基于Python的接口自动化unittest测试框架和ddt数据驱动详解
引言
在编写接口自动化用例时,我们一般针对一个接口建立一个.py文件,一条接口测试用例封装为一个函数(方法),但是在批量执行的过程中,如果其中一条出错,后面的用例就无法执行,还有在运行大量的接口测试用例时测试数据如何管理和加载。针对测试用例加载以及执行控制,python语言提供了unittest单元测试框架,将测试用例编写在unittest框架下,使用该框架可以单个或者批量加载互不影响的用例执行及更灵活的执行控制,对于更好的进行测试数据的管理和加载,这里我们引入数据驱动的模块:ddt,测试数据和测试脚本的分离,通过ddt数据驱动来加载测试数据到测试用例脚本中,通常在接口自动化测试中会将unittest和ddt结合起来使用,从而实现测试用例脚本和测试数据的载入来完成测试的执行。下面来看看unittest框架和ddt这两个模块具体的应用。
一、unittest测试框架
unittest单元测试框架是python语言的一套标准模块,封装提供了诸多操作测试用例和用例加载、测试前置和场景恢复以及测试结果输出等一系列类和方法。
1.unittest框架中最核心四个组件概念:
(1)TestCase:测试用例类,编写测试用例脚本时需要继承该类,从而具有该类的属性和方法,一个TestCase实例就是一个测试用例,其中测试用例方法都以test开头。
(2)TestSuite:测试集,也就是测试用例的集合,用来组织用例。
(3)testrunner:用来执行测试用例,并返回测试用例的执行结果,可以用图形或者文本将测试结果形象地展现出来,HTMLTestRunner用来生成图形化的报告,TextTestRunner用来生成简单的文本测试结果。
(4)testfixure:测试夹件,主要用于测试用例的前置初始化和执行后的销毁。
2.testcase----测试用例
- 新建一个的.py测试用例文件必须是test开头,如test_login.py,主要后续用于识别测试用例文件编写测试用例的类,必须继承unittest.TestCase,做为测试类
- 测试类中用例的方法名称必须以test开头,用于识别测试用例数
- 测试类中的用例执行顺序,按照以test开头的方法后的Ascill码顺序执行(0~9,A~Z,a~z)
3.testfixure----测试夹件
- 也叫测试夹具,主要是用例前置的初始化以及执行后的销毁
- 测试夹件提供两种方法,一种是类级别的:setup()和teardown(),一种是方法级别的:setUpClass()和tearDownClass()
- 类级别的测试夹件,每一条测试用例执行之前与之后都要运行一次setup()和teardown();方法级别的测试夹件,所有测试用例执行之前到执行完成只运行一次setUpClass()和tearDownClass()
下面通过简单的代码示例看看TestCase与TestFixure的使用
(1)使用setup()和teardown(),创建test_666.py文件编辑如下代码:
import unittest
class test_unittest(unittest.TestCase):
def setUp(self):
print("测试环境初始化,开始执行setup")
def tearDown(self):
print("测试执行完成,运行teardown")
print("------------------------------")
def test_a(self):
print("开始执行test_a用例")
def test_A(self):
print("开始执行test_A用例")
def test_1(self):
print("开始执行test_1用例")
def notest_1(self):
print("不执行notest_1用例")
if __name__ == "__main__":
unittest.main()
执行后,输出如下:
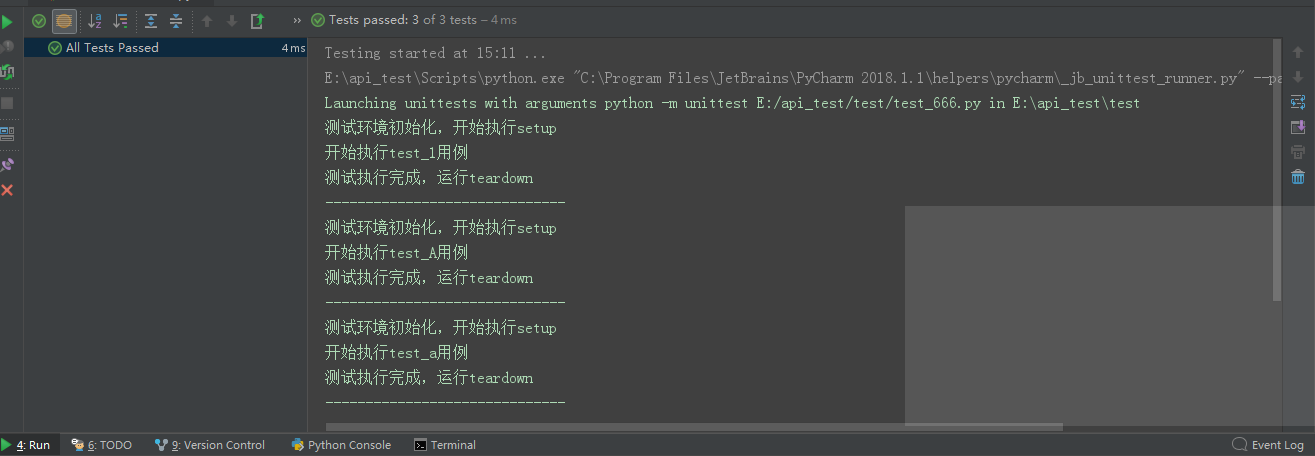
在代码中我们编写了4个def用例方法,只执行了3个def,因为最后一个def不是test开头。可以看到每执行一个def用例,setup()和teardown()都会执行一次,其中按照执行顺序:test_1最先执行,test_A其后,test_a最后执行
(2)使用setUpClass()和tearDownClass()
对于setUpClass()和tearDownClass()我们只需将上面代码,稍微修改即可
import unittest
class test_unittest(unittest.TestCase):
@classmethod
def setUpClass(cls):
print("测试环境初始化,开始执行setup")
@classmethod
def tearDownClass(cls):
print("测试执行完成,运行teardown")
print("------------------------------")
def test_a(self):
print("开始执行test_a用例")
def test_A(self):
print("开始执行test_A用例")
def test_1(self):
print("开始执行test_1用例")
if __name__ == "__main__":
unittest.main()
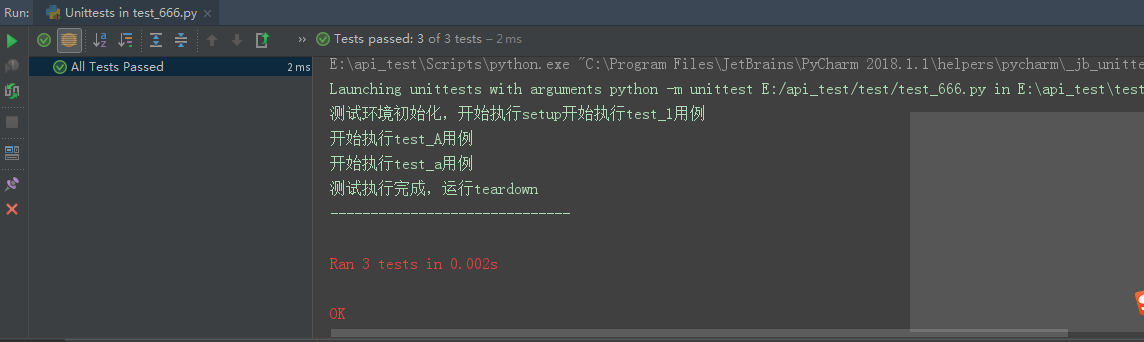
运行效果如下:
可以看到所有用例都执行完后,setUpClass()和tearDownClass()只运行了一次。因此在编写一个测试脚本时,里面写了多个测试用例,
这时我们希望的是所有用例执行完成后再销毁环境,这时使用setUpClass()和tearDownClass()就比较好了。
3.TestSuite----测试集
unittest框架下提供了unittest.TestSuite()和unittest.TestLoader()类,这两个类下封装了加载用例的方法,用于加载测试用例到测试集中
(1)unittest.TestSuite()提供单个用例加载方法
addTest():单个用例加载,当然也可以将多个用例的方法名放入列表中添加到addTest()中,加载多条测试用例
(2)unittest.TestLoader()提供批量加载或发现用例的方法
loadTestsFromTestCase(测试类名):添加一个测试类
loadTestsFromModule(模块名):添加一个模块
discover(测试用例的所在目录):指定目录去加载,会自动寻找这个目录下所有符合命名规则的测试用例
4.testrunner----测试运行
testrunner就是用来执行测试用例的,并且可以生成相应的测试报告。测试报告有两种展示形式,一种是text文本,一种是html格式。
html格式的就是HTMLTestRunner了,HTMLTestRunner是Python标准库的unittest框架的一个扩展,它可以生成一个直观清晰的HTML测试报告。使用的前提就是要下载HTMLTestRunner.py,下载完后放在python的安装目录下的scripts目录下即可。
通过代码示例看看testsuite和testrunner这两个组件的使用,上面的test_666.py用例文件我们已经写好了3条用例了,现在我们来加载这些用例
新建run_case.py文件,该文件和test_666.py文件放置在同一个包文件:test下,run_case.py文件编辑如下代码运行:
import unittest
from test.test_666 import test_unittest
# 单个用例加载
suite = unittest.TestSuite()
case1 = test_unittest('test_1')
case2 = test_unittest('test_a')
suite.addTest(case1)
suite.addTest(case2)
print(suite)
print("------------------")
# 批量用例加载
case_path = r"E:\api_test\test"
# 按文件路径加载,注意该文件为包文件即文件下有__init__.py
all_case = unittest.defaultTestLoader.discover(case_path,pattern="test_666*.py",top_level_dir=None)
all_case1 = unittest.defaultTestLoader.loadTestsFromTestCase(test_unittest) # 按类名称加载
print(all_case)
print("------------------")
print(all_case1)
输出结果如下:
E:\api_test\Scripts\python.exe E:/api_test/test_bak/run_case.py
<unittest.suite.TestSuite tests=[<test.test_666.test_unittest testMethod=test_1>, <test.test_666.test_unittest testMethod=test_a>]>
------------------
<unittest.suite.TestSuite tests=[<unittest.suite.TestSuite tests=[<unittest.suite.TestSuite tests=[<test_666.test_unittest testMethod=test_1>, <test_666.test_unittest testMethod=test_A>, <test_666.test_unittest testMethod=test_a>]>]>]>
------------------
<unittest.suite.TestSuite tests=[<test.test_666.test_unittest testMethod=test_1>, <test.test_666.test_unittest testMethod=test_A>, <test.test_666.test_unittest testMethod=test_a>]>
Process finished with exit code 0
通过unittest框架下提供的加载用例的诸多方法,我们就可以单个或者批量加载用例,后续可以将加载的用例集引入到HTMLTestRunner.py模块生成可视化的测试报告
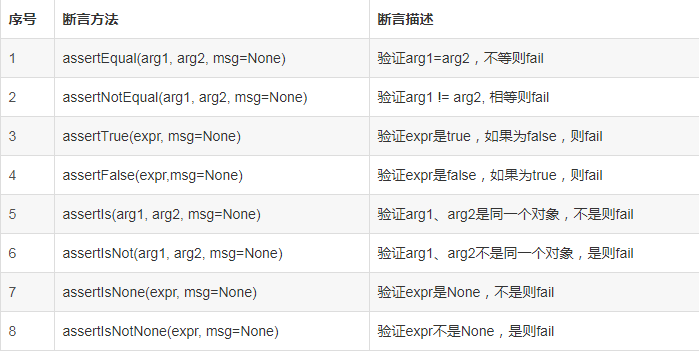
5.assert----测试断言
无论是什么样的测试用例,最后都需要有用例执行后的验证,在接口自动化测试中我们执行完接口用例也需要验证断言用例执行是否满足我们的预期。unittest提供了丰富的断言方法,常见的断言如下表:
二、ddt数据驱动
- @ddt:类的装饰器,继承的是TestCase类
- @data():@data装饰符可以把参数当成测试数据,参数可以是单个值、列表、元祖、字典这些类型,用于输入测试数据
- @unpack:分解数据标志,主要是把元祖和列表解析成多个参数
- @file_data():输入文件,如json或者yaml类型文件
(1)输入简单的参数:单个值、列表、元祖、字典
import unittest
from ddt import data,unpack,ddt
@ddt
class myddt(unittest.TestCase):
@data("123") # 单个值
def test1(self,testdata1):
print(testdata1)
print("------------------")
@data([1,2,3],[4,5,6]) # 列表
def test2(self,testdata2):
print(testdata2)
print("------------------")
"""
@data((1, 2, 3)) # 元组
def test2(self, testdata3):
print(testdata3)
print("------------------")
@data({'zhangshan':1,'wangwu':2,'lisi':3}) # 字典
def test2(self, testdata4):
print(testdata4)
print("------------------")
"""
if __name__ == '__main__':
unittest.main()
(2)使用@unpack对复杂数据结构,如元组、列表数据进行分解
代码示例:
import unittest
from ddt import data,unpack,ddt
@ddt
class myddt(unittest.TestCase):
@data([1,2],[3,4]) # 列表
@unpack
def test2(self, testdata1,testdata2):
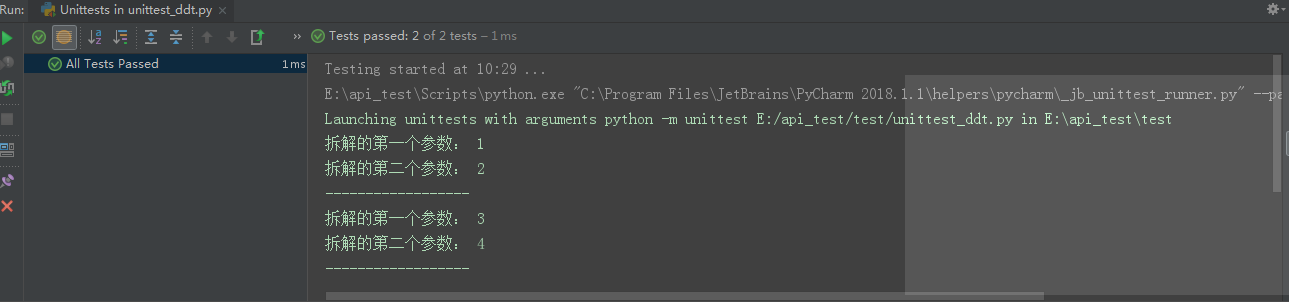
print("拆解的第一个参数:",testdata1)
print("拆解的第二个参数:", testdata2)
print("------------------")
if __name__ == '__main__':
unittest.main()
运行后输出如下:
(3)使用@file_data()输入文件格式测试数据
编辑一个data.json的文件,代码示例:
import unittest from ddt import file_data,ddt @ddt class myddt(unittest.TestCase): @file_data(r"E:\api_test\test\data.json") def test1(self, *value): print(value) if __name__ == '__main__': unittest.main()
通过ddt和unittest框架的结合就可以实现测试用例脚本编写、测试执行控制以及测试数据的批量加载,从而完成不同接口测试用例的批量执行和覆盖测试不同测试场景。
到此这篇关于基于Python的接口自动化unittest测试框架和ddt数据驱动详解的文章就介绍到这了,更多相关Python的接口自动化ddt数据驱动内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python自动化测试之DDT数据驱动的实现代码
时隔已久,再次冒烟,自动化测试工作仍在继续,自动化测试中的数据驱动技术尤为重要,不然咋去实现数据分离呢,对吧,这里就简单介绍下与传统unittest自动化测试框架匹配的DDT数据驱动技术. 话不多说,先撸一波源码,其实整体代码并不多 # -*- coding: utf-8 -*- # This file is a part of DDT (https://github.com/txels/ddt) # Copyright 2012-2015 Carles Barrobés and DDT con
-

Python3+Requests+Excel完整接口自动化测试框架的实现
框架整体使用Python3+Requests+Excel:包含对实时token的获取 1.------base -------runmethond.py runmethond:对不同的请求方式进行封装 import json import requests requests.packages.urllib3.disable_warnings() class RunMethod: def post_main(self, url, data, header=None): res = None if
-
python接口自动化测试之接口数据依赖的实现方法
在做自动化测试时,经常会对一整套业务流程进行一组接口上的测试,这时候接口之间经常会有数据依赖,那么具体要怎么实现这个依赖呢. 思路如下: 抽取之前接口的返回值存储到全局变量字典中. 初始化接口请求时,解析请求头部.请求参数等信息中的全局变量并进行替换. 发出请求. 核心代码实现: 抽取接口的返回值存储到全局变量字典中 # 抽取接口的返回值存储到全局变量字典中 if set_global_vars and isinstance(set_global_vars, list): for set_glo
-
python ddt数据驱动最简实例代码
在接口自动化测试中,往往一个接口的用例需要考虑 正确的.错误的.异常的.边界值等诸多情况,然后你需要写很多个同样代码,参数不同的用例.如果测试接口很多,不但需要写大量的代码,测试数据和代码柔合在一起,可维护性也会变的很差.数据驱动可以完美的将代码和测试数据分开,将代码进行分装,提高复用性,测试数据维护在本地文件或数据库. 使用python做接口自动化,首要任务是搭建一个自动化测试框架,其中unittest+ddt是一个不错的选择,下文主要介绍ddt在unittest下的使用. ddt包含两个方法
-
Python+unittest+DDT实现数据驱动测试
前言 数据驱动测试: 避免编写重复代码 数据与测试脚本分离 通过使用数据驱动测试,来验证多组数据测试场景 通常来说,多用于单元测试和接口测试 ddt介绍 Data-Driven Tests(DDT)即数据驱动测试,可以实现不同数据运行同一个测试用例.ddt本质其实就是装饰器,一组数据一个场景. ddt模块包含了一个类的装饰器ddt和三个个方法的装饰器: data:包含多个你想要传给测试用例的参数,可以为列表.元组.字典等: file_data:会从json或yaml中加载数据: unpack:分
-
python ddt实现数据驱动
ddt 是第三方模块,需安装, pip install ddt DDT包含类的装饰器ddt和两个方法装饰器data(直接输入测试数据) 通常情况下,data中的数据按照一个参数传递给测试用例,如果data中含有多个数据,以元组,列表,字典等数据,需要自行在脚本中对数据进行分解或者使用unpack分解数据. @data(a,b) 那么a和b各运行一次用例 @data([a,d],[c,d]) 如果没有@unpack,那么[a,b]当成一个参数传入用例运行 如果有@unpack,那么[a,b]被分解
-
基于Python的接口自动化unittest测试框架和ddt数据驱动详解
引言 在编写接口自动化用例时,我们一般针对一个接口建立一个.py文件,一条接口测试用例封装为一个函数(方法),但是在批量执行的过程中,如果其中一条出错,后面的用例就无法执行,还有在运行大量的接口测试用例时测试数据如何管理和加载.针对测试用例加载以及执行控制,python语言提供了unittest单元测试框架,将测试用例编写在unittest框架下,使用该框架可以单个或者批量加载互不影响的用例执行及更灵活的执行控制,对于更好的进行测试数据的管理和加载,这里我们引入数据驱动的模块:ddt,测试数据和
-
基于Python的接口自动化读写excel文件的方法
引言 使用python进行接口测试时常常需要接口用例测试数据.断言接口功能.验证接口响应状态等,如果大量的接口测试用例脚本都将接口测试用例数据写在脚本文件中,这样写出来整个接口测试用例脚本代码将看起来很冗余和难以清晰的阅读以及维护,试想如果所有的接口测试数据都写在代码中,接口参数或者测试数据需要修改,那不得每个代码文件都要一一改动?.因此,这种不高效的模式不是我们想要的.所以,在自动化测试中就有个重要的思想:测试数据和测试脚本分离,也就是测试脚本只有一份,其中需要输入数据的地方会用变量来代替,然
-
基于Python中单例模式的几种实现方式及优化详解
单例模式 单例模式(Singleton Pattern)是一种常用的软件设计模式,该模式的主要目的是确保某一个类只有一个实例存在.当你希望在整个系统中,某个类只能出现一个实例时,单例对象就能派上用场. 比如,某个服务器程序的配置信息存放在一个文件中,客户端通过一个 AppConfig 的类来读取配置文件的信息.如果在程序运行期间,有很多地方都需要使用配置文件的内容,也就是说,很多地方都需要创建 AppConfig 对象的实例,这就导致系统中存在多个 AppConfig 的实例对象,而这样会严重浪
-
Pytest测试框架基本使用方法详解
pytest介绍 pytest是一个非常成熟的全功能的Python测试框架,主要特点有以下几点: 1.简单灵活,容易上手,文档丰富: 2.支持参数化,可以细粒度地控制要测试的测试用例: 3.能够支持简单的单元测试和复杂的功能测试,还可以用来做selenium/appnium等自动化测试.接口自动化测试(pytest+requests); 4.pytest具有很多第三方插件,并且可以自定义扩展 如pytest-selenium(集成selenium). pytest-html(完美html测试报告
-
google c++程序测试框架googletest使用教程详解
目录 什么是googletest? googletest简介 谁在使用 GoogleTest? 相关开源项目 googletest的下载与编译 cmake gui编译 在vs2019中使用googletest GTest的一些基本概念 GTest的断言 事件机制 参数化 什么是googletest? googletest简介 GoogleTest 是 Google 的 C++ 测试和模拟框架,可以帮助程序员测试C++程序的结果预期,GoogleTest 的代码用cmake管理,可以使用cmak
-
基于python的selenium两种文件上传操作实现详解
方法一.input标签上传 如果是input标签,可以直接输入路径,那么可以直接调用send_keys输入路径,这里不做过多赘述,前文有相关操作方法. 方法二.非input标签上传 这种上传方式需要借助第三方工具,主要有以下三种情况: 1.AutoIt 去调用它生成的au3或者exe格式的文件 2.SendKeys第三方库(目前只支持到2.7版本) 网址:https://pypi.python.org/pypi/SendKeys/ 3.Python的pywin32库,通过识别对话框句柄来进行操作
-
python+requests接口自动化框架的实现
为什么要做接口自动化框架 1.业务与配置的分离 2.数据与程序的分离:数据的变更不影响程序 3.有日志功能,实现无人值守 4.自动发送测试报告 5.不懂编程的测试人员也可以进行测试 正常接口测试的流程是什么? 确定接口测试使用的工具----->配置需要的接口参数----->进行测试----->检查测试结果----->生成测试报告 测试的工具:python+requests 接口测试用例:excel 一.接口框架如下: 1.action包:用来存放关键字函数 2.config包:用来
-
python+pytest接口自动化之token关联登录的实现
目录 一. 什么是token 二. token场景处理 这里介绍如下两种处理思路. 1. 思路一 2. 思路二 三. 总结 在PC端登录公司的后台管理系统或在手机上登录某个APP时,经常会发现登录成功后,返回参数中会包含token,它的值为一段较长的字符串,而后续去请求的请求头中都需要带上这个token作为参数,否则就提示需要先登录. 这其实就是状态或会话保持的第三种方式token. 一. 什么是token token 由服务端产生,是客户端用于请求的身份令牌.第一次登录成功时,服务端会生成一个
-
python+pytest接口自动化参数关联
目录 前言 一.什么是参数关联? 二.有哪些场景? 三.参数关联场景 四.脚本编写 1.在用例中按顺序调用 2. 使用Fixture函数 五. 总结 前言 今天呢,笔者想和大家来聊聊python+pytest接口自动化测试的参数关联,笔者这边就不多说废话了,咱们直接进入正题. 一.什么是参数关联? 参数关联,也叫接口关联,即接口之间存在参数的联系或依赖.在完成某一功能业务时,有时需要按顺序请求多个接口,此时在某些接口之间可能会存在关联关系.比如:B接口的某个或某些请求参数是通过调用A接口获取的,
-
基于Python实现报表自动化并发送到邮箱
目录 项目背景 一.报表自动化目的 二.报表自动化范围 三.实现步骤 第一步:读取数据源文件 第二步:DataFrame计算 第三步:自动发送邮件 项目背景 作为数据分析师,我们需要经常制作统计分析图表.但是报表太多的时候往往需要花费我们大部分时间去制作报表.这耽误了我们利用大量的时间去进行数据分析.但是作为数据分析师我们应该尽可能去挖掘表格图表数据背后隐藏关联信息,而不是简单的统计表格制作图表再发送报表.既然报表的工作不可免除,那我们应该如何利用我们所学的技术去更好的处理工作呢?这就需要我们制