Hadoop-3.1.2完全分布式环境搭建过程图文详解(Windows 10)
一、前言
Hadoop原理架构本人就不在此赘述了,可以自行百度,本文仅介绍Hadoop-3.1.2完全分布式环境搭建(本人使用三个虚拟机搭建)。
首先,步骤:
① 准备安装包和工具:
hadoop-3.1.2.tar.gz ◦ jdk-8u221-linux-x64.tar.gz(Linux环境下的JDK) ◦ CertOS-7-x86_64-DVD-1810.iso(CentOS镜像) ◦工具:WinSCP(用于上传文件到虚拟机),SecureCRTP ortable(用于操作虚拟机,可复制粘贴Linux命令。不用该工具也可以,但是要纯手打命令),VMware Workstation Pro
② 安装虚拟机:本人使用的是VMware Workstation Pro,需要激活。(先最小化安装一个虚拟机Master,配置完Hadoop之后再克隆两个Slave)
③ 配置虚拟机:修改用户名,设置静态IP地址,修改host文件,关闭防火墙,安装Hadoop,安装JDK,配置系统环境,配置免密码登录(必要)。
④ 配置Hadoop:配置hadoop-env.sh,hdfs-site.xml,core-site.xml,mepred-site.xml,yarn-site.xml,workers文件(在Hadoop-2×中是slaves文件,用于存放从节点的主机名称,或者IP地址)
⑤ 克隆虚拟机:克隆两个Slave,主机名称分别是Slave1,Slave2。然后修改Slave的Hadoop配置。
⑥ namenode格式化:分别对Master、Slave1,Slave2执行hadoop namenode -format命令。
⑦ 启动hdfs和yarn:在Master上执行start-all.sh命令。待启动完成之后,执行jps命令查看进程,应包含namenode,secondarynamenode,resourcemaneger三个进程。Slave上有datanode,nodemanager进程。
⑧ 检查测试:先修改真实主机的host(IP地址与Master的映射)在浏览器中输入Master:9870回车,进入hdfs,点击上方datanode应该可以看到下面有两个节点;输入Master:8088回车,进入资源调度管理(yarn)
好了,开始吧。
二、准备工具
hadoop-3.1.2.tar.tz下载地址:http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-3.1.2/hadoop-3.1.2.tar.gz
jdk-8u221-linux-x64.tar.gz下载地址:https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
CentOS下载地址:http://isoredirect.centos.org/centos/7/isos/x86_64/CentOS-7-x86_64-DVD-1810.iso
WinSCP下载地址: https://winscp.net/eng/download.php
SecureCRTP ortable下载地址: http://fs2.download82.com/software/bbd8ff9dba17080c0c121804efbd61d5/securecrt-portable/scrt675_u3.exe
VMware Workstation Pro下载地址:http://download3.vmware.com/software/wkst/file/VMware-workstation-full-15.1.0-13591040.exe
附VMware Workstation Pro秘钥:
YG5H2-ANZ0H-M8ERY-TXZZZ-YKRV8
UG5J2-0ME12-M89WY-NPWXX-WQH88
UA5DR-2ZD4H-089FY-6YQ5T-YPRX6
三、安装虚拟机
此步略,详情之后发布
四、配置虚拟机
1.修改用户名:
hostnamectl --static set-hostname Master
2.设置静态IP地址
首先查看一下原本自动获取到的网关和DNS,记下来
[root@Master ~]# cat /etc/resolv.conf # Generated by NetworkManager nameserver 192.168.28.2 //DNS<br><br> [root@Master ~]# IP routing table Destination Gateway Genmask Flags MSS Window irtt Iface default 192.168.28.2(网关) 0.0.0.0 UG 0 0 0 ens33 192.168.28.0 0.0.0.0 255.255.255.0 U 0 0 0 ens33<br><br>
[root@Master ~]# vi /etc/sysconfig/network-scripts/ifcfg-ens33 //修改ifcfg-ens33文件,执行此命令后进入如下界面
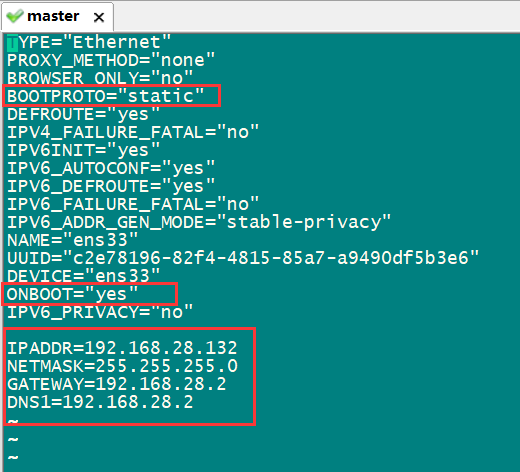
进入界面后按“I”键进入编辑模式,修改或添加图中标红部分。“static”表示静态地址,“netmask”子网掩码,gateways是网关,设置为上一步查看得到的即可。修改后按“esc”退出编辑模式。输入":wq"保存退出。然后输入以下代码更新网络配置。
systemctl restart network
3.修改hosts文件
注明:本人设置Master的IP地址为192.168.28.132,Slave1和Slave2分别为192.168.28.133,192.168.28.134
输入以下代码修改hosts文件(在真实主机中也需要添加):
vi /etc/hosts<br>添加:<br>192.168.28.132 Master<br>192.168.28.133 Slave1<br>192.168.28.134 Slave2
4.关闭防火墙
关闭防火墙代码:
systemctl stop firewalld.service //临时关闭 systemctl disable firewalld.service //设置开机不自启
5.安装Hadoop和JDK
先创建两个文件夹:
mkdir /tools //用来存放安装包 mkdir /bigdata //存放解压之后的文件夹
使用WinSCP上传压缩包:登录后找到已下载好的压缩包按如下步骤点击上传即可。
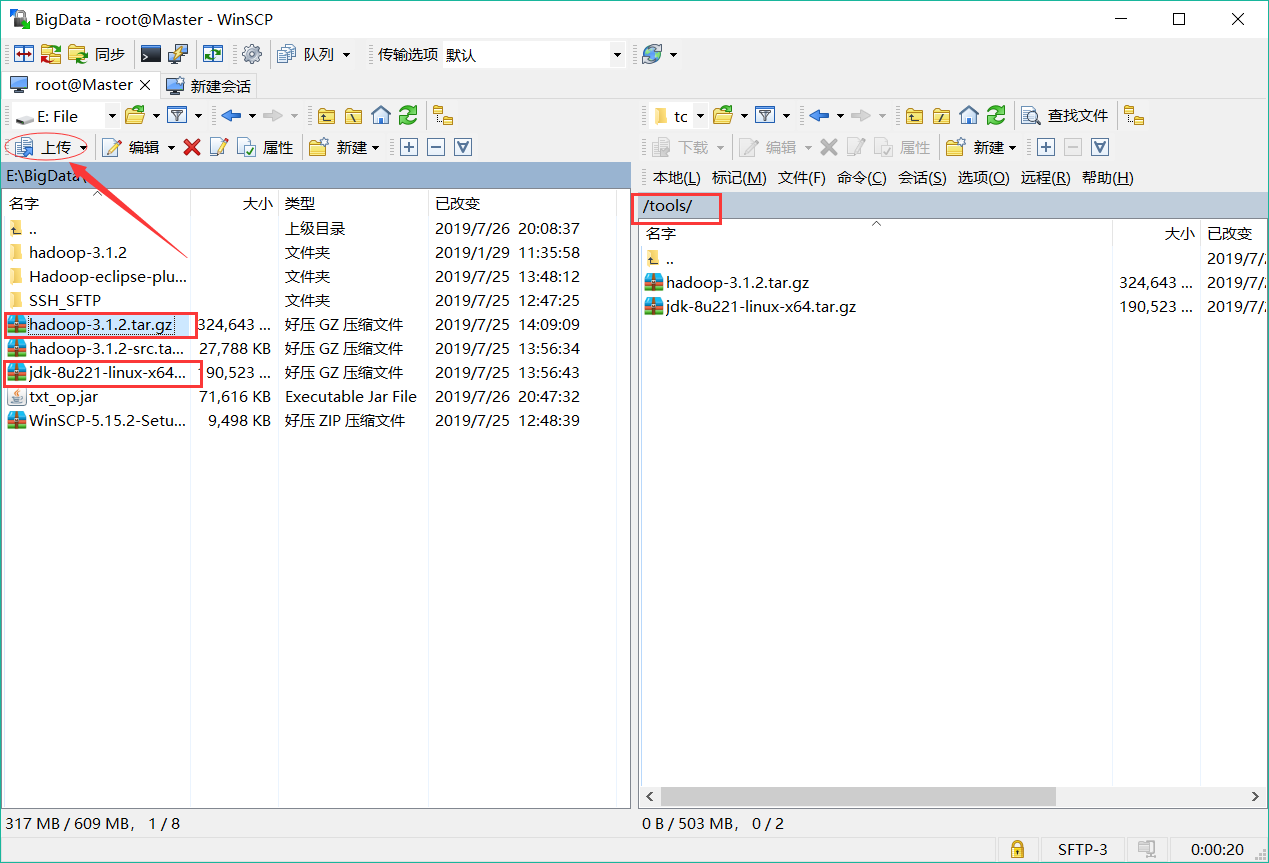
上传文件后,虚拟机端进入tools文件夹并解压文件:
cd /tools //进入tools文件夹 tar -zvxf jdk-8u221-linux-x64.tar.gz -C /bigdata/ //解压文件到bigdata目录下<br>tar -zvxf hadoop-3.1.2.
6.配置系统环境
vi ~/.bash_profile 添加: export JAVA_HOME=/bigdata/jdk1.8.0_221 export JRE_HOME=$JAVA_HOME/jre export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin export HADOOP_HOME=/bigdata/hadoop-3.1.2 export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin<br><br>保存退出,让环境变量生效: source ~/.bash_profile
7.配置免密登录(重要)
ssh-keygen -t rsa (直接回车3次) cd ~/.ssh/ ssh-copy-id -i id_rsa.pub root@Master ssh-copy-id -i id_rsa.pub root@Slave1 ssh-copy-id -i id_rsa.pub root@Slave2 测试是否成功配置(在配置完Slave之后测试): ssh Slave1 可以登录到Slave1节点
五、配置Hadoop
Hadoop-3.1.2中有许多坑,在2X版本中有些默认的不需要特别配置,但在Hadoop-3.1.2中需要。
hadoop-env.sh配置:
cd /bigdata/hadoop-3.1.2/etc/hadoop/
vi hadoop-env.sh
添加:
export JAVA_HOME=/bigdata/jdk1.8.0_221
export HADOOP_HOME=/bigdata/hadoop-3.1.2
export PATH=$PATH:/bigdata/hadoop-3.1.2/bin
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib/native"
export HADOOP_PID_DIR=/bigdata/hadoop-3.1.2/pids //PID存放目录,若没有此配置则默认存放在tmp临时文件夹中,在启动和关闭HDFS时可能会报错
#export HADOOP_ROOT_LOGGER=DEBUG,console //先注释掉,有问题可以打开,将调试信息打印在console上
hdfs-site.xml:
<configuration> <property> <name>dfs.replication</name> //冗余度,默认为3 <value>1</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/bigdata/hadoop-3.1.2/dfs/tmp/data</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/bigdata/hadoop-3.1.2/dfs/tmp/name</value> </property> <property> <name>dfs.permissions</name> <value>false</value> </property> </configuration>
mapred.site.xml:
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapred.job.tracker</name> <value>Master:9001</value> </property> </configuration>
yarn-site.xml:
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>Master</value> </property> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property> </configuration>
core-site.xml:
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://Master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/bigdata/hadoop-3.1.2/tmp</value> </property> </configuration>
workers:把默认的localhost删掉
Slave1 192.168.28.133 Slave2 192.168.28.134
yarn-env.sh 添加:
YARN_RESOURCEMANAGER_USER=root HADOOP_SECURE_DN_USER=yarn YARN_NODEMANAGER_USER=root
进入/bigdata/hadoop-3.1.2/sbin,修改start-dfs.sh,stop-dfs.sh,都添加:
HDFS_DATANODE_USER=root HDFS_DATANODE_SECURE_USER=hdfs HDFS_NAMENODE_USER=root HDFS_SECONDARYNAMENODE_USER=root
六、克隆虚拟机
克隆两个从节点虚拟机,主机名称分别为Slave1,Slave2(需要进入虚拟机中修改),然后分别修改IP地址(具体方法上面有)重启网络,重启虚拟机。
重启完成后进行namenode格式化:分别对Master、Slave1,Slave2执行:
hadoop namenode -format
对Master执行
start-all.sh //启动hdfs和yarn
待完成后用jps查看进程:
[root@Master ~]# jps 7840 ResourceManager 8164 Jps 7323 NameNode 7564 SecondaryNameNode
两Slave的进程:
包含以下两个: DataNode NodeManager
七、检查
浏览器输入:在浏览器中输入Master:9870回车,进入hdfs管理页面,点击上方datanode应该可以看到下面有两个节点;
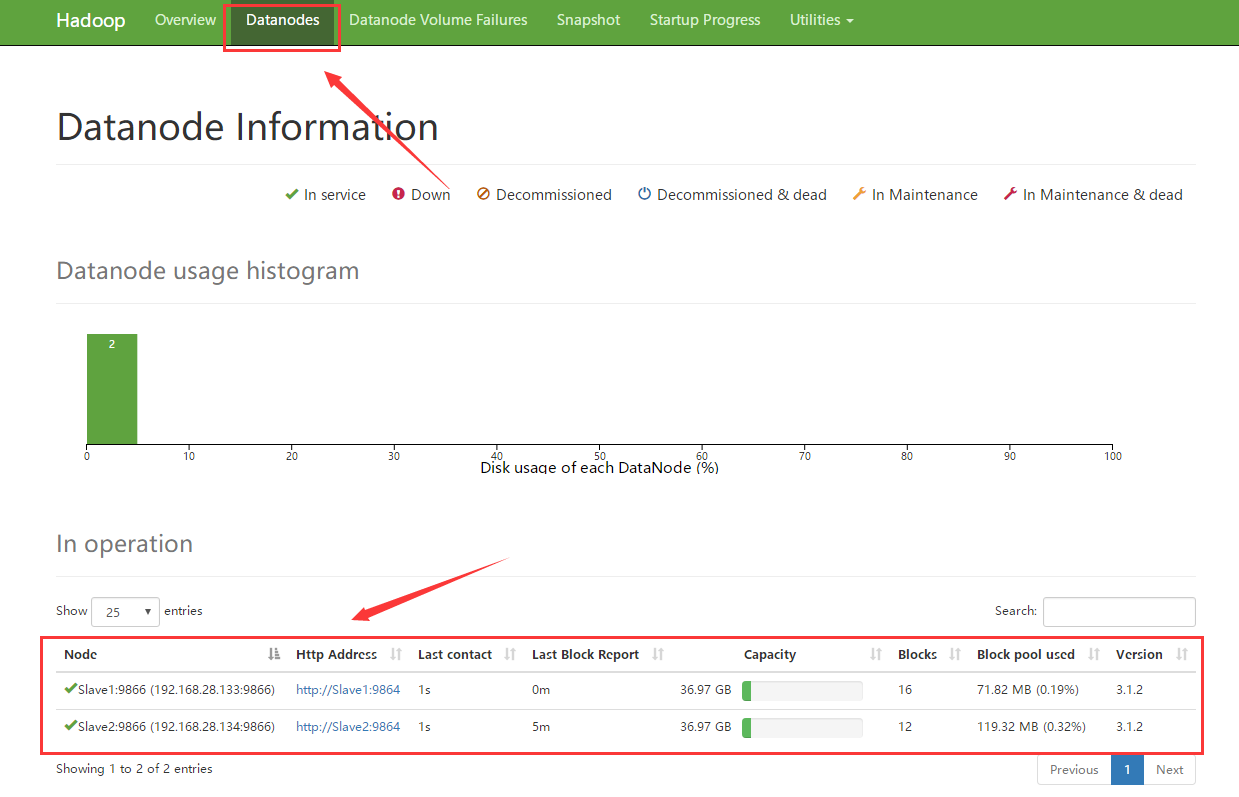
输入Master:8088回车,进入资源调度管理(yarn)
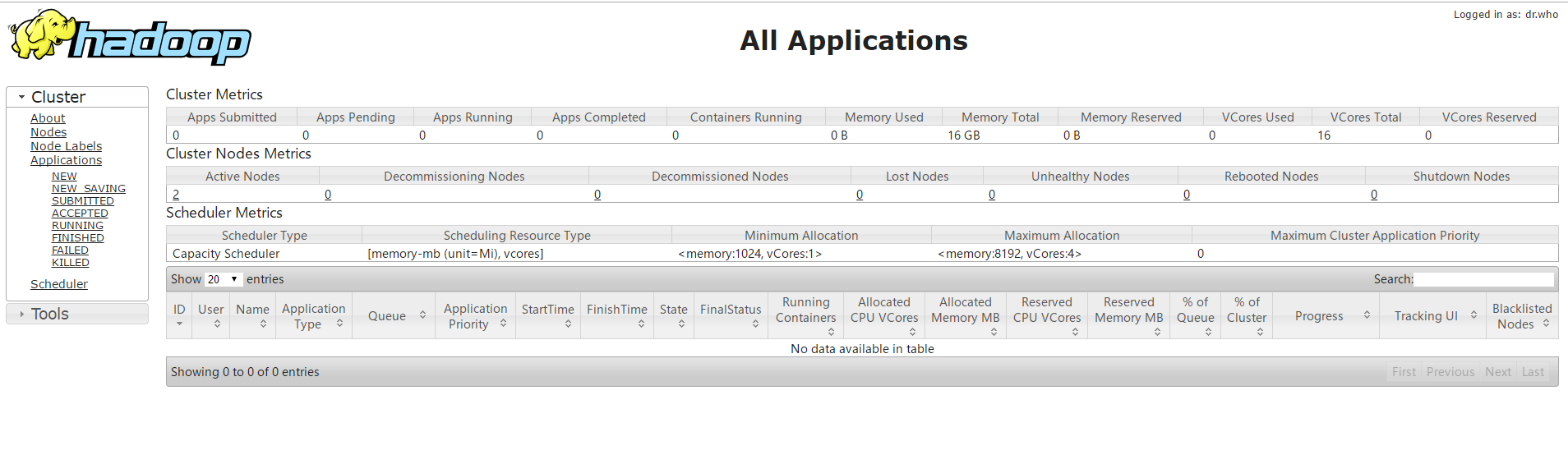
总结
以上所述是小编给大家介绍的Hadoop-3.1.2完全分布式环境搭建过程图文详解(Windows 10) ,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
相关推荐
-

ubantu 16.4下Hadoop完全分布式搭建实战教程
前言 本文主要介绍了关于ubantu 16.4 Hadoop完全分布式搭建的相关内容,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧 一个虚拟机 1.以 NAT网卡模式 装载虚拟机 2.最好将几个用到的虚拟机修改主机名,静态IP /etc/network/interface,这里 是 s101 s102 s103 三台主机 ubantu,改/etc/hostname文件 3.安装ssh 在第一台主机那里s101 创建公私密匙 ssh-keygen -t rsa
-
详解VMware12使用三台虚拟机Ubuntu16.04系统搭建hadoop-2.7.1+hbase-1.2.4(完全分布式)
初衷 首先说明一下既然网上有那么多教程为什么要还要写这样一个安装教程呢?网上教程虽然多,但是有些教程比较老,许多教程忽略许多安装过程中的细节,比如添加用户的权限,文件权限,小编在安装过程遇到许多这样的问题所以想写一篇完整的教程,希望对初学Hadoop的人有一个直观的了解,我们接触真集群的机会比较少,虚拟机是个不错的选择,可以基本完全模拟真实的情况,前提是你的电脑要配置相对较好不然跑起来都想死,废话不多说. 环境说明 本文使用VMware® Workstation 12 Pro虚拟机创建并安装三台
-
Hadoop 2.x伪分布式环境搭建详细步骤
本文以图文结合的方式详细介绍了Hadoop 2.x伪分布式环境搭建的全过程,供大家参考,具体内容如下 1.修改hadoop-env.sh.yarn-env.sh.mapred-env.sh 方法:使用notepad++(beifeng用户)打开这三个文件 添加代码:export JAVA_HOME=/opt/modules/jdk1.7.0_67 2.修改core-site.xml.hdfs-site.xml.yarn-site.xml.mapred-site.xml配置文件 1)修改core-
-
详解使用docker搭建hadoop分布式集群
使用Docker搭建部署Hadoop分布式集群 在网上找了很长时间都没有找到使用docker搭建hadoop分布式集群的文档,没办法,只能自己写一个了. 一:环境准备: 1:首先要有一个Centos7操作系统,可以在虚拟机中安装. 2:在centos7中安装docker,docker的版本为1.8.2 安装步骤如下: <1>安装制定版本的docker yum install -y docker-1.8.2-10.el7.centos <2>安装的时候可能会报错,需要删除这个依赖 r
-
Hadoop2.8.1完全分布式环境搭建过程
前言 本文搭建了一个由三节点(master.slave1.slave2)构成的Hadoop完全分布式集群(区别单节点伪分布式集群),并通过Hadoop分布式计算的一个示例测试集群的正确性. 本文集群三个节点基于三台虚拟机进行搭建,节点安装的操作系统为Centos7(yum源),Hadoop版本选取为2.8.0.作者也是初次搭建Hadoop集群,其间遇到了很多问题,故希望通过该博客让读者避免. 实验过程 1.基础集群的搭建 目的:获得一个可以互相通信的三节点集群 下载并安装VMware WorkS
-
基于CentOS的Hadoop分布式环境的搭建开发
首先,要说明的一点的是,我不想重复发明轮子.如果想要搭建Hadoop环境,网上有很多详细的步骤和命令代码,我不想再重复记录. 其次,我要说的是我也是新手,对于Hadoop也不是很熟悉.但是就是想实际搭建好环境,看看他的庐山真面目,还好,还好,最好看到了.当运行wordcount词频统计的时候,实在是感叹hadoop已经把分布式做的如此之好,即使没有分布式相关经验的人,也只需要做一些配置即可运行分布式集群环境. 好了,言归真传. 在搭建Hadoop环境中你要知道的一些事儿: 1.hadoop运行于
-
Hadoop-3.1.2完全分布式环境搭建过程图文详解(Windows 10)
一.前言 Hadoop原理架构本人就不在此赘述了,可以自行百度,本文仅介绍Hadoop-3.1.2完全分布式环境搭建(本人使用三个虚拟机搭建). 首先,步骤: ① 准备安装包和工具: hadoop-3.1.2.tar.gz ◦ jdk-8u221-linux-x64.tar.gz(Linux环境下的JDK) ◦ CertOS-7-x86_64-DVD-1810.iso(CentOS镜像) ◦工具:WinSCP(用于上传文件到虚拟机),SecureCRTP ortable(用于操作虚拟机,可复制粘
-
IDEA插件开发之环境搭建过程图文详解
基于IntelliJ Platform Plugin搭建 环境步骤 File->New->Project 选择IntelliJ Platform Plugin 如果你这里没有SDK环境,则添加一个SDK环境,选择自己的idea的安装的根目录即可. 展示效果 基于Gradle搭建环境步骤 File->New->Project 选择Gradle next 进来以后大概是这样的一个界面,然后gradle会自动build项目,下载相关的依赖.(可能会失败) 遇到的问题一,依赖ideaIC-
-
Android开发环境搭建过程图文详解
一.工具 IDE:Android Studio4.1+genymotion (Android studio 自带AVD着实有些不好用,这里选择使用genymotion模拟器) JDK:1.8 SDK:7.1 版本管理:Git 二.环境搭建 1.安装jdk 这里使用的是jdk1.8 ,安装并配置环境变量,通用步骤,不一 一介绍了 2.安装Android Studio 安装:android-studio-ide-201.6858069-windows.exe ,默认安装即可配置sdk (可以选择设置
-
GO语言开发环境搭建过程图文详解
一.GO语言开发包 1.什么是GO语言开发包 go 语言开发包其实是对go语言的一种实现,包括相应版本的语法, 编译, 运行, 垃圾回收等, 里面包含着开发 go 语言所需的标准库, 运行时以及其他的一些必要资源 2.GO语言开发包下载地址 Go官方下载地址 : https://golang.org/dl/ Go官方镜像站(上面打不开可使用这个) : https://golang.google.cn/dl/ Go语言中文网下载地址 : https://studygolang.com/dl gop
-
Python3 虚拟开发环境搭建过程(图文详解)
虚拟环境的搭建 为什么要使用虚拟环境# 1.使不同应用开发环境相互独立 2.环境升级不影响其他应用,也不会影响全局的python环境 3.防止出现包管理混乱及包版本冲突 windows平台# 安装 # 建议使用pip3安装到python3环境下 pip3 install virtualenv pip3 install virtualenvwrapper-win 配置虚拟环境管理器工作目录 # 配置环境变量: # 控制面板 => 系统和安全 => 系统 => 高级系统设置 => 环境
-
Python3+Pycharm+PyQt5环境搭建步骤图文详解
搭建环境: 操作系统:Win10 64bit Python版本:3.7 Pycharm:社区免费版 一.Python3.7安装 下载链接:官网https://www.python.org/downloads/windows/或腾讯软件中心下载https://pc.qq.com/detail/5/detail_24685.html或其他站点下载.我下载的是python-3.7.0-amd64. 下载到安装包后打开,如果想安装到默认路径(C盘)的话一直点下一步就可以了,或者自定义安装到其他分区,我的
-
Docker Consul概述以及集群环境搭建步骤(图文详解)
目录 一.Docker consul概述 二.基于 nginx 与 consul 构建自动发现即高可用的 Docker 服务架构 一.Docker consul概述 容器服务更新与发现:先发现再更新,发现的是后端节点上容器的变化(registrator),更新的是nginx配置文件(agent) registrator:是consul安插在docker容器里的眼线,用于监听监控节点上容器的变化(增加或减少,或者宕机),一旦有变化会把这些信息告诉并注册在consul server端(使用回调和协程
-
python框架Django实战商城项目之工程搭建过程图文详解
项目说明 该电商项目类似于京东商城,主要模块有验证.用户.第三方登录.首页广告.商品.购物车.订单.支付以及后台管理系统.项目开发模式采用前后端不分离的模式,为了提高搜索引擎排名,页面整体刷新采用jinja2模板引擎实现,局部刷新采用vue.js实现. 项目运行机制如下: 项目搭建 工程创建 项目使用码云进行源代码版本控制,在码云创建好后直接克隆到本地即可,然后在项目根目录下执行virtualenv venv创建虚拟环境,source venv/bin/activat激活虚拟环境后,安装djan
-
基于 Vue 的 Electron 项目搭建过程图文详解
Electron 应用技术体系推荐 目录结构 demo(项目名称) ├─ .electron-vue(webpack配置文件) │ └─ build.js(生产环境构建代码) | └─ dev-client.js(热加载相关) │ └─ dev-runner.js(开发环境启动入口) │ └─ webpack.main.config.js(主进程配置文件) │ └─ webpack.renderer.config.js(渲染进程配置文件) │ └─ webpack.web.config.js ├
-
hadoop分布式环境搭建过程
1. Java安装与环境配置 Hadoop是基于Java的,所以首先需要安装配置好java环境.从官网下载JDK,我用的是1.8版本. 在Mac下可以在终端下使用scp命令远程拷贝到虚拟机linux中. danieldu@daniels-MacBook-Pro-857 ~/Downloads scp jdk-8u121-linux-x64.tar.gz root@hadoop100:/opt/software root@hadoop100's password: danieldu@daniels