Elasticsearch6.2服务器升配后的bug(避坑指南)
目录
- 一、问题描述
- 二、升级过程升配前
- 三、处理步骤
- 1.限流处理
- 2.mlock
- 3、总结
本篇文章记录最近一次生产服务器硬件升级之后引起集群不稳定的现象,希望可以帮到有其它人避免采坑。
一、问题描述
升级后出现的异常如下:
出现限流日志:stop throttling indexing: numMergesInFlight=8, maxNumMerges=9应用写入集群的rt耗时变高,同时集群监控的indexing的时长也变高mlocked的内存调用一直在增长

二、升级过程升配前
ES version:6.2.4
配置:32C64G
环境:阿里云ecs自建
gc:cms
jvm:30GB
升配后
ES version:6.2.4
配置:64C128G
环境:阿里云ecs自建
gc:cms
jvm:30GB
三、处理步骤
升配之后第二天首先应用表现出异常,写入ES的耗时变高了好十几倍,从40ms上升到600ms;升配导致集群变慢还是头一次遇到。通过对集群监控分析集群整体负载正常比升配之前有所下降,但是indexing的写入耗时监控确实比升配之前增长了很多。在ES的输出日志中出现了异常日志"stop throttling indexing: numMergesInFlight=8, maxNumMerges=9";
1.限流处理
当时怀疑应该是这个限流导致,ES的限流的主要目的是出于对集群的保护避免产生过多的段影响性能,说白了就是段的合并跟不上写入的速度,所以先来解决这个限流的问题,
由于配置文件没有配置最大线程数和最大的合并线程数,所以这两个值是用的是默认值
Spinning media has a harder time with concurrent I/O, so we need to decrease the number of threads that can concurrently access the disk per index. This setting will allow max_thread_count + 2 threads to operate on the disk at one time, so a setting of 1 will allow three threads.
index.merge.scheduler.max_thread_count
The maximum number of threads on a single shard that may be merging at once. Defaults to Math.max(1, Math.min(4, Runtime.getRuntime().availableProcessors() / 2)) which works well for a good solid-state-disk (SSD). If your index is on spinning platter drives instead, decrease this to 1.
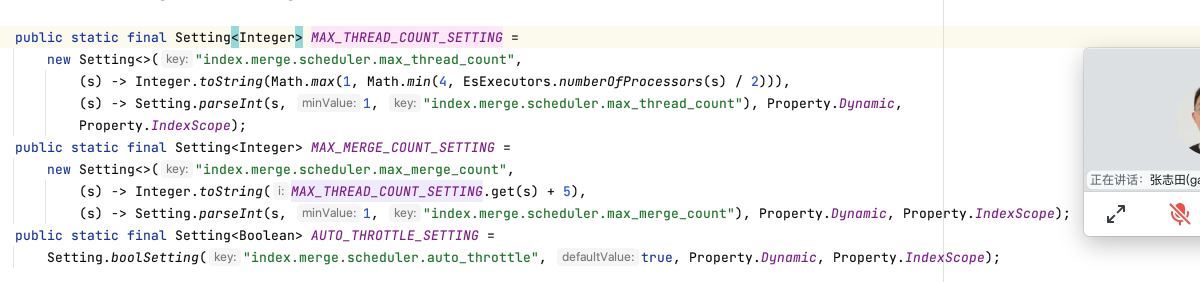
注意:在6.x版本之后已经取消了"indices.store.throttle.max_bytes_per_sec",所以现在只能通过调整max_thread_count,max_merge_count,默认max_thread_count最小是1最大是4,如果是机械盘推荐设1如果是ssd盘可以设成4或者更高,max_merge_count默认等于max_thread_count+5,也可以单独设置
可以通过命令查看默认的集群参数配置:
GET _settings/?include_defaults
可以配置到配置文件当中,也可以通过以下命令针对索引进行动态设置:
PUT index_name/_settings
{
"index.merge.scheduler.max_thread_count": 4,
"index.merge.scheduler.max_merge_count": 20
}
2.mlock
通过修改线程数之后,限流的问题解决了,但是应用的写入rt耗时问题还是没有得到解决 。通过对"hot_threads"进行分析发现主要的耗时还是在merge和index两大块,并且通过os层面的监控发现mlock的占用内存一直在增长,启动参数配置文件设置在内存锁定“bootstrap.memory_lock: true”不明白为什么还会出现mlock的增长。
处理办法:
将硬件配置降回到32C64G问题解决,增加一副本来提升查询性能
3、总结
经过3天问题排查,网上也没有找到类似的案例,网上更多的还是限流相关的案例,总结下来应该还是当前版本对于大内存的处理相关的bug,在7.x版本没有出现类似的内存问题
到此这篇关于Elasticsearch6.2服务器升配后的bug的文章就介绍到这了,更多相关Elasticsearch6.2服务器内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

基于Lucene的Java搜索服务器Elasticsearch安装使用教程
一.安装Elasticsearch Elasticsearch下载地址:http://www.elasticsearch.org/download/ ·下载后直接解压,进入目录下的bin,在cmd下运行elasticsearch.bat 即可启动Elasticsearch ·用浏览器访问: http://localhost:9200/ ,如果出现类似如下结果则说明安装成功: { "name" : "Benedict Kine", "cluster_na
-
Elasticsearch6.2服务器升配后的bug(避坑指南)
目录 一.问题描述 二.升级过程升配前 三.处理步骤 1.限流处理 2.mlock 3.总结 本篇文章记录最近一次生产服务器硬件升级之后引起集群不稳定的现象,希望可以帮到有其它人避免采坑. 一.问题描述 升级后出现的异常如下: 出现限流日志:stop throttling indexing: numMergesInFlight=8, maxNumMerges=9应用写入集群的rt耗时变高,同时集群监控的indexing的时长也变高mlocked的内存调用一直在增长 二.升级过程升配前 ES ve
-
SQL Server误区30日谈 第1天 正在运行的事务在服务器故障转移后继续执行
误区 #1:在服务器故障转移后,正在运行的事务继续执行 这当然是错误的! 每次故障转移都伴随着某种形式的恢复.但是如果当正在执行的事务没有Commit时,由于服务器或实例崩溃导致连接断开,SQL Server可没有办法在故障转移后的服务器重新建立事务的上下文并继续执行事务-无论你使用的故障转移方式是集群,镜像,日志传送或是SAN复制. 对于故障转移集群来说,当故障转移发生后,一个SQL Server实例在另一个故障转移集群的节点启动.所有实例上的数据库都要经历Recovery阶段-也就是所有没有
-
Mybatis mapper标签中配置子标签package的坑及解决
目录 mapper标签中配置子标签package的坑 Mybatis中mappers标签介绍 配置方式 1.接口所在包 2.相对路径配置 3.类注册引入 4.使用URL绝对路径方式引入(不用) 使用总结 mapper标签中配置子标签package的坑 首先java目录下的.java文件和resources下的.xml文件必须要在同一目录下,但是在resource中创建目录时不要顺手像在java文件中创建包一样,直接创建了com.mapper文件夹,这样不是创建了com - mapper两个文件夹
-
ShardingJdbc读写分离的BUG踩坑解决
目录 前言 数据库介绍 1. 常规写完读 2. 在一个 service 里面调用另一个 service 3. 新开一个线程去调用 service2 4. service2 新开一个事务执行 前言 最近公司准备接入ShardingJdbc做读写分离了,老大让我们理一理有没有写完数据立马读的场景,因为主从同步是有延迟的,如果写完读取数据走到从库,而从库正好有延迟,没读取到数据,岂不是造成了生产事故. 今天我们来看看,ShardingJdbc作为一个成熟的框架是怎么处理写完数据立即读取的场景的. 数据
-
Docker安装阿里云服务器和在虚拟机安装遇到的坑(问题小结)
Docker安装(阿里云服务器) Docker官方centos安装教程 卸载旧版本 $ sudo yum remove docker \ docker-client \ docker-client-latest \ docker-common \ docker-latest \ docker-latest-logrotate \ docker-logrotate \ docker-engine 使用存储库安装 在新主机上首次安装Docker Engine之前,需要设置Docker存储库.之后,您
-
Centos 6.5 服务器优化配置备忘(一些基础优化和安全设置)
本文 centos 6.5 优化 的项有18处: 1.centos6.5最小化安装后启动网卡 2.ifconfig查询IP进行SSH链接 3.更新系统源并且升级系统 4.系统时间更新和设定定时任 5.修改ip地址.网关.主机名.DNS 6.关闭selinux,清空iptables 7.创建普通用户并进行sudo授权管理 8.修改SSH端口号和屏蔽root账号远程登陆 9.锁定关键文件系统(禁止非授权用户获得权限) 10.精简开机自启动服务 11.调整系统文件描述符大小 12.设置系统字符集 13
-
详解超简单的react服务器渲染(ssr)入坑指南
前言 本文是基于react ssr的入门教程,在实际项目中使用还需要做更多的配置和优化,比较适合第一次尝试react ssr的小伙伴们.技术涉及到 koa2 + react,案例使用create-react-app创建 SSR 介绍 Server Slide Rendering,缩写为 ssr 即服务器端渲染,这个要从SEO说起,目前react单页应用HTML代码是下面这样的 <!DOCTYPE html> <html lang="en"> <head&g
-
Navicat Premium15连接云服务器中的数据库问题及遇到坑
使用云服务器时,我们有时会连接数据库,但在使用Navicat Premium15来连接时,总会遇到报错. 常规连接方式,以腾讯云服务器中的MySQL5.6.50版本来介绍. 常规链接: 以上填写好后,点击测试连接,此时会报错,报错如图: 无法连接!如此,在腾讯云服务器中修改安全组规则,入站及出站规则均需改动. 点击完成后,再进行出站规则的调配,同入站规则,不再讲解. 以上操作完毕后,回到Navicat Premium15中进行配置,依然报错(2003-Can't connect to MySQL
-
解决jupyter notebook启动后没有token的坑
时隔一年,重拾python,想在pycharm里面使用jupyter完成一些小demo,结果一年后的jupyter死活没有token,连都连不上去,经过一番排查找出问题所在. 场景重现 正常情况下启动jupyter应该是这样的: 而我的jupyter启动后是这样的 迷了,没有token??,在浏览器是可以正常使用,但是没有token!我怎么在pycharm使用?? 解决 在jupyter配置文件中发现: 这里配置了password,导致在启动jupyter时没有token生成. 删除后即可正常.
-
.NET+PostgreSQL实践与避坑指南(推荐)
简介 .NET+PostgreSQL(简称PG)这个组合我已经用了蛮长的一段时间,感觉还是挺不错的.不过大多数人说起.NET平台,还是会想起跟它"原汁原味"配套的Microsoft SQL Server(简称MSSQL),其实没有MSSQL也没有任何问题,甚至没有Windows Server都没问题,谁说用.NET就一定要上微软全家桶?这都什么年代了-- PG和MSSQL的具体比较我就不详细展开了,自行搜一下,这种比较分析文章很多.应该说两个RDBMS各有特色,MSSQL工具集庞大(大