使用Ray集群简单创建Python分布式应用程序
目录
- 什么是 Ray
- 安装 Ray
- 使用 Ray
- 使用 Ray 集群
- 具体步骤:
- 1. 下载 ubuntu 镜像
- 2. 启动 ubuntu 容器,安装依赖
- 3. 启动 head 节点和 worker 节点
- 4、执行任务
- 最后的话
什么是 Ray
Ray 是基于 Python 的分布式计算框架,采用动态图计算模型,提供简单、通用的 API 来创建分布式应用。使用起来很方便,你可以通过装饰器的方式,仅需修改极少的的代码,让原本运行在单机的 Python 代码轻松实现分布式计算,目前多用于机器学习。
Ray 的特色:
1、提供用于构建和运行分布式应用程序的简单原语。
2、使用户能够并行化单机代码,代码更改很少甚至为零。
3、Ray Core 包括一个由应用程序、库和工具组成的大型生态系统,以支持复杂的应用程序。比如 Tune、RLlib、RaySGD、Serve、Datasets、Workflows。
安装 Ray
最简单的安装官方版本的方式:
pip install -U ray pip install 'ray[default]'
如果是 Windows 系统,要求必须安装 Visual C++ runtime
其他安装方式见官方文档。
使用 Ray
一个装饰器就搞定分布式计算:
import ray
ray.init()
@ray.remote
def f(x):
return x * x
futures = [f.remote(i) for i in range(4)]
print(ray.get(futures)) # [0, 1, 4, 9]
先执行 ray.init(),然后在要执行分布式任务的函数前加一个装饰器 @ray.remote 就实现了分布式计算。装饰器 @ray.remote 也可以装饰一个类:
import ray
ray.init()
@ray.remote
class Counter(object):
def __init__(self):
self.n = 0
def increment(self):
self.n += 1
def read(self):
return self.n
counters = [Counter.remote() for i in range(4)]
tmp1 = [c.increment.remote() for c in counters]
tmp2 = [c.increment.remote() for c in counters]
tmp3 = [c.increment.remote() for c in counters]
futures = [c.read.remote() for c in counters]
print(ray.get(futures)) # [3, 3, 3, 3]
当然了,上述的分布式计算依然是在自己的电脑上进行的,只不过是以分布式的形式。程序执行的过程中,你可以输入 http://127.0.0.1:8265/#/ 查看分布式任务的执行情况:
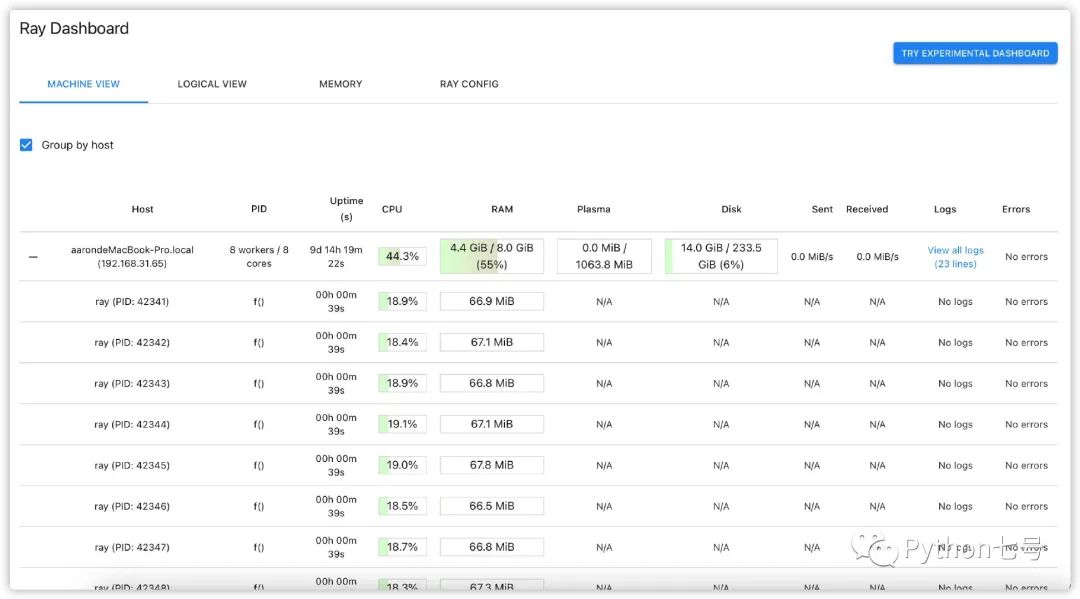
那么如何实现 Ray 集群计算呢?接着往下看。
使用 Ray 集群
Ray 的优势之一是能够在同一程序中利用多台机器。当然,Ray 可以在一台机器上运行,因为通常情况下,你只有一台机器。但真正的力量是在一组机器上使用 Ray。
Ray 集群由一个头节点和一组工作节点组成。需要先启动头节点,给 worker 节点赋予头节点地址,组成集群:
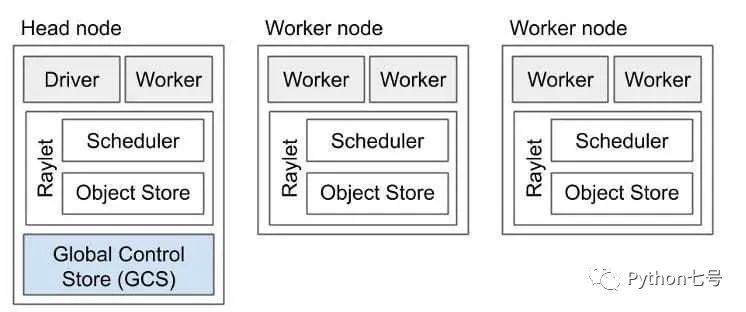
你可以使用 Ray Cluster Launcher 来配置机器并启动多节点 Ray 集群。你可以在 AWS、GCP、Azure、Kubernetes、阿里云、内部部署和 Staroid 上甚至在你的自定义节点提供商上使用集群启动器。
Ray 集群还可以利用 Ray Autoscaler,它允许 Ray 与云提供商交互,以根据规范和应用程序工作负载请求或发布实例。
现在,我们来快速演示下 Ray 集群的功能,这里是用 Docker 来启动两个 Ubuntu 容器来模拟集群:
- 环境 1: 172.17.0.2 作为 head 节点
- 环境 2: 172.17.0.3 作为 worker 节点,可以有多个 worker 节点
具体步骤:
1. 下载 ubuntu 镜像
docker pull ubuntu
2. 启动 ubuntu 容器,安装依赖
启动第一个
docker run -it --name ubuntu-01 ubuntu bash
启动第二个
docker run -it --name ubuntu-02 ubuntu bash
检查下它们的 IP 地址:
$ docker inspect -f "{{ .NetworkSettings.IPAddress }}" ubuntu-01
172.17.0.2
$ docker inspect -f "{{ .NetworkSettings.IPAddress }}" ubuntu-02
172.17.0.3
然后分别在容器内部安装 python、pip、ray
apt update && apt install python3 apt install python3-pip pip3 install ray
3. 启动 head 节点和 worker 节点
选择在其中一个容器作为 head 节点,这里选择 172.17.0.2,执行:
ray start --head --node-ip-address 172.17.0.2
默认端口是 6379,你可以使用 --port 参数来修改默认端口,启动后的结果如下:

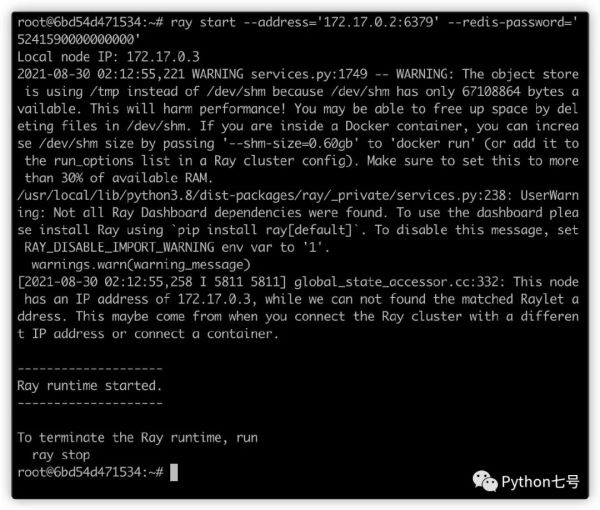
忽略掉警告,可以看到给出了一个提示,如果要把其他节点绑定到该 head,可以这样:
ray start --address='172.17.0.2:6379' --redis-password='5241590000000000'
在另一个节点执行上述命令,即可启动 worker 节点:
如果要关闭,执行:
ray stop
4、执行任务
随便选择一个节点,执行下面的脚本,修改下 ray.init() 函数的参数:
from collections import Counter
import socket
import time
import ray
ray.init(address='172.17.0.2:6379', _redis_password='5241590000000000')
print('''This cluster consists o f
{} nodes in total
{} CPU resources in total
'''.format(len(ray.nodes()), ray.cluster_resources()['CPU']))
@ray.remote
def f():
time.sleep(0.001)
# Return IP address.
return socket.gethostbyname(socket.gethostname())
object_ids = [f.remote() for _ in range(10000)]
ip_addresses = ray.get(object_ids)
print('Tasks executed')
for ip_address, num_tasks in Counter(ip_addresses).items():
print(' {} tasks on {}'.format(num_tasks, ip_address))
执行结果如下:

可以看到 172.17.0.2 执行了 4751 个任务,172.17.0.3 执行了 5249 个任务,实现了分布式计算的效果。
最后的话
有了 Ray,你可以不使用 Python 的多进程就可以实现并行计算。今天的机器学习主要就是计算密集型任务,不借助分布式计算速度会非常慢,Ray 提供了简单实现分布式计算的解决方案。官方文档提供了很详细的教程和样例,感兴趣的可以去了解下。
以上就是使用Ray集群简单实现Python分布式应用程序的详细内容,更多关于Ray集群简单实现Python分布式的资料请关注我们其它相关文章!
相关推荐
-

支持python的分布式计算框架Ray详解
项目地址:https://github.com/ray-project/ray 1.简介 Ray为构建分布式应用程序提供了一个简单.通用的API.Ray是一种分布式执行框架,便于大规模应用程序和利用先进的机器学习库. Ray通过以下方式完成这项任务: 为构建和运行分布式应用程序提供简单的原语. 使最终用户能够并行化单个机器代码,而代码更改很少到零. 在核心Ray之上包含大量应用程序.库和工具,以支持复杂的应用程序. 2.安装 安装方式比较简单: pip install ray==1.4.1 [r
-
在Python程序中实现分布式进程的教程
在Thread和Process中,应当优选Process,因为Process更稳定,而且,Process可以分布到多台机器上,而Thread最多只能分布到同一台机器的多个CPU上. Python的multiprocessing模块不但支持多进程,其中managers子模块还支持把多进程分布到多台机器上.一个服务进程可以作为调度者,将任务分布到其他多个进程中,依靠网络通信.由于managers模块封装很好,不必了解网络通信的细节,就可以很容易地编写分布式多进程程序. 举个例子:如果我们已经有一个通
-
Python如何快速实现分布式任务
深入读了读python的官方文档,发觉Python自带的multiprocessing模块有很多预制的接口可以方便的实现多个主机之间的通讯,进而实现典型的生产者-消费者模式的分布式任务架构. 之前,为了在Python中实现生产者-消费者模式,往往就会选择一个额外的队列系统,比如rabbitMQ之类.此外,你有可能还要设计一套任务对象的序列化方式以便塞入队列.如果没有队列的支持,那不排除有些同学不得不从socket服务器做起,直接跟TCP/IP打起交道来. 其实multiprocessing.ma
-
Python自定义主从分布式架构实例分析
本文实例讲述了Python自定义主从分布式架构.分享给大家供大家参考,具体如下: 环境:Win7 x64,Python 2.7,APScheduler 2.1.2. 原理图如下: 代码部分: (1).中心节点: #encoding=utf-8 #author: walker #date: 2014-12-03 #function: 中心节点(主要功能是分配任务) import SocketServer, socket, Queue CenterIP = '127.0.0.1' #中心节点IP C
-
使用Ray集群简单创建Python分布式应用程序
目录 什么是 Ray 安装 Ray 使用 Ray 使用 Ray 集群 具体步骤: 1. 下载 ubuntu 镜像 2. 启动 ubuntu 容器,安装依赖 3. 启动 head 节点和 worker 节点 4.执行任务 最后的话 什么是 Ray Ray 是基于 Python 的分布式计算框架,采用动态图计算模型,提供简单.通用的 API 来创建分布式应用.使用起来很方便,你可以通过装饰器的方式,仅需修改极少的的代码,让原本运行在单机的 Python 代码轻松实现分布式计算,目前多用于机器学习.
-
Docker集群的创建与管理实例详解
本文详细讲述了Docker集群的创建与管理.分享给大家供大家参考,具体如下: 在<Docker简单安装与应用入门教程>中编写一个应用程序,并将其转化为服务,在<Docker分布式应用教程>中,使应用程序在生产过程中扩展5倍,并定义应该如何运行.现在将此应用程序部署到集群上,并在多台机器上运行它,通过将多台机器连接到Dockerized集群上,使多容器.多机器应用成为可能. Swarm(集群)是运行Docker并加入到一个集群中的一组机器,在这种情况下,您将继续运行以往的Docker
-
Docker+K8S 集群环境搭建及分布式应用部署
1.安装docker yum install docker #启动服务 systemctl start docker.service systemctl enable docker.service #测试 docker version 2.安装etcd yum install etcd -y #启动etcd systemctl start etcd systemctl enable etcd #输入如下命令查看 etcd 健康状况 etcdctl -C http://localhost:2379
-
Docker Compose 搭建简单的Python网络应用程序(步骤详解)
目录 前提条件 第1步:设置 第2步:创建一个Dockerfile 第3步:在Compose文件中定义服务 Web服务 Redis服务 第4步:用Compose构建和运行你的应用 第5步:编辑Compose文件以添加绑定挂载 第6步:用Compose重新构建并运行应用程序 第7步:更新应用程序 第8步:试验一些其他命令 在这个页面上,你可以建立一个简单的Python网络应用程序,运行在Docker Compose上.该应用使用Flask框架,并在Redis中维护一个点击计数器.虽然样本使用了Py
-
简单实现python聊天程序
本文实例为大家分享了简单实现python聊天程序的具体代码,供大家参考,具体内容如下 客户端 #coding:utf-8 import socket, sys host = 'localhost' port = 10001 s = socket.socket(socket.AF_INET,socket.SOCK_STREAM) print 'socket创建成功' try: s.connect((host,port)) print '连接成功' except: sys.exit(1) while
-
一个简单的python爬虫程序 爬取豆瓣热度Top100以内的电影信息
概述 这是一个简单的python爬虫程序,仅用作技术学习与交流,主要是通过一个简单的实际案例来对网络爬虫有个基础的认识. 什么是网络爬虫 简单的讲,网络爬虫就是模拟人访问web站点的行为来获取有价值的数据.专业的解释:百度百科 分析爬虫需求 确定目标 爬取豆瓣热度在Top100以内的电影的一些信息,包括电影的名称.豆瓣评分.导演.编剧.主演.类型.制片国家/地区.语言.上映日期.片长.IMDb链接等信息. 分析目标 1.借助工具分析目标网页 首先,我们打开豆瓣电影·热门电影,会发现页面总共20部
-
一个超级简单的python web程序
在MAC/LINUX环境下,执行vi hello.py命令,并输入以下代码 import web import sys urls = ("/Service/hello","hello") app = web.application(urls,globals()) class hello: def GET(self): return 'Hello,world!'; if __name__=="__main__": app.run() 执行pytho
-
详解.net core下如何简单构建高可用服务集群
一说到集群服务相信对普通开发者来说肯定想到很复杂的事情,如zeekeeper ,反向代理服务网关等一系列的搭建和配置等等:总得来说需要有一定经验和规划的团队才能应用起来.在这文章里你能看到在.net core下的另一种集群构建方案,通过Beetlex即可非常便捷地构建高可用的集群服务. 简述 Beetlex的Webapi集群应用并没有依赖于第三方服务,而是由Beetlex自身完成:它主要是通过Client和策略监控服务相结合的方式来实现集群化的服务负载访问.以下是服务结构: client一旦从配
-
使用kubeadm命令行工具创建kubernetes集群
目录 命令行工具 通过软件仓库安装 二进制文件下载安装 ubutu & centos 快速安装 创建 kubernetes 集群 1,创建 Master 2,然后初始化集群网络. 3,加入集群 清除环境 命令行工具 主要有三个工具,命令行工具使用 kube 前缀命名. kubeadm:用来初始化集群的指令. kubelet:在集群中的每个节点上用来启动 Pod 和容器等. kubectl:用来与集群通信的命令行工具. 通过软件仓库安装 方法 ① 此方法是通过 Google 的源下载安装工具包.
-
使用Docker Swarm搭建分布式爬虫集群的方法示例
在爬虫开发过程中,你肯定遇到过需要把爬虫部署在多个服务器上面的情况.此时你是怎么操作的呢?逐一SSH登录每个服务器,使用git拉下代码,然后运行?代码修改了,于是又要一个服务器一个服务器登录上去依次更新? 有时候爬虫只需要在一个服务器上面运行,有时候需要在200个服务器上面运行.你是怎么快速切换的呢?一个服务器一个服务器登录上去开关?或者聪明一点,在Redis里面设置一个可以修改的标记,只有标记对应的服务器上面的爬虫运行? A爬虫已经在所有服务器上面部署了,现在又做了一个B爬虫,你是不是又得依次