SpringBoot整合JDBC、Druid数据源的示例代码
1.SpringBoot整合JDBCTemplate
1.1.导入jdbc相关依赖包
主要的依赖包:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<!--实现web页面接口调用-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
1.2.yaml配置数据源
application.yml用于连接jdbc数据库操作数据源配置,这里是最简化的配置:
spring:
datasource:
username: root
password: admin
#假如时区报错,增加时区配置serverTimezone=UTC,以及编码配置
url: jdbc:mysql://localhost:3306/mybatis02_0322?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8
driver-class-name: com.mysql.cj.jdbc.Driver
实际开发过程中基本上会与Druid、C3P0整合,下面也给出了整合Druid数据源相关的配置,所以这里一并放上完整的application.yml配置:
spring:
datasource:
username: root
password: admin
#假如时区报错,增加时区配置serverTimezone=UTC
url: jdbc:mysql://localhost:3306/mybatis02_0322?serverTimezone=UTC&useUnicode=true&characterEncoding=utf-8
driver-class-name: com.mysql.cj.jdbc.Driver
type: com.alibaba.druid.pool.DruidDataSource
#springboot 默认是不注入这些属性值的,需要自己绑定
#druid 数据源专有配置
initialSize: 5
minIdle: 5
maxActive: 20
maxWait: 60000
timeBetweenEvictionRunsMillis: 60000
minEvictableIdleTimeMillis: 300000
validationQuery: SELECT 1 FROM DUAL
testWhileIdle: true
testOnBorrow: false
testOnReturn: false
poolPreparedStatements: true
#配置监控统计拦截的filters,stat:监控统计、log4j:日志记录、wall:防止sql注入
#如果允许时报错:java.lang.ClassNotFoundException:org.apache.log4j.Priority
#则导入 log4j 依赖即可,maven地址:https://mvnrepository.com/artifact/log4j/log4j
filters: stat,wall,log4j
maxPoolPreparedStatementPerConnectionSize: 20
useGlobalDataSourceStat: true
connectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=500
最后测试一下数据库连接访问是否成功:
@SpringBootTest
class SpringbootDataApplicationTests {
@Autowired
private DataSource dataSource;
@Test
void testConnection() throws SQLException {
System.out.println(dataSource.getClass());
Connection connection = dataSource.getConnection();
System.out.println(connection);
}
}
打印成功,显示获取到了数据源信息:
1.3.界面访问接口测试
@RestController
public class JDBCController {
@Autowired
private JdbcTemplate jdbcTemplate;
@RequestMapping("/queryList")
public List<Map<String, Object>> query() {
String sql = "select * from user";
List<Map<String, Object>> queryForList = jdbcTemplate.queryForList(sql);
return queryForList;
}
@RequestMapping("/addUser")
public String AddUser(){
String sql = "insert into mybatis02_0322.user(id, username, password) values(4, '李磊', '654321')";
int update = jdbcTemplate.update(sql);
return "AddUser Ok";
}
@RequestMapping("/update/{id}")
public String update(@PathVariable("id") Integer id){
String sql = "update mybatis02_0322.user set username = ?, password = ? where id = " + id;
Object[] objects = new Object[2];
objects[0] = "测试哈哈哈111";
objects[1] = "32321";
int update = jdbcTemplate.update(sql, objects);
return "updateUser Ok";
}
@RequestMapping("/delete/{id}")
public String delete(@PathVariable("id") Integer id){
String sql = "delete from mybatis02_0322.user where id = " + id;
int update = jdbcTemplate.update(sql);
return "delete Ok";
}
}
这里对应接口请求页面进行请求测试即可,后台数据库层面进行验证,比较简单,这里就不一一细说,对应可以去看我的源码。
2.SpringBoot整合DruidDataSource
2.1.Druid简介
Druid是阿里巴巴开源平台上一个数据库连接池实现,它结合了C3P0、DBCP、PROXOOL等DB池的优秀实践,同时加入了日志监控。
Druid可以很好地监控DB池连接和Sql的执行情况,是天生针对监控的DB连接池。
SpringBoot2.0以上默认使用Hikari数据源,可以说HiKari和Druid都是当前Java Web上开源的优秀数据源。
2.2.导入Druid相关依赖
对应pom.xml文件:
<!--整合alibaba druid数据源-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.2.3</version>
</dependency>
<!--导入log4j日志包-->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
2.3.配置Druid并使用监控页面
①编写DruidConfig类,启用后台监控功能Bean以及过滤器Bean:
@Configuration
public class DruidConfig {
@ConfigurationProperties(prefix = "spring.datasource")
@Bean
public DataSource druidDataSource(){
return new DruidDataSource();
}
//后台监控功能
@Bean
public ServletRegistrationBean statViewServlet(){
ServletRegistrationBean<StatViewServlet> bean = new ServletRegistrationBean<>(new StatViewServlet(), "/druid/*");
//后台需要有人登陆,账号密码配置
HashMap<String, String> initParameters = new HashMap<>();
initParameters.put("loginUsername", "admin"); //登陆key,是固定的 loginUsername loginPassword
initParameters.put("loginPassword", "123456");
//允许谁可以访问
initParameters.put("allow", "");
//禁止谁可以访问 initParameters.put("fengye", "192.168.1.10");
bean.setInitParameters(initParameters); //设置初始化参数
return bean;
}
//过滤器
@Bean
public FilterRegistrationBean webStatFilter(){
FilterRegistrationBean<Filter> bean = new FilterRegistrationBean<>();
bean.setFilter(new WebStatFilter());
HashMap<String, String> initParameters = new HashMap<>();
//这些不进行统计
initParameters.put("exclusions", "*.js,*.css,/druid/*");
bean.setInitParameters(initParameters);
return bean;
}
}
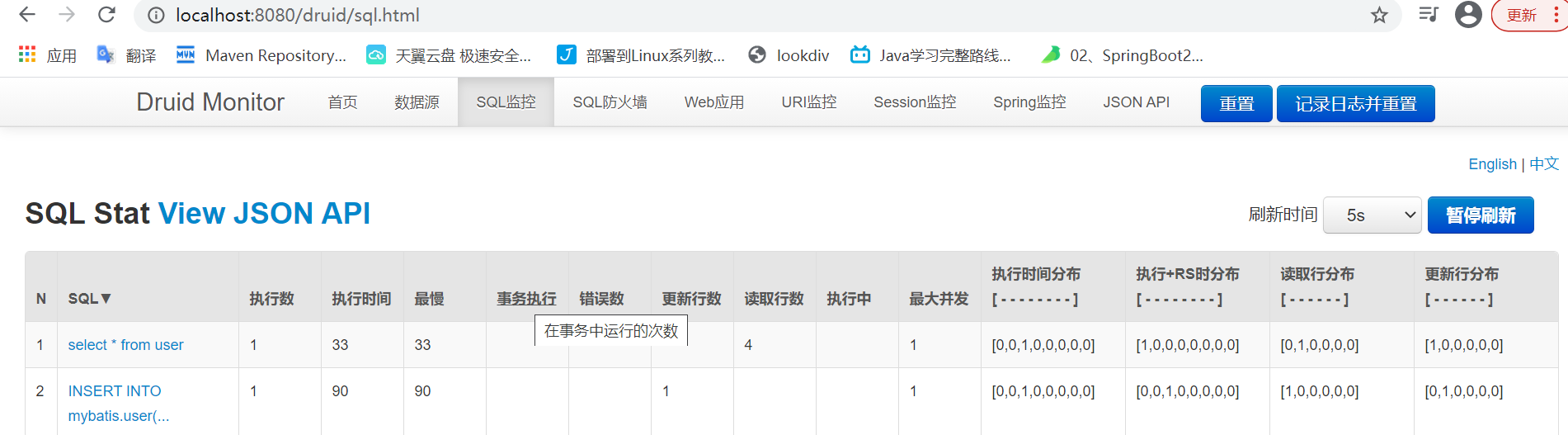
②启动页面访问Druid并测试请求访问sql:
本博客写作参考文档相关:
https://docs.spring.io/spring-boot/docs/current/reference/htmlsingle/#using-boot-starter
https://www.yuque.com/atguigu/springboot/aob431#wtNk1
Spring Boot 2 学习笔记(上):https://blog.csdn.net/u011863024/article/details/113667634
Spring Boot 2 学习笔记(下):
https://blog.csdn.net/u011863024/article/details/113667946
示例代码已上传至Github地址:
https://github.com/devyf/SpringBoot_Study
到此这篇关于SpringBoot整合JDBC、Druid数据源的文章就介绍到这了,更多相关SpringBoot整合JDBC、Druid数据源内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

springboot使用JdbcTemplate完成对数据库的增删改查功能
首先新建一个简单的数据表,通过操作这个数据表来进行演示 DROP TABLE IF EXISTS `items`; CREATE TABLE `items` ( `id` int(11) NOT NULL AUTO_INCREMENT, `title` varchar(255) DEFAULT NULL, `name` varchar(10) DEFAULT NULL, `detail` varchar(255) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE
-
SpringBoot使用JdbcTemplate操作数据库
前言 本文是对SpringBoot使用JdbcTemplate操作数据库的一个介绍,提供一个小的Demo供大家参考. 操作数据库的方式有很多,本文介绍使用SpringBoot结合JdbcTemplate. 新建项目 新建一个项目.pom文件中加入Jdbc依赖,完整pom如下: <?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM
-
Springboot mybatis plus druid多数据源解决方案 dynamic-datasource的使用详解
依赖 <dependency> <groupId>com.baomidou</groupId> <artifactId>dynamic-datasource-spring-boot-starter</artifactId> <version>2.5.0</version> </dependency> <dependency> <groupId>p6spy</groupId>
-
SpringBoot 2.0 整合sharding-jdbc中间件实现数据分库分表
一.水平分割 1.水平分库 1).概念: 以字段为依据,按照一定策略,将一个库中的数据拆分到多个库中. 2).结果 每个库的结构都一样:数据都不一样: 所有库的并集是全量数据: 2.水平分表 1).概念 以字段为依据,按照一定策略,将一个表中的数据拆分到多个表中. 2).结果 每个表的结构都一样:数据都不一样: 所有表的并集是全量数据: 二.Shard-jdbc 中间件 1.架构图 2.特点 1).Sharding-JDBC直接封装JDBC API,旧代码迁移成本几乎为零. 2).适
-
SpringBoot整合Druid数据源过程详解
这篇文章主要介绍了SpringBoot整合Druid数据源过程详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 1.数据库结构 2.项目结构 3.pom.xml文件 <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-jdbc</ar
-
springboot 动态数据源的实现方法(Mybatis+Druid)
Spring多数据源实现的方式大概有2中,一种是新建多个MapperScan扫描不同包,另外一种则是通过继承AbstractRoutingDataSource实现动态路由.今天作者主要基于后者做的实现,且方式1的实现比较简单这里不做过多探讨. 实现方式 方式1的实现(核心代码): @Configuration @MapperScan(basePackages = "com.goofly.test1", sqlSessionTemplateRef = "test1SqlSess
-
SpringBoot使用Druid数据源的配置方法
Druid是阿里巴巴开源平台上一个数据库连接池实现,它结合了C3P0.DBCP.PROXOOL等DB池的优点,同时加入了日志监控,可以很好的监控DB池连接和SQL的执行情况,可以说是针对监控而生的DB连接池(据说是目前最好的连接池) 一.依赖 为了测试,使用jdbcTemplate <!-- jdbcTemplate --> <dependency> <groupId>org.springframework.boot</groupId> <artifa
-
SpringBoot JdbcTemplate批量操作的示例代码
前言 在我们做后端服务Dao层开发,特别是大数据批量插入的时候,这时候普通的ORM框架(Mybatis.hibernate.JPA)就无法满足程序对性能的要求了.当然我们又不可能使用原生的JDBC进行操作,那样尽管效率会高,但是复杂度会上升. 综合考虑我们使用Spring中的JdbcTemplate和具名参数namedParameterJdbcTemplate来进行批量操作. 改造前 在开始讲解之前,我们首先来看下之前的JPA是如何批量操作的. 实体类User: public class App
-
SpringBoot整合阿里 Druid 数据源的实例详解
目录 1. 在容器中注册 DruidDataSource 数据源. 2. Druid 数据源各种属性配置方法 3. 开启Druid的内置监控页面 4. 打开 Druid 监控统计功能 5. 配置Web和Spring关联监控 6. 配置防火墙: 7. 给监控页加入账号密码 前言:今年是我的第二个 1024 了 ,和我一起大声说出来,技术宅改变世界!!! 本节主要介绍的是:SpringBoot 整合阿里 Druid 数据源手动配置方法 1. 在容器中注册 DruidDataSource 数据源. 编
-
SpringBoot整合Netty实现WebSocket的示例代码
目录 一.pom.xml依赖配置 二.代码 2.1.NettyServer 类 2.2.SocketHandler 类 2.3.ChannelHandlerPool 类 2.4.Application启动类 三.测试 一.pom.xml依赖配置 <!-- netty --> <dependency> <groupId>io.netty</groupId> <artifactId>netty-all</artifactId> <v
-
SpringBoot整合JDBC、Druid数据源的示例代码
1.SpringBoot整合JDBCTemplate 1.1.导入jdbc相关依赖包 主要的依赖包: <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-jdbc</artifactId> </dependency> <dependency> <groupId>mysql</gro
-
SpringBoot集成阿里巴巴Druid监控的示例代码
druid是阿里巴巴开源的数据库连接池,提供了优秀的对数据库操作的监控功能,本文要讲解一下springboot项目怎么集成druid. 本文在基于jpa的项目下开发,首先在pom文件中额外加入druid依赖,pom文件如下: <?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi=&qu
-
SpringBoot整合Shiro和Redis的示例代码
demo源码 此demo用SpringBoot+Shiro简单实现了登陆.注册.认证.授权的功能,并用redis做分布式缓存提高性能. 1.准备工作 导入pom.xml <?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XM
-
SpringBoot整合Elasticsearch游标查询的示例代码(scroll)
游标查询(scroll)简介 scroll 查询 可以用来对 Elasticsearch 有效地执行大批量的文档查询,而又不用付出深度分页那种代价. 游标查询会取某个时间点的快照数据. 查询初始化之后索引上的任何变化会被它忽略. 它通过保存旧的数据文件来实现这个特性,结果就像保留初始化时的索引 视图 一样. 启用游标查询可以通过在查询的时候设置参数 scroll 的值为我们期望的游标查询的过期时间. 游标查询的过期时间会在每次做查询的时候刷新,所以这个时间只需要足够处理当前批的结果就可以了,而不
-
SpringBoot整合分布式锁redisson的示例代码
目录 1.导入maven坐标 2.redisson配置类(如果redis没有密码就不需要private String password) 3.创建redisson的bean 4.测试,入队 5.测试,出队 6.分布式锁 1.导入maven坐标 <!-- 用redisson作为所有分布式锁,分布式对象等功能框架--> <dependency> <groupId>org.redisson</groupId> <artifactId>redisson&
-
springBoot整合RocketMQ及坑的示例代码
版本: JDK:1.8 springBoot:1.5.10 rocketMQ:4.2.0 pom 配置: <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>1.5.10.RELEASE</version> </parent> <d
-
MyBatis-Plus实现多数据源的示例代码
多数据源的目的在于一个代码模块可调用多个数据库的数据进行某些业务操作. MyBatis-Plus开发者写了一个多数据源叫dynamic-datasource-spring-boot-starter,非常简单易用. dynamic-datasource-spring-boot-starter文档 官方文档部分截图: 第三方集成的,基本上是目前比较主流的(用的比较多). 一.添加Maven依赖 <dependency> <groupId>com.baomidou</groupId
-
SpringBoot整合Mybatis注解开发的实现代码
官方文档: https://mybatis.org/mybatis-3/zh/getting-started.html SpringBoot整合Mybatis 引入maven依赖 (IDEA建项目的时候直接选就可以了) <dependency> <groupId>org.mybatis.spring.boot</groupId> <artifactId>mybatis-spring-boot-starter</artifactId> <ve