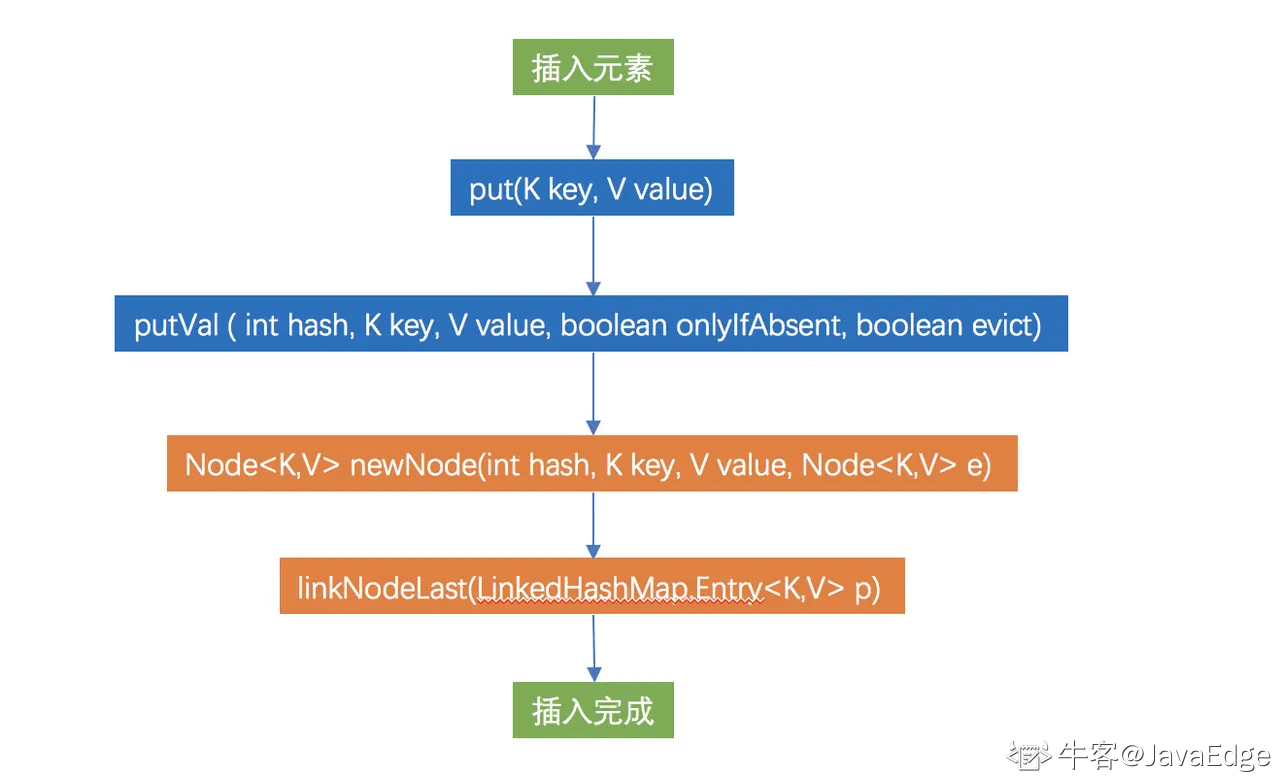
蓝色部分是 HashMap 的方法
橙色部分为 LinkedHashMap 独有方法
注意 LinkedHashMap 虽然也是双向链表,但只提供单向的按插入的顺序从头到尾访问,不及 LinkedList 般可双向无死角访问.
- LinkedHashMap 通过迭代器访问,而且默认是从头节点开始访问
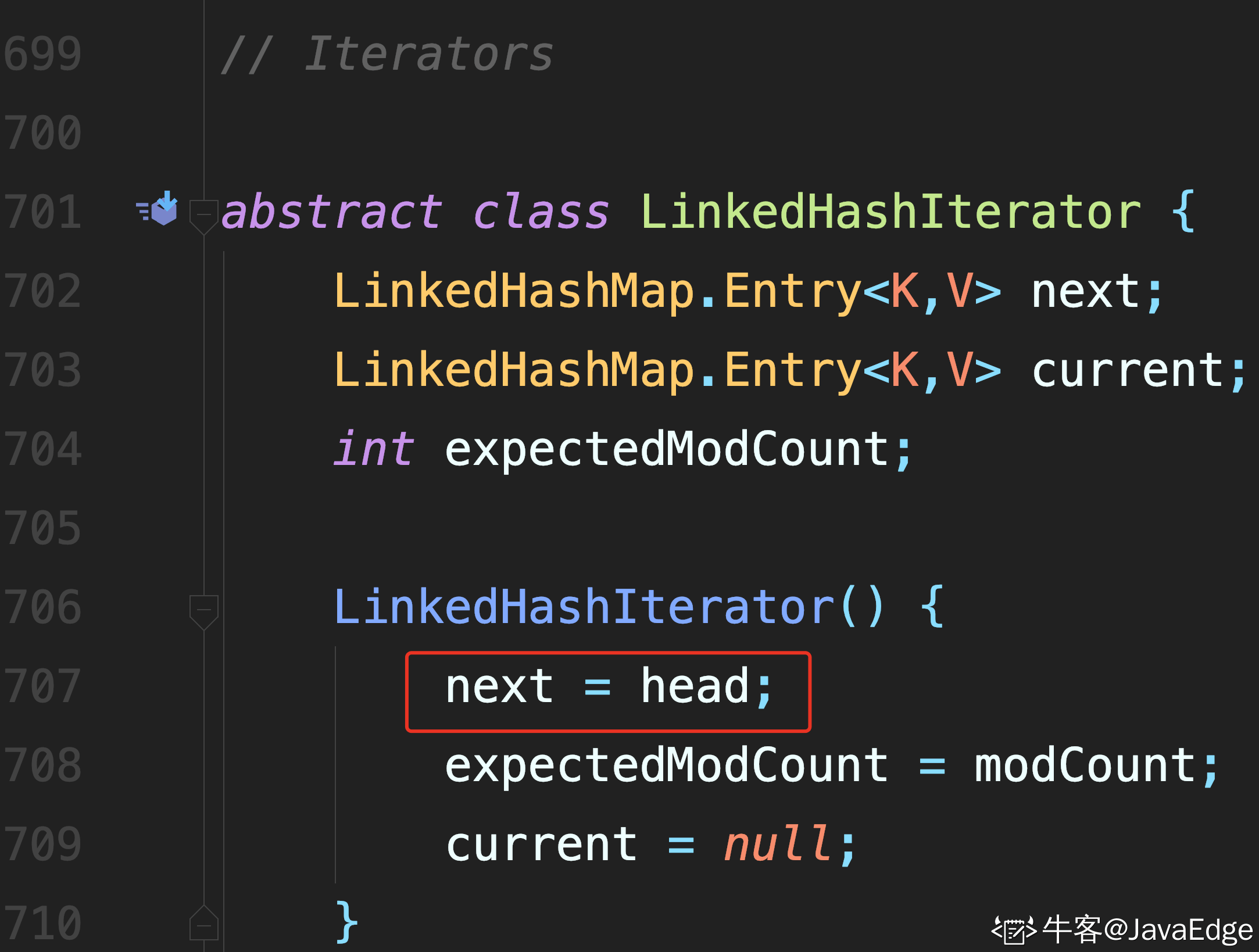
迭代过程中,不断访问 after 节点即可完成遍历.
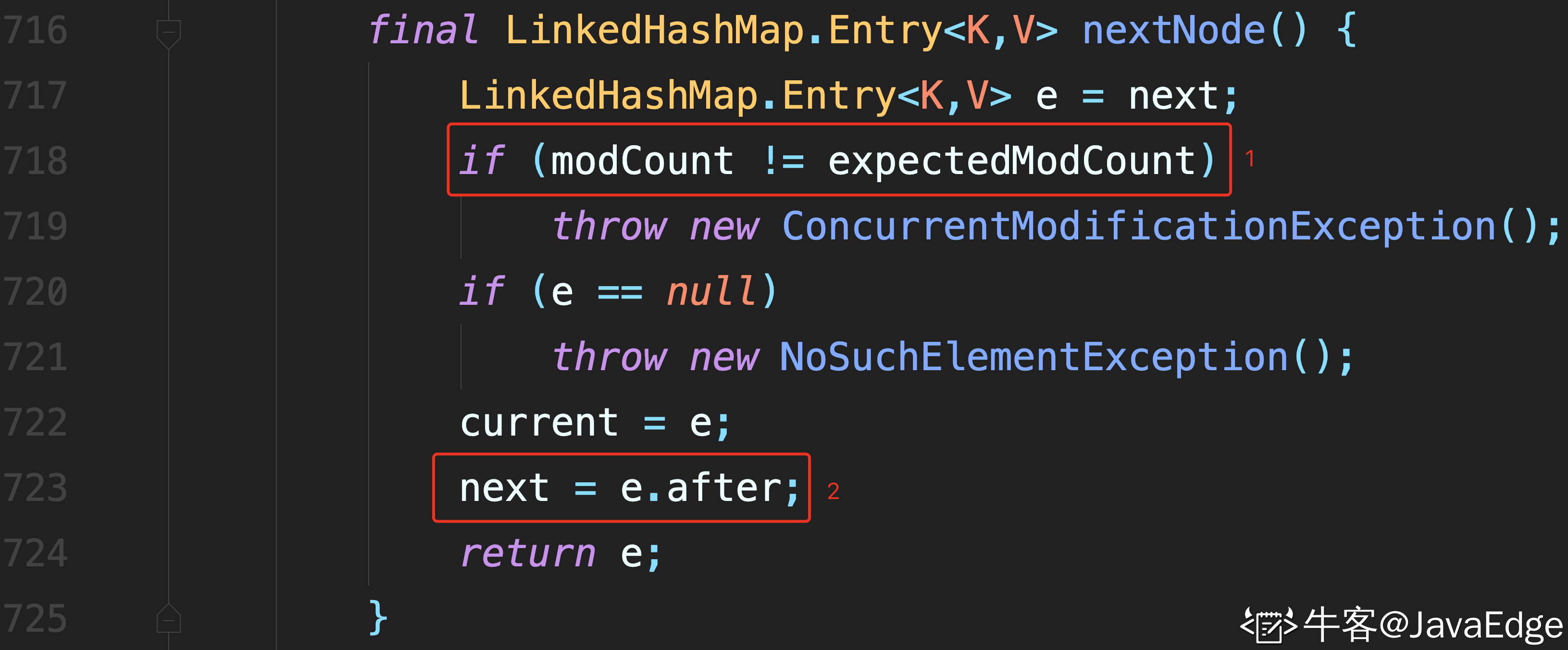
1 处进行校验
2 处通过节点的 after 属性,找到后继节点
链表节点的删除
- HashMap 中保存的允许 LinkedHashMap 后处理的回调

与插入操作一样,LinkedHashMap 删除操作相关的代码也是直接用父类的实现. 在删除节点时,父类不会修复 LinkedHashMap 的双向链表。那么删除及节点后,被删除的节点该如何从双链表中安全移除呢?其实在删除节点后,回调方法 afterNodeRemoval 会被调用。LinkedHashMap 重写了该方法.
`// e 为已经删除的节点`
`void` `afterNodeRemoval(Node<K,V> e) { ``// unlink`
`LinkedHashMap.Entry<K,V> p =`
`(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;`
`// 将 p 节点的前驱后后继引用置 null,辅助 GC`
`p.before = p.after = ``null``;`
`// p.before 为 null,表明 p 是头节点`
`if` `(b == ``null``)`
`head = a;`
`else`
`// 否则将 p 的前驱节点连接到 p 的后继节点`
`b.after = a;`
`// a 为 null,表明 p 是尾节点`
`if` `(a == ``null``)`
`tail = b;`
`else`
`// 否则将 a 的前驱节点连接到 b`
`a.before = b;`
`}`
删除元素的主要流程:
- 根据 hash 定位到桶位置
- 遍历链表或调用红黑树相关的删除方法
- 从 LinkedHashMap 维护的双链表中移除要删除的节点
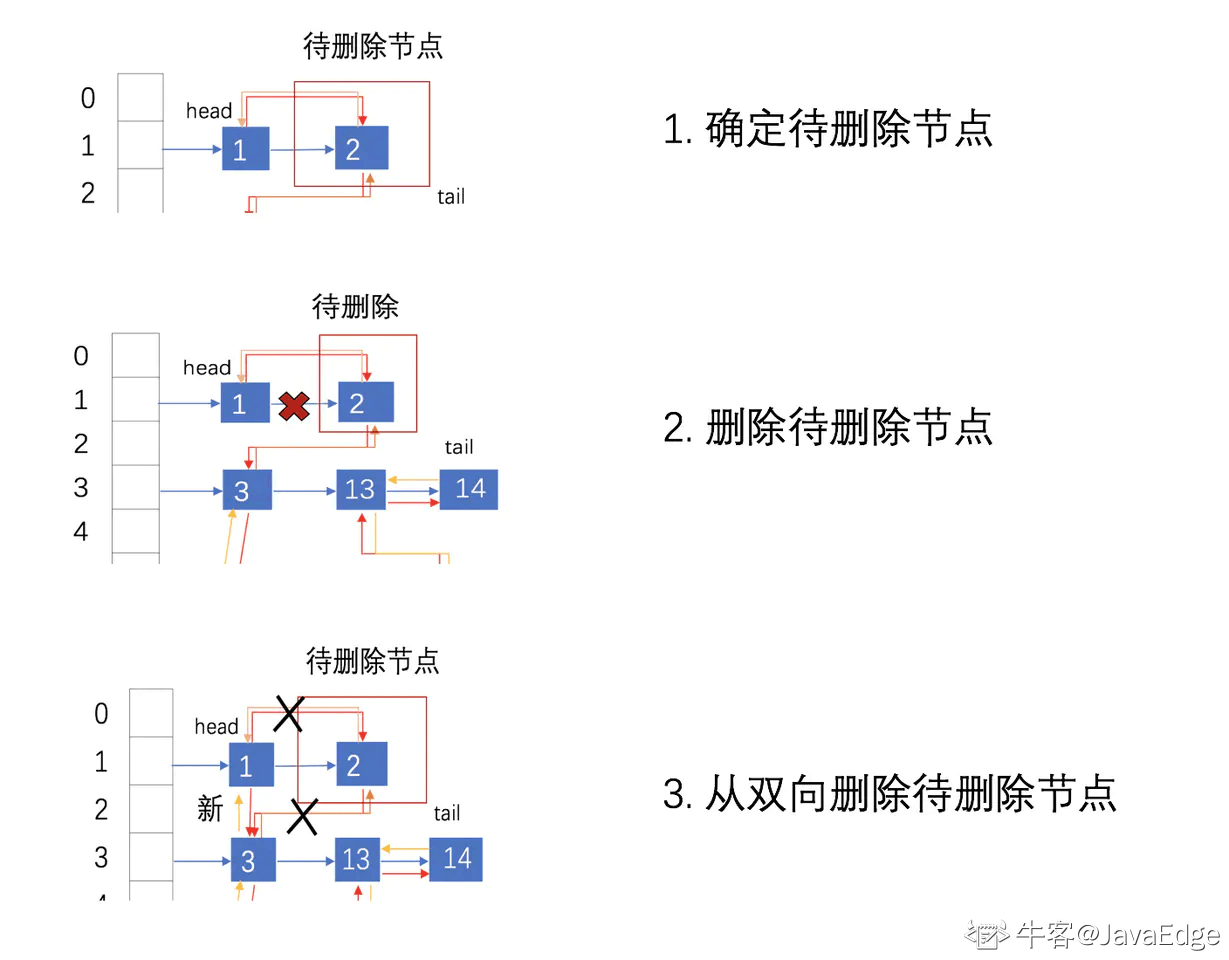
转存失败重新上传取消
LRU(Least recently used,最近最少使用)
栗子
经常访问的元素会被追加到队尾,这样不经常访问的数据自然就靠近队头,然后可以通过设置删除策略,比如当 Map 元素个数大于多少时,把头节点删除
元素被移到队尾
get 时,元素会被移动到队尾:

`public` `V get(Object key) {`
`Node<K,V> e;`
`// 调用 HashMap get 方法`
`if` `((e = getNode(hash(key), key)) == ``null``)`
`return` `null``;`
`// 如果设置了 LRU 策略`
`if` `(accessOrder)`
`// 这个方法把当前 key 移动到队尾`
`afterNodeAccess(e);`
`return` `e.value;`
`}`
从上述源码中,可以看到,通过 afterNodeAccess 方法把当前访问节点移动到了队尾,其实不仅仅是 get 方法,执行 getOrDefault、compute、computeIfAbsent、computeIfPresent、merge 方法时,也会这么做,通过不断的把经常访问的节点移动到队尾,那么靠近队头的节点,自然就是很少被访问的元素了。
到此这篇关于源码解析带你了解LinkedHashMap的文章就介绍到这了,更多相关Java LinkedHashMap内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Java集合框架源码分析之LinkedHashMap详解
LinkedHashMap简介 LinkedHashMap是HashMap的子类,与HashMap有着同样的存储结构,但它加入了一个双向链表的头结点,将所有put到LinkedHashmap的节点一一串成了一个双向循环链表,因此它保留了节点插入的顺序,可以使节点的输出顺序与输入顺序相同. LinkedHashMap可以用来实现LRU算法(这会在下面的源码中进行分析). LinkedHashMap同样是非线程安全的,只在单线程环境下使用. LinkedHashMap源码剖析 LinkedHashM
-
Java集合系列之LinkedHashMap源码分析
这篇文章我们开始分析LinkedHashMap的源码,LinkedHashMap继承了HashMap,也就是说LinkedHashMap是在HashMap的基础上扩展而来的,因此在看LinkedHashMap源码之前,读者有必要先去了解HashMap的源码,可以查看我上一篇文章的介绍<Java集合系列[3]----HashMap源码分析>.只要深入理解了HashMap的实现原理,回过头来再去看LinkedHashMap,HashSet和LinkedHashSet的源码那都是非常简单的.因此,读
-
Java中LinkedHashMap源码解析
概述: LinkedHashMap实现Map继承HashMap,基于Map的哈希表和链该列表实现,具有可预知的迭代顺序. LinedHashMap维护着一个运行于所有条目的双重链表结构,该链表定义了迭代顺序,可以是插入或者访问顺序. LintHashMap的节点对象继承HashMap的节点对象,并增加了前后指针 before after: /** * LinkedHashMap节点对象 */ static class Entry<K,V> extends HashMap.Node<K,V
-
Java LinkedHashMap 底层实现原理分析
在实现上,LinkedHashMap很多方法直接继承自HashMap,仅为维护双向链表覆写了部分方法.所以,要看懂 LinkedHashMap 的源码,需要先看懂 HashMap 的源码. 默认情况下,LinkedHashMap的迭代顺序是按照插入节点的顺序.也可以通过改变accessOrder参数的值,使得其遍历顺序按照访问顺序输出. 这里我们只讨论LinkedHashMap和HashMap的不同之处,LinkedHashMap的其他操作和特性具体请参考HashMap 我们先来看下两者的区别:
-
Java源码解析之LinkedHashMap
一.成员变量 先来看看存储元素的结构吧: static class Entry<K,V> extends HashMap.Node<K,V> { Entry<K,V> before, after; Entry(int hash, K key, V value, Node<K,V> next) { super(hash, key, value, next); } } 这个Entry在HashMap中被引用过,主要是为了能让LinkedHashMap也支持树化.
-

源码解析带你了解LinkedHashMap
目录 元素存储关系 继承体系 属性 构造方法 无参 有参 按插入顺序访问 newNode linkNodeLast 链表节点的删除 LRU(Least recently used,最近最少使用) 栗子 元素被移到队尾 LinkedHashMap维护插入的顺序. 元素存储关系 红黄箭头:元素添加顺序 蓝箭头:单链表各个元素的存储顺序 head:链表头部 tail:链表尾部 继承体系 继承自 HashMap ,因此 HashMap 拥有的荣耀它也都有. 属性 双向链表的头(最老) 双链表的末尾(最小
-
Java源码解析之HashMap的put、resize方法详解
一.HashMap 简介 HashMap 底层采用哈希表结构 数组加链表加红黑树实现,允许储存null键和null值 数组优点:通过数组下标可以快速实现对数组元素的访问,效率高 链表优点:插入或删除数据不需要移动元素,只需要修改节点引用效率高 二.源码分析 2.1 继承和实现 public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable {
-
Flink状态和容错源码解析
目录 引言 概述 State Keyed State 状态实例管理及数据存储 HeapKeyedStateBackend RocksDBKeyedStateBackend OperatorState 上层封装 总结 引言 计算模型 DataStream基础框架 事件时间和窗口 状态和容错 部署&调度 存储体系 底层支撑 Flink中提供了State(状态)这个概念来保存中间计算结果和缓存数据,按照不同的场景,Flink提供了多种不同类型的State,同时为了实现Exactly once的语义,F
-
jq源码解析之绑在$,jQuery上面的方法(实例讲解)
1.当我们用$符号直接调用的方法.在jQuery内部是如何封装的呢?有没有好奇心? // jQuery.extend 的方法 是绑定在 $ 上面的. jQuery.extend( { //expando 用于决定当前页面的唯一性. /\D/ 非数字.其实就是去掉小数点. expando: "jQuery" + ( version + Math.random() ).replace( /\D/g, "" ), // Assume jQuery is ready wit
-
Java源码解析之object类
在源码的阅读过程中,可以了解别人实现某个功能的涉及思路,看看他们是怎么想,怎么做的.接下来,我们看看这篇Java源码解析之object的详细内容. Java基类Object java.lang.Object,Java所有类的父类,在你编写一个类的时候,若无指定父类(没有显式extends一个父类)编译器(一般编译器完成该步骤)会默认的添加Object为该类的父类(可以将该类反编译看其字节码,不过貌似Java7自带的反编译javap现在看不到了). 再说的详细点:假如类A,没有显式继承其他类,编译
-
Redis源码解析:集群手动故障转移、从节点迁移详解
一:手动故障转移 Redis集群支持手动故障转移.也就是向从节点发送"CLUSTER FAILOVER"命令,使其在主节点未下线的情况下,发起故障转移流程,升级为新的主节点,而原来的主节点降级为从节点. 为了不丢失数据,向从节点发送"CLUSTER FAILOVER"命令后,流程如下: a:从节点收到命令后,向主节点发送CLUSTERMSG_TYPE_MFSTART包: b:主节点收到该包后,会将其所有客户端置于阻塞状态,也就是在10s的时间内
-
Android图片加载利器之Picasso源码解析
看到了这里,相信大家对Picasso的使用已经比较熟悉了,本篇博客中将从基本的用法着手,逐步的深入了解其设计原理. Picasso的代码量在众多的开源框架中算得上非常少的一个了,一共只有35个class文件,但是麻雀虽小,五脏俱全.好了下面跟随我的脚步,出发了. 基本用法 Picasso.with(this).load(imageUrl).into(imageView); with(this)方法 public static Picasso with(Context context) { if
-
Android源码解析之截屏事件流程
今天这篇文章我们主要讲一下Android系统中的截屏事件处理流程.用过android系统手机的同学应该都知道,一般的android手机按下音量减少键和电源按键就会触发截屏事件(国内定制机做个修改的这里就不做考虑了).那么这里的截屏事件是如何触发的呢?触发之后android系统是如何实现截屏操作的呢?带着这两个问题,开始我们的源码阅读流程. 我们知道这里的截屏事件是通过我们的按键操作触发的,所以这里就需要我们从android系统的按键触发模块开始看起,由于我们在不同的App页面,操作音量减少键和电
-
详解无限滚动插件vue-infinite-scroll源码解析
最近在项目中遇到一个需求,有一个列表需要滚动加载,类似于微博的无限滚动.当时第一反应时监听滚动事件,在判断滚动到达底部时加载下一页,同时心里也清楚,监听滚动事件需要做好截流.顺手搜索了下发现有一个现成的插件vue-infinite-scroll,用法也很简单,于是乎就用了起来. 需求上线后,对它的实现挺好奇的,于是研究了一番源码,这篇文章就是源码解析笔记. 插件使用方法 这是一个 vue 的指令,按照 github 仓库上的介绍,用法挺简单的,例如: <div class="app&quo