Python 如何让特征值滞后一行
看代码吧~
# 加载库
import pandas as pd
# 데이터프레임을 만듭니다.
dataframe = pd.DataFrame()
# 模拟数据
dataframe["dates"] = pd.date_range("1/1/2001", periods=5, freq="D")
dataframe["stock_price"] = [1.1,2.2,3.3,4.4,5.5]
dataframe.head()
# 让值滞后一行
dataframe["previous_days_stock_price"] = dataframe["stock_price"].shift(1)
dataframe.head()
dates stock_price previous_days_stock_price
0 2001-01-01 1.1 NaN
1 2001-01-02 2.2 1.1
2 2001-01-03 3.3 2.2
3 2001-01-04 4.4 3.3
4 2001-01-05 5.5 4.4
补充:怎样用python画超前滞后先关图
想要获取更多Python学习资料,了解更多关于Python的知识,可以加Q群630390733踊跃发言,大家一起来学习讨论吧!
超前滞后相关是什么
想看两个时间序列是否相关,最简单的方法就是求二者的相关系数,但是在大气、海洋等科学问题的研究中,往往一个过程的响应并不是实时的,可能当a过程发生以后一段时间b过程才会发生,这样的关系往往不是同时期的相关系数可以表现的。
超前滞后相关就是为了看两个过程的发生演变是否在时间的先后上有一定的相关性。
举个例子:
有a、b两个时间序列,长度都是十二个月,直接求相关系数就是简单的同期相关。
如果a的1-11月对b的2-12月做相关系数,就是a对b超前1个月的相关;拿a的2-12月对b的1-11月做相关则称之为a对b的滞后1月相关,以此类推,就能求出n个月的超前滞后相关,画图出来就是沿0月(同期)正负各n月。

摘自黄嘉佑的书《气相统计分析与预报方法》,第三版,17页
python中的实现
需要输入两个时间序列,结果为data1对data2的超前滞后相关系数的序列
from scipy.stats import pearsonr
import numpy as np
#超前滞后相关
def leadlagcor(data1,data2,n):
#data1和data2为两个时间序列,n设置做多少个时间步长的超前滞后
a=-n
b=-a
c=b*2+1
x=np.arange(-n,n+1,1)
r=np.zeros((c,1))
p=np.zeros((c,1))
for i in range(c):
if i<(b):
r[n-i],p[n-i]=pearsonr(data1[:(len(data1)-i)], data2[i:])
else:
r[i],p[i]=pearsonr(data1[x[i]:], data2[:len(data1)-x[i]])
return r
附赠一个可视化程序
def leadlagcor_plot(data1,data2,n):
#data1和data2为两个时间序列,n设置做多少个时间步长的超前滞后
r=leadlagcor(data1,data2,n)#调用上面写的函数做超前滞后相关
x=range(-n,n+1,1)
fig = plt.figure()
ax = fig.add_subplot(111)
ax.plot(x,r,'k--',linewidth=0.8)
ax.axhline(0, color='k')
b=ax.bar(x,np.squeeze(r),color='red')
for bar,height in zip(b,r):
if height<0:
bar.set(color='blue')
print('cor_max:',np.max(r),'\n','cor_min:',np.min(r))
plt.savefig('%s.jpg')
plt.show()
画出来的结果就是这样啦,有更好的写法和例图也欢迎分享~
祝大家科研顺利,身心健康!
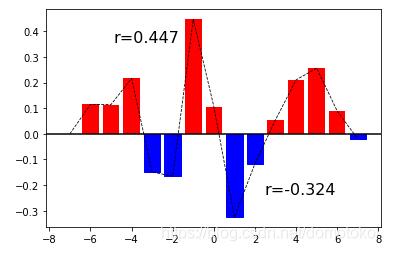
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

Python箱型图绘制与特征值获取过程解析
这篇文章主要介绍了Python箱型图绘制与特征值获取过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 它主要用于反映原始数据分布的特征,还可以进行多组数据分布特征的比较 如何利用Python绘制箱型图 需要的import的包 import matplotlib.pyplot as plt from matplotlib.font_manager import FontProperties import numpy as np import
-
python dataframe常见操作方法:实现取行、列、切片、统计特征值
实例如下所示: # -*- coding: utf-8 -*- import numpy as np import pandas as pd from pandas import * from numpy import * data = DataFrame(np.arange(16).reshape(4,4),index = list("ABCD"),columns=list('wxyz')) print data print data[0:2] #取前两行数据 print'+++++
-
python共轭梯度法特征值迭代次数讨论
共轭梯度法,特征值聚堆情况下迭代次数讨论 输入各种特征值聚堆与分散时的矩阵,并应用共轭梯度法,观察迭代次数与聚堆情况的关系. 因为对角矩阵的对角线元素为其特征值,则用对角矩阵讨论较为方便 代码 import numpy as np def cg(x0, A, b): r0 = np.dot(A, x0) - b p0 = -r0 rk = r0 pk = p0 xk = x0 t = 0 #记录迭代次数 while np.linalg.norm(rk) >= 1e-6: rr = np.dot(
-
Python 如何让特征值滞后一行
看代码吧~ # 加载库 import pandas as pd # 데이터프레임을 만듭니다. dataframe = pd.DataFrame() # 模拟数据 dataframe["dates"] = pd.date_range("1/1/2001", periods=5, freq="D") dataframe["stock_price"] = [1.1,2.2,3.3,4.4,5.5] dataframe.he
-
python在文本开头插入一行的实例
问题 对于一个文本文件,需要在起开头插入一行,其他内容不变 解决方法 with open('article.txt', 'r+') as f: content = f.read() f.seek(0, 0) f.write('writer:Fatsheep\n'+content) 其中字符串'writer:Fatsheep\n'中为要插入的内容. 效果 运行代码后: 注意 f.seek(0, 0)不可或缺,file.seek(off, whence=0)在文件中移动文件指针, 从 whence
-
Python中pandas dataframe删除一行或一列:drop函数详解
用法:DataFrame.drop(labels=None,axis=0, index=None, columns=None, inplace=False) 在这里默认:axis=0,指删除index,因此删除columns时要指定axis=1: inplace=False,默认该删除操作不改变原数据,而是返回一个执行删除操作后的新dataframe: inplace=True,则会直接在原数据上进行删除操作,删除后就回不来了. 例子: >>>df = pd.DataFrame(np.a
-
python:删除离群值操作(每一行为一类数据)
删除有多行字符串的json文件中的离群值 def processHold(eachsubject,directory,newfile): filename = 'CMUDataCol/Hold/subject{0}.json'.format(eachsubject) # 原文件 with open(filename, 'r') as f: for jsonstr in f.readlines(): # 按行读取原文件 # 这里的情况是每一行为一类数值,该行内的数据相互比较找出是否有离群值 # 若
-
一篇文章入门Python生态系统(Python新手入门指导)
译者按:原文写于2011年末,虽然文中关于Python 3的一些说法可以说已经不成立了,但是作为一篇面向从其他语言转型到Python的程序员来说,本文对Python的生态系统还是做了较为全面的介绍.文中提到了一些第三方库,但是Python社区中强大的第三方库并不止这些,欢迎各位Pytonistas补充. •原文链接:http://mirnazim.org/writings/python-ecosystem-introduction/ •译文链接:http://codingpy.com/artic
-
浅析Python中的多条件排序实现
多条件排序及itemgetter的应用 曾经客户端的同事用as写一大堆代码来排序,在得知Python排序往往只需要一行,惊讶无比,遂对python产生浓厚的兴趣. 之前在做足球的积分榜的时候需要用到多条件排序,如果积分相同,则按净胜球,再相同按进球数,再相同按失球数. 即按积分P.净胜球GD.进球GS.失球GA这样的顺序. 在python中,排序非常方便,排序的参数主要有key.reverse.参数cmp不建议使用了,在python3.0被移除了,用参数key代替. 对于多条件排序,也非常简单,
-
基于python全局设置id 自动化测试元素定位过程解析
背景: 在自动化化测试过程中,不方便准确获取页面的元素,或者在重构过程中方法修改造成元素层级改变,因此通过设置id准备定位. 一.python准备工作: 功能:用自动化的方式进行批量处理. 比如,你想要在大量的文本文件中执行查找/替换,或者以复杂的方式对大量的图片进行重命名和整理. 语法用例: #!/usr/bin/python //脚本语言的第一行,只对 Linux/Unix 用户适用,用来指定本脚本用什么解释器来执行,即:调用 /usr/bin 下的 python 解释器,推荐使用#!/us
-
Python文本处理简单易懂方法解析
这篇文章主要介绍了Python文本处理简单易懂方法解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 自从认识了python这门语言,所有的事情好像变得容易了,作为小白,逗汁儿今天就为大家总结一下python的文本处理的一些小方法. 话不多说,代码撸起来. python大小写字符互换 在进行大小写互换时,常用到的方法有4种,upper().lower().capitalize() 和title(). str = "www.dataCASTLE.
-
python 利用openpyxl读取Excel表格中指定的行或列教程
Worksheet 对象的 rows 属性和 columns 属性得到的是一 Generator 对象,不能用中括号取索引. 可先用列表推导式生成包含每一列中所有单元格的元组的列表,在对列表取索引. Worksheet 的 rows 属性亦可用相同的方法处理. 补充:python之表格数据读取 python 操作excel主要用到xlrd,xlwt这两个库,xlrd,是读取excel表,xlwt是写入表格 1.打开表格 table = xlrd.open("path_to_your_excel&
-
Python中使用Lambda函数的5种用法
引言 Lambda 函数(也称为匿名函数)是函数式编程中的核心概念之一. 支持多编程范例的 Python 也提供了一种简单的方法来定义 lambda 函数. 用 Python 编写 lambda 函数的模板是: lambda arguments : expression 它包括三个部分: · Lambda 关键字 · 函数将接收的参数 · 结果为函数返回值的表达式 由于它的简单性,lambda 函数可以使我们的 Python 代码在某些使用场景中更加优雅.这篇文章将演示在 Python 中 la