redis集群搭建教程及遇到的问题处理
这里,在一个Linux虚拟机上搭建6个节点的redis伪集群,思路很简单,一台虚拟机上开启6个redis实例,每个redis实例有自己的端口。这样的话,相当于模拟出了6台机器了,然后在以这6个实例组建redis集群就可以了。
前提:redis已经安装,目录为/usr/local/redis-4.0.1 如不会,可以参考一下文章 windows下安装redis Linux下安装redis
redis集群是用的ruby脚本,所以要想执行该脚本,需要ruby环境.。对应redis的源码src目录下的redis-trib.rb,redis-trib.rb是redis官方推出的管理redis集群的工具,是基于redis提供的集群命令封装成简单、便捷、实用的操作工具。so
安装ruby环境:
1.yum install ruby
2.yum install rubygems
3.gem install redis

Centos默认支持ruby到2.0.0,redis需要最低是2.2.2。解决办法是 先安装rvm 再把ruby版本升级到2.3.3
1.sudo yum install curl
2.安装rvm
curl -L get.rvm.io | bash -s stable
3.
source /usr/local/rvm/scripts/rvm
4.查看rvm库中已知的ruby版本
rvm list known
5.安装一个ruby版本
rvm install 2.3.3
6.使用一个ruby版本
rvm use 2.3.3
7.卸载一个已知版本
rvm remove 2.0.0
8.查看版本
ruby --version
9.再安装redis
gem install redis
redis集群搭建
创建redis-cluster目录,再创建redis-8001,redis-8002,redis-8003节点目录,再把redis-conf分别复制到节点目录下
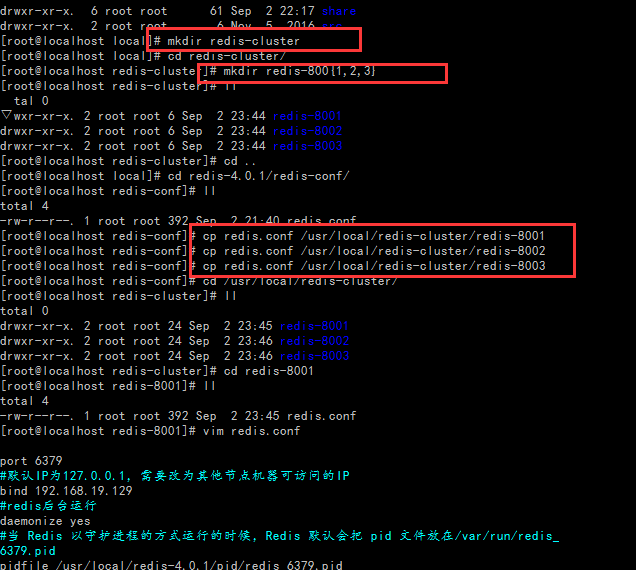
分别修改节点下redis-conf文件,由于在一台机器(192.16819.129)上,因此每个实例应该有不同的端口;同时,每个实例显然会有自己的存放数据的地方;开启AOF模式;开启集群配置;开启后台模式;
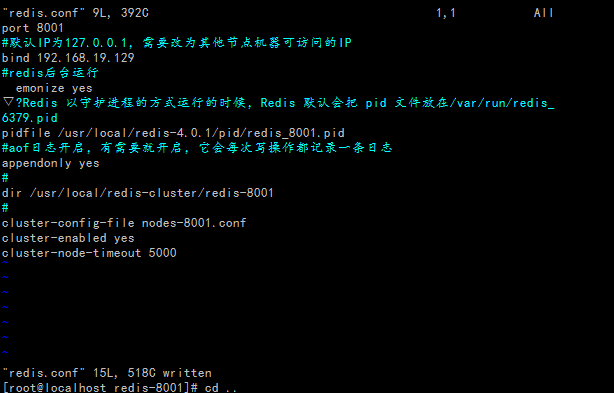
开启redis服务,看看是否能启动。ok没问题。
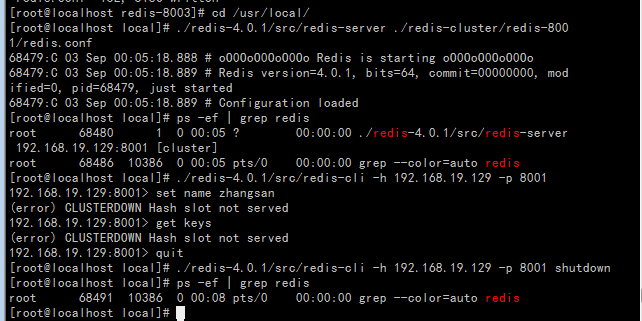
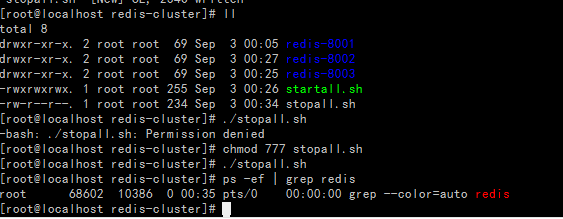
创建startall.sh脚本(提示permission denied说明权限不足,执行命令chmod 777 startall.sh修改权限)
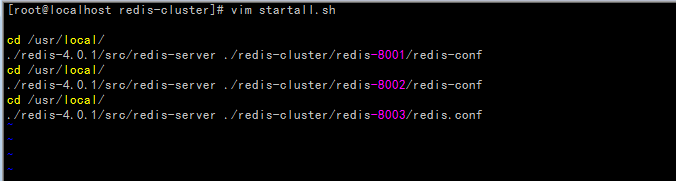
启动startall.sh脚本
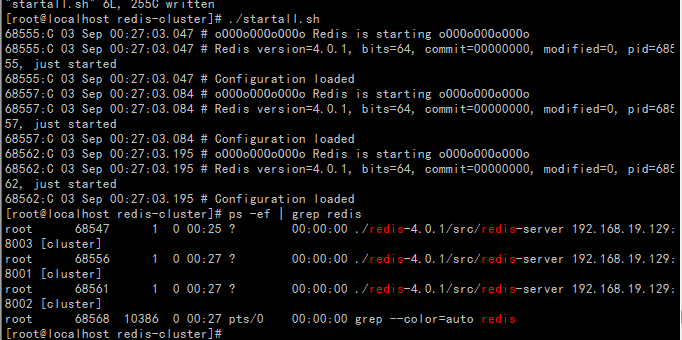
创建stopall.sh脚本
创建集群
接下来,我们要通过Ruby脚本来创建集群了。
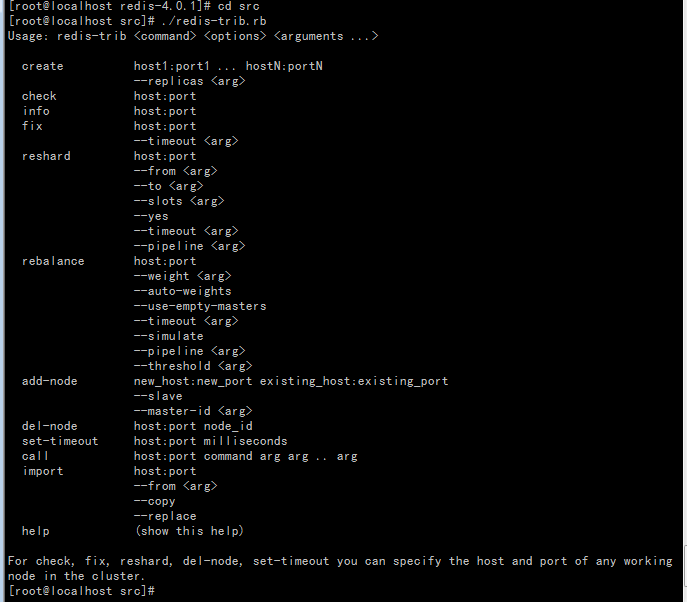
可以看到redis-trib.rb具有以下功能:
- create :创建集群
- check :检查集群
- info :查看集群信息
- fix :修复集群
- reshard :在线迁移slot
- rebalance :平衡集群节点slot数量
- add-node :将新节点加入集群
- del-node :从集群中删除节点
- set-timeout :设置集群节点间心跳连接的超时时间
- call :在集群全部节点上执行命令
- import :将外部redis数据导入集群
redis-trib.rb主要有两个类: ClusterNode 和 RedisTrib 。 ClusterNode 保存了每个节点的信息, RedisTrib 则是redis-trib.rb各个功能的实现

注意:提示最少3个master cluster nodes,前面说是创建6个,但实际操作我只创建了3个节点,所以可以得出我们创建redis集群是最少三个主节点,而且应该是奇数个,so,不要偷懒,再创建三个吧。
特别注意:这里关键是可选replicas参数,--replicas 2 意思为为每个 master 分配 2 各 slave,replicas表示需要有几个slave。不填写这个参数是可以创建成功的,这样是三个master 。关于replicas参数后面再介绍吧

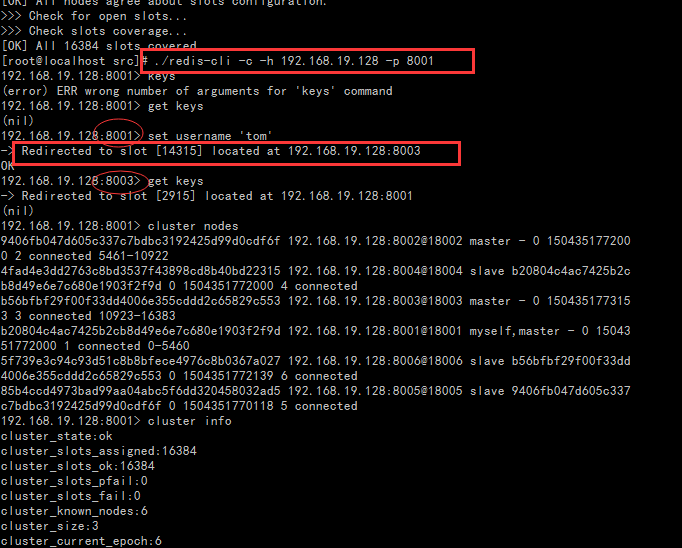
首先,--replicas 1 1其实代表的是一个比例,就是主节点数/从节点数的比例。那么想一想,在创建集群的时候,哪些节点是主节点呢?哪些节点是从节点呢?答案是将按照命令中IP:PORT的顺序,先是3个主节点,然后是3个从节点。
其次,注意到图中slot的概念。slot对于Redis集群而言,就是一个存放数据的地方,就是一个槽。对于每一个Master而言,会存在一个slot的范围,而Slave则没有。在Redis集群中,依然是Master可以读、写,而Slave只读。数据的写入,实际上是分布的存储在slot中,这和以前1.X的主从模式是不一样的(主从模式下Master/Slave数据存储是完全一致的),因为Redis集群中3台Master的数据存储并不一样。这个将在后续的随笔中验证。
相关推荐
-

redis数据结构之intset的实例详解
redis数据结构之intset的实例详解 在redis中,intset主要用于保存整数值,由于其底层是使用数组来保存数据的,因而当对集合进行数据添加时需要对集合进行扩容和迁移操作,因而也只有在数据量不大时redis才使用该数据结构来保存整数集合.其具体的底层数据结构如下: typedef struct intset { // 编码方式 uint32_t encoding; // 集合包含的元素数量 uint32_t length; // 保存元素的数组 int8_t contents[]; }
-
Redis 实现队列原理的实例详解
Redis 实现队列原理的实例详解 场景说明: ·用于处理比较耗时的请求,例如批量发送邮件,如果直接在网页触发执行发送,程序会出现超时 ·高并发场景,当某个时刻请求瞬间增加时,可以把请求写入到队列,后台在去处理这些请求 ·抢购场景,先入先出的模式 命令: rpush + blpop 或 lpush + brpop rpush : 往列表右侧推入数据 blpop : 客户端阻塞直到队列有值输出 简单队列: simple.php $stmt = $pdo->prepare('select id, c
-
python脚本实现Redis未授权批量提权
前言 本文主要给大家介绍了关于redis未授权批量提权的相关内容,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧. 安装依赖 sudo easy_install redis 使用 redis python hackredis.py usage: hackredis.py [-h] [-l IPLIST] [-p PORT] [-r ID_RSAFILE] [-sp SSH_PORT] For Example: -----------------------------------
-
Linux Redis 的安装步骤详解
Linux Redis 的安装步骤详解 前言: Redis 是一个开源(BSD许可)的,内存中的数据结构存储系统,它可以用作数据库.缓存和消息中间件. 它支持多种类型的数据结构,如 字符串(strings), 散列(hashes), 列表(lists), 集合(sets), 有序集合(sorted sets) 与范围查询, bitmaps, hyperloglogs 和 地理空间(geospatial) 索引半径查询. redis 是完全开源免费的,是一个高性能的key-value数据库.Re
-
redis数据类型_动力节点Java学院整理
Redis支持5种数据类型,它们描述如下: Strings - 字符串 Redis的字符串是字节序列.在Redis中字符串是二进制安全的,这意味着他们有一个已知的长度,是没有任何特殊字符终止决定的,所以可以存储任何东西,最大长度可达512兆. 例子 redis 127.0.0.1:6379> SET name "yiibai" OK redis 127.0.0.1:6379> GET name "yiibai" 在上面的例子使用Redis命令set和ge
-
Redis集群搭建全记录
Redis集群是一个提供在多个Redis节点间共享数据的程序集. Redis集群中不支持处理多个keys的命令. Redis集群通过分区来提供一定程度的可用性.在某个节点宕机或者不可用的时候可以继续处理命令. Redis集群数据分片 在Redis集群中,使用数据分片(sharding)而不是一致性hash(consistency hashing)来实现,一个Redis集群包含16384个哈希槽(hash slot),数据库中的每个键都存在这些哈希槽中的某一个,通过CRC16校验后对16384取模
-
redis集群搭建教程及遇到的问题处理
这里,在一个Linux虚拟机上搭建6个节点的redis伪集群,思路很简单,一台虚拟机上开启6个redis实例,每个redis实例有自己的端口.这样的话,相当于模拟出了6台机器了,然后在以这6个实例组建redis集群就可以了. 前提:redis已经安装,目录为/usr/local/redis-4.0.1 如不会,可以参考一下文章 windows下安装redis Linux下安装redis redis集群是用的ruby脚本,所以要想执行该脚本,需要ruby环境..对应redis的源码src目
-
Redis 集群搭建和简单使用教程
前言 Redis集群搭建的目的其实也就是集群搭建的目的,所有的集群主要都是为了解决一个问题,横向扩展. 在集群的概念出现之前,我们使用的硬件资源都是纵向扩展的,但是纵向扩展很快就会达到一个极限,单台机器的Cpu的处理速度,内存大小,硬盘大小没办法一直满足需求,而且机器纵向扩展的成本是相当高的.集群的出现就是能够让多台机器像一台机器一样工作,实现了资源的横向扩展. Redis是内存型数据库,当我们要存储的数据达到一定程度时,单台机器的内存满足不了我们的需求,搭建集群则是一种很好的解决方案. 介绍安
-
docker实现redis集群搭建的方法步骤
目录 一.创建redis docker基础镜像 二.制作redis节点镜像 三.运行redis集群 引用: 摘要:接触docker以来,似乎养成了一种习惯,安装什么应用软件都想往docker方向做,今天就想来尝试下使用docker搭建redis集群. 首先,我们需要理论知识:Redis Cluster是Redis的分布式解决方案,它解决了redis单机中心化的问题,分布式数据库--首要解决把整个数据集按照分区规则映射到多个节点的问题. 这边就需要知道分区规则--哈希分区规则.Redis Clus
-
redis集群搭建_动力节点Java学院整理
现在项目上用redis的话,很少说不用集群的情况,毕竟如果生产上只有一台redis会有极大的风险,比如机器挂掉,或者内存爆掉,就比如我们生产环境曾今也遭遇到这种情况,导致redis内存不够挂掉的情况,当然这些都是我们及其不能容忍的,第一个必须要做到高可靠,其次才是高性能,好了,下面我来逐一搭建一下. 一:Redis集群搭建 1. 下载 首先去官网下载较新的3.2.0版本,下载方式还是非常简单的,比如官网介绍的这样. $ wget http://download.redis.io/releases
-
详解Redis集群搭建的三种方式
一.单节点实例 单节点实例还是比较简单的,平时做个测试,写个小程序如果需要用到缓存的话,启动一个 Redis 还是很轻松的,做为一个 key/value 数据库也是可以胜任的 二.主从模式(master/slaver) redis 主从模式配置 主从模式: redis 的主从模式,使用异步复制,slave 节点异步从 master 节点复制数据,master 节点提供读写服务,slave 节点只提供读服务(这个是默认配置,可以通过修改配置文件 slave-read-only 控制).master
-
Docker上实现Redis集群搭建
环境:Docker + ( Redis:5.0.5 * 3 ) 1.拉取镜像 docker pull redis:5.0.5 2.创建Redis容器 创建三个 redis 容器: redis-node1:6379 redis-node2:6380 redis-node3:6381 docker create --name redis-node1 -v /data/redis-data/node1:/data -p 6379:6379 redis:5.0.5 --cluster-enabled y
-
redis集群搭建过程(非常详细,适合新手)
目录 redis集群搭建 一.Redis Cluster(Redis集群)简介 二.集群搭建需要的环境 三.集群搭建具体步骤如下(注意要关闭防火墙) 四.结语 redis集群搭建 在开始redis集群搭建之前,我们先简单回顾一下redis单机版的搭建过程 下载redis压缩包,然后解压压缩文件: 进入到解压缩后的redis文件目录(此时可以看到Makefile文件),编译redis源文件: 把编译好的redis源文件安装到/usr/local/redis目录下,如果/local目录下没有redi
-
Docker微服务的ETCD集群搭建教程详解
目录 etcd的特性 Etcd构建自身高可用集群主要有三种形式 本次搭建的基础环境 1.将服务器挨个添加进集群 2.将服务器统一添加进集群 etcd api接口 服务注册与发现 etcd是一个高可用的键值存储系统,主要用于共享配置和服务发现.etcd是由CoreOS开发并维护的,灵感来自于 ZooKeeper 和 Doozer,它使用Go语言编写,并通过Raft一致性算法处理日志复制以保证强一致性.Raft是一个来自Stanford的新的一致性算法,适用于分布式系统的日志复制,Raft通过选举的
-
Nginx+Tomcat高性能负载均衡集群搭建教程
Nginx是一个高性能的HTTP服务器/反向代理服务器及电子邮件(IMAP/POP3)代理服务器.其占有内存少,并发能力强,在同类型的网页服务器中表现较好.Nginx可以在大多数Unix Linux OS上编译运行,并有Windows移植版.一般情况下,对于新建站点,建议使用最新稳定版作为生产版本. 单个Tomcat最大支持在线访问是500左右,要通知支持更多的访问量一个Tomcat就没法做到了.在这里我们采用集群部署方式,使用多个Tomcat,反向代理使用Nginx. 架构如下: 准备工作 a