正则基础之 环视 Lookaround
1 环视基础
环视只进行子表达式的匹配,不占有字符,匹配到的内容不保存到最终的匹配结果,是零宽度的。环视匹配的最终结果就是一个位置。
环视的作用相当于对所在位置加了一个附加条件,只有满足这个条件,环视子表达式才能匹配成功。
环视按照方向划分有顺序和逆序两种,按照是否匹配有肯定和否定两种,组合起来就有四种环视。顺序环视相当于在当前位置右侧附加一个条件,而逆序环视相当于在当前位置左侧附加一个条件。
|
表达式 |
说明 |
|
(?<=Expression) |
逆序肯定环视,表示所在位置左侧能够匹配Expression |
|
(?<!Expression) |
逆序否定环视,表示所在位置左侧不能匹配Expression |
|
(?=Expression) |
顺序肯定环视,表示所在位置右侧能够匹配Expression |
|
(?!Expression) |
顺序否定环视,表示所在位置右侧不能匹配Expression |
对于环视的叫法,有的文档里叫预搜索,有的叫什么什么断言的,这里使用了更多人容易接受的《精通正则表达式》中“环视”的叫法,其实叫什么无所谓,只要知道是什么作用就是了,就这么几个语法规则, 还是很容易记的
2 环视匹配原理
环视是正则中的一个难点,对于环视的理解,可以从应用和原理两个角度理解,如果想理解得更清晰、深入一些,还是从原理的角度理解好一些,正则匹配基本原理参考 NFA引擎匹配原理。
上面提到环视相当于对“所在位置”附加了一个条件,环视的难点在于找到这个“位置”,这一点解决了,环视也就没什么秘密可言了。
顺序环视匹配过程
对于顺序肯定环视(?=Expression)来说,当子表达式Expression匹配成功时,(?=Expression)匹配成功,并报告(?=Expression)匹配当前位置成功。
对于顺序否定环视(?!Expression)来说,当子表达式Expression匹配成功时,(?!Expression)匹配失败;当子表达式Expression匹配失败时,(?!Expression)匹配成功,并报告(?!Expression)匹配当前位置成功;
顺序肯定环视的例子已在NFA引擎匹配原理中讲解过了,这里再讲解一下顺序否定环视。
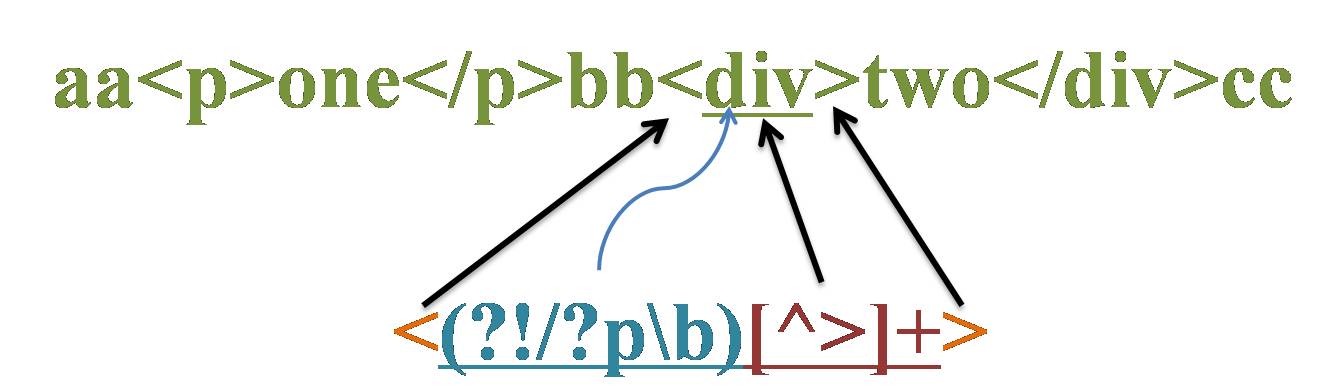
源字符串:aa<p>one</p>bb<div>two</div>cc
正则表达式:<(?!/?p\b)[^>]+>
这个正则的意义就是匹配除<p…>或</p>之外的其余标签。
匹配过程:
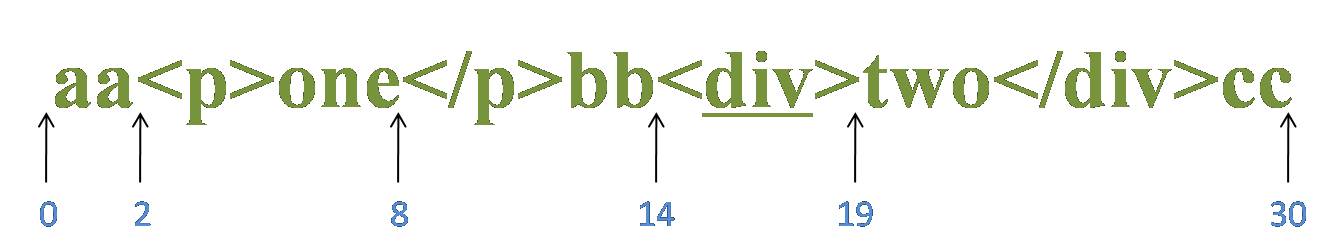
首先由字符“<”取得控制权,从位置0开始匹配,由于“<”匹配“a”失败,在位置0处整个表达式匹配失败,第一次迭代匹配失败,正则引擎向前传动,由位置1处开始尝试第二次迭代匹配。
重复以上过程,直到位置2,“<”匹配“<”成功,控制权交给“(?!/?p\b)”;“(?!/?p\b)”子表达式取得控制权后,进行内部子表达式的匹配。首先由“/?”取得控制权,尝试匹配“p”失败,进行回溯,不匹配,控制权交给“p”;由“p”来尝试匹配“p”,匹配成功,控制权交给“\b”;由“\b”来尝试匹配位置4,匹配成功。此时子表达式匹配完成,“/?p\b”匹配成功,那么环视表达式“(?!/?p\b)”就匹配失败。在位置2处整个表达式匹配失败,新一轮迭代匹配失败,正则引擎向前传动,由位置3处开始尝试下一轮迭代匹配。
在位置8处也会遇到一轮“/?p\b”匹配“/p”成功,而导致环视表达式“(?!/?p\b)”匹配失败,从而导致整个表达式匹配失败的过程。
重复以上过程,直到位置14,“<”匹配“<”成功,控制权交给“(?!/?p\b)”;“/?”尝试匹配“d”失败,进行回溯,不匹配,控制权交给“p”;由“p”来尝试匹配“d”,匹配失败,已经没有备选状态可供回溯,匹配失败。此时子表达式匹配完成,“/?p\b”匹配失败,那么环视表达式“(?!/?p\b)”就匹配成功。匹配的结果是位置15,然后控制权交给“[^>]+”;由“[^>]+”从位置15进行尝试匹配,可以成功匹配到“div”,控制权交给“>”;由“>”来匹配“>”。
此时正则表达式匹配完成,报告匹配成功。匹配结果为“<div>”,开始位置为14,结束位置为19。其中“<”匹配“<”,“(?!/?p\b)”匹配位置15,“[^>]+”匹配字符串“div”,“>”匹配“>”。
逆序环视基础
对于逆序肯定环视(?<=Expression)来说,当子表达式Expression匹配成功时,(?<=Expression)匹配成功,并报告(?<=Expression)匹配当前位置成功。
对于逆序否定环视(?<!Expression)来说,当子表达式Expression匹配成功时,(?<!Expression)匹配失败;当子表达式Expression匹配失败时,(?<!Expression)匹配成功,并报告(?<!Expression)匹配当前位置成功;
顺序环视相当于在当前位置右侧附加一个条件,所以它的匹配尝试是从当前位置开始的,然后向右尝试匹配,直到某一位置使得匹配成功或失败为止。而逆序环视的特殊处在于,它相当于在当前位置左侧附加一个条件,所以它不是在当前位置开始尝试匹配的,而是从当前位置左侧某一位置开始,匹配到当前位置为止,报告匹配成功或失败。
顺序环视尝试匹配的起点是确定的,就是当前位置,而匹配的终点是不确定的。逆序环视匹配的起点是不确定的,是当前位置左侧某一位置,而匹配的终点是确定的,就是当前位置。
所以顺序环视相对是简单的,而逆序环视相对是复杂的。这也就是为什么大多数语言和工具都提供了对顺序环视的支持,而只有少数语言提供了对逆序环视支持的原因。
JavaScript中只支持顺序环视,不支持逆序环视。
Java中虽然顺序环视和逆序环视都支持,但是逆序环视只支持长度确定的表达式,逆序环视中量词只支持“?”,不支持其它长度不定的量词。长度确定时,引擎可以向左查找固定长度的位置作为起点开始尝试匹配,而如果长度不确定时,就要从位置0开始尝试匹配,处理的复杂度是显而易见的。
目前只有.NET中支持不确定长度的逆序环视。
逆序环视匹配过程
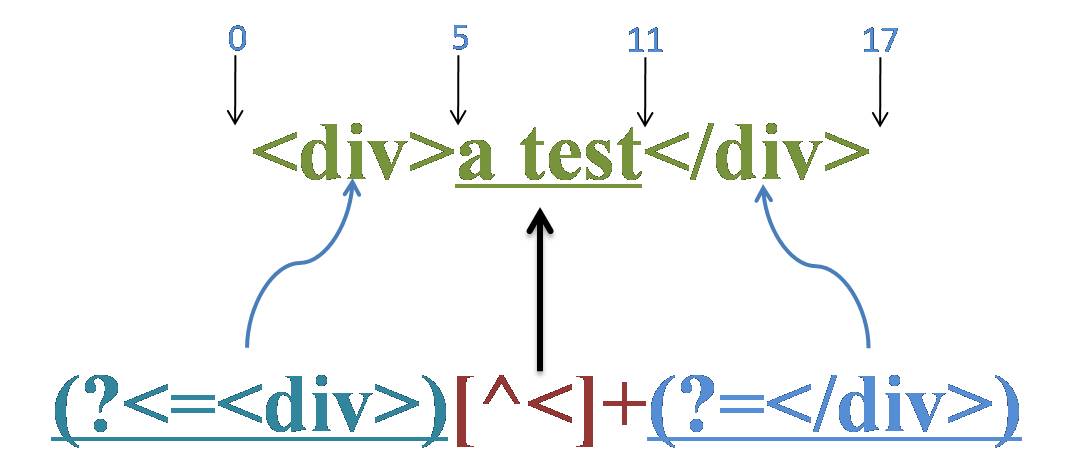
源字符串:<div>a test</div>
正则表达式:(?<=<div>)[^<]+(?=</div>)
这个正则的意义就是匹配<div>和</div>标签之间的内容,而不包括<div>和</div>标签本身。
匹配过程:
首先由“(?<=<div>)”取得控制权,从位置0开始匹配,由于位置0是起始位置,左侧没有任何内容,所以“<div>”必然匹配失败,从而环视表达式“(?<=<div>)”匹配失败,导致整个表达式在位置0处匹配失败。第一轮迭代匹配失败,正则引擎向前传动,由位置1处开始尝试第二次迭代匹配。
直到传动到位置5,“(?<=<div>)”取得控制权,向左查找5个位置,由位置0开始匹配,由“<div>”匹配“<div>”成功,从而“(?<=<div>)”匹配成功,匹配的结果为位置5,控制权交给“[^<]+”;“[^<]+”从位置5开始尝试匹配,匹配“a test”成功,控制权交给“(?=</div>)”;由“</div>”匹配“</div>”成功,从而“(?=</div>)”匹配成功,匹配结果为位置11。
此时正则表达式匹配完成,报告匹配成功。匹配结果为“a test”,开始位置为5,结束位置为11。其中“(?<=<div>)”匹配位置5,“[^<]+”匹配“a test”,“(?=</div>)”匹配位置11。
逆序否定环视的匹配过程与上述过程类似,区别只是当Expression匹配失败时,逆序否定表达式(?<!Expression)才匹配成功。
到此环视的匹配原理已基本讲解完,环视也就没有什么秘密可言了,所需要的,也只是多加练习而已。
3 环视应用
今天写累了,暂时就给出一个环视的综合应用实例吧,至于环视的应用场景和技巧,后面再整理。
需求:数字格式化成用“,”的货币格式。
正则表达式:(?<=\d)(?<!\.\d*)(?=(?:\d{3})+(?:\.\d+|$))
测试代码:
double[] data = new double[] { 0, 12, 123, 1234, 12345, 123456, 1234567, 123456789, 1234567890, 12.345, 123.456, 1234.56, 12345.6789, 123456.789, 1234567.89, 12345678.9 };
foreach (double d in data)
{
richTextBox2.Text += "源字符串:" + d.ToString().PadRight(15) + "格式化:" + Regex.Replace(d.ToString(), @"(?<=\d)(?<!\.\d*)(?=(?:\d{3})+(?:\.\d+|$))", ",") + "\n";
}
输出结果:
源字符串:0 格式化:0
源字符串:12 格式化:12
源字符串:123 格式化:123
源字符串:1234 格式化:1,234
源字符串:12345 格式化:12,345
源字符串:123456 格式化:123,456
源字符串:1234567 格式化:1,234,567
源字符串:123456789 格式化:123,456,789
源字符串:1234567890 格式化:1,234,567,890
源字符串:12.345 格式化:12.345
源字符串:123.456 格式化:123.456
源字符串:1234.56 格式化:1,234.56
源字符串:12345.6789 格式化:12,345.6789
源字符串:123456.789 格式化:123,456.789
源字符串:1234567.89 格式化:1,234,567.89
源字符串:12345678.9 格式化:12,345,678.9
实现分析:
首先根据需求可以确定是把一些特定的位置替换为“,”,接下来就是分析并找到这些位置的规律,并抽象出来以正则表达式来表示。
1、 这个位置的左侧必须为数字
2、 这个位置右侧到出现“.”或结尾为止,必须是数字,且数字的个数必须为3的倍数
3、 这个位置左侧相隔任意个数字不能出现“.”
由以上三条,就可以完全确定这些位置,只要实现以上三条,组合一下正则表达式就可以了。
根据分析,最终匹配的结果是一个位置,所以所有子表达式都要求是零宽度。
1、 是对当前所在位置左侧附加的条件,所以要用到逆序环视,因为要求必须出现,所以是肯定的,符合这一条件的子表达式即为“(?<=\d)”
2、 是对当前所在位置右侧附加的条件,所以要用到顺序环视,也是要求出现,所以是肯定的,是数字,且个数为3的倍数,即“(?=(?:\d{3})*)”,到出现“.”或结尾为止,即“(?=(?:\d{3})*(?:\.|$))”
3、 是对当前所在位置左侧附加的条件,所以要用到逆序环视,因为要求不能出现,所以是否定的,即“(?<!\.\d*)”
因为零宽度的子表达式是非互斥的,最后匹配的都是同一个位置,所以先后顺序是不影响最后的匹配结果的,可以任意组合,只是习惯上把逆序环视写在左侧,顺序环视写在右侧。
相关推荐
-
正则表达式之零宽断言实例详解【基于PHP】
本文实例讲述了正则表达式之零宽断言.分享给大家供大家参考,具体如下: 前言 之前我曾写了一篇关于正则表达式的文章(http://www.jb51.net/article/111359.htm) 在该文章中详细介绍了正则,但是关于零宽断言介绍却是很少提及到.现在将该内容补充一下.在本文中,主要解决如下问题: ① 什么是零宽断言,为什么要使用零宽断言 ② 怎样使用零宽断言 概念 零宽断言,大多地方这样定义它,用于查找在某些内容(但并不包括这些内容)之前或之后的东西,也就是说它们像 \b ^ $ \<
-

正则表达式断言、巡视(Assertions)、正向断言、反向断言介绍
断言(Assertions)在正则表达式概念里面难理解,它通常指的是在目标字符串的当前匹配位置进行的一种测试但这种测试并不占用目标字符串,也即不会移动模式在目标字符串中的当前匹配位置.详细可以看看,正则表达式匹配解析过程探讨分析(正则表达式匹配原理),里面提到"零宽度"很多元字符,只是对特殊位置进行匹配,它们可以理解为断言. 断言元字符 常见断言元字符有: \b, \B, \A, \Z, \z, ^ ,$ 它们只是表示特殊位置,各自作用如有字符串AB,带位置表示为:0A1B2 元字符
-
正则表达式零宽断言详解
正则表达式零宽断言: 零宽断言是正则表达式中的难点,所以本章节重点从匹配原理方面进行一下分析.零宽断言还有其他的名称,例如"环视"或者"预搜索"等等,不过这些都不是我们关注的重点. 一.基本概念: 零宽断言正如它的名字一样,是一种零宽度的匹配,它匹配到的内容不会保存到匹配结果中去,最终匹配结果只是一个位置而已. 作用是给指定位置添加一个限定条件,用来规定此位置之前或者之后的字符必须满足限定条件才能使正则中的字表达式匹配成功. 注意:这里所说的子表达式并非只有用小括号
-
javascript 正则表达式分组、断言详解
javascript 正则表达式分组.断言详解 提示:阅读本文需要有一定的正则表达式基础. 正则表达式中的断言,作为高级应用出现,倒不是因为它有多难,而是概念比较抽象,不容易理解而已,今天就让小菜通俗的讲解一下. 如果不用断言,以往用过的那些表达式,仅仅能获取到有规律的字符串,而不能获取无规律的字符串. 举个例子,比如html源码中有<title>xxx</title>标签,用以前的知识,我们只能确定源码中的<title>和</title>是固定不变的.因
-
正则表达式中环视的简单应用示例【基于java】
本文实例讲述了正则表达式中环视的简单应用.分享给大家供大家参考,具体如下: 由于开发工作需要对文本中内容进行过滤,删除或替换掉一些无用的或不符合要求的信息.于是发现一个问题,某一类工程性文本中,用到很多英文写法相同.但含义不同的单位,需要将其分别转为真实含义对应的汉字.比如:"粘度为17s,移动距离为350厘米,要求混凝土必须内实外光.振捣时间为30s.",很明显第一个s是粘度的单位,第二s是时间单位,现在需要将文本中所有表示时间的s替换为"秒",在朋友指引下,发现
-
正则应用之 逆序环视探索 .
1 问题引出 前几天在CSDN论坛遇到这样一个问题. 我要通过正则分别取出下面 <font color="#008000"> 与 </font> 之间的字符串 1.在 <font color="#008000"> 与 </font> 之间的字符串是没法固定的,是随机自动生成的 2.其中 <font color="#008000"> 与 </font>的数量也是没法固定的,也是
-
正则匹配原理之 逆序环视深入 .
说明:部分内容有待进一步研究和修正,因为最近工作太忙,暂时抽不出时间来,未研究过的可以跳过这一篇,想研究的不要被我的思路所左右了,有研究清楚的还请指正1 问题引出 前几天在CSDN论坛遇到这样一个问题: var str="8912341253789"; 需要将这个字符串中的重复的数字给去掉,也就是结果89123457. 首先需要说明的是,这种需求并不适合用正则来实现,至少,正则不是最好的实现方式. 这个问题本身不是本文讨论的重点,本文所要讨论的,主要是由这一问题的解决方案而引出的另一个
-
正则表达式环视概念与用法分析
本文实例讲述了正则表达式环视概念与用法.分享给大家供大家参考,具体如下: 1.环视又叫预搜索和零宽断言 2.环视又划分为 (?=exp)肯定顺序环视 (?<=exp)肯定逆序环视 (?!exp)否定顺序环视 (?<exp)否定逆序环视 3.环视只占用逻辑位置 不占用物理位置 如:匹配后缀名字为txt的文件 字符:file.txt.file2.exe 正则 \w(?=.exe) 匹配字符串file2 4.环视的用法 (?=exp)肯定顺序环视的2种用法 ① 查找电话号码是132开头的电话 字符:
-
正则基础之 环视 Lookaround
1 环视基础 环视只进行子表达式的匹配,不占有字符,匹配到的内容不保存到最终的匹配结果,是零宽度的.环视匹配的最终结果就是一个位置. 环视的作用相当于对所在位置加了一个附加条件,只有满足这个条件,环视子表达式才能匹配成功. 环视按照方向划分有顺序和逆序两种,按照是否匹配有肯定和否定两种,组合起来就有四种环视.顺序环视相当于在当前位置右侧附加一个条件,而逆序环视相当于在当前位置左侧附加一个条件. 表达式 说明 (?<=Expression) 逆序肯定环视,表示所在位置左侧能够匹配Exp
-
正则基础之 NFA引擎匹配原理
1 为什么要了解引擎匹配原理 一个个音符杂乱无章的组合在一起,弹奏出的或许就是噪音,同样的音符经过作曲家的手,就可以谱出非常动听的乐曲,一个演奏者同样可以照着乐谱奏出动听的乐曲,但他/她或许不知道该如何去改变音符的组合,使得乐曲更动听. 作为正则的使用者也一样,不懂正则引擎原理的情况下,同样可以写出满足需求的正则,但是不知道原理,却很难写出高效且没有隐患的正则.所以对于经常使用正则,或是有兴趣深入学习正则的人,还是有必要了解一下正则引擎的匹配原理的. 2 正则表达式引擎
-
正则基础之 \b 单词边界
1概述 "\b"匹配单词边界,不匹配任何字符. "\b"匹配的只是一个位置,这个位置的一侧是构成单词的字符,另一侧为非单词字符.字符串的开始或结束位置."\b"是零宽度的. 基本上所有的资料里都会说"\b"是单词边界,但是关于"单词"的范围却是少有提及.通常情况下,正则表达式中所谓的"单词",就是由"\w"所定义的字符所组成的子串. "\b"表示所
-
正则基础之 神奇的转义
1 概述这或许会是一个让人迷惑,甚至感到混乱的话题,但也正因为如此,才有了讨论的必要.在正则中,一些具有特殊意义的字符,或是字符序列,被称作元字符,如"?"表示被修饰的子表达式匹配0次或1次,"(?i)"表示忽略大小写的匹配模式等等.而当这些元字符被要求匹配其本身时,就要进行转义处理了.不同的语言或应用场景下,正则定义方式.元字符出现的位置不同,转义的方式也是林林总总,不一而同.2 .NET正则中的字符转义2.1 .NET正则中的转义符绝大多数语言中,&qu
-
正则基础之 小数点
一些细节 对于使用传统NFA引擎的大多数语言和工具,如Java..NET来说,"."的匹配范围是匹配除了换行符"\n"以外的任意一个字符. 但是对于javascript来说有些特殊,由于各浏览器的解析引擎不同,"."的匹配范围也有所不同,对于Trident内核的浏览器,如IE来说,"."同样是匹配除了换行符"\n"以外的任意一个字符,但是对于其它内核的浏览器,如Firefox.Opera.Chrome来说,
-
jQuery中的正则表达式分析 正则基础
quickExpr = /^(?:[^<]*(<[\w\W]+>)[^>]*$|#([\w\-]+)$)/ (?:-)表示是一个非捕获型 [^<]表示是以"<"起始,包含0个或多个'<'括号 (<[\w\W]+>)表示是一个捕获型,以'<>'起始,中间包含一个或多个字符 $表示字符的结尾 (#([\w\-]+))表示是一个捕获型,以'#'号和字符串.数字._以及-组成 rnotwhite = /\S/ \S表示是空白字符
-
JS正则表达式一条龙讲解(从原理和语法到JS正则)
正则啊,就像一座灯塔,当你在字符串的海洋不知所措的时候,总能给你一点思路:正则啊,就像一台验钞机,在你不知道用户提交的钞票真假的时候,总能帮你一眼识别:正则啊,就像一个手电筒,在你需要找什么玩意的时候,总能帮你get你要的东西... -- 节选自 Stinson 同学的语文排比句练习<正则> 欣赏了一段文学节选后,我们正式来梳理一遍JS中的正则,本文的首要目的是,防止我经常忘记正则的一些用法,故梳理和写下来加强熟练度和用作参考,次要目的是与君共勉,如有纰漏,请不吝赐教,良辰谢过. 本文既然取题
-
webregexp 正则测试实现代码
WebRegExp 1.0 - 客服果果 [ 无忧版 ] body{background:#2B3C53;} *{font-size:12px;} #win{ width:900px;font-size:12px; position:absolute;left:0;top:0; background:#F1F0EA; border:2px outset;color:#000; -moz-border-top-colors:#d4d0c8 white; -moz-border-left-color