正则表达式断言、巡视(Assertions)、正向断言、反向断言介绍
断言(Assertions)在正则表达式概念里面难理解,它通常指的是在目标字符串的当前匹配位置进行的一种测试但这种测试并不占用目标字符串,也即不会移动模式在目标字符串中的当前匹配位置。详细可以看看,正则表达式匹配解析过程探讨分析(正则表达式匹配原理),里面提到“零宽度“很多元字符,只是对特殊位置进行匹配,它们可以理解为断言。
断言元字符
常见断言元字符有: \b, \B, \A, \Z, \z, ^ ,$ 它们只是表示特殊位置,各自作用如有字符串AB,带位置表示为:0A1B2
| 元字符 | 意义(以上面带位置字符串说明) |
|---|---|
| ^ | 行首,字符串首 表示位置0 |
| $ | 行尾,字符串尾部,表示位置2 |
| \b | 字分界线,可以表示:0,2位置 |
| \B | 非字分界线,可以表示1位置 |
| \A | 目标的开头(独立于多行模式) 表示位置0 |
| \Z | 目标的结尾或位于结尾的换行符前(独立于多行模式) 表示位置2 |
| \z | 目标的结尾(独立于多行模式)表示位置2 |
| \G | 目标中的第一个匹配位置 |
| A,Z,z,G很少使用 | |
这些断言的测试都是一些基于当前位置的测试,断言还支持更多复杂的测试条件。更复杂的断言以子模式方式来表示,它包括先行(前向)断言(Lookahead assertions)和后行(后向)断言(Lookbehind assertions),这些断言判断只做匹配判断条件,不会记录在匹配结果中,不会匹配字符。
先行断言、正向断言、正向巡视(Lookahead assertions)
先行断言,常有表示(?=pattern),从当前匹配位置开始测试后面匹配字符串是否成立,还有(?!pattern)这样两种格式,我们来看看一个例子。源字符串:“abc100”,正则表达式是:
/[a-z]+(?=\d+)/ ,我们分析下过程如下图:
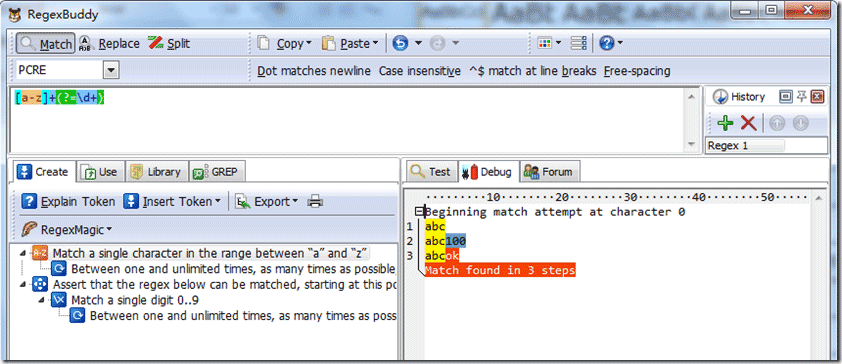
首先由正则表达式字符 [a-z]+ 取得控制权,匹配字符:”abc”,位置从”0”开始匹配,变成3。从该位置测试/d+是否成立。匹配到字符100,返回成立。因此正则表达式正向断言成功。返回匹配字符串”abc”
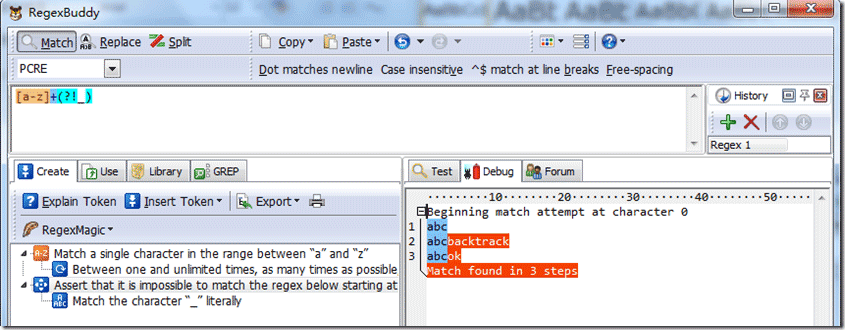
(?!pattern) 只是,正向匹配,当后面没有匹配成功,将返回真。以下是系统源字符串:abc100,测试结果如下:
后行断言、反向断言、反向巡视(Lookbehind assertions)
后行断言,常见表达式是:(?<=pattern)或者(?<!pattern)格式。正则表达式里面,不要出现不固定长度量词,可能会出现死循环。匹配出错。表示当前位置左边将出现匹配字符,则返回真,后面匹配正常。因为如果它出现在最左边,默认位置从0开始,匹配都是失败的。一般都从后面正则表达式开始匹配,再回溯,直到匹配到为止。我们看看下面例子:源字符串:“abc100+=“,正则表达式是:”(?<=\w)\w+”,匹配过程如下图:
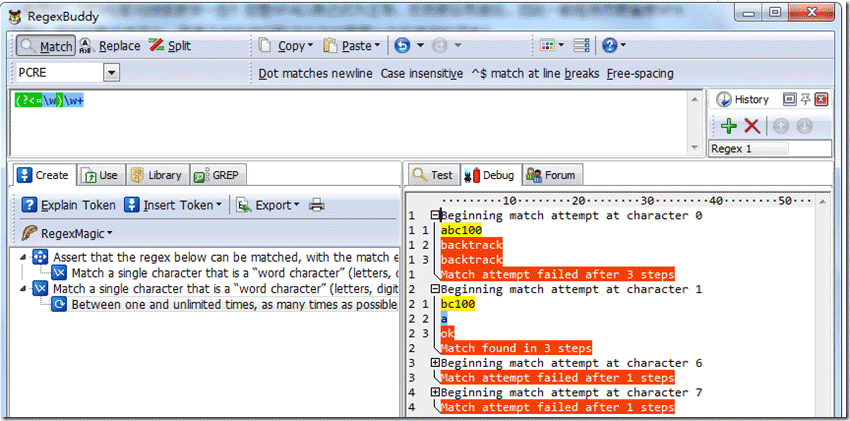
首先由正则表达式字符 /\w+/取得控制权,匹配字符:”abc100”,位置从”0”开始匹配,匹配到6个字符。从该位置0检测左变\w匹配失败。因此/\w+/从字符b开始匹配到”bc100”,测试它左侧有字符”a”,反向断言正确。因此匹配到字符串“bc100”,(?<!pattern),只是没有匹配成功返回真,其它都一样!
后记:从这篇文章,我们发现搜索特点都是从左到有,一般正向断言放到,正则表达式后,反向断言放到匹配正则表达式前。但是,这里也可以放到前或后。这里就不再举例。欢迎交流讨论!
相关推荐
-

正则匹配原理之 逆序环视深入 .
说明:部分内容有待进一步研究和修正,因为最近工作太忙,暂时抽不出时间来,未研究过的可以跳过这一篇,想研究的不要被我的思路所左右了,有研究清楚的还请指正1 问题引出 前几天在CSDN论坛遇到这样一个问题: var str="8912341253789"; 需要将这个字符串中的重复的数字给去掉,也就是结果89123457. 首先需要说明的是,这种需求并不适合用正则来实现,至少,正则不是最好的实现方式. 这个问题本身不是本文讨论的重点,本文所要讨论的,主要是由这一问题的解决方案而引出的另一个
-
正则表达式环视概念与用法分析
本文实例讲述了正则表达式环视概念与用法.分享给大家供大家参考,具体如下: 1.环视又叫预搜索和零宽断言 2.环视又划分为 (?=exp)肯定顺序环视 (?<=exp)肯定逆序环视 (?!exp)否定顺序环视 (?<exp)否定逆序环视 3.环视只占用逻辑位置 不占用物理位置 如:匹配后缀名字为txt的文件 字符:file.txt.file2.exe 正则 \w(?=.exe) 匹配字符串file2 4.环视的用法 (?=exp)肯定顺序环视的2种用法 ① 查找电话号码是132开头的电话 字符:
-
正则基础之 环视 Lookaround
1 环视基础 环视只进行子表达式的匹配,不占有字符,匹配到的内容不保存到最终的匹配结果,是零宽度的.环视匹配的最终结果就是一个位置. 环视的作用相当于对所在位置加了一个附加条件,只有满足这个条件,环视子表达式才能匹配成功. 环视按照方向划分有顺序和逆序两种,按照是否匹配有肯定和否定两种,组合起来就有四种环视.顺序环视相当于在当前位置右侧附加一个条件,而逆序环视相当于在当前位置左侧附加一个条件. 表达式 说明 (?<=Expression) 逆序肯定环视,表示所在位置左侧能够匹配Exp
-
javascript 正则表达式分组、断言详解
javascript 正则表达式分组.断言详解 提示:阅读本文需要有一定的正则表达式基础. 正则表达式中的断言,作为高级应用出现,倒不是因为它有多难,而是概念比较抽象,不容易理解而已,今天就让小菜通俗的讲解一下. 如果不用断言,以往用过的那些表达式,仅仅能获取到有规律的字符串,而不能获取无规律的字符串. 举个例子,比如html源码中有<title>xxx</title>标签,用以前的知识,我们只能确定源码中的<title>和</title>是固定不变的.因
-
正则表达式零宽断言详解
正则表达式零宽断言: 零宽断言是正则表达式中的难点,所以本章节重点从匹配原理方面进行一下分析.零宽断言还有其他的名称,例如"环视"或者"预搜索"等等,不过这些都不是我们关注的重点. 一.基本概念: 零宽断言正如它的名字一样,是一种零宽度的匹配,它匹配到的内容不会保存到匹配结果中去,最终匹配结果只是一个位置而已. 作用是给指定位置添加一个限定条件,用来规定此位置之前或者之后的字符必须满足限定条件才能使正则中的字表达式匹配成功. 注意:这里所说的子表达式并非只有用小括号
-
正则表达式之零宽断言实例详解【基于PHP】
本文实例讲述了正则表达式之零宽断言.分享给大家供大家参考,具体如下: 前言 之前我曾写了一篇关于正则表达式的文章(http://www.jb51.net/article/111359.htm) 在该文章中详细介绍了正则,但是关于零宽断言介绍却是很少提及到.现在将该内容补充一下.在本文中,主要解决如下问题: ① 什么是零宽断言,为什么要使用零宽断言 ② 怎样使用零宽断言 概念 零宽断言,大多地方这样定义它,用于查找在某些内容(但并不包括这些内容)之前或之后的东西,也就是说它们像 \b ^ $ \<
-
正则表达式中环视的简单应用示例【基于java】
本文实例讲述了正则表达式中环视的简单应用.分享给大家供大家参考,具体如下: 由于开发工作需要对文本中内容进行过滤,删除或替换掉一些无用的或不符合要求的信息.于是发现一个问题,某一类工程性文本中,用到很多英文写法相同.但含义不同的单位,需要将其分别转为真实含义对应的汉字.比如:"粘度为17s,移动距离为350厘米,要求混凝土必须内实外光.振捣时间为30s.",很明显第一个s是粘度的单位,第二s是时间单位,现在需要将文本中所有表示时间的s替换为"秒",在朋友指引下,发现
-
正则应用之 逆序环视探索 .
1 问题引出 前几天在CSDN论坛遇到这样一个问题. 我要通过正则分别取出下面 <font color="#008000"> 与 </font> 之间的字符串 1.在 <font color="#008000"> 与 </font> 之间的字符串是没法固定的,是随机自动生成的 2.其中 <font color="#008000"> 与 </font>的数量也是没法固定的,也是
-
正则表达式断言、巡视(Assertions)、正向断言、反向断言介绍
断言(Assertions)在正则表达式概念里面难理解,它通常指的是在目标字符串的当前匹配位置进行的一种测试但这种测试并不占用目标字符串,也即不会移动模式在目标字符串中的当前匹配位置.详细可以看看,正则表达式匹配解析过程探讨分析(正则表达式匹配原理),里面提到"零宽度"很多元字符,只是对特殊位置进行匹配,它们可以理解为断言. 断言元字符 常见断言元字符有: \b, \B, \A, \Z, \z, ^ ,$ 它们只是表示特殊位置,各自作用如有字符串AB,带位置表示为:0A1B2 元字符
-
分布式架构中关于正向代理反向代理面试提问
目录 引言 1.面试官:完看你简历提到使用过Nginx做代理,你是如何理解“正向代理”,“反向代理”的? 2.面试官:那服务端为什么要使用代理?有啥好处? 3.面试官:那你知道哪些负载均衡算法? 深入分析 什么是负载均衡 常用的负载均衡框架 正向代理&反向代理 正向代理 反向代理 总结 引言 面完了RPC相关的一系列问题,面试官确定我对分布式架构的理论知识和服务间通讯框架(RPC) 确实了解了. 接下来又开始问我网络相关的知识,但不是直接问HTTP三次握手,TCP,UPD这些,因为这些基础已经在
-
perl后门,正向和反向!实例代码
反向连接代码: 1. #!/usr/bin/perl 2. #usage: 3. #nc -vv -l -p PORT(default 1988) on your local system first,then 4. #Perl $0 Remote IP(default 127.0.0.1) Remote_port(default 1988) 5. #Type 'exit' to exit or press Enter to gain shell when u under the
-
PHP和正则表达式教程集合之二第1/2页
正则表达式快速入门(二) [导读]在本文里,我们主要介绍子模式(subpatterns),逆向引用(Back references)和量词(quantifiers) 在上篇文章里,我们介绍了正则表达式的模式修正符与元字符,细心的读者也许会发现,这部分介绍的非常简略,而且很少有实际的例子的讲解.这主要是因为网上现有的正则表达式资料都对这部分都有详细的介绍和众多的例子,如果觉得对前一部分缺乏了解可以参看这些资料.本文希望可以尽可能多涉及一些较高级的正则表达式特性. 在本文里,我们主要介绍子模式(su
-
正则表达式(?=)正向先行断言实战案例
最近在练习正则表达式,遇到了一道很有意思的题,题目如下 我的答案如下 (?=.*?[A-Z])(?=.*?\d)(?=.*?[a-z]).{8,} 对于这个答案的理解得先从正向先行断言的语法开始说起. 正向先行断言的语法格式如下 expression1(?=expression2) # 查找expression2前面的expression1 当然这个expression1也可以不写(也就是为空白符) 例子如下 该正则表达式的意思为:寻找abcd字符串前的123456字符串. 这里也提一个有意思的
-
Golang单元测试与断言编写流程详解
目录 编写单元测试 批量测试(test tables) 执行测试 性能测试 配置计算时间 断言(assertion) Go 在testing包中内置测试命令go test,提供了最小化但完整的测试体验.标准工具链还包括基准测试和基于代码覆盖的语句,类似于NCover(.NET)或Istanbul(Node.js).本文详细讲解go编写单元测试的过程,包括性能测试及测试工具的使用,另外还介绍第三方断言库的使用. 编写单元测试 go中单元测试与语言中其他特性一样具有独特见解,如格式化.命名规范.语法
-
Pytest断言的具体使用
目录 assert断言方法 异常断言Excepiton 检查断言装饰器 Pytest使用的断言是使用python内置的断言assert.Python assert(断言)用于判断一个表达式,在表达式条件为 false 的时候触发异常.即pytest测试结果为False的断言为断言失败即测试用例执行失败,反之为断言成功即测试用例执行成功. 断言使用场景: 为测试结果作断言 为断言不通过的结果添加说明信息 为预期异常作断言 为失败断言作自定义说明信息 assert断言方法 assert关键字后面接表
-
node.js学习之断言assert的使用示例
一. 简介 断言是编程术语,表示为一些布尔表达式,程序员相信在程序中的某个特定点该表达式值为真,可以在任何时候启用和禁用断言验证,因此可以在测试时启用断言而在部署时禁用断言.同样,程序投入运行后,最终用户在遇到问题时可以重新启用断言. 使用断言可以创建更稳定.品质更好且 不易于出错的代码.当需要在一个值为FALSE时中断当前操作的话,可以使用断言.[单元测试]必须使用断言. Node提供了 10 多个断言测试的函数,用于测试不变式,我在文章中中将这 10 多个函数进行了分组,方便理解记忆. [提