一文了解Hive是什么
目录
- 一、Hive介绍
- Hive的优缺点
- Hive架构
- Hive用户接口
- Hive元数据的三种存储模式
- Hive数据存储
- 架构原理
- Hive文件格式
- Hive本质
- Hive工作原理
- Hive数据类型
一、Hive介绍
hive: 由 Facebook 开源用于解决海量结构化日志的数据统计工具。
Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类 SQL 查询功能。
Hive的优缺点
优点:
- 类似于SQL语句,简单学习易上手
- 避免了去写 MapReduce,减少开发人员的学习成本
- Hive 的执行延迟比较高,因此 Hive 常用于数据分析,对实时性要求不高的场合
- Hive 优势在于处理大数据,对于处理小数据没有优势,因为 Hive 的执行延迟比较高
- Hive 支持用户自定义函数,用户可以根据自己的需求来实现自己的函数
缺点:
- Hive 的 HQL 表达能力有限
- Hive 的效率比较低
- Hive本质是一个MR
Hive架构
Hive用户接口
- Hive CLI(Hive Command Line) Hive的命令行
- HWI(Hive Web Interface) HiveWeb接口
- Hive提供了Thrift服务,也就是Hiveserver。
Hive元数据的三种存储模式
- 单用户模式 : Hive安装时,默认使用的是Derby数据库存储元数据,这样不能并发调用Hive。
- 多用户模式 : MySQL服务器存储元数据
- 远程服务器模式 : 启动MetaStoreServer
Hive数据存储
Hive数据可区分为表数据和元数据,表数据我们都知道是表中的数据,而元数据是用来存储表的名字、列、表分区以及属性
Hive是基于Hadoop分布式文件存储的,它的数据存储在HDFS中。现在我们介绍Hive中常见的数据导入方式
- 本地文件系统中导入数据到Hive
- 从HDFS上导入数据到Hive表
- 从其他表中查询出相应的数据并导入Hive表中
- 在创建表的时候通过从其他表中查询出相应的记录并插入到所创建的表中
#1.演示从本地装载数据到hive #1.1创建表 create table student(id string, name string) row format delimited fields terminated by '\t'; #1.2加载本地的文件到hive load data local inpath '/root/student.txt' into table default.student; #default.test 数据库.表名 也可直接表名 #2.演示加载HDFS文件到hive中 #2.1 将文件上传到HDFS根目录 dfs -put /root/student.txt /; #2.2加载HDFS上的数据 load data inpath '/student.txt' into table test.student; #3.加载数据覆盖表中原有的数据 #3.1上传文件到HDFS中 dfs -put /root/student.txt /; #将文件装载到表下 文件就相当于Windows中的剪切操作 #3.2加载数据覆盖表中原有数据 load data inpath '/student.txt' overwrite into table test.student; #4.查询表 select * from student;
#通过查询语句向表中插入数据(insert) #1.1创建表 create table student_par(id int,name String) row format delimited fields terminated by '\t'; #1.2通过insert插入数据 insert into table student_par values(1,'zhangsan'),(2,'lisi');
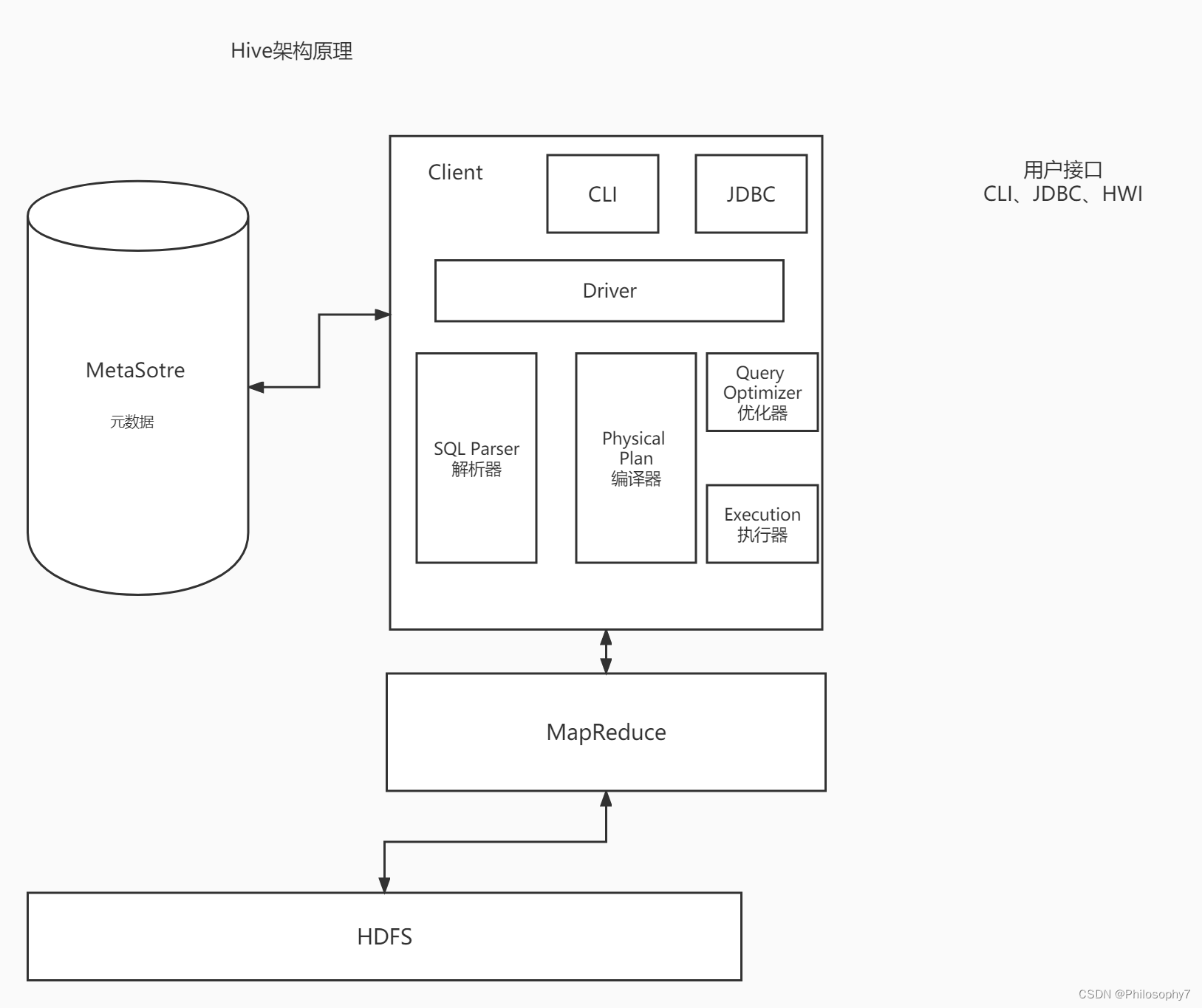
架构原理
用户接口
CLI(command-line interface)、JDBC/ODBC(jdbc 访问 hive)、WEBUI(浏览器访问 hive)
元数据
元数据包括:表名、表所属的数据库(默认是 default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等
Hadoop
使用 HDFS 进行存储,使用 MapReduce 进行计算。
驱动器:Driver
(1)解析器(SQL Parser):将 SQL 字符串转换成抽象语法树 AST,这一步一般都用第三方工具库完成,比如 antlr;对 AST 进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。
(2)编译器(Physical Plan):将 AST 编译生成逻辑执行计划。
(3)优化器(Query Optimizer):对逻辑执行计划进行优化。
(4)执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于 Hive 来说,就是 MR/Spark。
Hive文件格式
- TextFile
这是默认的文件格式。数据不会压缩处理,磁盘开销大,数据解析开销也大。
SequenceFile
这是HadooAPI提供的一种二进制文件支持,以二进制的形式序列化到文件中。
- RCFile
这种格式是行列存储结构的存储方式。
- ORC
Optimized Row Columnar ORC文件格式是一种Hadoop生态圈中的列式存储格式。
ORC的优势:
- 列示存储,有多种文件压缩方式
- 文件是可分割的。
- 提供了多种索引
- 可以支持复杂的数据结构 比如Map
ORC文件格式是以二进制方式存储的,所以是不可直接读取的。
Hive本质
将HQL转换成MapReduce程序。
- Hive处理的数据存储在HDFS上
- Hive分析数据底层的实现是MapReduce
- 执行程序运行在Yarn上
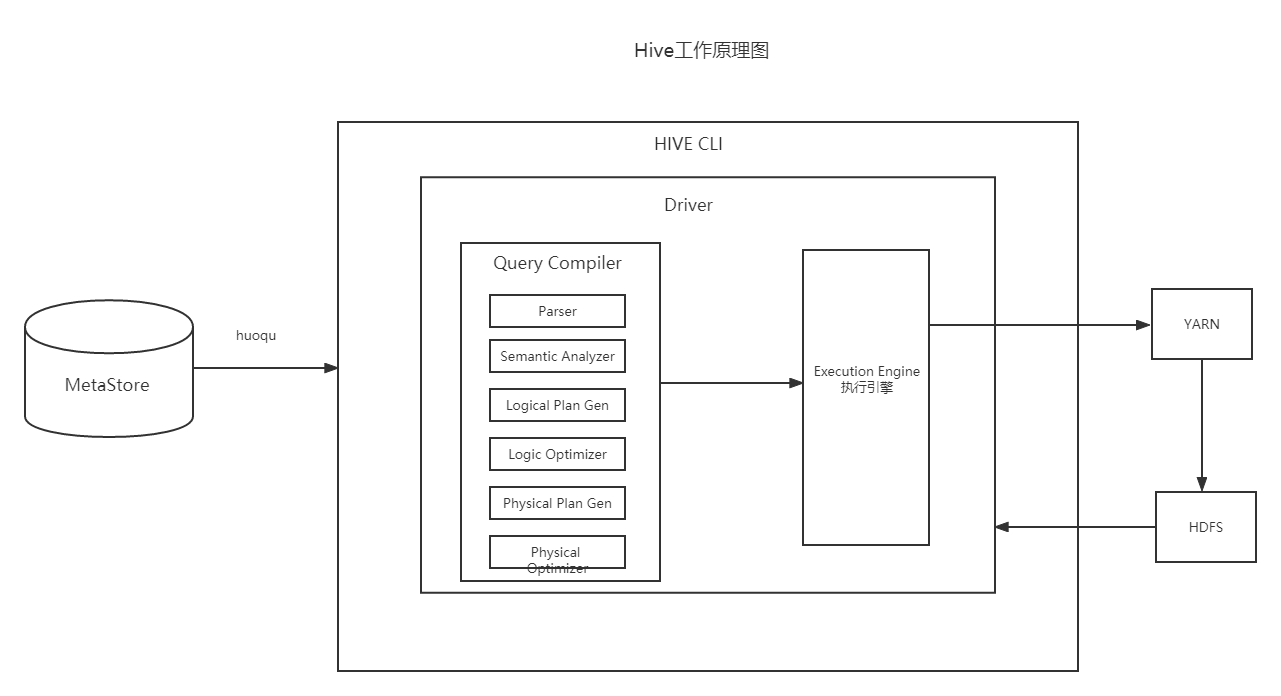
Hive工作原理
简单来说Hive就是一个查询引擎。当Hive接受到一条SQL语句会执行如下操作:
- 词法分析和语法分析。使用antlr将SQL语句解析成抽象语法树
- 语义分析。从MetaStore中获取元数据信息,解释SQL语句中的表名、列名、数据类型
- 逻辑计划生成。生成逻辑计划得到算子树
- 逻辑计划优化。对算子树进行优化
- 物理计划生成。将逻辑计划生成出的MapReduce任务组成的DAG的物理计划
- 物理计划执行。将DAG发送到Hadoop集群进行执行
- 将查询结果返回。
Hive展现的MapReduce任务设计到组件有:
- 元存储 : 该组件存储了Hive中表的信息,其中包括了表、表的分区、模式、列及其类型、表映射关系等
- 驱动 : 控制HiveQL生命周期的组件
- 查询编辑器
- 执行引擎
- Hive服务器
- 客户端组件 提供命令行接口Hive CLI、Web UI、JDBC驱动等
Hive数据类型
Hive支持两种数据类型,一种原子数据类型、还有一种叫复杂数据类型。
| 基本数据类型 | ||
|---|---|---|
| 类型 | 描述 | 示例 |
| TINYINT | 1字节有符合整数 | 1 |
| SMALLINT | 2字节有符号整数 | 1 |
| INT | 4字节有符号整数 | 1 |
| BIGINT | 8字节有符号整数 | 1 |
| FLOAT | 4字节单精度浮点数 | 1.0 |
| DOUBLE | 8字节双精度浮点数 | 1.0 |
| BOOLEAN | true/false | true |
| STRING | 字符串 | “hive”,‘hive’ |
Hive类型中的String数据类型类似于MySQL中的VARCHAR。该类型是一个可变的字符串。
Hive支持数据类型转换,Hive是用Java编写的,所以数据类型转换规则遵循Java :
隐式转换 --> 小转大
强制转换 --> 大传小
| 类型 | 描述 | 示例 |
|---|---|---|
| ARRAY | 有序的字段。字符类型必须相同 | ARRAY(1,2) |
| MAP | 无序的键值对。建的类型必须是原子的,值可以是任何类型。 | Map(‘a’,1,‘b’,2) |
| STRUCT | 一组命名的字段。字段类型可以不同 | STRUCT(‘a’,1,1,0) |
到此这篇关于一文了解Hive是什么的文章就介绍到这了,更多相关Hive是什么内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

详解hbase与hive数据同步
hive的表数据是可以同步到impala中去的.一般impala是提供实时查询操作的,像比较耗时的入库操作我们可以使用hive,然后再将数据同步到impala中.另外,我们也可以在hive中创建一张表同时映射hbase中的表,实现数据同步. 下面,笔者依次进行介绍. 一.impala与hive的数据同步 首先,我们在hive命令行执行showdatabases;可以看到有以下几个数据库: 然后,我们在impala同样执行showdatabases;可以看到: 目前的数据库都是一样的. 下面,我们
-
解决hive中导入text文件遇到的坑
今天帮一同学导入一个excel数据,我把excel保存为txt格式,然后建表导入,失败!分隔符格式不匹配,无法导入!!!!怎么看两边都是\t,怎么不匹配呢? 做为程序员,最不怕的就是失败,因为我们有一颗勇敢的心!再来!又特么失败... 想了好久,看看了看我的表格式,我犯了一个好低级的错误: hive表的存储格式设置为了orcfile!!! 众所周知:orcfile为压缩格式,可以节约大量存储空间,但orc还有个特点就是不能直接load数据!要想load数据,我们要建一个存储格式为textfile
-
hive中的几种join到底有什么区别
目录 数据: 1. left join 2. join 3. full join 4. Join…on 1=1 5. union 6. union all union和union all的区别 总结 hive中,几种join的区别 数据: tom,1jey,2lilly,7lilly,8 tom,1lilly,3may,4bob,5 以上两个为数据,没有什么意义,全是为了检测join的使用 看一下两张表,其实可以看出来,在name一行有重复的,也有不重复的,在id一行1表完全包含2表 1. le
-
hive函数简介
首先我们要知道hive到底是做什么的.下面这几段文字很好的描述了hive的特性: 1.hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行.其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析. 2.Hive是建立在 Hadoop 上的数据仓库基础构架.它提供了一系列的工具,可以用来进行数据提
-
一文了解Hive是什么
目录 一.Hive介绍 Hive的优缺点 Hive架构 Hive用户接口 Hive元数据的三种存储模式 Hive数据存储 架构原理 Hive文件格式 Hive本质 Hive工作原理 Hive数据类型 一.Hive介绍 hive: 由 Facebook 开源用于解决海量结构化日志的数据统计工具. Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类 SQL 查询功能. Hive的优缺点 优点: 类似于SQL语句,简单学习易上手 避免了去写 MapRedu
-
一文读懂数据库管理工具 Navicat 和 DBeaver
Navicat "Navicat" 是一套可创建多个连接的数据库管理工具,用以方便管理 MySQL.Oracle.PostgreSQL.SQLite.SQL Server.MariaDB 和/或 MongoDB 等不同类型的数据库,并支持管理某些云数据库,例如阿里云.腾讯云.Navicat 和 Navicat Premium 都可以用来连接和管理数据库.Navicat Premium 支持更多的数据库,并且功能更多,但是这两个都是收费软件. Navicat Premium 15:ht
-
一文学会Hadoop与Spark等大数据框架知识
目录 一个实际的需求场景:日志分析 Hadoop Hadoop的生态坏境 Spark Spark整体架构 Spark核心概念 Spark的核心组件 海量数据的存储问题很早就已经出现了,一些行业或者部门因为历史的积累,数据量也达到了一定的级别.很早以前,当一台电脑无法存储这么庞大的数据时,采用的解决方案是使用NFS(网络文件系统)将数据分开存储.但是这种方法无法充分利用多台计算机同时进行分析数据. 一个实际的需求场景:日志分析 日志分析是对日志中的每一个用户的流量进行汇总求和.对于一个日志文件,如
-
一文解答为什么MySQL的count()方法这么慢
目录 前言 count()的原理 各种count()方法的原理 允许粗略估计行数的场景 必须精确估计行数的场景 总结 前言 mysql用count方法查全表数据,在不同的存储引擎里实现不同,myisam有专门字段记录全表的行数,直接读这个字段就好了.而innodb则需要一行行去算. 比如说,你有一张短信表(sms),里面放了各种需要发送的短信信息. sms建表sql: sms表; 需要注意的是state字段,为0的时候说明这时候短信还未发送. 此时还会有一个异步线程不断的捞起未发送(state=
-
详解hive常见表结构
目录 hive简介 1.外部表 2.内部表 3.分区表 1.静态分区 2.动态分区 4.分桶表 1.抽样 2.map-side join 5.表的文件存储格式 1.TEXTFILE 2.SEQUENCEFILE 3.RCFILE 4.ORC 5.Parquet 6.总结 5.表的行存储格式(row format) 6.表属性 1.压缩 1.为什么要压缩 2.压缩常见的格式 3.压缩性能比较 hive简介 hive是基于Hadoop的一个数据仓库工具,用来进行数据提取.转化.加载,这是一种可以存储
-
remote script文档(转载自微软)(九)
文档: 等待方法 终止当前正执行的客户脚本,直到指定调用对象的异步 remote scripting 调用完成. 语法 co.wait() 参数 co 执行 remote scripting 调用而生成的调用对象. 说明 调用该方法将把一个异步 remote scripting 调用转换为同步调用.如果 remote scripting 调用已完成,那么该方法将立即返回.如果您在客户脚本中遇到这种情况──需要来自 remote scripting 调用的结果,那么这种调用是有用的. 示例 下面
-
remote script文档(转载自微软)(八)
文档: 调用对象属性和方法 当您调用一个服务器方法时,该方法不返回单个值.而是创建一个调用对象,该对象包含被调用过程的返回值和状态信息.下表列出了调用对象的属性. 属性 描述 id 调用的唯一标识号,它是首次调用时产生的. return_value 方法的返回值──如果有的话. data 产生 remote scripting 调用时,服务器返回的粗数据,是以 XML 标记封装的.有关详细信息,请参阅检查错误. status 指示方法调用当前状态的值.可能值包括: -1 失败 0 完成
-
remote script文档(转载自微软)(七)
文档: 检查错误 当您在服务器脚本中用 remote scripting 调用方法时,可能会遇到多种错误,包括语法错误和运行时间错误,以及调用 remote scripting 方法时的错误.remote scripting 调用机制向您提供了获知调用过程中所出现错误信息的途径. 错误处理程序根据您是进行同步或者异步调用稍微有些不一样.如果您在进行同步调用时导致错误,那么 remote scripting 机制将在浏览器中显示一条错误消息.错误文字来自于调用对象的 message 属性.有关详细
-
remote script文档(转载自微软)(六)
文档: 调用 Remote Scripting 方法异步 Remote scripting 向您提供了异步调用服务器方法的选择 ──当执行服务器方法时,用户的客户脚本继续运行.异步调用 remote scripting 方法使得您可以避免应用程序用户接口速度的减慢,因为您可以在执行服务器脚本的同时继续工作. 注意 如果您的应用程序需要,那么也可以同步调用服务器方法.有关详细信息,请参阅同步调用 Remote Scripting 方法. 异步调用某个 remote script 类似于同步调用.不
-
remote script文档(转载自微软)(五)
文档: 调用 Remote Scripting 方法同步 在对某个客户页和某个服务器页上的 remote scripting 进行配置后,您就可以从自己的客户脚本调用该服务器页的方法了.缺省的情况是,当用户调用某个服务器方法时,它被同步执行──您的客户脚本直到服务器方法执行完毕并返回结果后才能停止运行.一般说来,当您在自己的客户脚本中需要服务器方法结果时,则需同步调用服务器方法. 注意 您也可以异步调用服务器方法.有关详细信息,请参阅异步调用 Remote Scripting 方法. 当您调用某