用python将word文档合并实例代码
目录
- 背景:
- 设计思路:
- 脚本环境说明:
- 完整代码:
- 功能执行效果图:
- 总结:
背景:
由于工作需要,现在有这么一个需求,要合并大量的word文档,而且要在不同的目录下找到同一个人的word文档,进行合并,最终输出一个合并后的word文档。一般来说几个或者十几个量不多的话,就手工合并一下好了,但现在这个量是真的大。目录有十多个,每个目录又有50多个不同人的word文档,而且同一个人在不同目录下又不一定都有word文档,因此,整个合并工作就出现了人工操作的困难:
工作量多;容易疏漏犯错。
为此,利用python进行高效准确的执行这类工作,尤为凸显现代自动化办公的能力。因此,我写了这个python脚本,作为一个小工具来辅助我的工作需求。
设计思路:
首先,整个脚本实现两个功能:
查看各目录下未提交word文档的名单合并各目录下的word文档查看各目录未提交名单:
对于这个需求,首先是读一个写有所有人姓名等信息的Excel文件,有格式要求。然后通过遍历Excel的信息,获取到所有人的姓名。遍历各目录下,是否有对应姓名的文件存在,如果没有,则输出没有提交文件的姓名。
合并word文件:
合并word文件和上一个需求有类似的地方。首先我们都需要读Excel文件,得到姓名信息,然后在各目录下获取到这个人所提交的所有word文件的文件路径,然后通过合并word的操作实现文件合并,合并后最终输出到指定的目录下。
脚本环境说明:
脚本对第三方包有依赖,执行前必须先安装对应的第三方包
pip install python-docx pywin32 xlrd
首先,目录结构必须是如下图所示,所有需要遍历的目录名称都必须是【实训+数字】,因为脚本中涉及多处正则匹配。
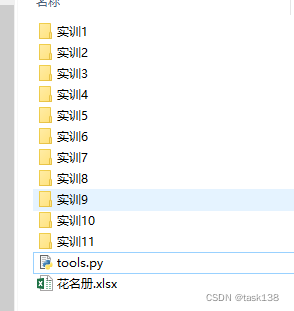
其次,Excel文件必须遵循下图所示的格式,首行是标题行,遍历的时候会自动跳过,遍历时会遍历C列和D列,其中C列是人员编号,D列是人员姓名

接着,python脚本必须要根目录下
最后,执行脚本的时候,必须带有传参,传递的参数就是那个Excel表
Microsoft Windows [版本 10.0.19043.1415] (c) Microsoft Corporation。保留所有权利。 C:\Windows\system32>python tools.py 花名册.xlsx
完整代码:
#! /usr/bin env python
# -*- coding:utf-8 -*-
"""
============================
======Power By Python3======
====== Author Task138 ======
============================
"""
import sys
import xlrd, os, re
from docx import Document
from docxcompose.composer import Composer
from win32com import client as wc
# 读Excel表获取学生的学号和姓名
def read_excel(excel_file):
workbook = xlrd.open_workbook(excel_file)
sheet = workbook.sheet_by_index(0)
name_list = []
name_dict = []
Sno_list = sheet.col_values(2)[1::]
Sname_list = sheet.col_values(3)[1::]
for i in range(len(Sno_list)):
try:
Sno = str(int(Sno_list[i]))
except:
Sno = Sno_list[i]
dict = {}
dict['Sno'] = Sno
dict['Sname'] = Sname_list[i]
name_list.append(Sname_list[i])
name_dict.append(dict)
return name_list, name_dict
# 合并文档
def merge_doc(source_file_path_list,target_file_path):
#填充分页符号文档
page_break_doc = Document()
page_break_doc.add_page_break()
#定义新文档
target_doc = Document(source_file_path_list[0])
target_composer = Composer(target_doc)
for i in range(len(source_file_path_list)):
#跳过第一个作为模板的文件
if i==0:
continue
#填充分页符文档
target_composer.append(page_break_doc)
#拼接文档内容
f = source_file_path_list[i]
target_composer.append(Document(f))
#保存目标文档
target_composer.save(target_file_path)
print('[ %s ]保存成功' % target_file_path)
if __name__ == '__main__':
if len(sys.argv) < 2:
print('缺乏必要的参数,请输入学生Excel表作为参数')
print('程序终止')
exit()
excel_file = sys.argv[1]
print('请选择需要执行的功能:')
print('[ 0 ] 查看各实训目录下未提交的学生名单')
print('[ 1 ] 合并实训文件')
cmd = input('请选择: ')
while cmd not in ['0','1']:
print('输入有误,请重新输入,按 Ctrl+C 可退出程序')
print('请选择需要执行的功能:')
print('[ 0 ] 查看各实训目录下未提交的学生名单')
print('[ 1 ] 合并实训文件')
cmd = input('请选择: ')
try:
name_list, name_dict = read_excel(excel_file)
except Exception as e:
print('Excel读取失败,程序终止,错误如下:')
print(e)
print()
exit()
else:
if cmd == '0':
# 实训目录的数列
file_list = []
for i in os.listdir():
if os.path.isdir(i):
if re.match(r'实训\d', i):
file_list.append(i)
for i in range(1, len(file_list) + 1):
dir_name = '实训%s' % i
# 进入该实训目录
os.chdir(dir_name)
file_list = os.listdir()
submit_list = []
for x in file_list:
for j in name_list:
if j in x and j not in submit_list:
submit_list.append(j)
result = list(set(submit_list) ^ set(name_list))
if result:
print(dir_name, result)
os.chdir('../')
if cmd == '1':
if not os.path.exists('实训汇总'):
os.mkdir('实训汇总')
print('目录[ 实训汇总 ]创建成功')
# 实训目录的数列
file_list = []
for i in os.listdir():
if os.path.isdir(i):
if re.match(r'实训\d',i):
file_list.append(i)
for i in name_dict:
doc_list = []
for j in range(1,len(file_list)+1):
dir_name = '实训%s' % j
# 进入该实训目录
os.chdir(dir_name)
tmp = []
for x in os.listdir():
# 判断文件尾缀
fname,fext = os.path.splitext(x)
# 如果是.doc,则转换为.docx
if fext == '.doc' and not x.startswith('~$'):
w = wc.Dispatch('Word.Application')
doc = w.Documents.Open(os.path.abspath(x))
doc.SaveAs(os.path.join(os.getcwd(),'%s.docx' % fname), 16)
doc.Close()
os.remove(x)
print('转换文件[ %s ]类型为.docx' % x)
elif fext == '.docx':
if (i['Sname'] in x) and (len(tmp) == 0):
# 只有一个文件
tmp.append(x)
elif (i['Sname'] in x) and (len(tmp) != 0):
# 有多个文件,按照最新的修改时间进行替换
tmp_file = tmp.pop()
old_file_mtime = os.path.getmtime(tmp_file)
new_file_mtime = os.path.getmtime(x)
if new_file_mtime > old_file_mtime:
# 新文件比较新,以新的为准
tmp.append(x)
else:
# 老文件比较新,以老文件为准
tmp.append(tmp_file)
else:
# 其它文件类型,直接跳过
# print('当前文件[ %s ]类型不是.doc或者.docx,跳过此文件的合并' % os.path.abspath(x))
continue
if tmp:
# 如果这次实训有这位同学的文件
doc_list.append(os.path.join(dir_name,tmp.pop()))
# 返回父目录
os.chdir('../')
if doc_list:
# 有内容,进行文档合并
try:
merge_file_name = i['Sno'] + '-' + i['Sname'] + '-' + '实训汇总' + '.docx'
merge_doc(doc_list, './实训汇总/' + merge_file_name)
except Exception as e:
print()
print('[ %s ]学生信息有误,程序中断' % i['Sname'])
print(e)
print()
功能执行效果图:

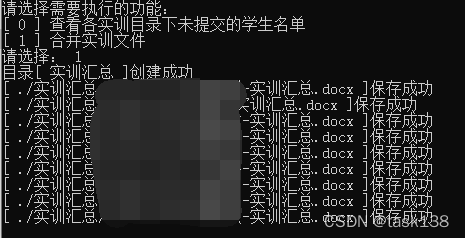
总结:
通过python,我们可以很便捷的满足我们的需求,鉴于这个需求似乎是长期性的,所以还是有必要写个小工具来优化一下自己的办公方式,提高自己的业务能力。
到此这篇关于用python将word文档合并实例代码的文章就介绍到这了,更多相关python word文档合并内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
详解python-docx处理Word必备工具
我的理解 为什么会用到python-docx,因为近段时间下载了大量网文,但格式都是html的,我个人习惯使用word处理文字,于是就想法设法把html文档转换为word,首先要考虑的问题就是从html中提取的文字怎么存word里呢,之前用了pandoc直接转换,带转换后的效果太不理想,没什么格式,不符合我这种对word格式有严格要求强迫症人的需要,于是就到处搜寻其他方法,终于功夫不负有心人,通过几天研究python-docx,感觉很适合我,就一边分析html文档,一边思考怎么用python-d
-

Python实现Word的读写改操作
目录 用 docx 模块读取 Word Word 调整样式 Word 写入操作 用 docx 模块读取 Word docx 安装 cmd 中输入pip install python-docx 即可安装 docx 模块 docx 常用函数 创建空白文档 from docx import Document document = Document() document.save("word.docx") # 生成空白 word print(document) 读取文档 from docx i
-
Python实现将Word表格嵌入到Excel中
今日需求 其实就是把Word中的表格转到Excel中,顺便做一个调整.这个需求在实际工作中,很多人还是经常碰到的! 如果单单是两个表格,那只要简单的复制黏贴即可,但如果上百了呢?那就得考虑自动化了.好在今天碰到的需求中的原文件格式是比较有规律的,那直接来尝试一下. # 首先要pip install python-docx # 如果原文件是doc格式,那就先转成docx from docx import Document import pandas as pd path = "./word表格转e
-
python提取word文件中的所有图片
前言 办公中,偶尔会碰到一种情况,需要提取word文档中的图片,决定写这样一款工具自动提取图片. 关于脚本的使用: 情景1:如果你拿到的是一个文件夹,所有的word文件都在这个文件夹的子目录下,深度为1层,你可以直接使用该脚本 情景2:如果你拿到的是一个文件夹,打开之后,里面杂乱无章的充斥着各种文件,你也不确定word文档都在哪,那么你需要使用Everything来手动提取出所有的word文档,虽然我也可以让脚本实现这个功能,但是使用脚本需要考虑到有可能存在同名文件,再处理起来代码量会更大,还是
-
用python将word文档合并实例代码
目录 背景: 设计思路: 脚本环境说明: 完整代码: 功能执行效果图: 总结: 背景: 由于工作需要,现在有这么一个需求,要合并大量的word文档,而且要在不同的目录下找到同一个人的word文档,进行合并,最终输出一个合并后的word文档.一般来说几个或者十几个量不多的话,就手工合并一下好了,但现在这个量是真的大.目录有十多个,每个目录又有50多个不同人的word文档,而且同一个人在不同目录下又不一定都有word文档,因此,整个合并工作就出现了人工操作的困难: 工作量多:容易疏漏
-
python实现word文档批量转成自定义格式的excel文档的思路及实例代码
支持按照文件夹去批量处理,也可以单独一个文件进行处理,并且可以自定义标识符 最近在开发一个答题类的小程序,到了录入试题进行测试的时候了,发现一个问题,试题都是word文档格式的,每份有100题左右,拿到的第一份试题,光是段落数目就有800个.而且可能有几十份这样的试题. 而word文档是没有固定格式的,想批量录入关系型数据库mysql,必须先转成excel文档.这个如果是手动一个个粘贴到excel表格,那就头大了. 我最终需要的excel文档结构是这样的:每道题独立占1行,每1列是这道题的一项内
-
Python操作word文档插入图片和表格的实例演示
前言 图片是Word的一种特殊内容,这篇文章主要介绍了关于Python操作word文档,向里面插入图片和表格的相关内容,下面话不多说了,来一起看看详细的代码 实例代码: # -*- coding: UTF8 -*- from docx import Document from docx.shared import Pt doc = Document() # 文件存储路径 path = "C:\\Users\\Administrator\\Desktop\\word文档\\" # 读取文
-
python读取word文档的方法
本文实例讲述了python读取word文档的方法.分享给大家供大家参考.具体如下: 首先下载安装win32com from win32com import client as wc word = wc.Dispatch('Word.Application') doc = word.Documents.Open('c:/test') doc.SaveAs('c:/test.text', 2) doc.Close() word.Quit() 这种方式产生的text文档,不能用python用普通的r方
-
python读取word文档,插入mysql数据库的示例代码
表格内容如下: 1.实现批量导入word文档,取文档标题中的数字作为编号 2.除取上面打钩的内容需要匹配出来入库入库,其他内容全部直接入库mysql # wuyanfeng # -*- coding:utf-8 -*- # 读取docx中的文本代码示例 import docx import pymysql import re import os # 创建数据库链接 conn = pymysql.connect( host='rm-bp1vu5d84dg12c6d59o.mysql.rds.ali
-
python输出pdf文档的实例
python导出pdf,参考诸多资料,发现pdfkit是效果比较好的. 故下载后进行了实现,多次失败后终于成功了,现将其中经验总结如下: """ 需要安装pdfkit,另外需要安装可执行文件wkhtmltopdf.exe, pdfkit核心命令是调用wkhtmltopdf.exe实现转pdf 有三个接口: pdfkit.from_url pdfkit.from_string pdfkit.from_file 需要注意的是,pdfkit主要是用来将html转pdf,所以文件也是
-
Python实现Word文档转换Markdown的示例
随着SaaS服务的流行,越来越多的人选择在各个平台上编写文档,制作表格并进行分享. 同时,随着Markdown语法的破圈,很多平台开始集成支持这种简洁的书写标记语言,这样可以保证平台上用户文档样式的统一性. 但是在一些场景下,我们还是会在本地的Office软件上写有很多文档,或者历史遗留了很多本地文档. 如果我们需要将其上传到各大平台,直接复制粘贴,大概率是会造成文档内容结构和样式的丢失.于此我们需要将其转换为 Markdown 语法. 很多桌面软件(比如Typora)都提供了导入 Word 文
-
Python加密word文档详解
目录 Python加密word文档 总结 Python加密word文档 我们先了解一下异或是什么.简单来说,如果a.b两个值不相同,则异或结果为1.如果a.b两个值相同,异或结果为0.我们简单的梳理一下代码思路.代码分为两部分,加密和解密. 1.加密 把文件转换成二进制的格式,然后生成等长的随机密钥进行异或操作,得到加密后的二进制文件.这一步我们需要保留的数据有,加密后的文件和随机生成的密钥,当然他们都是一些二进制数. 2.解密 这一步就简单了,我们把加密后的文件和之前随机生成的密钥再进行一次异
-
Python操作word文档的示例详解
目录 写在前面 创建一个文档 先实现第一步,写入一个标题 添加文字段落 列表的添加 图片的添加 表格添加 相关样式设置 页眉和页脚 写在前面 python-docx 不支持 doc 文档,一定要注意该点,如果使用 doc 文档,需要提前将其用 Word 相关软件转换为 docx 格式. doc 和 docx 是存在本质差异的,一个是二进制,另一个 XML 格式的文件. 模块的安装 pip install python-docx . 以下网址首先准备好 官方手册:https://python-do
-
Python实现Word文档样式批量处理
这里批量处理word文档的操作主要是通过python-docx非标准库实现的,通过定位到文档对象.再到段落.最后到一行文本从而完成针对文字对象的处理. 使用pip的方式安装python-docx pip install python-docx 将实现过程中需要的模块导入进来 from docx import Document # 文档处理对象 from docx.shared import RGBColor, Pt, Cm # 文本样式处理 import os # 应用/文件处理 import