Apache下通过shell脚本提交网站404死链的方法
网站运营人员对于死链这个概念一定不陌生,网站的一些数据删除或页面改版等都容易制造死链,影响用户体验不说,过多的死链还会影响到网站的整体权重或排名。
百度站长平台提供的死链提交工具,可将网站存在的死链(协议死链、404页面)进行提交,可快速删除死链,帮助网站SEO优化。在提交死链的文件中逐个手动填写死链的话太麻烦,工作中我们提倡复杂自动化,所以本文我们一起交流分享Apache服务中通过shell脚本整理网站死链,便于我们提交。
、
1.配置Apache记录搜索引擎
Apache是目前网站建设最为主流的web服务,但是apache的日志文件默认是不记录百度、谷歌等各大搜索引擎的爬取程序的,所以首先需要我们设置Apache的配置文件。
找到Apache的配置文件httpd.conf,在配置文件中找到下面两行:
CustomLog "logs/access_log" common #CustomLog "logs/access_log" combined
默认采用的是common,这里我们只需要将common这一行前面加#注释掉,然后将combined这一行前的#去掉即可。然后保存重启Apache服务。
注:如果你的服务器上添加了多个站点,每个站点有单独的配置文件,则我们只需要在相应站点的配置文件中设置CustomLog项即可,例如:
vim /usr/local/apache/conf/vhost/www.chanzhi.org.conf ServerAdmin [email protected] DocumentRoot "/data/wwwroot/www.chanzhi.org" ServerName www.chanzhi.org ServerAlias chanzhi.org ErrorLog "/data/wwwlogs/www.chanzhi.org_error_apache.log" CustomLog "/data/wwwlogs/www.chanzhi.org_apache.log" combined SetOutputFilter DEFLATE Options FollowSymLinks ExecCGI Require all granted AllowOverride All Order allow,deny Allow from all DirectoryIndex index.html index.php
下面是配置前后的网站日志记录格式:
配置前:

配置后:

2.编写shell脚本
我们通过shell脚本获取网站日志中指定爬虫的抓取记录,然后汇总到一个文件中,便于后期使用。代码如下,比如保存为deathlink.sh
#!/bin/bash
#初始化变量
#定义蜘蛛UA信息(默认是百度蜘蛛)
UA='+http://www.baidu.com/search/spider.html'
#前一天的日期(apache日志)
DATE=`date +%Y%m%d -d "1 day ago"`
#定义日志路径
logfile=/data/wwwlogs/www.chanzhi.org_apache.log-${DATE}.log
#定义死链文件存放路径
deathfile=/data/wwwroot/www.chanzhi.org/deathlink.txt
#定义网站访问地址
website=http://www.chanzhi.org
#分析日志并保存死链数据
for url in `awk -v str="${UA}" '$9=="404" && $15~str {print $7}' ${logfile}`
do
grep -q "$url" ${deathfile} || echo ${website}${url} >>${deathfile}
done
大家在使用该脚本时,根据自己服务器情况调整下路径和字段即可,然后执行脚本,:
bash deathlink.sh
3.提交死链
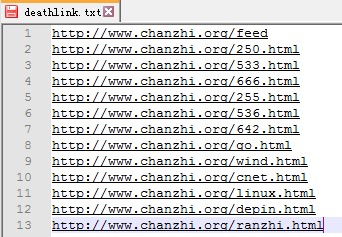
执行上面脚本时候,就会在指定目录下生成包含所有获取的404页面链接的文件,每个连接占一行。例如:
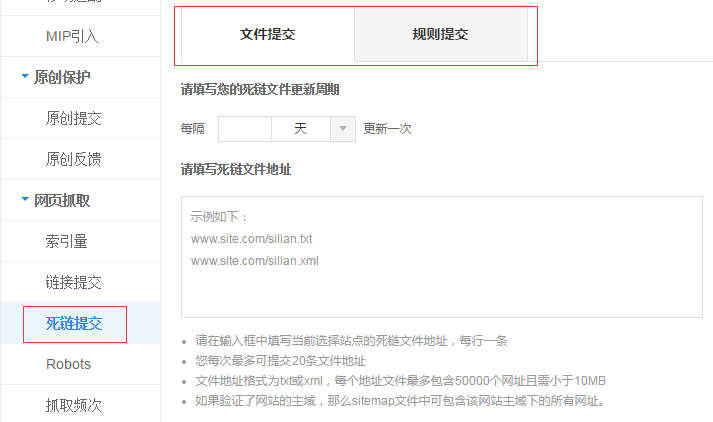
最后在站长平台提交死链页面中,填写自己的死链文件地址即可,例如:

百度在审核通过之后,会将已经收录的失效链接删除,以避免失效页面链接对网站造成不良的影响。
总结
以上所述是小编给大家介绍的Apache下通过shell脚本提交网站404死链的方法,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
相关推荐
-
Shell脚本实现apache日志中的状态码分析
一.首先将apache日志按天切割 复制代码 代码如下: vi /etc/httpd/conf/httpd.conf ErrorLog "|rotatelogs /var/log/httpd/%Y%m%derror_log 86400 480" CustomLog "|rotatelogs /var/log/httpd/%Y%m%daccess_log 86400 480" combined 二.重启apache服务 复制代码 代码如下
-
PHP+shell脚本操作Memcached和Apache Status的实例分享
memcached 进程启动及监控 1.memcached_inc.sh 设置路径,端口等讯息. #!/bin/sh #config include HOST=$(hostname) SITE="mysite" PORT=11211 MEMCACHED_PID_FILE="/tmp/memcached.pid" MEMCACHED_DAEMON_PID_FILE="/tmp/memcached_daemon.pid" MEMCACHED=&quo
-
Shell脚本实现分析apache日志中ip所在的地区
查询ip地址所用的组件 复制代码 代码如下: wget http://rfyiamcool.googlecode.com/files/nali-0.1.tar.gz tar zxvf nali-0.1.tar.gz cd nali-0.1 ./configure && make && make install 步骤和nginx是差不多的,只是取日志里面的ip地址的方法不一样~~~ 复制代码 代码如下: #!/bin/bash #rfyiamcool IPSUMFI
-
智能监测自动重启Apache服务器的Shell脚本
由于需要监控某些要求高可用性的Apache服务器,除了专业的监控报警设备,低成本下在Apache服务器上写一个自动监测Apache状态的脚本是个不错的主意.在网上搜索了许多类似的脚本,但由于局限性较大,也都存在一些不完善的地方,所以自己写了一个. 脚本功能与特点 1.能够每隔一段时间监测Apache服务器的可用性(由于本脚本直接模拟了客户端的访问,因此这里的"可用性"是指切切实实的正常可访问) 2.在出现无法访问的情况下,能够自动重启Apache服务(强行重启) 3.在重启后仍然无法正
-
Shell脚本判断Apache进程是否存在
写一个脚本检查Apache进程是否存在,若不存在则显示不存在,若存在则显示进程个数,当不等于10个时用红色字体通知管理员,并询问管理员是否启动Apache服务. 复制代码 代码如下: #!/bin/bash #echo "$(service httpd status)" PIDNUM=$(pgrep httpd | wc -l) if [[ $PIDNUM -eq 0 ]];then echo "Apache is stopped."
-
Ubuntu服务器配置apache2.4的限速功能shell脚本分享
过程都写成脚本了,原理都写在注释里,大家懂的.一键操作就是sudo bash xxx.sh 复制代码 代码如下: #!/bin/bash #cd到临时目录创建配置文件 cd /tmp (cat <<EOF <Directory /home/hursing/mylimiteddir/> SetOutputFilter RATE_LIMIT SetEnv rate-limit 30 </Directory> EOF ) > ratelimit.conf
-

Apache下通过shell脚本提交网站404死链的方法
网站运营人员对于死链这个概念一定不陌生,网站的一些数据删除或页面改版等都容易制造死链,影响用户体验不说,过多的死链还会影响到网站的整体权重或排名. 百度站长平台提供的死链提交工具,可将网站存在的死链(协议死链.404页面)进行提交,可快速删除死链,帮助网站SEO优化.在提交死链的文件中逐个手动填写死链的话太麻烦,工作中我们提倡复杂自动化,所以本文我们一起交流分享Apache服务中通过shell脚本整理网站死链,便于我们提交. . 1.配置Apache记录搜索引擎 Apache是目前网站建设最为主
-
linux环境下编写shell脚本实现启动停止tomcat服务的方法
第一步:以管理员的身份进入控制台,在指定目录下新建一个shell脚本,我这里命名为tomcat.sh 第二步:编写shell脚本 #!/bin/bash tomcat_home=/usr/tomcat/apache-tomcat-8.0.48 SHUTDOWN=$tomcat_home/bin/shutdown.sh STARTTOMCAT=$tomcat_home/bin/startup.sh case $1 in start) echo "启动$tomcat_home" $STAR
-
Linux下使用shell脚本自动执行脚本文件
以下实例本人在Centos6.5 64位操作系统中使用 一.定时复制文件 a.在/usr/local/wfjb_web_back目录下创建 tomcatBack.sh文件 文件内容: #将tomcat中的应用wfjb_web 复制到 /usr/local/wfjb_web_back/tomcat_back/目录下 并按照日期作为文件名称 cp -af /usr/local/apache-tomcat-7.0.73/webapps/wfjb_web /usr/local/wfjb_web_back
-
解决Centos7下crontab+shell脚本定期自动删除文件问题
问题描述: 最近有个需求,就是rsync每次同步的数据量很多,但是需要保留的数据库bak文件 保留7天就够了,所以需要自动清理文件夹内的bak文件 解决方案: 利用shell脚本来定期删除文件夹内的任务 1.创建shell文件 [root@zabbix script]# vim backup_sql_clean.sh #!/bin/sh find /data1/backup/KDKDA\$AGKDPAYKT/XNAKSD/FXUIJ -mtime +10 -name "*.bak" -
-
Linux下使用Shell脚本获取终端宽度的解决方法
获取终端大小时候的学习 在写shell脚本时想输出一行占满整个终端屏幕宽度的 横杠 发现for循环会导致执行缓慢 解决方法: 使用yes 命令 sed '50q' 显示50行 tr -d '\n' 删除 \n 多次重复输入相同字符可用yes yes "2" | sed '50q' | tr -d '\n' 想法来自:打印100个连续的符号,不用循环 ---------------------------------------------------------------------
-
linux下采用shell脚本实现批量为指定文件夹下图片添加水印的方法
要实现linux下采用shell脚本批量为指定文件夹下图片添加水印,首先需要安装imagemagick: CentOS上安装: yum install ImageMagick -y Debian上安装: apt-get install ImageMagick -y 脚本: #!/bin/bash for each in /要处理的图片目录/*{.jpg,.gif} s=`du -k $each | awk '{print $1}'` if [ $s -gt 10 ]; then #convert
-
Linux 下使用shell脚本定时维护数据库的案例
疫情期间哪哪也不能在,天天在家宅着快闷出病了,今天跟着韩顺平老师的视频学了一个星期的Linux基础命令和shell编程之后,做了一个shell脚本定时维护数据库的案例,用于之后复习和应用. 脚本需求如下: #数据库定时备份 #备份路径 BACKUP=/data/backup/db #获取当前时间作为文件名 DATETIME=$(date +%Y_%m_%d_%H%M%S) echo "=开始备份=" echo '备份的路径是 BACKUP/BACKUP/BACKUP/DATETIME.
-
通过shell脚本循环进入目录执行命令的方法
公司需要部署一套新的环境,新环境里面好多项目,整体目录结构如为:/webserver/* 所有的项目都在webserver目录下,其中有laravel和thinkphp项目的代码. laravel框架中, 根目录下storage vendor bootstrap 目录需要设置777权限. thinkphp框架,根目录App下Runtime目录需要设置777权限. 因此相对应的目录结构如下; laravel框架的目录结构为:/webserver/aaa/www/storage,vendor,boo
-
linux下利用shell在指定的行添加内容的方法
在linux的一些配置中总会要进行某个文件中的某行的操作,进行增加,修改,删除等操作. 而这里主要是进行的是指定的行添加数据的操作: 脚本如下: sed -i '3i asdf 1.sh' 1.sh 这个就是在1.sh中的第3行加入asdf的数据. 首先看1.sh内容如下: 执行sed命令如下: 这个就是一个比较简单的操作,比较实用. 以上这篇linux下利用shell在指定的行添加内容的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
touch shell脚本并修改为777权限的方法
mksh.sh #!/bin/bash for i in "$@" do touch ${i} chmod 777 ${i} echo "#!/bin/bash">${i} done mkcpptest.sh #!/bin/bash for i in "$@" do touch ${i} echo '#include<iostream> #include<ctime> using namespace std; int