使用python爬取B站千万级数据
Python(发音:英[?pa?θ?n],美[?pa?θɑ:n]),是一种面向对象、直译式电脑编程语言,也是一种功能强大的通用型语言,已经具有近二十年的发展历史,成熟且稳定。它包含了一组完善而且容易理解的标准库,能够轻松完成很多常见的任务。它的语法非常简捷和清晰,与其它大多数程序设计语言不一样,它使用缩进来定义语句。
Python支持命令式程序设计、面向对象程序设计、函数式编程、面向切面编程、泛型编程多种编程范式。与Scheme、Ruby、Perl、Tcl等动态语言一样,Python具备垃圾回收功能,能够自动管理存储器使用。它经常被当作脚本语言用于处理系统管理任务和网络程序编写,然而它也非常适合完成各种高级任务。Python虚拟机本身几乎可以在所有的作业系统中运行。使用一些诸如py2exe、PyPy、PyInstaller之类的工具可以将Python源代码转换成可以脱离Python解释器运行的程序。

粉丝独白
说起热门的B站相信很多喜欢玩动漫的,看最有创意的Up主的同学一定非常熟悉。我突发奇想学Python这么久了,为啥不用Python爬取B站中我关注的人,已经关注的人他们关注的人,看看全站里面热门的UP主都是是哪些。
要点:
- 爬取10万用户数据
- 数据存储
- 数据词云分析
1.准备阶段
写代码前先构思思路:既然我要爬取用户关注的用户,那我需要存储用户之间的关系,确定谁是主用户,谁是follower。
存储关系使用数据库最方便,也有利于后期的数据分析,我选择sqlite数据库,因为Python自带sqlite,sqlite在Python中使用起来也非常方便。
数据库中需要2个表,一个表存储用户的相互关注信息,另一个表存储用户的基本信息,在B站的用户体系中,一个用户的mid号是唯一的。
然后我还需要一个列表来存储所以已经爬取的用户,防止重复爬取,毕竟用户之间相互关注的现象也是存在的,列表中存用户的mid号就可以了。
2.新建数据库
先写建数据库的代码,数据库中放一个用户表,一个关系表:

3.爬取前5页的用户数据
我需要找到B站用户的关注列表的json接口,很快就找到了,地址是:
https://api.bilibili.com/x/relation/followings?vmid=2&pn=1&ps=20&order=desc&jsonp=jsonp&callback=__jp7
其中vimd=后的参数就是用户的mid号
pn=1指用户的关注的第一面用户,一面显示20个用户
因为B站的隐私设置,一个人只能爬取其他人的前5页关注,共100人。
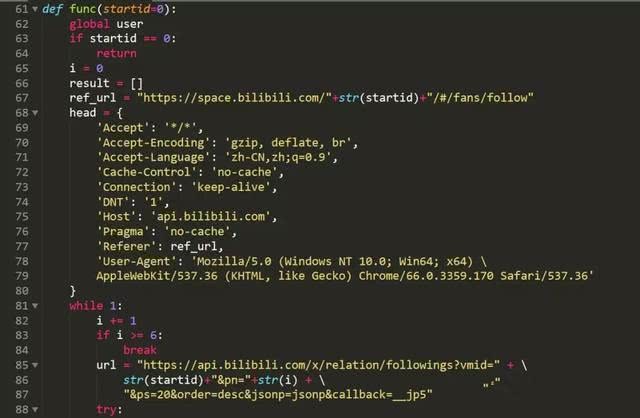
整个爬取页面的思路比较简单,首先设置header,用requests库进行API请求,获得关注的用户数据列表。
我们爬取前5页,每一页的数据进行简单的处理,然后转为字典数据进行获取mid,uname,sign3个维度的数据,最后save()函数存入db.

4.存入数据库
我们数据集里面一共有2个表,一个用户列表,用来存储所以的用户信息,一个是用户之间的关注信息。

5.探秘是热门UP主
打算利用已经爬取到本地的数据进行词云的生成,来看一下这10万用户中共同的关注的哪些UP主出现的次数最多。
代码的思路主要是从数据库中获取用户的名字,重复的次数越多说明越多的用户关注,然后我使用fate的一张图片作为词云的mask图片,最后生成词云图片。

最后一起来看一下词云图

可以看出蕾丝,暴走漫画,木鱼水心,参透之C君,papi酱等B站大UP主都是热门关注。

Python可以做什么?
web开发和 爬虫是比较适合 零基础的
自动化运维 运维开发 和 自动化测试 是适合 已经在做运维和测试的人员
大数据 数据分析 这方面 是很需要专业的 专业性相对而言比较强
科学计算 一般都是科研人员 在用
机器学习 和 人工智能 首先 学历 要求高 其次 高数要求高 难度很大
相关推荐
-
python爬虫爬取微博评论案例详解
前几天,杨超越编程大赛火了,大家都在报名参加,而我也是其中的一员. 在我们的项目中,我负责的是数据爬取这块,我主要是把对于杨超越 的每一条评论的相关信息. 数据格式:{"name":评论人姓名,"comment_time":评论时间,"comment_info":评论内容,"comment_url":评论人的主页} 以上就是我们需要的信息. 爬虫前的分析: 以上是杨超越的微博主页,这是我们首先需要获取到的内容. 因为我们需要等
-
实例讲解Python爬取网页数据
一.利用webbrowser.open()打开一个网站: >>> import webbrowser >>> webbrowser.open('http://i.firefoxchina.cn/?from=worldindex') True 实例:使用脚本打开一个网页. 所有Python程序的第一行都应以#!python开头,它告诉计算机想让Python来执行这个程序.(我没带这行试了试,也可以,可能这是一种规范吧) 1.从sys.argv读取命令行参数:打开一个新的文
-
Python 爬取携程所有机票的实例代码
打开携程网,查询机票,如广州到成都. 这时网址为:http://flights.ctrip.com/booking/CAN-CTU-day-1.html?DDate1=2018-06-15 其中,CAN 表示广州,CTU 表示成都,日期 "2018-06-15"就比较明显了.一般的爬虫,只有替换这几个值,就可以遍历了.但观察发现,有个链接可以看到当前网页的所有json格式的数据.如下 http://flights.ctrip.com/domesticsearch/search/Sear
-
python爬取盘搜的有效链接实现代码
因为盘搜搜索出来的链接有很多已经失效了,影响找数据的效率,因此想到了用爬虫来过滤出有效的链接,顺便练练手~ 这是本次爬取的目标网址http://www.pansou.com,首先先搜索个python,之后打开开发者工具, 可以发现这个链接下的json数据就是我们要爬取的数据了,把多余的参数去掉, 剩下的链接格式为http://106.15.195.249:8011/search_new?q=python&p=1,q为搜索内容,p为页码 以下是代码实现: import requests impor
-
Python爬取数据并写入MySQL数据库的实例
首先我们来爬取 http://html-color-codes.info/color-names/ 的一些数据. 按 F12 或 ctrl+u 审查元素,结果如下: 结构很清晰简单,我们就是要爬 tr 标签里面的 style 和 tr 下几个并列的 td 标签,下面是爬取的代码: #!/usr/bin/env python # coding=utf-8 import requests from bs4 import BeautifulSoup import MySQLdb print('连接到m
-
使用python爬取B站千万级数据
Python(发音:英[?pa?θ?n],美[?pa?θɑ:n]),是一种面向对象.直译式电脑编程语言,也是一种功能强大的通用型语言,已经具有近二十年的发展历史,成熟且稳定.它包含了一组完善而且容易理解的标准库,能够轻松完成很多常见的任务.它的语法非常简捷和清晰,与其它大多数程序设计语言不一样,它使用缩进来定义语句. Python支持命令式程序设计.面向对象程序设计.函数式编程.面向切面编程.泛型编程多种编程范式.与Scheme.Ruby.Perl.Tcl等动态语言一样,Python具备垃圾回收
-
python 爬取B站原视频的实例代码
B站原视频爬取,我就不多说直接上代码.直接运行就好. B站是把视频和音频分开.要把2个合并起来使用.这个需要分析才能看出来.然后就是登陆这块是比较难的. import os import re import argparse import subprocess import prettytable from DecryptLogin import login '''B站类''' class Bilibili(): def __init__(self, username, password, **
-

如何使用python爬取B站排行榜Top100的视频数据
记得收藏呀!!! 1.第三方库导入 from bs4 import BeautifulSoup # 解析网页 import re # 正则表达式,进行文字匹配 import urllib.request,urllib.error # 通过浏览器请求数据 import sqlite3 # 轻型数据库 import time # 获取当前时间 2.程序运行主函数 爬取过程主要包括声明爬取网页 -> 爬取网页数据并解析 -> 保存数据 def main(): #声明爬取网站 baseurl = &q
-
python爬取B站关注列表及数据库的设计与操作
目录 一.数据库的设计与操作 1.数据的分析 2.数据库设计 3.数据库操作 二.爬虫 三.完整代码 四.项目仓库 一.数据库的设计与操作 1.数据的分析 B站的关注列表在 https://api.bilibili.com/x/relation/followings?vmid=UID&pn=1&ps=50&order=desc&order_type=attention 中,一页最多50条信息. 我们大致分析一下信息, { "code": 0, "
-
python爬取安居客二手房网站数据(实例讲解)
是小打小闹 哈哈,现在开始正式进行爬虫书写首先,需要分析一下要爬取的网站的结构:作为一名河南的学生,那就看看郑州的二手房信息吧! 在上面这个页面中,我们可以看到一条条的房源信息,从中我们发现了什么,发现了连郑州的二手房都是这么的贵,作为即将毕业的学生狗惹不起啊惹不起 还是正文吧!!!由上可以看到网页一条条的房源信息,点击进去后就会发现: 房源的详细信息.OK!那么我们要干嘛呢,就是把郑州这个地区的二手房房源信息都能拿到手,可以保存到数据库中,用来干嘛呢,作为一个地理人,还是有点用处的,这次就不说
-
Python爬取股票信息,并可视化数据的示例
前言 截止2019年年底我国股票投资者数量为15975.24万户, 如此多的股民热衷于炒股,首先抛开炒股技术不说, 那么多股票数据是不是非常难找, 找到之后是不是看着密密麻麻的数据是不是头都大了? 今天带大家爬取雪球平台的股票数据, 并且实现数据可视化 先看下效果图 基本环境配置 python 3.6 pycharm requests csv time 目标地址 https://xueqiu.com/hq 爬虫代码 请求网页 import requests url = 'https://xueq
-
Python爬取腾讯疫情实时数据并存储到mysql数据库的示例代码
思路: 在腾讯疫情数据网站F12解析网站结构,使用Python爬取当日疫情数据和历史疫情数据,分别存储到details和history两个mysql表. ①此方法用于爬取每日详细疫情数据 import requests import json import time def get_details(): url = 'https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5&callback=jQuery3410284820553141302
-
python爬取链家二手房的数据
一.查找数据所在位置: 打开链家官网,进入二手房页面,选取某个城市,可以看到该城市房源总数以及房源列表数据. 二.确定数据存放位置: 某些网站的数据是存放在html中,而有些却api接口,甚至有些加密在js中,还好链家的房源数据是存放到html中: 三.获取html数据: 通过requests请求页面,获取每页的html数据 # 爬取的url,默认爬取的南京的链家房产信息 url = 'https://nj.lianjia.com/ershoufang/pg{}/'.format(page) #
-
单身狗福利?Python爬取某婚恋网征婚数据
目标网址https://www.csflhjw.com/zhenghun/34.html?page=1 一.打开界面 鼠标右键打开检查,方框里为你一个文小姐的征婚信息..由此判断出为同步加载 点击elements,定位图片地址,方框里为该女士的url地址及图片地址 可以看出该女士的url地址不全,之后在代码中要进行url的拼接,看一下翻页的url地址有什么变化 点击第2页 https://www.csflhjw.com/zhenghun/34.html?page=2 点击第3页 https://
-
用Python爬取某乎手机APP数据
目录 一.配置抓包工具 二.配置手机代理 三.抓取数据 四.总结 一.配置抓包工具 1.安装软件 本文选择的抓包工具:Fiddler 具体的下载安装这里不详细赘述!(网上搜Fiddler安装,一大堆教程),本文以实战为例,就不再这里浪费时间了! 2.配置Fiddler 安装好之后,接下来就开始配置Fiddler工具(这里是关键,仔细阅读!) 配置Connections 打开Fiddler后,点击Tools->Options 点击Connections 勾选上对应的选项 配置HTTPS 由于目