python difflib模块示例讲解
difflib模块提供的类和方法用来进行序列的差异化比较,它能够比对文件并生成差异结果文本或者html格式的差异化比较页面,如果需要比较目录的不同,可以使用filecmp模块。
class difflib.SequenceMatcher
此类提供了比较任意可哈希类型序列对方法。此方法将寻找没有包含‘垃圾'元素的最大连续匹配序列。
通过对算法的复杂度比较,它由于原始的完形匹配算法,在最坏情况下有n的平方次运算,在最好情况下,具有线性的效率。
它具有自动垃圾启发式,可以将重复超过片段1%或者重复200次的字符作为垃圾来处理。可以通过将autojunk设置为false关闭该功能。
class difflib.Differ
此类比较的是文本行的差异并且产生适合人类阅读的差异结果或者增量结果,结果中各部分的表示如下:

class difflib.HtmlDiff
此类可以被用来创建HTML表格 (或者说包含表格的html文件) ,两边对应展示或者行对行的展示比对差异结果。
make_file(fromlines, tolines [, fromdesc][, todesc][, context][, numlines])
make_table(fromlines, tolines [, fromdesc][, todesc][, context][, numlines])
以上两个方法都可以用来生成包含一个内容为比对结果的表格的html文件,并且部分内容会高亮显示。
difflib.context_diff(a, b[, fromfile][, tofile][, fromfiledate][, tofiledate][, n][, lineterm])
比较a与b(字符串列表),并且返回一个差异文本行的生成器
示例:
>>> s1 = ['bacon\n', 'eggs\n', 'ham\n', 'guido\n'] >>> s2 = ['python\n', 'eggy\n', 'hamster\n', 'guido\n'] >>> for line in context_diff(s1, s2, fromfile='before.py', tofile='after.py'): ... sys.stdout.write(line) *** before.py --- after.py *************** *** 1,4 **** ! bacon ! eggs ! ham guido --- 1,4 ---- ! python ! eggy ! hamster guido
difflib.get_close_matches(word, possibilities[, n][, cutoff])
返回最大匹配结果的列表
示例:
>>> get_close_matches('appel', ['ape', 'apple', 'peach', 'puppy'])
['apple', 'ape']
>>> import keyword
>>> get_close_matches('wheel', keyword.kwlist)
['while']
>>> get_close_matches('apple', keyword.kwlist)
[]
>>> get_close_matches('accept', keyword.kwlist)
['except']
difflib.ndiff(a, b[, linejunk][, charjunk])
比较a与b(字符串列表),返回一个Differ-style 的差异结果
示例:
>>> diff = ndiff('one\ntwo\nthree\n'.splitlines(1),
... 'ore\ntree\nemu\n'.splitlines(1))
>>> print ''.join(diff),
- one
? ^
+ ore
? ^
- two
- three
? -
+ tree
+ emu
difflib.restore(sequence, which)
返回一个由两个比对序列产生的结果
示例
>>> diff = ndiff('one\ntwo\nthree\n'.splitlines(1),
... 'ore\ntree\nemu\n'.splitlines(1))
>>> diff = list(diff) # materialize the generated delta into a list
>>> print ''.join(restore(diff, 1)),
one
two
three
>>> print ''.join(restore(diff, 2)),
ore
tree
emu
difflib.unified_diff(a, b[, fromfile][, tofile][, fromfiledate][, tofiledate][, n][, lineterm])
比较a与b(字符串列表),返回一个unified diff格式的差异结果.
示例:
>>> s1 = ['bacon\n', 'eggs\n', 'ham\n', 'guido\n'] >>> s2 = ['python\n', 'eggy\n', 'hamster\n', 'guido\n'] >>> for line in unified_diff(s1, s2, fromfile='before.py', tofile='after.py'): ... sys.stdout.write(line) --- before.py +++ after.py @@ -1,4 +1,4 @@ -bacon -eggs -ham +python +eggy +hamster guido
实际应用示例
比对两个文件,然后生成一个展示差异结果的HTML文件
#coding:utf-8
'''
file:difflibeg.py
date:2017/9/9 10:33
author:lockey
email:lockey@123.com
desc:diffle module learning and practising
'''
import difflib
hd = difflib.HtmlDiff()
loads = ''
with open('G:/python/note/day09/0907code/hostinfo/cpu.py','r') as load:
loads = load.readlines()
load.close()
mems = ''
with open('G:/python/note/day09/0907code/hostinfo/mem.py', 'r') as mem:
mems = mem.readlines()
mem.close()
with open('htmlout.html','a+') as fo:
fo.write(hd.make_file(loads,mems))
fo.close()
运行结果:
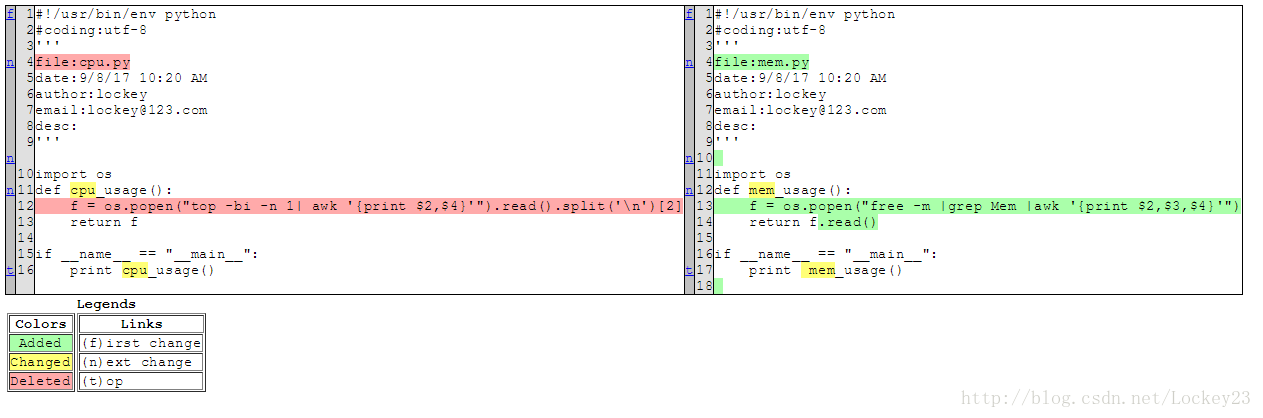
生成的html文件比对结果:
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
Python subprocess模块学习总结
一.subprocess以及常用的封装函数运行python的时候,我们都是在创建并运行一个进程.像Linux进程那样,一个进程可以fork一个子进程,并让这个子进程exec另外一个程序.在Python中,我们通过标准库中的subprocess包来fork一个子进程,并运行一个外部的程序.subprocess包中定义有数个创建子进程的函数,这些函数分别以不同的方式创建子进程,所以我们可以根据需要来从中选取一个使用.另外subprocess还提供了一些管理标准流(standard stream)和管
-
Python random模块(获取随机数)常用方法和使用例子
random.randomrandom.random()用于生成一个0到1的随机符点数: 0 <= n < 1.0 random.uniformrandom.uniform(a, b),用于生成一个指定范围内的随机符点数,两个参数其中一个是上限,一个是下限.如果a > b,则生成的随机数n: a <= n <= b.如果 a <b, 则 b <= n <= a 复制代码 代码如下: print random.uniform(10, 20)print rand
-
Python Queue模块详解
Python中,队列是线程间最常用的交换数据的形式.Queue模块是提供队列操作的模块,虽然简单易用,但是不小心的话,还是会出现一些意外. 创建一个"队列"对象 import Queue q = Queue.Queue(maxsize = 10) Queue.Queue类即是一个队列的同步实现.队列长度可为无限或者有限.可通过Queue的构造函数的可选参数maxsize来设定队列长度.如果maxsize小于1就表示队列长度无限. 将一个值放入队列中 q.put(10) 调用队列对象的p
-
Python urllib模块urlopen()与urlretrieve()详解
1.urlopen()方法urllib.urlopen(url[, data[, proxies]]) :创建一个表示远程url的类文件对象,然后像本地文件一样操作这个类文件对象来获取远程数据.参数url表示远程数据的路径,一般是网址:参数data表示以post方式提交到url的数据(玩过web的人应该知道提交数据的两种方式:post与get.如果你不清楚,也不必太在意,一般情况下很少用到这个参数):参数proxies用于设置代理.urlopen返回 一个类文件对象,它提供了如下方法:read(
-
python中MySQLdb模块用法实例
本文实例讲述了python中MySQLdb模块用法.分享给大家供大家参考.具体用法分析如下: MySQLdb其实有点像php或asp中连接数据库的一个模式了,只是MySQLdb是针对mysql连接了接口,我们可以在python中连接MySQLdb来实现数据的各种操作. python连接mysql的方案有oursql.PyMySQL. myconnpy.MySQL Connector 等,不过本篇要说的确是另外一个类库MySQLdb,MySQLdb 是用于Python链接Mysql数据库的接口,它
-
python正则表达式re模块详细介绍
本模块提供了和Perl里的正则表达式类似的功能,不关是正则表达式本身还是被搜索的字符串,都可以是Unicode字符,这点不用担心,python会处理地和Ascii字符一样漂亮. 正则表达式使用反斜杆(\)来转义特殊字符,使其可以匹配字符本身,而不是指定其他特殊的含义.这可能会和python字面意义上的字符串转义相冲突,这也许有些令人费解.比如,要匹配一个反斜杆本身,你也许要用'\\\\'来做为正则表达式的字符串,因为正则表达式要是\\,而字符串里,每个反斜杆都要写成\\. 你也可以在字符串前加上
-
Python下的Mysql模块MySQLdb安装详解
默认情况下,MySQLdb包是没有安装的,不信? 看到类似下面的代码你就信了. 复制代码 代码如下: -bash-3.2# /usr/local/python2.7.3/bin/python get_cnblogs_news.py Traceback (most recent call last): File "get_cnblogs_news.py", line 9, in <module> import MySQLdbImportError: No module
-

python difflib模块示例讲解
difflib模块提供的类和方法用来进行序列的差异化比较,它能够比对文件并生成差异结果文本或者html格式的差异化比较页面,如果需要比较目录的不同,可以使用filecmp模块. class difflib.SequenceMatcher 此类提供了比较任意可哈希类型序列对方法.此方法将寻找没有包含'垃圾'元素的最大连续匹配序列. 通过对算法的复杂度比较,它由于原始的完形匹配算法,在最坏情况下有n的平方次运算,在最好情况下,具有线性的效率. 它具有自动垃圾启发式,可以将重复超过片段1%或者重复20
-
Python hashlib模块详细讲解使用方法
目录 1.hashlib的简介 2.hashlib的使用 1. 常用属性 2. 常用方法 3. 使用示例 3.hashlib的特点 4.实际演示 1. 基本演示 2. 应用场景案例 1.hashlib的简介 hashlib 是一个提供了一些流行的hash(摘要)算法的Python标准库.其中所包括的算法有 md5, sha1, sha224, sha256, sha384, sha512等 什么是摘要算法呢?摘要算法又称哈希算法.散列算法.它通过一个函数,把任意长度的数据转换为一个长度固定的数据
-
Python的字符串示例讲解
之前我们学习过一个不可变的序列叫元组,今天我们探讨的字符串,也是一个不可变序列. 1. 字符串的创建 一个概念: 字符串的驻留机制 那什么是字符串的驻留机制呢? 意思是: 仅保留一份相同且不可变字符串的方法,不同的值被存放在字符串的驻留池中,python的驻留机制对相同的字符串只保留一份拷贝,后续创建相同字符串时候,不会开辟新的空间,而是把该字符串的地址重新赋值给新建的变量. 1) 字符串的定义 # 作者:互联网老辛 # 开发时间:2021/4/4/0004 6s a='itlaoxin' b=
-
Python collections模块实例讲解
collections模块基本介绍 我们都知道,Python拥有一些内置的数据类型,比如str, int, list, tuple, dict等, collections模块在这些内置数据类型的基础上,提供了几个额外的数据类型: 1.namedtuple(): 生成可以使用名字来访问元素内容的tuple子类2.deque: 双端队列,可以快速的从另外一侧追加和推出对象3.Counter: 计数器,主要用来计数4.OrderedDict: 有序字典5.defaultdict: 带有默认值的字典 n
-
python XlsxWriter模块创建aexcel表格的实例讲解
安装使用pip install XlsxWriter来安装,Xlsxwriter用来创建excel表格,功能很强大,下面具体介绍: 1.简单使用excel的实例: #coding:utf-8 import xlsxwriter workbook = xlsxwriter.Workbook('d:\\suq\\test\\demo1.xlsx') #创建一个excel文件 worksheet = workbook.add_worksheet('TEST') #在文件中创建一个名为TEST的shee
-
对python自动生成接口测试的示例讲解
在python中Template可以将字符串的格式固定下来,重复利用. 同一套测试框架为了可以复用,所以我们可以将用例部分做参数化,然后运用到各个项目中. 代码如下: coding=utf-8 ''' 作者:大石 功能:自动生成pyunit框架下的接口测试用例 环境:python2.7.6 用法:将用户给的参数处理成对应格式,然后调用模块类生成函数,并将参数传入即可 ''' from string import Template #动态生成单个测试用例函数字符串 def singleMethod
-
Python使用draw类绘制图形示例讲解
目录 视频 Pygame模块之pygame.draw 示例1 示例2 视频 观看视频 Pygame模块之pygame.draw 本文将主要介绍Pygame的draw模块,主要内容翻译自pygame的官方文档 pygame.draw 模块用于在Surface上绘制一些简单的图形,比如点.直线.矩形.圆.弧等. pygame.draw中函数的第一个参数总是一个surface,然后是颜色,再后会是一系列的坐标等.稍有些计算机绘图经验的人就会知道,计算机里的坐标,(0,0)代表左上角.而返回值是一个Re
-
python模块之time模块(实例讲解)
time 表示时间的三种形式 时间戳(timestamp) :通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量.我们运行"type(time.time())",返回的是float类型. 格式化的时间字符串(Format String): '1999-12-06' 时间格式化符号 ''' %y 两位数的年份表示(00-99) %Y 四位数的年份表示(000-9999) %m 月份(01-12) %d 月内中的一天(0-31) %H 24小时制小时数(0-2
-
Python实现购物系统(示例讲解)
要求: 用户入口 1.商品信息存在文件里 2.已购商品,余额记录. 商家入口 可以添加商品,修改商品价格 Code: 商家入口: # Author:P J J import os ps = ''' 1 >>>>>> 修改商品 2 >>>>>> 添加商品 按q为退出程序 ''' # 打开两个文件,f文件为原来存取商品文件,f_new文件为修改后的商品文件 f = open('commodit', 'r', encoding='utf-8
-
python模块之sys模块和序列化模块(实例讲解)
sys模块 sys模块是与python解释器交互的一个接口 sys.argv 命令行参数List,第一个元素是程序本身路径 sys.exit(n) 退出程序,正常退出时exit(0),错误退出sys.exit(1) sys.version 获取Python解释程序的版本信息 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 sys.platform 返回操作系统平台名称 序列化模块 序列化的目的: 以某种存储形式使自定义对象持久化 将对象从一个地方传递到另一个地