SpringBoot2.0 中 HikariCP 数据库连接池原理解析
作为后台服务开发,在日常工作中我们天天都在跟数据库打交道,一直在进行各种CRUD操作,都会使用到数据库连接池。按照发展历程,业界知名的数据库连接池有以下几种:c3p0、DBCP、Tomcat JDBC Connection Pool、Druid 等,不过最近最火的是 HiKariCP。
HiKariCP 号称是业界跑得最快的数据库连接池,自从 SpringBoot 2.0 将其作为默认数据库连接池后,其发展势头锐不可当。那它为什么那么快呢?今天咱们就重点聊聊其中的原因。
一、什么是数据库连接池
在讲解HiKariCP之前,我们先简单介绍下什么是数据库连接池(Database Connection Pooling),以及为什么要有数据库连接池。
从根本上而言,数据库连接池和我们常用的线程池一样,都属于池化资源,它在程序初始化时创建一定数量的数据库连接对象并将其保存在一块内存区中。它允许应用程序重复使用一个现有的数据库连接,当需要执行 SQL 时,我们是直接从连接池中获取一个连接,而不是重新建立一个数据库连接,当 SQL 执行完,也并不是将数据库连接真的关掉,而是将其归还到数据库连接池中。我们可以通过配置连接池的参数来控制连接池中的初始连接数、最小连接、最大连接、最大空闲时间等参数,来保证访问数据库的数量在一定可控制的范围类,防止系统崩溃,同时保证用户良好的体验。数据库连接池示意图如下所示:

因此使用数据库连接池的核心作用,就是避免数据库连接频繁创建和销毁,节省系统开销。因为数据库连接是有限且代价昂贵,创建和释放数据库连接都非常耗时,频繁地进行这样的操作将占用大量的性能开销,进而导致网站的响应速度下降,甚至引起服务器崩溃。
二、常见数据库连接池对比分析
这里详细总结了常见数据库连接池的各项功能比较,我们重点分析下当前主流的阿里巴巴Druid与HikariCP,HikariCP在性能上是完全优于Druid连接池的。而Druid的性能稍微差点是由于锁机制的不同,并且Druid提供更丰富的功能,包括监控、sql拦截与解析等功能,两者的侧重点不一样,HikariCP追求极致的高性能。

下面是官网提供的性能对比图,在性能上面这五种数据库连接池的排序如下:HikariCP>druid>tomcat-jdbc>dbcp>c3p0:

三、HikariCP 数据库连接池简介
HikariCP 号称是史上性能最好的数据库连接池,SpringBoot 2.0将它设置为默认的数据源连接池。Hikari相比起其它连接池的性能高了非常多,那么,这是怎么做到的呢?通过查看HikariCP官网介绍,对于HikariCP所做优化总结如下:
1. 字节码精简 :优化代码,编译后的字节码量极少,使得CPU缓存可以加载更多的程序代码;
HikariCP在优化并精简字节码上也下了功夫,使用第三方的Java字节码修改类库Javassist来生成委托实现动态代理.动态代理的实现在ProxyFactory类,速度更快,相比于JDK Proxy生成的字节码更少,精简了很多不必要的字节码。
2. 优化代理和拦截器:减少代码,例如HikariCP的Statement proxy只有100行代码,只有BoneCP的十分之一;
3. 自定义数组类型(FastStatementList)代替ArrayList:避免ArrayList每次get()都要进行range check,避免调用remove()时的从头到尾的扫描(由于连接的特点是后获取连接的先释放);
4. 自定义集合类型(ConcurrentBag):提高并发读写的效率;
5. 其他针对BoneCP缺陷的优化,比如对于耗时超过一个CPU时间片的方法调用的研究。
当然作为一个数据库连接池,不能说快就会被消费者所推崇,它还具有非常好的健壮性及稳定性。HikariCP从15年推出以来,已经经受了广大应用市场的考验,并且成功地被SpringBoot2.0作为默认数据库连接池进行推广,在可靠性上面是值得信任的。其次借助于其代码量少,占用cpu和内存量小的优点,使得它的执行率非常高。最后,Spring配置HikariCP和druid基本没什么区别,迁移过来非常方便,这些都是为什么HikariCP目前如此受欢迎的原因。
字节码精简、优化代理和拦截器、自定义数组类型。
四、HikariCP 核心源码解析
4.1 FastList 是如何优化性能问题的
首先我们来看一下执行数据库操作规范化的操作步骤:
- 通过数据源获取一个数据库连接;
- 创建 Statement;
- 执行 SQL;
- 通过 ResultSet 获取 SQL 执行结果;
- 释放 ResultSet;
- 释放 Statement;
- 释放数据库连接。
当前所有数据库连接池都是严格地根据这个顺序来进行数据库操作的,为了防止最后的释放操作,各类数据库连接池都会把创建的 Statement 保存在数组 ArrayList 里,来保证当关闭连接的时候,可以依次将数组中的所有 Statement 关闭。HiKariCP 在处理这一步骤中,认为 ArrayList 的某些方法操作存在优化空间,因此对List接口的精简实现,针对List接口中核心的几个方法进行优化,其他部分与ArrayList基本一致 。
首先是get()方法,ArrayList每次调用get()方法时都会进行rangeCheck检查索引是否越界,FastList的实现中去除了这一检查,是因为数据库连接池满足索引的合法性,能保证不会越界,此时rangeCheck就属于无效的计算开销,所以不用每次都进行越界检查。省去频繁的无效操作,可以明显地减少性能消耗。
FastList get()操作
public T get(int index)
{
// ArrayList 在此多了范围检测 rangeCheck(index);
return elementData[index];
}
其次是remove方法,当通过 conn.createStatement() 创建一个 Statement 时,需要调用 ArrayList 的 add() 方法加入到 ArrayList 中,这个是没有问题的;但是当通过 stmt.close() 关闭 Statement 的时候,需要调用 ArrayList 的 remove() 方法来将其从 ArrayList 中删除,而ArrayList的remove(Object)方法是从头开始遍历数组,而FastList是从数组的尾部开始遍历,因此更为高效。假设一个 Connection 依次创建 6 个 Statement,分别是 S1、S2、S3、S4、S5、S6,而关闭 Statement 的顺序一般都是逆序的,从S6 到 S1,而 ArrayList 的 remove(Object o) 方法是顺序遍历查找,逆序删除而顺序查找,这样的查找效率就太慢了。因此FastList对其进行优化,改成了逆序查找。如下代码为FastList 实现的数据移除操作,相比于ArrayList的 remove()代码, FastList 去除了检查范围 和 从头到尾遍历检查元素的步骤,其性能更快。
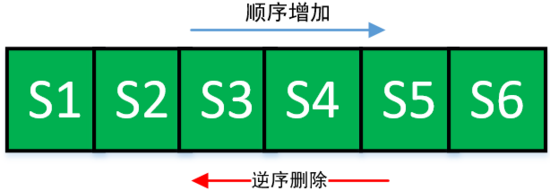
FastList 删除操作
public boolean remove(Object element)
{
// 删除操作使用逆序查找
for (int index = size - 1; index >= 0; index--) {
if (element == elementData[index]) {
final int numMoved = size - index - 1;
// 如果角标不是最后一个,复制一个新的数组结构
if (numMoved > 0) {
System.arraycopy(elementData, index + 1, elementData, index, numMoved);
}
//如果角标是最后面的 直接初始化为null
elementData[--size] = null;
return true;
}
}
return false;
}
通过上述源码分析,FastList 的优化点还是很简单的。相比ArrayList仅仅是去掉了rage检查,扩容优化等细节处,删除时数组从后往前遍历查找元素等微小的调整,从而追求性能极致。当然FastList 对于 ArrayList 的优化,我们不能说ArrayList不好。所谓定位不同、追求不同,ArrayList作为通用容器,更追求安全、稳定,操作前rangeCheck检查,对非法请求直接抛出异常,更符合 fail-fast(快速失败)机制,而FastList追求的是性能极致。
下面我们再来聊聊 HiKariCP 中的另外一个数据结构 ConcurrentBag,看看它又是如何提升性能的。
4.2 ConcurrentBag 实现原理分析
当前主流数据库连接池实现方式,大都用两个阻塞队列来实现。一个用于保存空闲数据库连接的队列 idle,另一个用于保存忙碌数据库连接的队列 busy;获取连接时将空闲的数据库连接从 idle 队列移动到 busy 队列,而关闭连接时将数据库连接从 busy 移动到 idle。这种方案将并发问题委托给了阻塞队列,实现简单,但是性能并不是很理想。因为 Java SDK 中的阻塞队列是用锁实现的,而高并发场景下锁的争用对性能影响很大。
HiKariCP 并没有使用 Java SDK 中的阻塞队列,而是自己实现了一个叫做 ConcurrentBag 的并发容器,在连接池(多线程数据交互)的实现上具有比LinkedBlockingQueue和LinkedTransferQueue更优越的性能。
ConcurrentBag 中最关键的属性有 4 个,分别是:用于存储所有的数据库连接的共享队列 sharedList、线程本地存储 threadList、等待数据库连接的线程数 waiters 以及分配数据库连接的工具 handoffQueue。其中,handoffQueue 用的是 Java SDK 提供的 SynchronousQueue,SynchronousQueue 主要用于线程之间传递数据。
ConcurrentBag 中的关键属性
// 存放共享元素,用于存储所有的数据库连接 private final CopyOnWriteArrayList<T> sharedList; // 在 ThreadLocal 缓存线程本地的数据库连接,避免线程争用 private final ThreadLocal<List<Object>> threadList; // 等待数据库连接的线程数 private final AtomicInteger waiters; // 接力队列,用来分配数据库连接 private final SynchronousQueue<T> handoffQueue;
ConcurrentBag 保证了全部的资源均只能通过 add() 方法进行添加,当线程池创建了一个数据库连接时,通过调用 ConcurrentBag 的 add() 方法加入到 ConcurrentBag 中,并通过 remove() 方法进行移出。下面是 add() 方法和 remove() 方法的具体实现,添加时实现了将这个连接加入到共享队列 sharedList 中,如果此时有线程在等待数据库连接,那么就通过 handoffQueue 将这个连接分配给等待的线程。
ConcurrentBag 的 add() 与 remove() 方法
public void add(final T bagEntry)
{
if (closed) {
LOGGER.info("ConcurrentBag has been closed, ignoring add()");
throw new IllegalStateException("ConcurrentBag has been closed, ignoring add()");
}
// 新添加的资源优先放入sharedList
sharedList.add(bagEntry);
// 当有等待资源的线程时,将资源交到等待线程 handoffQueue 后才返回
while (waiters.get() > 0 && bagEntry.getState() == STATE_NOT_IN_USE && !handoffQueue.offer(bagEntry)) {
yield();
}
}
public boolean remove(final T bagEntry)
{
// 如果资源正在使用且无法进行状态切换,则返回失败
if (!bagEntry.compareAndSet(STATE_IN_USE, STATE_REMOVED) && !bagEntry.compareAndSet(STATE_RESERVED, STATE_REMOVED) && !closed) {
LOGGER.warn("Attempt to remove an object from the bag that was not borrowed or reserved: {}", bagEntry);
return false;
}
// 从sharedList中移出
final boolean removed = sharedList.remove(bagEntry);
if (!removed && !closed) {
LOGGER.warn("Attempt to remove an object from the bag that does not exist: {}", bagEntry);
}
return removed;
}
同时ConcurrentBag通过提供的 borrow() 方法来获取一个空闲的数据库连接,并通过requite()方法进行资源回收,borrow() 的主要逻辑是:
- 查看线程本地存储 threadList 中是否有空闲连接,如果有,则返回一个空闲的连接;
- 如果线程本地存储中无空闲连接,则从共享队列 sharedList 中获取;
- 如果共享队列中也没有空闲的连接,则请求线程需要等待。
ConcurrentBag 的 borrow() 与 requite() 方法
// 该方法会从连接池中获取连接, 如果没有连接可用, 会一直等待timeout超时
public T borrow(long timeout, final TimeUnit timeUnit) throws InterruptedException
{
// 首先查看线程本地资源threadList是否有空闲连接
final List<Object> list = threadList.get();
// 从后往前反向遍历是有好处的, 因为最后一次使用的连接, 空闲的可能性比较大, 之前的连接可能会被其他线程提前借走了
for (int i = list.size() - 1; i >= 0; i--) {
final Object entry = list.remove(i);
@SuppressWarnings("unchecked")
final T bagEntry = weakThreadLocals ? ((WeakReference<T>) entry).get() : (T) entry;
// 线程本地存储中的连接也可以被窃取, 所以需要用CAS方法防止重复分配
if (bagEntry != null && bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) {
return bagEntry;
}
}
// 当无可用本地化资源时,遍历全部资源,查看可用资源,并用CAS方法防止资源被重复分配
final int waiting = waiters.incrementAndGet();
try {
for (T bagEntry : sharedList) {
if (bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) {
// 因为可能“抢走”了其他线程的资源,因此提醒包裹进行资源添加
if (waiting > 1) {
listener.addBagItem(waiting - 1);
}
return bagEntry;
}
}
listener.addBagItem(waiting);
timeout = timeUnit.toNanos(timeout);
do {
final long start = currentTime();
// 当现有全部资源都在使用中时,等待一个被释放的资源或者一个新资源
final T bagEntry = handoffQueue.poll(timeout, NANOSECONDS);
if (bagEntry == null || bagEntry.compareAndSet(STATE_NOT_IN_USE, STATE_IN_USE)) {
return bagEntry;
}
timeout -= elapsedNanos(start);
} while (timeout > 10_000);
return null;
}
finally {
waiters.decrementAndGet();
}
}
public void requite(final T bagEntry)
{
// 将资源状态转为未在使用
bagEntry.setState(STATE_NOT_IN_USE);
// 判断是否存在等待线程,若存在,则直接转手资源
for (int i = 0; waiters.get() > 0; i++) {
if (bagEntry.getState() != STATE_NOT_IN_USE || handoffQueue.offer(bagEntry)) {
return;
}
else if ((i & 0xff) == 0xff) {
parkNanos(MICROSECONDS.toNanos(10));
}
else {
yield();
}
}
// 否则,进行资源本地化处理
final List<Object> threadLocalList = threadList.get();
if (threadLocalList.size() < 50) {
threadLocalList.add(weakThreadLocals ? new WeakReference<>(bagEntry) : bagEntry);
}
}
borrow() 方法可以说是整个 HikariCP 中最核心的方法,它是我们从连接池中获取连接的时候最终会调用到的方法。需要注意的是 borrow() 方法只提供对象引用,不移除对象,因此使用时必须通过 requite() 方法进行放回,否则容易导致内存泄露。requite() 方法首先将数据库连接状态改为未使用,之后查看是否存在等待线程,如果有则分配给等待线程;否则将该数据库连接保存到线程本地存储里。
ConcurrentBag 实现采用了queue-stealing的机制获取元素:首先尝试从ThreadLocal中获取属于当前线程的元素来避免锁竞争,如果没有可用元素则再次从共享的CopyOnWriteArrayList中获取。此外,ThreadLocal和CopyOnWriteArrayList在ConcurrentBag中都是成员变量,线程间不共享,避免了伪共享(false sharing)的发生。同时因为线程本地存储中的连接是可以被其他线程窃取的,在共享队列中获取空闲连接,所以需要用 CAS 方法防止重复分配。
五、总结
Hikari 作为 SpringBoot2.0默认的连接池,目前在行业内使用范围非常广,对于大部分业务来说,都可以实现快速接入使用,做到高效连接。
参考资料
https://github.com/brettwooldridge/HikariCP
https://github.com/alibaba/druid
到此这篇关于SpringBoot2.0 中 HikariCP 数据库连接池原理解析的文章就介绍到这了,更多相关SpringBoot2.0 HikariCP连接池内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Spring Boot如何使用HikariCP连接池详解
前言 Springboot让Java开发更加美好,更加简洁,更加简单.Spring Boot 2.x中使用HikariCP作为默认的数据连接池. HikariCP使用Javassist字节码操作库来实现动态代理,优化并精简了字节码,同时内部使用 com.zaxxer.hikari.util.FastList 代替ArrayList.使用了更好的并发集合类 com.zaxxer.hikari.util.ConcurrentBag ,"号称"是目前最快的数据库连接池. 下面话不多说了,来一
-

SpringBoot2.0 中 HikariCP 数据库连接池原理解析
作为后台服务开发,在日常工作中我们天天都在跟数据库打交道,一直在进行各种CRUD操作,都会使用到数据库连接池.按照发展历程,业界知名的数据库连接池有以下几种:c3p0.DBCP.Tomcat JDBC Connection Pool.Druid 等,不过最近最火的是 HiKariCP. HiKariCP 号称是业界跑得最快的数据库连接池,自从 SpringBoot 2.0 将其作为默认数据库连接池后,其发展势头锐不可当.那它为什么那么快呢?今天咱们就重点聊聊其中的原因. 一.什么是数据库连接池
-
SpringBoot4.5.2 整合HikariCP 数据库连接池操作
目录 SpringBoot4.5.2 整合HikariCP 数据库连接池 引入 application.yaml 输出 HikariCP连接池及其在springboot中的配置 主要配置如下 SpringBoot4.5.2 整合HikariCP 数据库连接池 Spring Boot 2.+默认使用的就是连接池HikariCP 所以,只要引入相关包即可 引入 <dependency> <groupId>org.springframework.boot</groupId>
-
Spring事务管理中关于数据库连接池详解
目录 Spring事务管理 环境搭建 标准配置 声明式事务 总结 SqlSessionFactory XML中构建SqlSessionFactory 获得SqlSession的实例 代码实现 作用域(Scope)和生命周期 SqlSessionFactoryBuilder(构造器) SqlSessionFactory(工厂) SqlSession(会话) Spring事务管理 事务(Transaction),一般是指要做的或所做的事情.在计算机术语中是指访问并可能更新数据库中各种数据项的一个程序
-
Springboot2.0自适应效果错误响应过程解析
这篇文章主要介绍了Springboot2.0自适应效果错误响应过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 实现效果当访问thymeleaf渲染页面时,显示的是自定义的错误页面 当以接口方式访问时,显示的是自定义的json数据响应 1. 编写自定义异常 package cn.jfjb.crud.exception; /** * @author john * @date 2019/11/24 - 9:48 */ public class
-
Android中微信抢红包插件原理解析及开发思路
一.前言 自从去年中微信添加抢红包的功能,微信的电商之旅算是正式开始正式火爆起来.但是作为Android开发者来说,我们在抢红包的同时意识到了很多问题,就是手动去抢红包的速度慢了,当然这些有很多原因导致了.或许是网络的原因,而且这个也是最大的原因.但是其他的不可忽略的因素也是要考虑到进去的,比如在手机充电锁屏的时候,我们并不知道有人已经开始发红包了,那么这时候也是让我们丧失了一大批红包的原因.那么关于网络的问题,我们开发者可能用相关技术无法解决(当然在Google和Facebook看来的话,他们
-
Spring.Net在MVC中实现注入的原理解析
前言 本文将介绍Spring.Net(不仅仅是Spring.Net,其实所有的IoC容器要向控制器中进行注入,原理都是差不多的)在MVC控制器中依赖注入的实现原理,本文并没有关于在MVC使用Spring怎么配置,怎么使用,怎么实现. 引言放在前面,只是为了避免浪费你的时间. 望你能静心片刻,认真阅读. 情景 public class HomeController : Controller { //这是一个很神奇的注入 private IBLL.IUserInfoService UserInfoS
-
分析解决Python中sqlalchemy数据库连接池QueuePool异常
目录 数据库相关错误的解决办法 错误一:数据库连接池超过限制 错误二:数据库事务未回滚 数据库相关错误的解决办法 错误一:数据库连接池超过限制 SqlAlchemy QueuePool limit overflow 造成连接数超过数据库连接池的限制,有两方面的原因,第一个是由于数据库连接池数比较小,因此当连接数稍微增加的时候就会超过限制,另一个原因就是在使用完数据库连接后未能即使释放,最后造成数据连接数持续增加从而超出数据库连接池的限制,所以我们也可以从这两个方面来解决这个问题,但是根本上还是得
-
iOS底层探索之自动释放池原理解析
目录 1.概述 2.底层探索 2.1.打印自动释放池结构 2.2.objc_autoreleasePoolPush 2.2.1.AutoreleasePoolPage 2.2.2.AutoreleasePoolPageData 2.2.3.push(对象压栈) 2.2.4.池页容量 2.3.objc_autoreleasePoolPop 2.3.1.pop(对象出栈) 2.3.2.popPage 2.3.3.releaseUntil 2.3.4.kill 3.嵌套使用 总结 1.概述 OC 中的
-
.NET中的HashSet及原理解析
目录 哈希表原理 HashSet实现 总结 参考文章 在.NET中,System.Collection及System.Collection.Generic命名空间中提供了一系列的集合类,HashSet定义在System.Collections.Generic中,是一个不重复.无序的泛型集合,本文学习下HashSet的工作原理. 哈希表原理 HashSet是基于哈希表的原理实现的,学习HashSet首先要了解下哈希表. 哈希表(hash table, 也叫散列表)是根据key直接访问存储位置的数据
-
springboot2.0使用Hikari连接池的方法(替换druid)
1.springboot 2.0 默认连接池就是Hikari了,所以引用parents后不用专门加依赖 2.贴我自己的配置(时间单位都是毫秒) # jdbc_config datasource spring.datasource.driver-class-name=com.mysql.jdbc.Driver spring.datasource.url=jdbc:mysql://127.0.0.1:3306/datebook?useUnicode=true&characterEncoding=UT