python提取具有某种特定字符串的行数据方法
今天又帮女朋友处理了一下,她的实验数据,因为python是一年前经常用,最近找工作,用的是c,c++,python的有些东西忘记了,然后就一直催我,说我弄的慢,弄的慢,你自己弄啊,烦不烦啊,逼逼叨叨的,最后还不是我给弄好的?呵呵
好的,数据是这样的,我截个图
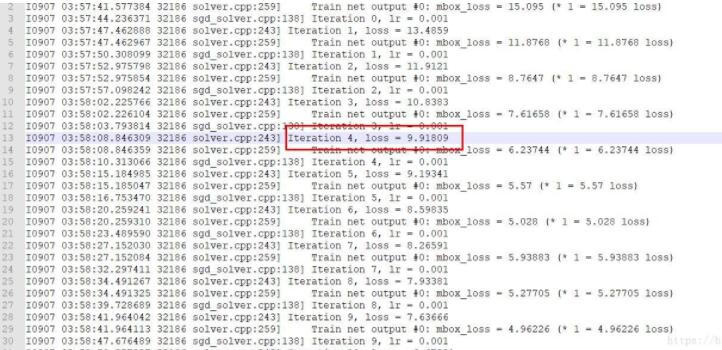
我用红括号括起来的,就是我所要提取的数据
其中lossstotal.txt是我要提取的原始数据,考虑两种方法去提取,前期以为所要提取行的数据是有一定规律的,后来发现,并不是,所以,我考虑用正则来提取,经过思考以后,完成了数据的提取,如下午所示,数据变的非常好看
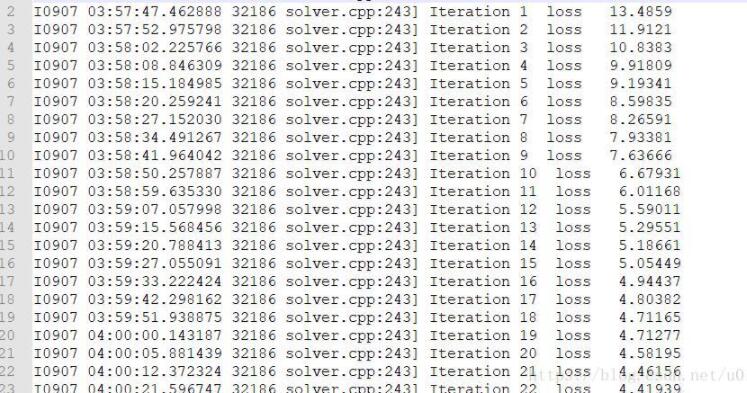
代码如下:
#coding:utf-8
#__author__ ='dell'
import re
f1=file('losstotal.txt','r')
data1=f1.readlines()
# print data1
f1.close()
results = []
f2 = open('loss2.txt', 'w')
# # 按照特定行提取,发现后面的行并无规律
# i = 0
# for line in data1:
# i+=1
# # print line
# if((i-1)%3==0):
# f2.write(line)
# print line
# 利用正则表达式
for line in data1:
data2=line.split()
# print data2
for i in data2:
n = re.findall(r"Iteration", i)
# m=re.findall(r"loss", i)
if n:
# print line
f2.writelines(line)
f2.close()
f3=file('loss2.txt','r')
data3=f3.readlines()
# print data1
f3.close()
f4 = open('loss3.txt', 'w')
for line in data3:
data4=line.split()
# print data2
for i in data4:
n = re.findall(r"loss", i)
# m=re.findall(r"loss", i)
if n:
print line
f4.writelines(line)
f4.close()
# 去掉逗号
f5=open('loss3.txt','r')
data5=f5.read()
f5=data5.replace(',',' ')
f6=file('lossfinal.txt','w')
f6.write(f5)
f6.close()
# # 去掉等号=
f7=open('lossfinal.txt','r')
data7=f7.read()
f7=data7.replace('=',' ')
f8=file('lossfinal.txt','w')
f8.write(f7)
f8.close()
# data3=lin.split()
# for j in data3:
# m=re.findall(r"loss",i)
# if m:
# print lin
# # m=re.findall(r"sgd_solver.cpp",i)
# n=re.findall(r"Iteration",i)
我在同样的目录下,还建立了
这几个txt文件,要不然,代码跑不通的哟。
解释:我连续用了两个正则,各自把含有特定字符串的行进行提取,两个写一起,发现还是不太会,所以分开写了,但是结果还是完成的不错!
以上这篇python提取具有某种特定字符串的行数据方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Python拼接字符串的7种方法总结
前言 忘了在哪看到一位编程大牛调侃,他说程序员每天就做两件事,其中之一就是处理字符串.相信不少同学会有同感. 在Python中,我们经常会遇到字符串的拼接问题,几乎任何一种编程语言,都把字符串列为最基础和不可或缺的数据类型.而拼接字符串是必备的一种技能.今天,我跟大家一起来学习Python拼接字符串的七种方式. 下面话不多说了,来一起看看详细的介绍吧 1.来自C语言的%方式 print('%s %s' % ('Hello', 'world')) >>> Hello world %号格式化
-
python 将字符串完成特定的向右移动方法
# 将字符串中的元素完成特定的向右移动,参数:字符串.移动长度 如:abcdef,移动2,结果:efabcd #原始方法,基本思想:末尾元素移动到开头,其他的元素依次向后移动.代码如下: def move(lt, n): lt = list(lt) #将字符串转换为列表 for i in range(n % len(lt)):#确定移动几次,比如说移动从长度和列表的长度相同时,就没必要移动 t = lt[len(lt) - 1] #取出末尾元素 for j in reversed(range(l
-
Python中常用的8种字符串操作方法
拼接字符串 使用"+"可以对多个字符串进行拼接 语法格式: str1 + str2 >>> str1 = "aaa" >>> str2 = "bbb" >>> print(str1 + str2) aaabbb 需要注意的是字符串不允许直接与其他类型进行拼接,例如 >>> num = 100 >>> str1 = "hello" >
-
Python 实现字符串中指定位置插入一个字符
如下所示: str_1='wo shi yi zhi da da niu/n'str_list=list(str_1) nPos=str_list.index('/') str_list.insert(nPos,',') str_2="".join(str_list) print(str_2) 从文件中提取行,在行最末尾插入一个逗号. 以上这篇Python 实现字符串中指定位置插入一个字符就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们. 您可能感兴趣的文章
-
python字符串循环左移
本文实例为大家分享了python字符串循环左移的具体代码,供大家参考,具体内容如下 字符串循环左移 给定一个字符串S[0-N-1],要求把S的前k个字符移动到S的尾部,如把字符串"abcdef"前面的2个字符'a'.'b'移动到字符串的尾部,得到新字符串"cdefab":即字符串循环左移k位. 循环左移k位等价于循环右移n-k位. 算法要求: 时间复杂度为 O(n),空间复杂度为 O(1). 分析思路: 暴力移位: 每次循环左移1位,调用k次即可 时间复杂度O(kN
-
python提取具有某种特定字符串的行数据方法
今天又帮女朋友处理了一下,她的实验数据,因为python是一年前经常用,最近找工作,用的是c,c++,python的有些东西忘记了,然后就一直催我,说我弄的慢,弄的慢,你自己弄啊,烦不烦啊,逼逼叨叨的,最后还不是我给弄好的?呵呵 好的,数据是这样的,我截个图 我用红括号括起来的,就是我所要提取的数据 其中lossstotal.txt是我要提取的原始数据,考虑两种方法去提取,前期以为所要提取行的数据是有一定规律的,后来发现,并不是,所以,我考虑用正则来提取,经过思考以后,完成了数据的提取,如下午所
-
python提取包含关键字的整行数据方法
问题描述: 如下图所示,有一个近2000行的数据表,需要把其中含有关键字'颈廓清术,中央组(VI组)'的数据所在行都都给抽取出来,且提取后的表格不能改变原先的顺序. 问题分析: 一开始想用excel的筛选功能,但是发现只提供单列筛选,由于关键词在P,S,V,Y,AB列都有,故需要筛选5次.但是筛选完后再整合再一起的表格顺序就乱了,而原先的表格排序规律不可知,无法通过简单的排序实现.于是决定用Python写个代码来解决这个问题~ python生成的表格是这个样子滴^_^那些空白的行就是不符合要求的
-

python删除列表中特定元素的几种方法
目录 前言 思路 方法1 方法2:使用while循环 方法3:for循环倒序删除空字符串 方法4:拷贝原列表 前言 题目如下: 给定一个仅包含大小写字母和空格 ’ ’ 的字符串 s,返回其最后一个单词的长度.如果字符串从左向右滚动显示,那么最后一个单词就是最后出现的单词. 如果不存在最后一个单词,请返回 0 . 说明:一个单词是指仅由字母组成.不包含任何空格字符的 最大子字符串. 示例: 输入: "Hello World"输出: 5 思路 题目要求给一个字符串s,s仅包含字母和空格字符
-
Python提取Linux内核源代码的目录结构实现方法
今天用Python提取了Linux内核源代码的目录树结构,没有怎么写过脚本程序,我居然折腾了2个小时,先是如何枚举出给定目录下的所有文件和文件夹,os.walk可以实现列举,但是os.walk是只给出目录名和文件名,而没有绝对路径.使用os.path.listdir可以达到这个目的,然后是创建目录,由于当目录存在是会提示创建失败的错误,所以我先想删除所有目录,然后再创建,但是发现还是有问题,最好还是使用判断如果不存在才创建目录,存在时就不创建,贴下代码: # @This script can b
-
python 读txt文件,按‘,’分割每行数据操作
按行读取TXT文件 fname = './新建文件夹/yob2010.txt' //文件夹路径 with open(fname,'r+',encoding='utf-8') as f: for line in f.readlines(): //按行读取每行 print(line[:-1].split(',')) //切片去掉换行符,再以','分割字符串 ,得到一个列表 s = [i[:-1].split(',') for i in f.readlines()] //列表生成器,将文件每行数据按上
-
python列表元素拼接成字符串的4种方法
目录 前言 一.使用join()方法连接列列表 二.利用for循环连接列表 三.对列表进行切片然后连接 四.使用zip压缩多个列表为一个列表 前言 我们在分析列表数据时,常常需要对列表数据进行输出或多列表关联拼接.直接使用列表,列表中的各元素以逗号分隔,每个元素包含引号.如何连接列表中的元素为一个字符串呢?文章主要介绍python 连接列表元素的4种方法,帮助大家更好的理解和学习使用python,感兴趣的朋友可以了解下. 一.使用join()方法连接列列表 使用join()方法可将列表中的元素以
-
python实现忽略大小写对字符串列表排序的方法
本文实例讲述了python实现忽略大小写对字符串列表排序的方法,是非常实用的技巧.分享给大家供大家参考.具体分析如下: 先来看看如下代码: string = ''' the stirng Has many line In THE fIle jb51 net ''' list_of_string = string.split() print list_of_string #将字符串分离开,放入列表中 print '*'*50 def case_insensitive_sort(liststring
-
python实现在IDLE中输入多行的方法
在python命令行模式下,在IDLE中输入多行,例如if else 使用tab的方式,控制缩进 在最后,连续两个回车,表示结束 >>> if state: ... print "ok" ... else: ... print "wrong" ... wrong >>> 以上这篇python实现在IDLE中输入多行的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们. 您可能感兴趣的文章: Pyth
-
对Python 多线程统计所有csv文件的行数方法详解
如下所示: #统计某文件夹下的所有csv文件的行数(多线程) import threading import csv import os class MyThreadLine(threading.Thread): #用于统计csv文件的行数的线程类 def __init__(self,path): threading.Thread.__init__(self) #父类初始化 self.path=path #路径 self.line=-1 #统计行数 def run(self): reader =
-
python 实现提取某个索引中某个时间段的数据方法
如下所示: from elasticsearch import Elasticsearch import datetime import time import dateutil.parser class App(object): def __init__(self): pass def _es_conn(self): es = Elasticsearch() return es def get_data(self, day,start,end): index_ = "gather-apk-20